一种用于生成3D数字人视频的方法及系统
文献发布时间:2024-04-18 19:58:21
技术领域
本申请涉及数字人生成技术领域,尤其涉及一种用于生成3D数字人视频的方法及系统。
背景技术
数字人是通过计算机技术制作的类人形象或者软件制作的结果。它们具备人类的外观或者行为模式,却不是现实世界中的某个人的录像,能独立运行和存在。数字人的本体存在于计算设备中(比如电脑、手机),并通过显示设备呈现出来。它们能够实现如语音交互、网上直播、客服沟通、导游向导、导购等等工作。
3D数字人相比于2D数字人在形象上能够更加相似于真人,具有良好的仿真效果,对于一些高要求的领域,通常会选择3D数字人。在3D数字人方向,人们通常会通过视频素材中获取用于生成3D数字人的表情、动作或语音等驱动素材,并使用驱动素材驱动得到3D数字人的视频。
在生成3D数字人的技术方案中,数字人仅仅可以做出几个动作,无法根据用户的驱动指令做出相应的动作,针对不同的场景3D数字人依然使用相同的动作,造成用户的视觉疲乏,降低用户的体验感。
发明内容
本申请实施例提供了一种用于生成3D数字人视频的方法及系统,以解决在生成3D数字人的技术方案中,数字人的动作无法根据用户的驱动指令进行交互的问题。
第一方面,本申请实施例提供了一种用于生成3D数字人视频的方法,所述方法包括:
获取视频素材,以及从所述视频素材中提取素材人物图像;
根据所述素材人物图像进行3D重建,以得到与所述素材人物图像中人物目标相关联的3D数字人模型;
获取用户输入的驱动指令;所述驱动指令中包括驱动动作以及驱动语音;
根据所述驱动动作以及所述驱动语音驱动所述3D数字人模型,以生成驱动视频;
渲染所述驱动视频,得到3D数字人视频。
在本申请的一些实施例中,根据所述驱动动作以及所述驱动语音驱动对所述3D数字人模型进行驱动的步骤中,所述方法还包括:
对所述驱动动作进行解析,得到面部驱动动作以及肢体驱动动作;
根据所述面部驱动作生成3D数字人的面部驱动帧,以及根据所述肢体驱动动作生成3D数字人的肢体驱动帧;
获取所述3D数字人的语音驱动帧;
将所述面部驱动帧、所述肢体驱动帧与3D数字人的语音驱动帧共同驱动,得到驱动视频。
在本申请的一些实施例中,获取所述3D数字人的语音驱动帧的步骤中,所述方法还包括:
对所述驱动语音进行解析,得到所述驱动语音的播放时间序列以及所述驱动语音的语音帧;
按照所述播放时间序列对所述语音帧进行排序,得到语音驱动帧。
在本申请的一些实施例中,所述方法还包括:
解析所述视频素材,以及从所述视频素材中提取素材人物动作;所述素材人物动作包括素材面部动作和素材肢体动作;
使用动作迁移模型将所述素材面部动作和所述素材肢体动作迁移至所述3D数字人模型,以生成驱动视频,所述动作迁移模型为根据所述素材人物动作生成所述3D数字人模型动作坐标的深度神经网络模型。
在本申请的一些实施例中,根据所述素材人物图像进行3D重建的步骤,所述方法还包括:
根据素材人物图像提取素材人物的面部特征;
将所述面部特征进行编码处理,得到面部特征编码;
将所述面部特征编码输入3D重建模型中,得到3D数字人模型。
在本申请的一些实施例中,所述方法还包括:
根据所述人物素材图像,提取人物特征参数;所述人物特征参数包括面部表情参数以及肢体参数;
根据所述面部表情参数以及所述肢体参数对所述3D数字人模型进行参数调整。
在本申请的一些实施例中,所述方法还包括:
获取样本素材,以及从所述样本素材中提取样本人物图像;
解析所述样本人物图像,得到样本人物特征;所述样本人物特征包括样本人物表情特征和样本人物体型特征;
将所述样本人物表情特征和所述样本人物体型特征输入至待训练模型的生成器中,得到样本3D数字人模型;所述待训练模型为根据所述样本人物特征生成样本3D数字人模型的神经网络模型;
通过所述第一损失函数计算所述样本3D数字人模型的第一训练损失;
如果所述第一训练损失小于第一损失阈值,输出当前生成器的第一训练参数。
在本申请的一些实施例中,所述方法还包括:
根据所述样本素材提取样本人物语音;
提取所述样本人物语音的语音特征;
将所述语音特征输入至所述待训练模型中,以对所述待训练模型的声音部分进行训练;
向所述待训练模型输入样本语音,以得到所述3D数字人音色;所述样本语音为不同于所述样本人物语音的语音音频;
通过第二损失函数计算所述3D数字人音色的第二训练损失;
如果所述第二训练损失小于第二损失阈值,输出当前待训练模型的声音部分的第二训练参数。
在本申请的一些实施例中,所述方法还包括:
根据所述样本人物图像,解析所述样本动作特征;所述样本动作特征包括样本表情动作和样本肢体动作;
将所述样本表情动作和所述样本肢体动作输入至所述待训练模型中,以得到样本驱动视频;所述样本驱动视频中,样本3D数字人模型同步执行样本表情动作和样本肢体动作;
通过第三损失函数计算所述样本驱动视频的第三训练损失;
如果所述第三训练损失小于第三损失阈值,则输出当前待训练模型的第三训练参数。
第二方面,本申请实施例还提供了一种用于生成3D数字人视频的系统,用于执行一种用于生成3D数字人视频的方法,所述系统包括应用模块,所述应用模块被配置为:
获取视频素材,以及从所述视频素材中提取素材人物图像;
根据所述素材人物图像进行3D重建,以得到与所述素材人物图像中人物目标相关联的3D数字人模型;
获取用户输入的驱动指令;所述驱动指令中包括驱动动作以及驱动语音;
根据所述驱动动作以及所述驱动语音驱动所述3D数字人模型,以生成驱动视频;
渲染所述驱动视频,得到3D数字人视频。
由以上技术方案可知,基于本申请提供一种用于生成3D数字人视频的方法及系统,所述方法通过获取视频素材,并从视频素材中提取素材人物图像,根据素材人物图像进行3D重建,得到与素材人物图像中的人物目标相关联的3D数字人模型。然后获取用户输入的驱动指令,根据驱动指令中的驱动动作和驱动语音驱动3D数字人,生成驱动视频,最后对驱动视频进行渲染,得到3D数字人视频。本申请通过对视频素材中的人物目标进行识别,根据人物目标建立3D数字人模型,并通过用户输入的驱动指令驱动3D数字人模型,增强用户与3D数字人之间的互动效果,提高用户的体验感。
附图说明
为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种用于生成3D数字人视频的方法的流程示意图;
图2为本申请实施例提供的通过动作迁移模型得到驱动视频的流程示意图;
图3为本申请实施例提供的训练神经网络模型时第一训练参数的训练流程图;
图4为本申请实施例提供的训练神经网络模型时第二训练参数的训练流程图;
图5为本申请实施例提供的训练神经网络模型时第三训练参数的训练流程图。
具体实施方式
下文中将参考附图并结合实施例来详细说明本申请。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
数字人是通过计算机技术制作的类人形象或者软件制作的结果。它们具备人类的外观或者行为模式,却不是现实世界中的某个人的录像,能独立运行和存在。数字人的本体存在于计算设备中(比如电脑、手机),并通过显示设备呈现出来。它们能够实现如语音交互、网上直播、客服沟通、导游向导、导购等工作。
对于不同的用户来说,使用数字人的场景需求也不同,部分用户为了追求更好的视觉效果,会选择使用3D数字人。3D数字人相比于2D数字人在形象上能够更加相似于真人,具有良好的仿真效果,对于一些高要求的领域,通常会选择3D数字人。在3D数字人方向,人们通常会通过视频素材中获取用于生成3D数字人的表情、动作或语音等驱动素材,并使用驱动素材驱动得到3D数字人的视频。
在生成3D数字人的技术方案中,数字人仅仅可以做出几个动作,无法根据用户的驱动指令做出相应的动作,针对不同的场景3D数字人依然使用相同的动作,3D数字人与用户的交互过程较少,造成用户的视觉疲乏,降低用户的体验感。
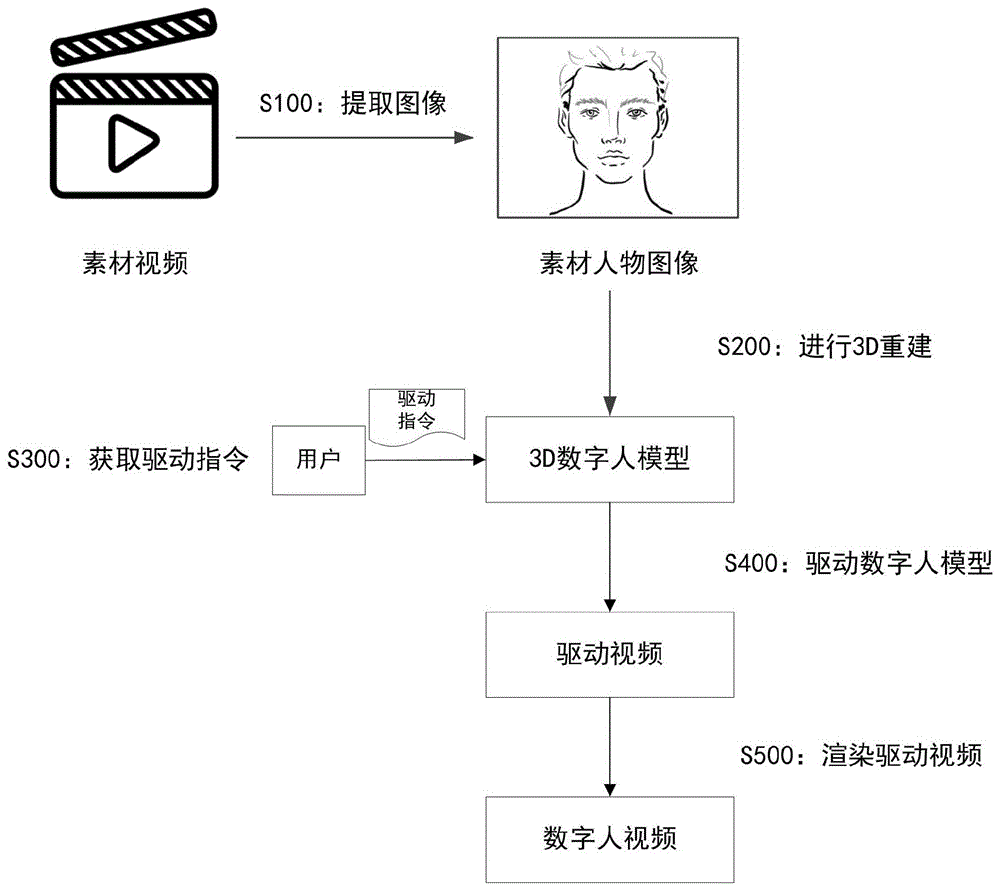
在生成3D数字人的技术方案中,数字人的动作无法根据用户的驱动指令进行交互的问题,本申请实施例提供了一种用于生成3D数字人视频的方法及系统,所述方法和系统可以应用于智能终端,如移动电话、平板电脑、计算机、笔记本电脑等。如图1所示,所述方法包括:
S100:获取视频素材,以及从所述视频素材中提取素材人物图像。
在本实施例中,视频素材应至少包括一个人物目标,用于作为建立3D数字人的参考。所述视频素材可以是已经录制好的视频或者是可下载截取的影视视频。用户可以通过点击预设的视频链接,并请求下载指定的影视视频,以影视视频画面中的人物作为人物目标,提取素材人物图像。
在一些实施例中,素材人物图像还可以包括虚拟人物,如虚拟歌手、卡通、动漫角色等,需要说明的是,上述虚拟人物仅用于后续的3D数字人模型的重建过程而并非为数字人本身。
在一些实施例中,可以选取视频素材中的一帧或多帧作为素材人物图像,并对素材人物图像中的人物目标进行提取和识别,并根据用户输入的选择指令,选择素材人物图像中的一个人物作为后续生成3D数字人模型的人物目标。
S200:根据所述素材人物图像进行3D重建,以得到与所述素材人物图像中人物目标相关联的3D数字人模型。
在获取到素材人物图像之后,根据用户选择的指定的人物目标进行3D重建,根据真人素材生成对应的3D数字人模型。所述3D数字人模型的人物形象与素材人物图像中的相关联,以确保人物目标与生成的3D数字人模型之间存在较高的相似度。3D重建是指利用二维投影恢复物体三维信息(形状等)的数学过程和计算机技术,包括数据获取、预处理、点云拼接和特征分析等步骤。
3D数字人需要在表情以及体型上都要与人物目标保持高相似度,为了提高3D重建的还原度,在一些实施例中,根据素材人物图像化进行3D重建的过程中,还需要获取人物目标的表情特征、面部特征以及体型特征。表情特征为人物目标在素材人物图像中的表情,表情特征可以是,喜悦、愤怒、惊讶、悲伤等。面部特征为人物目标在素材人物图像中的面部细节特征。例如毛发,如胡须、头发或眉毛等,以胡须为例,面部特征可以为长胡须、短胡须、胡茬或络腮胡等。面部细节特征还可以包括皱纹、痣、斑痕以及面部器官的类型等。体型特征为人物目标在素材人物图像中的体型特点,例如人物目标的身高高矮、体型胖瘦等。
在获取人物目标的表情特征、面部特征以及体型特征之后,还需要将上述特征共同作为人物目标的特征参数进行3D重建,以得到更生动更逼真的3D数字人模型。
在一些实施例中,还可以根据素材人物图像的表情特征、面部特征以及体型特征进行编码处理,得到表情特征编码、面部特征编码以及体型特征编码,并将上述表情特征编码、面部特征编码以及体型特征编码输入至3D重建模型中,通过3D重建模型来生成与人物目标形象相关联的3D数字人模型。
S300:获取用户输入的驱动指令。
其中,所述驱动指令中可以包括驱动动作以及驱动语音。驱动动作是控制3D数字人模型被驱动时所执行的动作。用户可以通过文字输入的方式,例如向3D数字人输入“拍手”、“眨眼”、“摇头”或“跳跃”等文本,并对该文本进行动作识别,以生成对应的驱动动作。用户还可以通过终端设备的摄像功能,实时捕捉用户做出的特定动作作为驱动动作。用户还可以通过智能终端向3D数字人上传一段带有特定动作的视频,通过对视频中动作的识别,来生成对应的驱动动作。
驱动语音是控制3D数字人做出指定动作或者说出指定文本的语音指令。驱动语音可以为控制3D数字人执行动作的语音,例如驱动语音为“请你拍拍手。”3D数字人在收到驱动语音后,会对驱动语音进行识别,并做出对应的拍手动作。驱动语音可以为一个与3D数字人进行交互的交互问题语音,例如,驱动语音为“请你告诉我当前的时间。”3D数字人在收到驱动语音后,会对驱动语音进行识别,并生成与交互问题对应的反馈答案文本,此时,3D数字人会执行说出反馈答案文本,以达到与用户交互的技术目的。
在一些实施例中,驱动指令还可以同时包括驱动动作和驱动语音,3D数字人在响应驱动指令时,会同时执行驱动动作以及驱动语音,也可以先后依次执行驱动动作和驱动语音。在先后依次执行驱动动作和驱动语音的过程中,执行驱动动作和驱动语音的先后顺序不限。
S400:根据所述驱动动作以及所述驱动语音驱动所述3D数字人模型,以生成驱动视频。
在本实施例中,智能终端可以在3D数字人接收到驱动指令之后开启智能终端的录制功能,在3D数字人执行驱动动作以及驱动语音的过程中全程进行录制,以得到驱动视频。为了保证驱动视频的录制完整性,在一些实施例中,在录制驱动视频的过程中,智能终端还可以对录制的驱动帧进行备份,并检测驱动视频是否存在丢帧的情况,如果检测到驱动视频出现丢帧,则根据丢帧位置,提取备份的驱动帧,并将驱动帧插入至丢帧位置,以保持驱动视频的完整性。
驱动动作还可以包括面部动作和肢体动作,为了更完整的驱动3D数字人,在一些实施例中,所述方法还包括对从面部动作和肢体动作两个方向对驱动动作进行解析,得到面部驱动动作和肢体驱动动作。所述面部驱动动作可以是驱动3D数字人进行头部区域的动作,例如大笑、点头、摇头等动作,面部驱动动作可以包括表情的动作以及头部区域的动作变化。所述肢体驱动动作即为驱动3D数字人进行身体区域的动作,例如跳舞、跳跃、转身等动作,肢体驱动动作可以包括肢体的运动动作以及身体整体的动作。
在得到面部驱动动作与肢体驱动动作之后,还可以将3D数字人面部的驱动与肢体的驱动分开生成,此时需要根据面部驱动动作生成3D数字人的面部驱动帧,以及根据肢体驱动动作生成3D数字人的肢体驱动帧,将面部动作与肢体动作分为两部分进行生成。
为了保持驱动视频的完整性,在一些实施例中,还可以直接根据驱动动作生成完整的3D数字人的动作驱动帧,以提高驱动视频的完整性以及提高生成驱动视频的生成效率。
在生成驱动视频的过程中,3D数字人还需要对驱动语音进行响应,因此,在生成驱动视频时,还需要获取3D数字人驱动于驱动语音时的语音驱动帧,例如,获取3D数字人对驱动语音执行反馈时的语音内容,并将上述语音内容按照时间序列分解为语音驱动帧的形式,以确保语音驱动帧能够与面部驱动帧以及肢体驱动帧相对应。
在得到语音驱动帧之后,将面部驱动帧、肢体驱动帧以及3D数字人的语音驱动帧共同驱动,此时3D数字人能够在说出对应音频的同时,作出相应的面部驱动动作以及肢体驱动动作,以得到驱动视频。
在一些实施例中,为了保证3D数字人响应驱动语音与响应驱动动作的同步,还可以对驱动语音进行分解析,得到驱动语音的播放时间序列以及驱动语音的语音帧。在得到语音帧之后,智能终端还可以按照播放时间序列对语音帧进行排序,得到语音驱动帧。
在一些实施例中,智能终端还可以对驱动语音进行语音识别,并根据语音识别的结果得到反馈文本,并将反馈文本转化为反馈语音。反馈语音需要由3D数字人进行驱动执行,因此,智能终端还可以将反馈语音进行解析,按照播放时间序列对反馈语音进行分帧处理,并将反馈语音的分帧结果作为语音驱动帧。
在一些实施例中,智能终端还可以按照播放时间序列对包含有面部驱动帧、肢体驱动帧的动作驱动帧以及语音驱动帧进行逐帧匹配,以达到3D数字人的音频与动作同步的效果。
S500:渲染所述驱动视频,得到3D数字人视频。
在本实施例中,得到驱动视频之后,智能终端需要对驱动视频进行渲染,具体的,是根据3D数字人执行驱动指令时的场景进行上色操作以及色彩调整。在一些实施例中,智能终端还可以根据3D数字人的预计场景效果来进行色彩调整。例如,当3D数字人出现在黑夜场景时,智能终端可以将3D数字人的渲染色彩进行暗度调整,当3D数字人处于阳光场景时,智能终端可以将3D数字人的渲染色彩进行亮度调整,使3D数字人能够更加接近场景的渲染效果。
在对驱动视频进行渲染之后,所得到的3D数字人视频还可以添加其他的播放效果,例如动态表情、弹幕或者互动礼物等等。在本实施例中,智能终端还可以设置播放效果的显示时间、透明度、出现位置、消失位置、出现动画以及消失动画等。
用户还可以通过输入带有目标驱动动作的人物图像来驱动3D数字人,智能终端还可以对带有目标驱动动作的人物图像进行动作解析,并通过动作迁移模型,将解析出的动作迁移至3D数字人模型上,在一些实施例中,智能终端可以通过解析视频素材,以及从视频素材中提取素材人物动作。其中,素材人物动作包括素材面部动作以及素材肢体动作。
在一些实施例中,视频素材在每一帧中,人物目标所作出的动作不同,用户可以根据自己需要的人物动作,选取制定的素材视频帧,并对素材视频帧中的人物动作进行解析,以得到素材面部动作和素材肢体动作。
如图2所示,在得到素材面部动作和素材肢体动作之后,智能终端需要将素材面部动作和素材肢体动作迁移至3D数字人模型中,使用动作迁移模型将所述素材面部动作和所述素材肢体动作迁移至所述3D数字人模型,以生成驱动视频。在本实施例中,动作迁移模型为根据所述素材人物动作生成所述3D数字人模型动作坐标的深度神经网络模型。
在生成得到3D数字人模型之后,还可以将3D重建得到的3D数字人模型与素材人物图像进行相似度比对,如果3D数字人模型与素材人物图像之间的相似度小于相似度阈值,说明3D数字人模型在生成的过程中产生的损失较大。为了提高3D数字人与素材人物图像的相似度,在一些实施例中,还可以根据人物素材图像,提取人物特征参数。其中,所述人物特征参数包括面部表情参数以及肢体参数。面部表情参数以及肢体参数能够表示素材人物图像中的人物目标的动作参数,因此可以通过根据所述面部表情参数以及所述肢体参数对所述3D数字人模型进行参数调整。
在一些实施例中,在对3D数字人进行参数调整之后,还需要再计算3D数字人模型与素材人物图像之间的相似度,再次与相似度阈值进行比对,直至相似度小于相似度阈值时,说明3D数字人模型达到输出标准,此时可以继续进行后续的驱动指令。
3D数字人的3D重建过程还可以借助于神经网络模型,在进行3D重建之前,还需要使用神经网络模型的生成器进行训练,即在一些实施例中,可以先获取样本素材,以及从样本素材中提取样本人物图像。在得到样本人物图像之后,通过解析样本人物图像,得到样本人物特征,其中,所述样本人物特征包括样本人物表情特征和样本人物体型特征,本申请通过对样本人物的表情以及体型来对待训练模型的生成器进行训练,以减少训练过程中的特征损失。
在得到样本人物表情特征和样本人物体型特征之后,将样本人物表情特征和样本人物体型特征输入至待训练模型的生成器中,以对模型进行训练。在训练的过程中,能够得到样本3D数字人模型,本申请实施例可以通过计算样本3D数字人模型的损失来判断训练收敛程度,当训练收敛程度达到收敛区间时,即可以输出生成器的当前训练参数。在本实施例中,待训练模型为根据样本人物特征生成样本3D数字人模型的神经网络模型。
如图3所示,在得到样本3D数字人模型之后,可以通过第一损失函数计算样本3D数字人模型与样本人物图像之间的相似度,以得到生成器的第一训练损失。所述第一训练损失即为样本3D数字人模型与样本素材人物之间的人脸损失。
在一些实施例中,还可以通过设置阈值的方式来判断第一训练损失是否符合生成器的输出要求,如果第一训练损失小于第一损失阈值,说明此时第一训练损失符合生成器的输出标准,可以输出当前生成器的第一训练参数。如果第一训练损失大于损失阈值,说明此时第一训练损失不符合生成器的输出标准,则对生成器进行迭代训练。
如图4所示,在一些实施例中,还可以根据样本素材提取样本人物语音,所述样本人物语音为样本素材人物在样本素材中说出的语音音频,提取样本人物语音的目的是为了对待训练模型的声音部分进行训练,以使生成的样本3D数字人模型以样本人物语音的音色进行说话。
在提取出样本人物语音之后,提取样本人物语音的语音特征,并将语音特征输入至待训练模型中,对待训练模型的声音部分进行训练。在对声音部分训练之后,还需要对待训练模型进行验证,在本实施例中,可以通过向待训练模型中输入与样本人物语音不同的样本语音,得到3D数字人音色。然后通过第二损失函数计算3D数字人音色与样本语音之间的第二训练损失,并通过第二损失阈值对第二训练损失进行校验。
如果第二训练损失小于第二损失阈值,说明第二训练损失能够达到输出标准,此时输出当前待训练模型的声音部分的第二训练参数。如果第二训练损失大于第二损失阈值,说明第二训练损失达不到输出标准,此时继续对待训练模型的声音部分进行迭代训练,直至第二训练损失小于第二损失阈值。
如图5所示,在一些实施例中,还可以根据样本人物图像,解析样本动作特征。其中,样本动作特征包括样本表情动作与样本肢体动作。然后将样本表情动作和样本肢体动作输入至待训练模型中,得到样本驱动视频。在样本驱动视频中,样本3D数字人模型同步执行样本表情动作与样本肢体动作。在得到样本驱动视频之后,还需要通过第三损失函数计算样本驱动视频中的样本人物动作与样本动作特征之间的第三训练损失。如果第三训练损失小于第三损失阈值,说明第三训练损失能够达到输出标准,此时输出当前待训练模型的第三训练参数。如果第三训练损失大于第三损失阈值,说明第三训练损失达不到输出标准,此时继续对待训练模型进行迭代训练,直至第三训练损失小于第三损失阈值。
在一些实施例中,本申请还提供了一种用于生成3D数字人视频的系统,所述系统用于执行一种用于生成3D数字人视频的方法,所述系统包括应用模块,所述应用模块被配置为执行:
S100:获取视频素材,以及从所述视频素材中提取素材人物图像.
S200:根据所述素材人物图像进行3D重建,以得到与所述素材人物图像中人物目标相关联的3D数字人模型。
S300:获取用户输入的驱动指令。
其中,所述驱动指令中包括驱动动作以及驱动语音。
S400:根据所述驱动动作以及所述驱动语音驱动所述3D数字人模型,以生成驱动视频。
S500:渲染所述驱动视频,得到3D数字人视频。
由以上技术方案可知,基于本申请提供一种用于生成3D数字人视频的方法及系统,所述方法通过获取视频素材,并从视频素材中提取素材人物图像,根据素材人物图像进行3D重建,得到与素材人物图像中的人物目标相关联的3D数字人模型。然后获取用户输入的驱动指令,根据驱动指令中的驱动动作和驱动语音驱动3D数字人,生成驱动视频,最后对驱动视频进行渲染,得到3D数字人视频。本申请通过对视频素材中的人物目标进行识别,根据人物目标建立3D数字人模型,并通过用户输入的驱动指令驱动3D数字人模型,增强用户与3D数字人之间的互动效果,提高用户的体验感。
本说明书中通篇提及的“多个实施例”、“一些实施例”、“一个实施例”或“实施例”等,意味着结合该实施例描述的具体特征,部件或特性包括在至少一个实施例中,因此,本说明书通篇出现的短语“在多个实施例中”、“在一些实施例中”、“在至少另一个实施例中”或“在实施例中”等,并不一定都指相同的实施例。此外,在一个或多个实施例中,具体特征、部件或特性可以任何合适的方式进行组合。因此,在无限制的情形下,结合一个实施例示出或描述的具体特征、部件或特性可全部或部分地与一个或多个其他实施例的特征、部件或特性进行组合。这种修改和变型旨在包括早本申请的范围之内。
本申请提供的实施例之间的相似部分相互参见即可,以上提供的具体实施方式只是本申请总的构思下的几个示例,并不构成本申请保护范围的限定。对于本领域的技术人员而言,在不付出创造性劳动的前提下依据本申请方案所扩展出的任何其他实施方式都属于本申请的保护范围。
以上所述仅是本申请的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。
- 一种视频在线生成系统及其生成方法
- 一种用于生成3D打印机线材的多通道生成装置
- 一种音视频AI算法驱动3D虚拟数字人的方法及系统
- 基于孪生工厂的水利水电建筑工程监测管理方法及系统