一种医学影像检查结果分析方法及装置
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及医学数据处理技术领域,特别是涉及一种医学影像检查结果分析方法及装置。
背景技术
随着现代科技的快速发展,医学影像处理技术越来越受到关注。医生通过医学影像的调阅和分析,能够快速、准确地确定病变位置和诊断结果,为患者提供更好的治疗方案和医疗保障。医学影像处理作为医学信息化的关键流程,对医学行业的质量和效率有着至关重要的影响,医学影像的标注作为医学影像处理的前端处理步骤,影响着后续医学图像处理质结果的好坏,因此,医学影像的数据处理可谓是医学信息化流程的重中之重。
医学影像检查是目前不可或缺的诊疗手段,通过影像检查,医生能很好的判断疾病发病部位、严重程度等,协助医生对患者做下一步的治疗。
但是,从患者角度来看,受限于专业技能和专业知识,患者并不能很好的从检查结果中获取到更多关于疾病的信息,不能很好的了解疾病的相关知识(如病因、表现、治疗手段等)。
综上所述,我们需要一种医学影像检查结果分析方法及装置,为医疗系统信息化的发展提供更优秀的技术支持和服务,帮助患者更好的了解自身病情。
发明内容
针对上述现有技术的不足,本申请提供一种医学影像检查结果分析方法及装置。
第一方面本申请提出了一种医学影像检查结果分析方法,包括以下步骤:
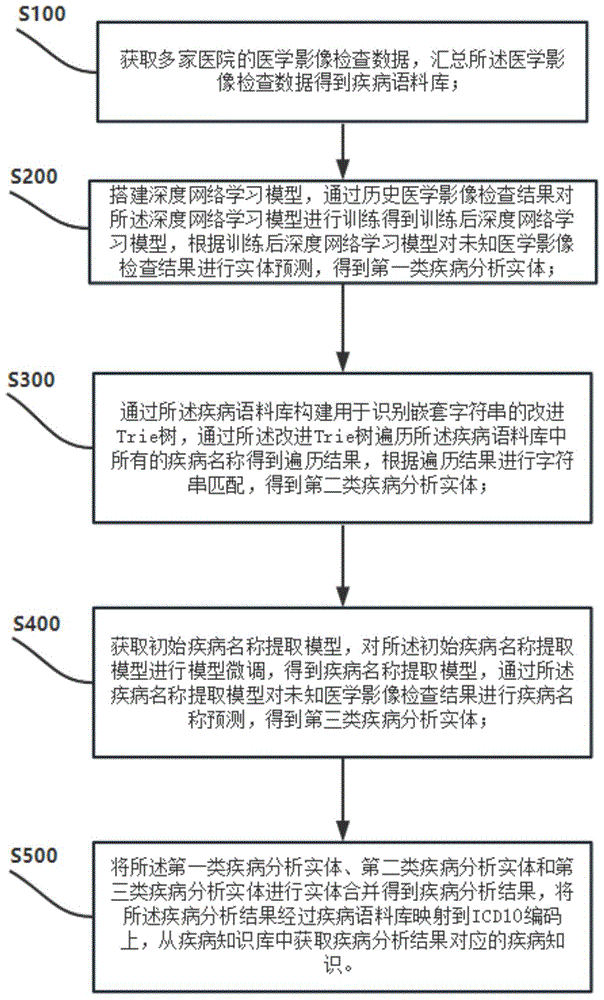
获取多家医院的医学影像检查数据,汇总所述医学影像检查数据得到疾病语料库;
搭建深度网络学习模型,通过历史医学影像检查结果对所述深度网络学习模型进行训练得到训练后深度网络学习模型,根据训练后深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体;
通过所述疾病语料库构建用于识别嵌套字符串的改进Trie树,通过所述改进Trie树遍历所述疾病语料库中所有的疾病名称得到遍历结果,根据遍历结果进行字符串匹配,得到第二类疾病分析实体;
获取初始疾病名称提取模型,对所述初始疾病名称提取模型进行模型微调,得到疾病名称提取模型,通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体;
将所述第一类疾病分析实体、第二类疾病分析实体和第三类疾病分析实体进行实体合并得到疾病分析结果,将所述疾病分析结果经过疾病语料库映射到ICD10编码上,从疾病知识库中获取疾病分析结果对应的疾病知识。
在一些实施例中,所述搭建深度网络学习模型,通过历史医学影像检查结果对所述深度网络学习模型进行训练得到训练后深度网络学习模型,根据训练后深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体,包括:
搭建的所述深度网络学习模型的模型结构包括文本编码层、多头注意力结构层、残差连接层、归一化层、前馈全连接层和线性分类层;
训练所述深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体的具体步骤为:
步骤a1:对所述历史医学影像检查结果进行实体标注得到训练数据集;
步骤a2:将所述训练数据集输入所述文本编码层得到文本向量;
步骤a3:将所述文本向量输入所述多头注意力结构层得到多头注意力向量;
步骤a4:将所述文本向量和所述多头注意力向量通过残差连接层进行残差连接得到残差连接向量;
步骤a5:将所述残差连接向量输入所述归一化层进行加速收敛得到收敛向量;
步骤a6:将所述收敛向量输入所述前馈全连接层得到前馈连接向量;
步骤a7:将所述前馈连接向量输入线性分类层得到分类向量,将所述分类向量经过反向传播获得损失函数;
步骤a8:循环执行一次步骤a2-步骤a7,在模型中加入获得的所述损失函数,最终得到训练后深度网络学习模型;
步骤a9:将所述未知医学影像检查结果输入训练后深度网络学习模型进行实体预测,得到第一类疾病分析实体。
在一些实施例中,所述通过所述疾病语料库构建用于识别嵌套字符串的改进Trie树,通过所述改进Trie树遍历所述疾病语料库中所有的疾病名称得到遍历结果,包括:
步骤b1:遍历所述疾病语料库中每一个疾病名称的每一个字符,在遍历过程中如果根节点下的子节点不存在第一子节点,则创建第一子节点,记录所述第一子节点不为字符串结束节点,如果存在第一子节点则将第一子节点标记为字符串结束标志;
步骤b2:在所述第一子节点基础上进行分析:如果所述第一子节点下的子节点不存在第二子节点,则创建第二子节点,并记录所述第二子节点不为字符串结束节点,如果存在第二子节点则将第二子节点标记为字符串结束标志;
步骤b3:在所述第二子节点基础上进行分析:如果第二子节点下的子节点不存在第三子节点,创建第三子节点,如果疾病名称遍历结束,则将第三子节点标记为字符串结束标志;如果疾病名称没有遍历结束,则返回所述步骤b1继续遍历,直至疾病名称遍历结束/出现所述字符串结束标志为止,得到遍历结果。
在一些实施例中,所述根据遍历结果进行字符串匹配,得到第二类疾病分析实体,包括:
在获取的遍历结果中进行字符串匹配,字符串匹配步骤为:
选择遍历结果中任一个影像检查结果字符,逐一检查所述影像检查结果字符是否存在对应节点下的子节点,并检查对应节点下的子节点是否为带有所述字符串结束标志的结束节点,如果存在对应的子节点并且不为所述结束节点,则对下一个影像检查结果字符进行节点检查,直到检查到的子节点为字符串的结束节点并且当前字符的下一个字符不存在对应节点下的子节点,则完成字符串匹配,根据字符串匹配的识别结果得到第二类疾病分析实体。
在一些实施例中,所述获取初始疾病名称提取模型,对所述初始疾病名称提取模型进行模型微调,得到疾病名称提取模型,通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体,包括:
步骤c1:调用LLama模型作为初始疾病名称提取模型,同时获取现有标注数据作为微调数据;
步骤c2:微调所述初始疾病名称提取模型的学习率、激活函数以及训练轮次,得到微调模型;
步骤c3:通过所述微调模型对所述微调数据进行模型预测,通过预测结果进行模型参数调整,得到疾病名称提取模型;
步骤c4:通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体。
第二方面本申请提出一种医学影像检查结果分析装置,包括疾病语料库获取模块、第一类疾病分析实体获取模块、第二类疾病分析实体获取模块、第三类疾病分析实体获取模块和疾病知识获取模块;
所述疾病语料库获取模块,用于获取多家医院的医学影像检查数据,汇总所述医学影像检查数据得到疾病语料库;
所述第一类疾病分析实体获取模块,用于搭建深度网络学习模型,通过历史医学影像检查结果对所述深度网络学习模型进行训练得到训练后深度网络学习模型,根据训练后深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体;
所述第二类疾病分析实体获取模块,用于通过所述疾病语料库构建用于识别嵌套字符串的改进Trie树,通过所述改进Trie树遍历所述疾病语料库中所有的疾病名称得到遍历结果,根据遍历结果进行字符串匹配,得到第二类疾病分析实体;
所述第三类疾病分析实体获取模块,用于获取初始疾病名称提取模型,对所述初始疾病名称提取模型进行模型微调,得到疾病名称提取模型,通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体;
所述疾病知识获取模块,用于将所述第一类疾病分析实体、第二类疾病分析实体和第三类疾病分析实体进行实体合并得到疾病分析结果,将所述疾病分析结果经过疾病语料库映射到ICD10编码上,从疾病知识库中获取疾病分析结果对应的疾病知识。
在一些实施例中,所述第一类疾病分析实体获取模块包括深度网络学习模型搭建单元和第一实体分析单元;
所述深度网络学习模型搭建单元,用于搭建所述深度网络学习模型,模型结构包括文本编码层、多头注意力结构层、残差连接层、归一化层、前馈全连接层和线性分类层;
所述第一实体分析单元,用于训练所述深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体的具体步骤为:
步骤a1:对所述历史医学影像检查结果进行实体标注得到训练数据集;
步骤a2:将所述训练数据集输入所述文本编码层得到文本向量;
步骤a3:将所述文本向量输入所述多头注意力结构层得到多头注意力向量;
步骤a4:将所述文本向量和所述多头注意力向量通过残差连接层进行残差连接得到残差连接向量;
步骤a5:将所述残差连接向量输入所述归一化层进行加速收敛得到收敛向量;
步骤a6:将所述收敛向量输入所述前馈全连接层得到前馈连接向量;
步骤a7:将所述前馈连接向量输入线性分类层得到分类向量,将所述分类向量经过反向传播获得损失函数;
步骤a8:循环执行一次步骤a2-步骤a7,在模型中加入获得的所述损失函数,最终得到训练后深度网络学习模型;
步骤a9:将所述未知医学影像检查结果输入训练后深度网络学习模型进行实体预测,得到第一类疾病分析实体。
在一些实施例中,所述第二类疾病分析实体获取模块包括第一遍历单元、第二遍历单元和第三遍历单元;
所述包括第一遍历单元,用于执行步骤b1:遍历所述疾病语料库中每一个疾病名称的每一个字符,在遍历过程中如果根节点下的子节点不存在第一子节点,则创建第一子节点,记录所述第一子节点不为字符串结束节点,如果存在第一子节点则将第一子节点标记为字符串结束标志;
所述第二遍历单元,用于步骤b2:在所述第一子节点基础上进行分析:如果所述第一子节点下的子节点不存在第二子节点,则创建第二子节点,并记录所述第二子节点不为字符串结束节点,如果存在第二子节点则将第二子节点标记为字符串结束标志;
所述第三遍历单元,用于步骤b3:在所述第二子节点基础上进行分析:如果第二子节点下的子节点不存在第三子节点,创建第三子节点,如果疾病名称遍历结束,则将第三子节点标记为字符串结束标志;如果疾病名称没有遍历结束,则返回所述步骤b1继续遍历,直至疾病名称遍历结束/出现所述字符串结束标志为止,得到遍历结果。
在一些实施例中,所述第二类疾病分析实体获取模块还包括字符串匹配单元;
所述字符串匹配单元,用于在获取的遍历结果中进行字符串匹配,字符串匹配步骤为:
选择遍历结果中任一个影像检查结果字符,逐一检查所述影像检查结果字符是否存在对应节点下的子节点,并检查对应节点下的子节点是否为带有所述字符串结束标志的结束节点,如果存在对应的子节点并且不为所述结束节点,则对下一个影像检查结果字符进行节点检查,直到检查到的子节点为字符串的结束节点并且当前字符的下一个字符不存在对应节点下的子节点,则完成字符串匹配,根据字符串匹配的识别结果得到第二类疾病分析实体。
在一些实施例中,所述第三类疾病分析实体获取模块包括第一微调单元、第二微调单元、第三微调单元和第四微调单元;
所述第一微调单元,用于执行步骤c1:调用LLama模型作为初始疾病名称提取模型,同时获取现有标注数据作为微调数据;
所述第二微调单元,用于执行步骤c2:微调所述初始疾病名称提取模型的学习率、激活函数以及训练轮次,得到微调模型;
所述第三微调单元,用于执行步骤c3:通过所述微调模型对所述微调数据进行模型预测,通过预测结果进行模型参数调整,得到疾病名称提取模型;
所述第四微调单元,用于执行步骤c4:通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体。
本发明的有益效果:
本方案以第二类疾病分析实体为主,第一类疾病分析实体和第三类疾病分析实体为辅进行实体合并,将最终合并的结果再经过疾病语料库映射到ICD10编码上,查找疾病知识库,获取疾病的相关知识,解决了患者并不能很好的从检查结果中获取到更多关于疾病的信息的问题,帮助患者更好的了解自身病情,理性看待病情,有利于患者协助医生做出有针对性的诊疗,提高诊疗效率。
附图说明
图1为本发明的总体流程图。
图2为改进Trie树的结构示意图。
图3为本发明的系统原理框图。
具体实施方式
下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制;相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
第一方面本申请提出了一种医学影像检查结果分析方法,如图1所示,包括以下步骤:
S100:获取多家医院的医学影像检查数据,汇总所述医学影像检查数据得到疾病语料库;
其中,地域不同,疾病的表达方式更是多种多样,通过处理多家医院的医学影像检查数据,最终汇总到一份20万常见疾病语料库,并且将每一种疾病映射到InternationalClassification of Diseases 10(即ICD10),部分结果展示如下表1所示:
表1:疾病语料库与ICD10部分映射表
其中,SOURCE_NAME:疾病名称;ICD10_CODE:ICD10编码;ICD10_NAME:ICD10编码对应的中文名称。
S200:搭建深度网络学习模型,通过历史医学影像检查结果对所述深度网络学习模型进行训练得到训练后深度网络学习模型,根据训练后深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体;
在一些实施例中,所述搭建深度网络学习模型,通过历史医学影像检查结果对所述深度网络学习模型进行训练得到训练后深度网络学习模型,根据训练后深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体,包括:
搭建的所述深度网络学习模型的模型结构包括文本编码层、多头注意力结构层、残差连接层、归一化层、前馈全连接层和线性分类层;
训练所述深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体的具体步骤为:
步骤a1:对所述历史医学影像检查结果进行实体标注得到训练数据集;
步骤a2:将所述训练数据集输入所述文本编码层得到文本向量;
步骤a3:将所述文本向量输入所述多头注意力结构层得到多头注意力向量;
步骤a4:将所述文本向量和所述多头注意力向量通过残差连接层进行残差连接得到残差连接向量;
步骤a5:将所述残差连接向量输入所述归一化层进行加速收敛得到收敛向量;
步骤a6:将所述收敛向量输入所述前馈全连接层得到前馈连接向量;
步骤a7:将所述前馈连接向量输入线性分类层得到分类向量,将所述分类向量经过反向传播获得损失函数;
步骤a8:循环执行一次步骤a2-步骤a7,在模型中加入获得的所述损失函数,最终得到训练后深度网络学习模型;
步骤a9:将所述未知医学影像检查结果输入训练后深度网络学习模型进行实体预测,得到第一类疾病分析实体。
其中,数据集来源:医院影像检查结果进行实体标注;
通过搭建深度网络学习模型,对标注好的数据集进行训练,模型结构如下所示:
模型结构:
1、文本编码层:包含位置编码层、token编码层和句子编码层。
文本经过文本编码层后得到E
2、E
3、残差连接层,避免梯度消失:E
4、归一化层(LayerNorm),加速收敛:X
5、前馈全连接层(Feed Forward):由两个线性层组成,第一个线性层有gelu激活函数,X
6、2个MLP,即线性分类层:X
7、向量X经过反向传播获得损失Loss,再一次循环上述的6个步骤,最终得到训练后深度网络学习模型。
进一步的,使用训练后深度网络学习模型预测未知的医学影像检查结果,获取到第一类疾病分析实体;
其中,模型预测的执行代码如下:
with torch.no_grad();
outputs = model(**inputs)//获取预测结果;
logits = outputs.logits;
predicted_class = torch.argmax(logits, dim=1).item()。
S300:通过所述疾病语料库构建用于识别嵌套字符串的改进Trie树,通过所述改进Trie树遍历所述疾病语料库中所有的疾病名称得到遍历结果,根据遍历结果进行字符串匹配,得到第二类疾病分析实体;
在一些实施例中,所述通过所述疾病语料库构建用于识别嵌套字符串的改进Trie树,通过所述改进Trie树遍历所述疾病语料库中所有的疾病名称得到遍历结果,包括:
步骤b1:遍历所述疾病语料库中每一个疾病名称的每一个字符,在遍历过程中如果根节点下的子节点不存在第一子节点,则创建第一子节点,记录所述第一子节点不为字符串结束节点,如果存在第一子节点则将第一子节点标记为字符串结束标志;
步骤b2:在所述第一子节点基础上进行分析:如果所述第一子节点下的子节点不存在第二子节点,则创建第二子节点,并记录所述第二子节点不为字符串结束节点,如果存在第二子节点则将第二子节点标记为字符串结束标志;
步骤b3:在所述第二子节点基础上进行分析:如果第二子节点下的子节点不存在第三子节点,创建第三子节点,如果疾病名称遍历结束,则将第三子节点标记为字符串结束标志;如果疾病名称没有遍历结束,则返回所述步骤b1继续遍历,直至疾病名称遍历结束/出现所述字符串结束标志为止,得到遍历结果。
其中,在获取遍历结果前,使用20万语料库构建改进Trie树;
构建改进Trie树后,执行如下步骤:
(1)遍历每一个疾病名称的每一个字符;
(2)如果根节点下的子节点不存在子节点x,创建子节点x,并记录该节点不为字符串结束节点;
(3)在节点x基础上,如果节点x下的子节点不存在子节点y,创建子节点y,并记录该节点不为字符串结束节点;
(4)在节点y基础上,如果节点y下的子节点不存在子节点z,创建子节点z,如果该疾病名称遍历结束,那么并将该节点标记为字符串结束标志;如果没有遍历结束,继续执行上述(3)步骤,直至遍历结束为止。
其中,需要注意的是,部分疾病与疾病之间存在嵌套关系,比如:十二指肠癌 和十二直肠癌伴出血。如果使用普通的tire树进行字符串匹配时,只能进行最长字符串匹配,即只能匹配到十二直肠癌伴出血,从而漏掉较短的字符串(十二指肠癌);
比如有这样一条文本:十二直肠癌Ⅲ期,使用普通的tire树匹配,是匹配不到十二直肠癌的,因为普通的tire树时,只有当该字符下没有子节点时,才会对该字符进行结束标记,因此,对于嵌套的字符串,较短字符串最后一个结束字符标记就会被构建较长字符串时修改,从而在匹配阶段不能识别到较短字符串;
因此,如图2所示,本方案在原有的tire树的基础上进行了改进,每一个字符都会做一个标记,是否是结束标记,如果不是,就用False,如果是,就用True。因此,在匹配时候,遍历文本中的每一个字符,当该字符结束标记是True,那么说明已经识别到了一个疾病,此时将该疾病提取出来。继续遍历下一个字符,如果下一个字符依旧可以匹配到,而且标记是False,继续遍历匹配,如果能匹配到更长的疾病名称,将该疾病名称提取出来,直到遍历结束为止。
在一些实施例中,所述根据遍历结果进行字符串匹配,得到第二类疾病分析实体,包括:
在获取的遍历结果中进行字符串匹配,字符串匹配步骤为:
选择遍历结果中任一个影像检查结果字符,逐一检查所述影像检查结果字符是否存在对应节点下的子节点,并检查对应节点下的子节点是否为带有所述字符串结束标志的结束节点,如果存在对应的子节点并且不为所述结束节点,则对下一个影像检查结果字符进行节点检查,直到检查到的子节点为字符串的结束节点并且当前字符的下一个字符不存在对应节点下的子节点,则完成字符串匹配,根据字符串匹配的识别结果得到第二类疾病分析实体。
其中,构建好Trie树后,在获取最长字符串过程中,遍历每一个影像检查结果字符,逐一查找该字符是否存在根节点下的子节点,并查看该子节点是否是字符串的结束节点,如果子节点存在并且不是结束节点,那么查看该字符的下一个字符是否存在该子节点下的子节点;
同上所述,直到子节点为字符串的结束节点并且当前字符的下一个字符不存在该节点下的子节点,那么该路径下字符串即为识别到的字符串(当前字符即为遍历的字符,当前节点即为Tire树中当前字符对应的节点),根据识别完成的字符串得到第二类疾病分析实体。
S400:获取初始疾病名称提取模型,对所述初始疾病名称提取模型进行模型微调,得到疾病名称提取模型,通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体;
在一些实施例中,所述获取初始疾病名称提取模型,对所述初始疾病名称提取模型进行模型微调,得到疾病名称提取模型,通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体,包括:
步骤c1:调用LLama模型作为初始疾病名称提取模型,同时获取现有标注数据作为微调数据;
步骤c2:微调所述初始疾病名称提取模型的学习率、激活函数以及训练轮次,得到微调模型;
步骤c3:通过所述微调模型对所述微调数据进行模型预测,通过预测结果进行模型参数调整,得到疾病名称提取模型;
步骤c4:通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体。
其中,训练一个专有的疾病大模型进行疾病名称提取。通用大模型可以实现疾病名称的提取,但是,在个别疾病的提取上准确度还是不够,或者达不到想要的效果。因此,在原有的通用大模型基础上进行模型微调,训练出来专门提取疾病的大模型。
1、数据构建:根据现有的标注数据,输入的是原始文本,输出的是需要提取的疾病名称,例如:
{“instruction”:”十二指肠癌伴出血”,“output”: “十二指肠癌|十二指肠癌伴出血”}
如果有多个疾病,中间用|隔开。
2、模型微调:通过使用现有开源的LLama模型,在他的基础上进行上述任务的微调。
具体步骤如下:
(1)准备微调数据,根据数据构建步骤获取微调数据;
(2)基座模型的选取和训练框架。由于微调的数据以中文为主,选用中文版的LLama2-13B模型,使用LLama提供的模型训练框架进行该任务的微调;
(3)微调学习率、激活函数以及训练轮次的设定。数据量相对较少,而且任务相对比较简单,学习率lr设置为2e-5,训练轮数为10轮。原始的LLama2模型激活函数为SwiGLU激活函数,微调阶段做下变更,使用GELU激活函数进行模型微调,主要是为了和SwiGLU激活函数做下对比。通过对比发现GELU激活函数效果与SwiGLU效果相当,对结果没有明显的影响。微调模型模式选用LoRA模式微调,冻结预训练的模型权重,并将可训练的秩分解矩阵注入Transformer架构的每一层,从而大大减少了下游任务的可训练参数的数量。
(4)模型微调结束后对微调后的模型进行模型评估和校验。选用100条未训练的文本让模型预测,人工校验预测结果并分析,通过分析结果对训练数据及微调参数进行调优,最终得到较好效果的模型。
3、模型预测:微调结束以后,使用微调后得到的疾病名称提取模型进行疾病名称预测,最终获取到识别到的疾病名,得到第三类疾病分析实体。
S500:将所述第一类疾病分析实体、第二类疾病分析实体和第三类疾病分析实体进行实体合并得到疾病分析结果,将所述疾病分析结果经过疾病语料库映射到ICD10编码上,从疾病知识库中获取疾病分析结果对应的疾病知识。
其中,将第一类疾病分析实体、第二类疾病分析实体和第三类疾病分析实体进行合并,以第二类疾病分析实体为主,第一类疾病分析实体和第三类疾病分析实体获取到的实体为辅,最终将合并的结果再经过疾病语料库进行映射,映射到ICD10编码上,查找疾病知识库,获取疾病的相关知识;
第二方面本申请提出一种医学影像检查结果分析装置,包括疾病语料库获取模块、第一类疾病分析实体获取模块、第二类疾病分析实体获取模块、第三类疾病分析实体获取模块和疾病知识获取模块;
所述疾病语料库获取模块,用于获取多家医院的医学影像检查数据,汇总所述医学影像检查数据得到疾病语料库;
所述第一类疾病分析实体获取模块,用于搭建深度网络学习模型,通过历史医学影像检查结果对所述深度网络学习模型进行训练得到训练后深度网络学习模型,根据训练后深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体;
所述第二类疾病分析实体获取模块,用于通过所述疾病语料库构建用于识别嵌套字符串的改进Trie树,通过所述改进Trie树遍历所述疾病语料库中所有的疾病名称得到遍历结果,根据遍历结果进行字符串匹配,得到第二类疾病分析实体;
所述第三类疾病分析实体获取模块,用于获取初始疾病名称提取模型,对所述初始疾病名称提取模型进行模型微调,得到疾病名称提取模型,通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体;
所述疾病知识获取模块,用于将所述第一类疾病分析实体、第二类疾病分析实体和第三类疾病分析实体进行实体合并得到疾病分析结果,将所述疾病分析结果经过疾病语料库映射到ICD10编码上,从疾病知识库中获取疾病分析结果对应的疾病知识。
在一些实施例中,所述第一类疾病分析实体获取模块包括深度网络学习模型搭建单元和第一实体分析单元;
所述深度网络学习模型搭建单元,用于搭建所述深度网络学习模型,模型结构包括文本编码层、多头注意力结构层、残差连接层、归一化层、前馈全连接层和线性分类层;
所述第一实体分析单元,用于训练所述深度网络学习模型对未知医学影像检查结果进行实体预测,得到第一类疾病分析实体的具体步骤为:
步骤a1:对所述历史医学影像检查结果进行实体标注得到训练数据集;
步骤a2:将所述训练数据集输入所述文本编码层得到文本向量;
步骤a3:将所述文本向量输入所述多头注意力结构层得到多头注意力向量;
步骤a4:将所述文本向量和所述多头注意力向量通过残差连接层进行残差连接得到残差连接向量;
步骤a5:将所述残差连接向量输入所述归一化层进行加速收敛得到收敛向量;
步骤a6:将所述收敛向量输入所述前馈全连接层得到前馈连接向量;
步骤a7:将所述前馈连接向量输入线性分类层得到分类向量,将所述分类向量经过反向传播获得损失函数;
步骤a8:循环执行一次步骤a2-步骤a7,在模型中加入获得的所述损失函数,最终得到训练后深度网络学习模型;
步骤a9:将所述未知医学影像检查结果输入训练后深度网络学习模型进行实体预测,得到第一类疾病分析实体。
在一些实施例中,所述第二类疾病分析实体获取模块包括第一遍历单元、第二遍历单元和第三遍历单元;
所述包括第一遍历单元,用于执行步骤b1:遍历所述疾病语料库中每一个疾病名称的每一个字符,在遍历过程中如果根节点下的子节点不存在第一子节点,则创建第一子节点,记录所述第一子节点不为字符串结束节点,如果存在第一子节点则将第一子节点标记为字符串结束标志;
所述第二遍历单元,用于步骤b2:在所述第一子节点基础上进行分析:如果所述第一子节点下的子节点不存在第二子节点,则创建第二子节点,并记录所述第二子节点不为字符串结束节点,如果存在第二子节点则将第二子节点标记为字符串结束标志;
所述第三遍历单元,用于步骤b3:在所述第二子节点基础上进行分析:如果第二子节点下的子节点不存在第三子节点,创建第三子节点,如果疾病名称遍历结束,则将第三子节点标记为字符串结束标志;如果疾病名称没有遍历结束,则返回所述步骤b1继续遍历,直至疾病名称遍历结束/出现所述字符串结束标志为止,得到遍历结果。
在一些实施例中,所述第二类疾病分析实体获取模块还包括字符串匹配单元;
所述字符串匹配单元,用于在获取的遍历结果中进行字符串匹配,字符串匹配步骤为:
选择遍历结果中任一个影像检查结果字符,逐一检查所述影像检查结果字符是否存在对应节点下的子节点,并检查对应节点下的子节点是否为带有所述字符串结束标志的结束节点,如果存在对应的子节点并且不为所述结束节点,则对下一个影像检查结果字符进行节点检查,直到检查到的子节点为字符串的结束节点并且当前字符的下一个字符不存在对应节点下的子节点,则完成字符串匹配,根据字符串匹配的识别结果得到第二类疾病分析实体。
在一些实施例中,所述第三类疾病分析实体获取模块包括第一微调单元、第二微调单元、第三微调单元和第四微调单元;
所述第一微调单元,用于执行步骤c1:调用LLama模型作为初始疾病名称提取模型,同时获取现有标注数据作为微调数据;
所述第二微调单元,用于执行步骤c2:微调所述初始疾病名称提取模型的学习率、激活函数以及训练轮次,得到微调模型;
所述第三微调单元,用于执行步骤c3:通过所述微调模型对所述微调数据进行模型预测,通过预测结果进行模型参数调整,得到疾病名称提取模型;
所述第四微调单元,用于执行步骤c4:通过所述疾病名称提取模型对未知医学影像检查结果进行疾病名称预测,得到第三类疾病分析实体。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。实施例中的各功能单元、模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。另外,各功能单元、模块的具体名称也只是为了便于相互区分,并不用于限制本申请的保护范围。上述系统中单元、模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本公开的范围。
在本公开所提供的实施例中,应该理解到,所揭露的装置/计算机设备和方法,可以通过其它的方式实现。例如,以上所描述的装置/计算机设备实施例仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通讯连接可以是通过一些接口,装置或单元的间接耦合或通讯连接,可以是电性,机械或其它的形式。
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本公开各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本公开实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,计算机程序可以存储在计算机可读存储介质中,该计算机程序在被处理器执行时,可以实现上述各个方法实施例的步骤。计算机程序可以包括计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读介质可以包括:能够携带计算机程序代码的任何实体或装置、记录介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、电载波信号、电信信号以及软件分发介质等。需要说明的是,计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如,在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
以上仅是本发明优选的实施方式,需指出的是,对于本领域技术人员在不脱离本技术方案的前提下,作出的若干变形和改进的技术方案应同样视为落入本权利要求书要求保护的范围。
- 一种平推式甘蔗清洗装置及其控制方法
- 一种具有机械式自锁平推闸门的信封机头装置
- 一种具有平推式机械自锁闸门板的扎把模块
- 一种平推式接物网支撑结构及其使用方法
- 一种平推式雨刷接头
- 一种平推式蒸房
- 一种平蒸式蒸养底板