结合选择性边缘聚合和深度神经网络的医学图像分割方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及图像处理领域的医学图像分割技术,特别涉及一种结合选择性边缘聚合和深度神经网络的医学图像分割方法。
背景技术
医学图像分割是一个被广泛研究且具有挑战性的课题,其目的是帮助临床医生更加关注病理区域,提取医学图像的详细信息以进行更准确的诊断和分析。目前常见的医学图像分割任务包括皮肤病灶分割、腺体分割,甲状腺结节分割等。但是,由于医学图像中待分割目标尺度变化大,目标结构边界模糊和模态众多等问题,并且在实践中缺乏用于训练的高质量标记图像,使得获得准确的分割结果非常困难。
随着深度学习技术的快速发展,人们提出了许多端到端的自动分割方法并应用到了医学图像分析领域。U-Net是目前应用最广泛医学图像分割模型之一,它利用编码器学习高级语义表示,解码器恢复丢失的空间信息,并应用跳越连接融合编码器和解码器不同尺度特征以产生更准确的分割掩膜,之后也有人提出了许多改进U-Net的变体,但基于U-Net及其变体的深度学习的医学图像分割方法没有明确考虑到准确的边界预测能够产生更高质量的分割掩膜。为了解决结构边界不明确的问题,已经报告了如DeepLab、EANet等方法,这些方法通过学习像素间依赖关系以恢复边界细节。然而,它们要么需要在后处理时手动调整参数,要么需要精心设计可学习的模块去完成这项劳动密集型任务。此外,现有大多数的CNNs方法由于卷积运算中感受野的限制,无法建立期依赖关系和全局上下文联系。重复的跨步和池化操作不可避免地丢失了图像的分辨率,这使得密集预测任务具有挑战性。Transformer的出现极大地缓解了这一问题,它最早被用于自然语言处理任务,能够对距离依赖关系进行编码。虽然Transformer擅长全局上下文建模,但缺乏图像的空间信息,尤其是在捕获图像结构边界时存在局限性。这些问题使得纯Transformer在数据量较小的医学图像数据集上成功应用受到限制。
综上所述,高效地进行边界预测,融合上下文和空间特征以及在较小数据集上表现出良好的性能是医学图像分割亟待解决的关键问题。
发明内容
针对上述问题,本发明的目的在于提供一种结合选择性边缘聚合和深度神经网络的医学图像分割方法,捕获图像的全局上下文特征和浅层空间特征,使网络具有多尺度学习能力以及在不需要额外学习的情况下使网络选择并保留与边缘相关的特征。技术方案如下:
一种结合选择性边缘聚合和深度神经网络的医学图像分割方法,包括以下步骤:
步骤1:挑选公开的医学图像分割数据集,并对数据集中的训练集进行预处理;
步骤2:构建选择性边缘聚合模块使网络关注边缘划分的准确性;
步骤3:构建密集连接前馈网络实现特征重用和网络的多尺度学习能力;
步骤4:设计包括选择性边缘聚合模块和密集连接前馈网络的基于Transformer的编码器结构,保留图像全局上下文信息;
步骤5:设计基于密集连接CNN的编码器和解码器结构,提取图像局部信息和空间纹理信息;
步骤6:构建多级优化策略,同时优化编码器和解码器使其学习到边界相关信息,产生更好的特征表示;
步骤7:设计由Transformer编码器结构、基于密集连接CNN的编码器和解码器结构和多级优化策略三个部分组成的图像分割框架,完成医学图像的分割。
进一步的,所述步骤1中医学图像分割数据集为:ISIC2017、PH2、TN-SCUI 2020challenge、GLAnd segmentation和COVID-19 Infection segmentation;对数据集中的训练集进行预处理为:将ISIC2017和PH2对图像颜色进行归一化后将所有图像分辨率调整为224x224像素大小,将TN-SCUI 2020 challenge和GLAnd segmentation所有图像分辨率调整为224x224像素大小,将COVID-19 Infection segmentation所有图像分辨率调整为352x352像素大小。
更进一步的,所述步骤2具体过程如下:
步骤2.1:将任意卷积层激活后的输入特征图映射表示为:
X
其中,H和W分别为图像的高度和宽度,C表示通道数量;
步骤2.2:利用边缘提取块通过最大池化操作提取输入特征图映射X
X
其中,K表示滑动窗口大小;
步骤2.3:利用显著特征选择块设置阈值选择输入特征图映射X
①深度聚合输入特征图映射X
②计算聚合后的通道信息X
③将平均值
其中,上标(x,y)表示特定位置的坐标;x,y∈[0,1,…,H-1],[0,1,…,W-1],且X
步骤2.4:将X
步骤2.5:利用通道选择算法保留特征图M
步骤2.6:将经过分辨率缩小操作后的输入特征图映射表示为:
T
其中,H和W分别为图像的高度和宽度,C表示通道数量;
步骤2.7:利用平局池化操作聚合输入特征图T
T
其中,K表示滑动窗口大小,在本发明中K为3;
步骤2.8:将使用Sigmoid激活函数激活后的T
其中,f表示Sigmoid激活函数,C表示通道数量,c表示图像通道的索引,
步骤2.9:对X
更进一步的,所述步骤3中构建密集连接前馈网络(Dense MLP)的具体过程如下:
步骤3.1:将选择性特征聚合(SEA)模块输出的特征图映射表示为:
其中,H和W分别为图像的高度和宽度,C表示通道数量;
步骤3.2:将
步骤3.3:将
.......,
其中,MLP表示密集连接前馈网络(Dense MLP)中的某一层,M表示通道的增长率,即MLP的输出维度,在本发明中M为16。
更进一步的,所述步骤4中基于Transformer的解码器,该解码器由多个Transformer块重复连接构成,每个Transformer块包括标准化层、选择性边缘聚合(SEA)模块、密集连接前馈网络(Dense MLP)三部分组成,并且每个Transformer块前都会加入PatchEmbedding层缩小输入特征图的分辨率;处理过程如下:
步骤4.1:利用Patch Embedding层缩小输入Transformer块的特征图分辨率,主要分为以下三步完成:
①将Transformer块的输入特征图映射表示为X
②对X
③利用卷积核为1,分组数为4的分组卷积将
步骤4.2:将X
其中,
更进一步的,所述步骤5设计基于密集连接CNN的编码器和解码器结构的具体步骤包括:
步骤5.1:从编码器的第一个卷积块开始对输入特征图依次下采样两倍,最终分辨率变为(H/16,W/16);
步骤5.2:构建编码器和解码器之间进行跳跃连接的融合特征,用以下公式表示:
其中,
步骤5.3:使用一个标准卷积将级联后的通道减少为原来1/4,然后通过一系列密集连接的卷积块将通道数增加到原始通道的1/2。
更进一步的,所述步骤6构建多级优化策略的具体步骤如下:
步骤6.1:利用IoU损失计算预测结果与真实值之间的重叠误差,即目标区域损失l
其中,P表示网络的预测结果,G表示真实值,下标i表示像素的索引;
步骤6.2:用于最小化P与G之间的边界误差的边界损失通过如下步骤计算:
①利用最大池化操作提取P与G的边界P
G
P
其中,K表示滑动窗口大小,在本发明中K为3;
②利用P
其中,
步骤6.3:利用目标区域损失l
l
其中,λ
步骤6.4:对基于Transformer编码器输出的概率图P
其中,N表示Transfomer编码器中Transformer块的数量,n表示Transformer块的索引。
更进一步的,所述步骤7设计由Transformer编码器结构、基于密集连接CNN的编码器和解码器结构和多级优化策略三个部分组成的图像分割框架,完成医学图像的分割的具体过程如下:
步骤7.1:将原始图像输入基于Transformer编码器和基于密集连接CNN的编码器,利用Transformer分支捕获并保留全局上下文信息,利用CNN分支提取局部信息和空间纹理信息;
步骤7.2:通过密集连接的CNN解码器融合来自双编码器和上采样路径由低到高的多尺度特征;
步骤7.3:将Transformer编码器的输出直接扩展到目标尺寸与真实值计算损失,将密集连接的CNN解码器的输出与真实值计算损失,并以多级优化方式同时优化编码器和解码器。
采用上述技术方案带来的有益效果:
1)本发明提出了一种新颖有效的结合选择性边缘聚合和深度神经网络的医学图像分割框架来全面解决医学图像分割的难题,该框架能够处理不同模态的医学图像中尺度多样和结构边界模糊的问题,并且即使在较小的医学图像分割数据集上依然能够表现出出色的分割性能。
2)本发明设计了一个不需要额外的监督选择性边缘聚合(SEA)模块来选择性聚合边缘信息,使网络更加关注边缘划分的准确性。此外,始终采用密集连接的方式使编解码器具有较小的参数量和多尺度学习能力。
3)本发明构造了一种结合目标边缘和区域的损失函数,并采用多级优化策略同时优化编码器和解码器。这种优化方式鼓励编码器学习到更多与边界相关的信息,产生更好的特征表示。
附图说明:
图1为本发明的选择性边缘聚合模块。
图2为本发明的边缘提取块。
图3为本发明的显著特征选择块。
图4为本发明的Transformer块。
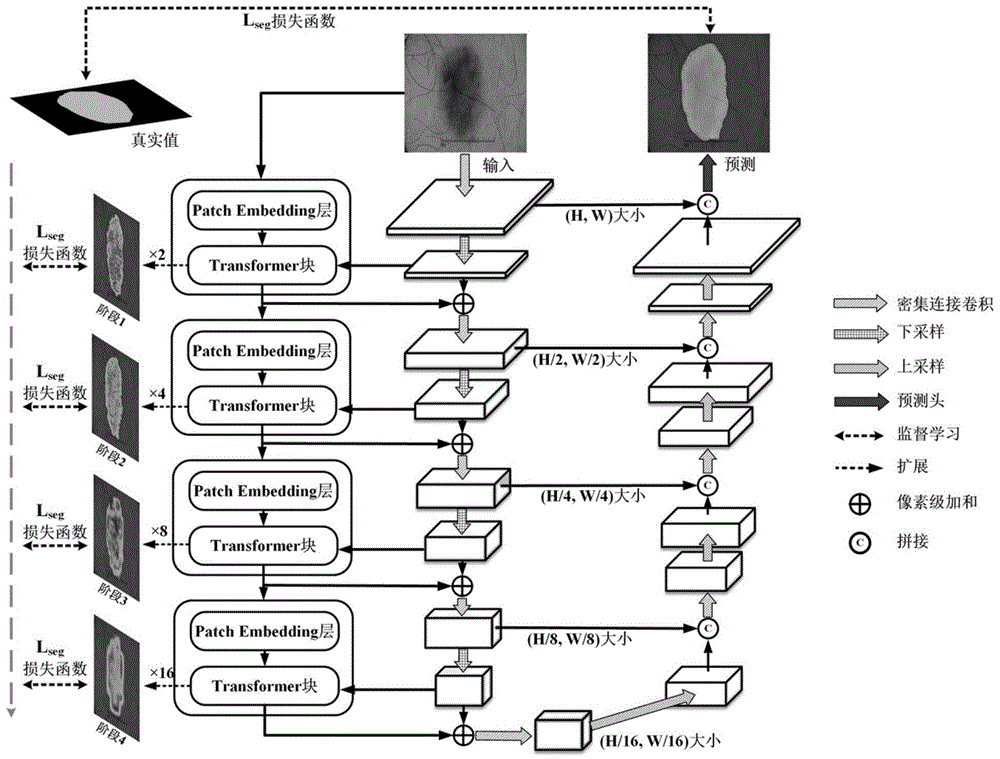
图5为本发明的结合选择性边缘聚合和深度神经网络的医学图像分割方法的流程图。
具体实施方式
下面将结合本发明中的附图,对本发明中的技术方案做进一步详细说明。
本发明设计了一种结合选择性边缘聚合和深度神经网络的医学图像分割方法。首先,以并行的方式将具有密集连接的CNN和具有密集前馈网络(Dense MLP)的Transformer结合在一起构成编码器,将密集连接的CNN作为解码器,以更深层次、多尺度的方式有效地捕获医学图像中浅层纹理信息和全局上下文信息;其次,我们提出了一种即插即用的选择性边缘聚合(SEA)模块,该模块在无监督的情况下去除噪声背景,选择并保留有用的边缘特征,使网络更加关注与目标边界相关的信息;此外,我们设计了一个结合目标内容和边缘的损失函数,并采用多级优化策略来细化模糊结构,帮助网络学习更好的特征表示,产生更准确的分割结果。
本发明在多个不同的挑战性医学分割任务中上评估了所提出的方法,与大多数最先进的方法相比表现良好,并且相比其他方法具有较少的参数量和GFlops。
步骤1:挑选公开的医学图像分割数据集,并对数据集进行预处理。
对训练集进行预处理的具体实施如下:
本发明在四个公开的医学图像分割数据集上进行分割训练任务。其中数据集分别为:ISIC2017,PH2,TN-SCUI 2020 challenge、GLAnd segmentation和COVID-19 Infectionsegmentation。
ISIC2017数据集由国际皮肤成像合作组织提供,包括2000张训练图像、150张验证图像和600张测试图像。PH2数据集包括200张皮肤镜像图像,分辨率为765×572像素,通过随机选取140幅图像作为训练集,20幅图像作为验证集,剩余的40幅图像作为测试集。首先对上述两个数据集使用灰度世界的颜色一致性算法对图像的颜色进行归一化,然后将所有图像分辨率调整到224×224像素进行实验,最后在训练过程中对训练数据增强以提高模型的泛化能力。
TN-SCUI 2020 challenge数据集提供了不同尺寸的3644张结节甲状腺图像,且结节的注释已经由经验丰富的医生进行了标注。首先将训练集、验证集和测试集划分为6:2:2。在训练过程对训练集进行日随机旋转,随机水平和垂直移位以及随机翻转等数据增强方法来增加训练数据的多样性,所有图像的分辨率统一调整为224×224像素大小。
GLAnd segmentation(GLAS)数据集包含苏木精和伊红(Hematoxylin and Eosin)染色玻片的显微图像,以及专家病理学家提供的真实值。该数据集包含165幅图像,这些图像的分辨率大小不统一,其中最小分辨率为433×574像素大小,最大分辨率为775×522像素大小。选取85幅图像用于训练,80幅图像用于测试。在实验中所有图像的分辨率调整为224×224像素大小。
COVID-19 Infection segmentation数据集包含了来自超过40名COVID-19患者的100张轴向CT图像和对应的标注图像。考虑到该数据集的数据量非常小,利用五折交叉验证进行实验(即每次使用80张图像进行训练,20张图像用于验证)。在训练时,同样采用数据增强策略来增加训练集的多样性,并且将图像统一调整为352×352像素大小。
步骤2:构建选择性边缘聚合(SEA)模块使网络关注边缘划分的准确性,该模块接收来自Transformer和CNN两个分支的特征。由于CNN能够较好地捕获分割目标的空间信息,所以用CNN分支补充Transformer分支,使两个分支实现特征融合和互补,参考图1为本发明的选择性边缘聚合模块。具体构建步骤如下:
1)将任意卷积层激活后的输入特征图映射表示为:
X
其中,H和W分别为图像的高度和宽度,C表示通道数量。
2)在CNN分支中利用边缘提取块(EEB)通过最大池化操作提取X
X
其中,K表示最大池化的滑动窗口大小,在本发明中K为3。
3)在CNN分支中利用显著特征选择块(SFS)设置阈值选择X
①深度聚合X
②计算X
③将
其中,上标(x,y)表示特定位置的坐标;x,y∈[0,1,…,H-1],[0,1,…,W-1],且X
4)将X
5)利用通道选择算法保留特征图M
6)在Transformer分支中将经过分辨率缩小操作后的输入特征图映射表示为:
T
其中,H和W分别为图像的高度和宽度,C表示通道数量。
7)利用平局池化操作聚合输入特征图T
T
其中,K表示平均池化的滑动窗口大小,在本发明中K为3。
8)将使用Sigmoid激活函数激活后的T
其中,f表示Sigmoid激活函数,C表示通道数量,c表示图像通道的索引,
9)对X
步骤3:构建Transformer块,每一个Transformer快中都包含密集连接前馈网络(Dense MLP),该密集连接前馈网络的构建使用了密集连接的方式在通道方向上应用线形层,进一步改善通道之间的信息流通,参考图4,为本发明的Transformer块。具体构建流程如下:
1)将选择性特征聚合(SEA)模块输出的特征图映射表示为:
其中,H和W分别为图像的高度和宽度,C表示通道数量。
2)将
3)将
……,
其中,MLP表示密集连接前馈网络(Dense MLP)中的某一层,M表示通道的增长率,即MLP的输出维度,在本发明中M为16。
步骤4:构建基于Transformer的解码器,该解码器由多个Transformer块重复连接构成,每个Transformer块包括标准化层、选择性边缘聚合(SEA)模块、密集连接前馈网络(Dense MLP)三部分组成,能够适应高分辨率图像,同时与CNN捕获的空间特征进行互补,并且每个Transformer块前都会加入Patch Embedding层缩小输入特征图的分辨率,使Transformer能够像CNN一样逐层扩大感受野,参考图5,本发明的结合选择性边缘聚合和深度神经网络的医学图像分割方法的流程图,其中基于Transformer的编码器即图5中“Transformer Encoder”分支。具体实施步骤如下:
1)利用Patch Embedding层缩小输入Transformer块的特征图分辨率,主要分为以下三步
完成:
①将Transformer块的输入特征图映射表示为X
②对X
③利用卷积核为1,分组数为4的分组卷积将
2)将X
其中,
步骤5:构建基于密集连接CNN的编码器和解码器,该编码器和解码器是一个U型网络,其中编码器用于提取医学图像从浅层到深层语义信息,解码器用于恢复编码器输出特征的空间分辨率。此外,应用跳跃连接从编码器和解码器获取详细信息以弥补由于下采样和卷积运算导致的信息丢失。参考图5,本发明的结合选择性边缘聚合和深度神经网络的医学图像分割方法的流程图,其中基于密集连接CNN的编码器和解码器即图5中的“CNNEncoder”和“CNN Decoder”分支。设计基于密集连接CNN的编码器和解码器结构的具体步骤包括:
1)从编码器的第一个卷积块开始对输入特征图依次下采样两倍,最终分辨率变为(H/16,W/16)。
2)构建编码器和解码器之间进行跳跃连接的融合特征,用以下公式表示:
其中,
3)使用一个标准卷积将级联后的通道减少为原来1/4,然后通过一系列密集连接的卷积块将通道数增加到原始通道的1/2。
步骤6:为了减小预测结果和真实值之间的差异,本文使用了两种损失函数分别从分割内容和分割边界两个独立的方面进行关注。第一个是IoU损失,用于最小化预测结果与真实值之间的重叠误差,第二个是边界损失,用于最小化预测结果与真实值之间的边界误差。此外,引入了多级优化策略同时优化编码器和解码器,参考图5,本发明的结合选择性边缘聚合和深度神经网络的医学图像分割方法的流程图,其中多级优化策略及图5中的“MLOStrategy”分支。设计损失函数和多级优化策略的具体步骤包括:
1)利用IoU损失计算预测结果与真实值之间的重叠误差,即目标区域损失l
其中,P表示网络的预测结果,G表示真实值,i表示P和G中所有像素的索引。
2)用于最小化P
①利用最大池化操作提取P与G的边界P
G
P
其中,K表示最大池化的滑动窗口大小,在本发明中K为3;
②利用
其中,
3)利用l
l
其中,λ
4)对基于Transformer编码器输出的概率图P
其中,N表示Transfomer编码器中Transformer块的数量,n表示Transformer块的索引。
步骤7:设计由Transformer编码器结构、基于密集连接CNN的编码器和解码器结构和多级优化策略三个部分组成的图像分割框架,参考图4为本发明的基于全分辨率表示网络的医学图像分割方法的流程图。完成医学图像的分割的具体过程如下:
1)该框架由三种模块组成:
构建包含多个Transformer块组成的基于Transformer的编码器,捕获并保留重要的全局上下文信息,本发明构建的Transformer块与不同于标准的Transformer块,在Transformer块前引入了Patch embedding层来适应高分辨率图像和密集预测任务,并且将标准Transformer块中的MSA和MLP替换为了本发明构建的选择性边缘聚合(SEA)模块和密集连接前馈网络(Dense MLP),使网络能够接受来自基于Transformer的编码器和基于密集连接CNN的编码器这两个分支的特征,实现特征融合与互补。通过基于密集连接CNN的编码器和解码器,使网络具有天然的多尺度特征提取能力,以及并行连接基于Transformer的编码器和基于密集连接CNN的编码器能够在多个级别上进行信息交互,充分利用图像的局部和全局信息,基于密集连接CNN的解码器融合了来自双编码器和上采样路径由低到高的多尺度特征,以更细粒度和更深层次的方式恢复特征图的空间分辨率。此外,设计了结合目标边缘和区域的损失函数损失,以多级优化策略同时优化编码器和解码器,使网络进一步学习更多的语义信息和边界细节,细化分割结果。
2)模型架构及超参数设置:
本发明在NVIDIA RTX3090 GPU(24g)上通过训练实现了基于Keras的方法。使用Adam优化器,学习速率固定为1e-4。mini batch size设置为16,当验证损失稳定且30个epoch内无显著变化时,采用提前停止机制停止训练。通过应用随机旋转(±25°),随机水平和垂直移位(15%)以及随机翻转(水平和垂直)来扩充训练数据。此外所有对比实验都使用相同的训练集和验证集。SEAformer CNN分支的第二个阶段之后,初始权重来自ImageNet上预训练的DenseNet121的Block2、Block3和Block4,其他层本发明从头开始训练。
3)模型评估方法
本发明使用了五个广泛使用的指标来评估模型性能。即准确率(Acc),Sensitivity(Sens),Specificity(Spec),Intersection over Union(IoU)和Dicesimilarity coefficient(Dice)。还报告了本发明的参数量,GFLOPs和FPS。
4)模型具体实施如下:
原始图像输入基于Transformer编码器和基于密集连接CNN的编码器,利用Transformer分支捕获并保留全局上下文信息,利用CNN分支提取局部信息和空间纹理信息;通过密集连接的CNN解码器融合来自双编码器和上采样路径由低到高的多尺度特征;将Transformer编码器的输出直接扩展到目标尺寸与真实值计算损失,将密集连接的CNN解码器的输出与真实值计算损失,并以多级优化方式同时优化编码器和解码器。