知识图谱增强的基于大语言模型配电网故障归因分析方法
文献发布时间:2024-04-18 19:53:33
技术领域
本发明涉及配网电力智能关键技术领域,尤其涉及一种知识图谱增强的基于大语言模型配电网故障归因分析方法。
背景技术
随着我国经济飞速发展,电力网络规模日益扩大,配电场景也变得越来越复杂。为了保障电力系统的稳定运行和保护公众的生活质量及财产安全,智能决策在配电网络中扮演着越来越重要的角色。特别是配电网的故障处理,它与用户息息相关,并且是保证配电网络安全稳定运行的关键一环。在应对数据的事件性、多样性、复杂性等挑战时,我们需要借助大数据、人工智能和知识工程的理念和技术,对配电网故障处理过程中产生的大量知识进行深度挖掘,进一步发挥其价值。
电力系统作为现代社会的重要基础设施,其安全稳定运行对于保障社会经济活动具有至关重要的作用。特别是配电网络,作为电力系统的“最后一公里”,其故障处理能力直接影响到用户的电力使用体验和电力系统的整体稳定性。然而,由于配电网络的规模日益扩大,故障数据的事件性、多样性和复杂性也在持续增强,这对配电网故障处理带来了严峻挑战。
当前,故障处理主要依赖于专业人员的经验和专业知识,但这种方法的效率较低,且难以应对复杂多变的故障情况。随着大数据、人工智能等技术的发展,如何利用这些技术进行故障数据的深度挖掘和故障原因的快速准确分析,已经成为当前研究的热点。尤其是如何将大数据技术与人工智能技术相结合,利用知识图谱和大语言模型实现故障数据的智能处理和故障原因的快速准确归因,是当前亟待解决的问题。
发明内容
本发明的目的在于解决背景技术存在问题,提供一种知识图谱增强的基于大语言模型配电网故障归因分析方法,该方法将知识图谱和大语言模型作为核心,综合运用大数据挖掘、人工智能和知识工程等技术,融合配电网领域特有的故障数据属性,如故障类型、故障时间、故障位置等,从而实现对配电网故障处理过程中产生的大量知识的深度挖掘和利用,提高故障处理的效率和准确性。本发明为配电网故障归因分析提供了新思路,有助于提升电力系统的安全稳定运行和用户的电力使用体验。
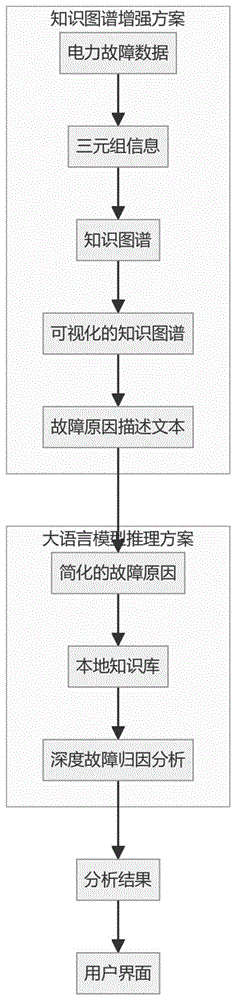
为实现上述目的,本发明的技术方案是:一种知识图谱增强的基于大语言模型配电网故障归因分析方法,包括如下步骤:
步骤一、采用数据提取技术,从大量复杂的电力故障数据中挖掘出关键信息,这些关键信息被结构化为三元组形式,用以初始化和构建知识图谱;
步骤二、利用可视化工具,对已构建的知识图谱进行细致的可视化处理;通过直观的图形展示揭示可能的故障原因,以此为后续分析提供基础;
步骤三、依赖启发式规则,在知识图谱上以预定节点为起点进行链接游走,选取关键节点,生成详尽且全面的描述故障原因的文本;
步骤四、使用大语言模型LLM对步骤三生成的文本进行深度处理,进行文本简化和信息提取,将复杂的故障原因描述转化为简洁明了的故障原因;
步骤五、将经步骤四处理后的文本信息存储为本地知识库,然后在本地知识库的基础上进行大语言模型问答,执行深度的故障归因分析。
本发明方法能有效地找出电力故障的原因,提高故障处理效率。
在本发明一实施例中,电力故障数据涵盖各类电力设备的故障报告,这些故障报告详细记录故障设备的信息,包括故障类型、故障时间、故障位置和故障影响等。这些信息在确定故障原因方面发挥了关键作用。
在本发明一实施例中,提取三元组的步骤包括设计一个专为电力故障数据定制的三元组模型,三元组模型将关键的故障信息,包括故障设备、故障类型、故障时间,结构化为实体和关系,形成“实体-关系-实体”的三元组形式;然后,利用Excel表格处理工具,直接从电力故障数据中提取出符合三元组模型的信息,以构建知识图谱。
在本发明一实施例中,所述可视化工具为Gephi图形可视化工具,可以清晰地展示知识图谱的结构,帮助用户理解故障原因的关联性和复杂性。
在本发明一实施例中,启发式规则包括选择预定节点作为起始节点,然后根据广度优先搜索的方式在知识图谱上进行链接游走,选择关键节点,并将关键节点的内容拼接在一起,供大模型使用。
在本发明一实施例中,大语言模型LLM对生成的文本进行深度处理,包括文本的清洗,去除无关信息,提取关键信息,以提高故障原因描述的精确性。
在本发明一实施例中,大语言模型LLM处理后的文本以本地知识库的形式进行存储,这是一种按照记录分段的文本文件。
在本发明一实施例中,大语言模型LLM对步骤三生成的文本进行处理的步骤,具体包括加载文件、读取文本、分割文本、将文本向量化、将提出的问题向量化、在文本向量中匹配出与问题向量最相似的top-k个向量、将匹配出的文本作为上下文和问题一起添加到prompt中、将整合后的prompt提交给大语言模型LLM生成答案。
在本发明一实施例中,还包括开发一个前端用户界面,用户能够通过前端用户界面输入问题,接收分析结果。
在本发明一实施例中,所述前端用户界面是由streamlit构建的web界面,用户能够通过前端用户界面输入问题,进行故障原因的查询,接收和查看系统生成的故障原因分析,并提供一些参考案例。
相较于现有技术,本发明具有以下有益效果:本发明提供的一种知识图谱增强的基于大语言模型配电网故障归因分析方法,结合了大数据、人工智能和知识工程的理念和技术,旨在实现对配电网故障处理过程中产生的大量知识的深度挖掘和利用,以提高故障处理的效率和准确性。具体来说,该方法通过构建知识图谱,使用大语言模型进行深度处理和大语言模型问答,对电力故障进行深度归因分析,以便更有效地找出故障的原因,提高故障处理的效率,从而提升电力系统的安全稳定运行和用户的电力使用体验。
附图说明
附图1为本发明方法流程示意图。
附图2是本发明的故障归因知识图谱主干网络示意图。
附图3是本发明的故障归因知识图谱故障编号的挂载属性示意图。
附图4是本发明的故障归因知识图谱主干网络可视化结果示意图。
附图5是本发明的步骤7得到的长文本,分析句子长度的图。
附图6是本发明的故障归因知识图谱链路游走示意图。
附图7是本发明的接口设计的Body形式的示意图。
附图8是本发明的web前端示意图。
附图9是本发明的web前端问答示意图。
附图10是本发明的web前端返回的原因的参数案例示意图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1所示,本发明提供了一种知识图谱增强的基于大语言模型配电网故障归因分析方法,包括如下步骤:
步骤一、采用数据提取技术,从大量复杂的电力故障数据中挖掘出关键信息,这些关键信息被结构化为三元组形式,用以初始化和构建知识图谱;
步骤二、利用可视化工具,对已构建的知识图谱进行细致的可视化处理;通过直观的图形展示揭示可能的故障原因,以此为后续分析提供基础;
步骤三、依赖启发式规则,在知识图谱上以预定节点为起点进行链接游走,选取关键节点,生成详尽且全面的描述故障原因的文本;
步骤四、使用大语言模型LLM对步骤三生成的文本进行深度处理,进行文本简化和信息提取,将复杂的故障原因描述转化为简洁明了的故障原因;
步骤五、将经步骤四处理后的文本信息存储为本地知识库,然后在本地知识库的基础上进行大语言模型问答,执行深度的故障归因分析。
在本发明实施例中,本发明方法具体实现如下:
步骤1、对2022年故障单结构化数据进行预处理,其中我们选择的数据是其中的本期/同期配变视角故障单;对数据集中低质量或无用字段根据人工设定的规则进行筛选,这里的人工规则是:去掉无用的故障线路,去掉重复的原因字段,去掉专用或公用字段,最终得到预处理后的数据集。
步骤2、经初步设计,整理得45种关系(三元组表示),每一种关系为一个csv文件。得到三元组总数:24322105个。
步骤3、对步骤2的数据写入NEO4J数据库,写入数据库的步骤包括建立索引,节点合并得到节点628220个,关系2218294个。
步骤4、从数据中发现关系,构成主干网络,如附图2所示。对于每个关系的定义采用人工启发式定义方法,如1.所属地区连接到运行单位(运行单位位于所属地区中);抢修处理人和抢修班组之间的关系(抢修处理人属于抢修班组)。
步骤5、围绕故障编号,挂载属性(见附图3)。通过主干网络,和挂载的节点,得到知识图谱。
步骤6、使用Gephi进行图谱可视化。对图谱可视化进行抽样,因为随机抽样可以代表整体的信息,而又可以更直观的在硬件上进行绘图。我们选取了21103个节点,21186条关系的子图。可视化结果如图4所示。我们得到的结果如下:1.故障集中于几个责任原因。2.可根据颜色深浅排序责任原因。
步骤7、基于链路游走(见附图6)从图谱中启发式提取记录,设计启发式规则,设定查找路线。将查找到的路线的节点内容拼接在一起,用分号隔开,得到自然语言文本。其查找的规则如下:
1.选择”责任原因”为第一个节点
2.进行广度优先查找
3.若下一个节点不全等于停用词,继续2
4.若下一个节点全等于停用词,则删除该节点,并把该节点的入/出边设置为该节点的入/出边,继续2.2
停用词设计:
Excel表格中的列名除以下,都为停用词:责任原因、责任原因细类、影响范围、故障类型、故障概述、故障原因、原因分析、整改措施、故障性质、保护动作情况、重合闸情况、技术原因大类、技术原因细类、故障原因、整改措施。
步骤8、对上述步骤7所得到的长文本,进行长度分析,发现内容过长其参差不齐,见附图5。用大语言模型,通过提问的方式,进行缩短提炼。然后,再利用spacy库进行二次精炼,进行stopwords删除,其中包含两种类型改的词汇:PERSON、DATE。然后暴力搜索删除行中,15个字符以上的重复子串。最终得到共计21292行。
步骤9、将步骤8中生成的文本,按照一条记录为一段,存储在一个文本文件中,作为本地的知识库。将在基于大语言模型的故障归因系统中使用。
步骤10、让用户输出问题,再读取步骤9中的文本、分割文本、将文本向量化、将提出的问题向量化、在文本向量中匹配出与问题向量最相似的top k个向量、将匹配出的文本作为上下文和问题一起添加到prompt中、将整合后的prompt提交给LLM生成答案。
步骤11、使用streamlit构建web前端界面,使用FastAPI,其接口形式可见附图7,将LLM的能力暴露到web端口中。这样一个简单的web应用就构建好了,用户可以基于web端进行体验和使用。Web前端的界面可见附图9,问答界面界面可见附图9。
步骤12、用户在前端提问的时候可提供数个参考案例。列表可展开,有序展示,并且展示相关度,可见附图10。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 一种粉末加工防止漏料的传送装置
- 一种压力机床的上料装置及基于该上料装置的多道次压制方法
- 一种用于送料装置上的摆动压料装置
- 一种玻璃纤维漏板池窑漏板专用加热装置
- 漏料检测振动装置及采用该装置制备的漏料检测机
- 用于铂金通道的漏料检测冷却系统及其漏料检测冷却装置