一种基于文本和图像社交网络抑郁检测方法
文献发布时间:2023-06-19 10:38:35
技术领域
本发明涉及抑郁症检测领域,具体涉及一种基于文本和图像社交网络抑郁检测方法。
背景技术
目前在抑郁症检测方面有使用语音特征进行抑郁评估的方法,首先用语音采集录音模块获取测试者的语音信息,对语音信号进行预处理后获得语音的声学特征,然后使用机器学习算法进行分类。还有检测情感信息的抑郁症诊断:首先对测试者进行情绪刺激,然后采集测试者的眼部图像和面部图像,然后对该图像处理,主要关注测试者的眼睛注视点和瞳孔直径,及面部表情特征,从而识别测试者的情绪刺激,对测试者进行判断。
但是,现有的很多方法都是发现了抑郁症,然后需要测试者配合完成一些数据收集,再对数据集进行分析,判断测试者有无抑郁症。这些方法存在数据收集不便,测试方法不合理的缺点,其不能及时发现问题,更不能及时解决问题,有一定的滞后性。
发明内容
本发明的目的在于提供一种基于文本和图像社交网络抑郁检测方法,该方法无需测试者配合进行数据收集,可以方便的从网络上获得大量的数据,并且该方法考虑了用户的文本、图像、人格、用户的互相影响、用户本身的社交网络指标等多项特征,使用机器学习的方法提取特征,采用集成网络算法分类检测,能够提前发现有抑郁倾向的用户,及早对其开导起到预防的效果。
为了达到上述目的,本发明通过以下技术方案实现:
一种基于文本和图像社交网络抑郁检测方法,包含:
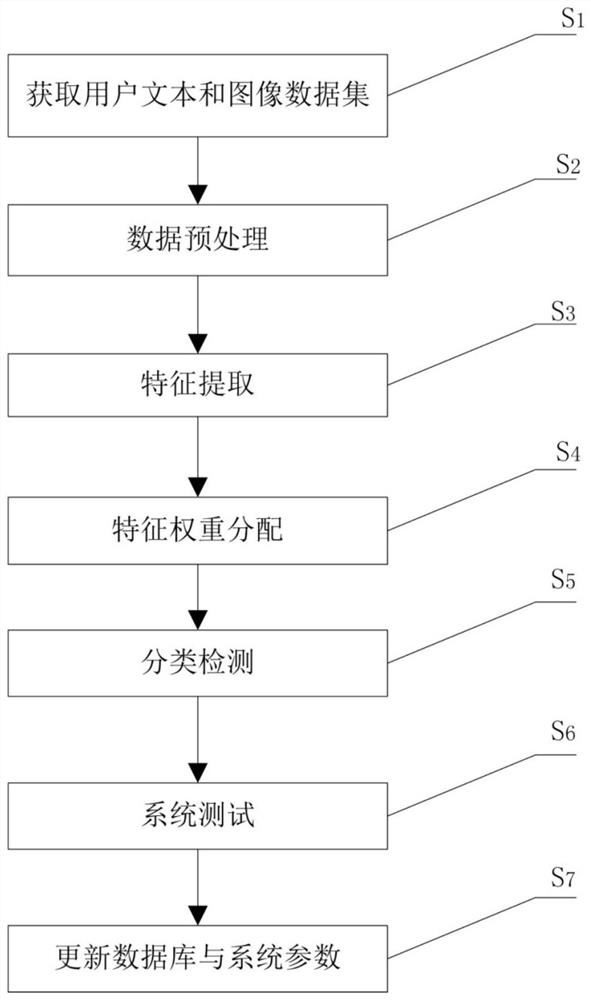
S1、获取用户文本和图像数据集,将其分为训练集和测试集;
S2、对训练集数据进行数据预处理;
S3、对经预处理后的数据进行特征提取;
S4、对步骤S3所得的数据进行特征权重分配;
S5、采用集成网络对步骤S4所得的数据进行分类检测,输出用户是否有抑郁症及其程度,以完善形成抑郁检测系统;
S6、采用测试集对所述抑郁检测系统进行测试,当测试合格时将所述抑郁检测系统投入使用,当测试不合格时,采用训练集重新对所述抑郁检测系统进行训练,直至测试合格;
S7、定期从网络上采集新数据对所述抑郁检测系统进行更新训练,当训练测试结果优于现有测试结果时,更新所述抑郁检测系统的模型参数。
可选的,所述步骤S2具体包含:
在Python中使用jieba分词对训练集中的文本数据进行分词,去停止词;
对训练集中的图像进行随机旋转、裁剪、变形、缩放以扩充数据。
可选的,所述步骤S3中,经预处理后的数据汇聚于数据集中,提取的特征包含:文本特征、网络指标、人格特征、图像特征和好友对用户的影响指标。
可选的,获取文本特征的方法包含:
基于情感词典对数据集中的文本数据进行词性标注,使用文本分析算法LICW得到文本数据中反映情感状态及各种词类的词频。
可选的,获取网络指标的方法包含:
使用Python中的统计函数提取社交网络指标,所述网络指标为辅助特征以便对用户状态进行判断,所述网络指标包含:状态总数、平均字符数、夜间活动指数、社交规模、动态频率变化,所述状态总数为数据集中每个用户的状态更新总数,所述平均字符数为用户在所有状态更新中使用的平均字符数,所述夜间活动指数为用户在夜间发布状态的活动情况,所述社交规模为用户在社交网络中的连接好友数,所述动态频率变化为用户相邻两次发布动态的时间间隔。
可选的,获取人格特征的方法包含:
将用户的文本特征作为特征输入到MLP进行分类预测,并以神经质、外倾性、经验开放性、宜人性、认真性五种人格的所占百分比作为输出。
可选的,获取图像特征的方法包含:
构建残差网络,获取用户所发动态的图片作为特征,将其送入所述残差网络中,经残差网络中的多层网络的训练输出积极图片、消极图片或其他无感情色彩的图片。
可选的,获取好友对用户的影响指标的方法包含:
由数据集得到用户之间的互动次数和用户互动的日期,由日期可以获取用户之间互动的天数,再计算得到用户之间的影响指数。
可选的,所述步骤S4具体包含:
将获得的各个特征进行融合,进行归一化处理,将归一化处理的结果送入权重分配网络中,给不同的特征赋予不同的权重。
可选的,所述步骤S5中集成网络中包含随机森林、神经网络和SVM模型;
和/或,所述步骤S5中,输出用户是否有抑郁症及其程度,当结果显示用户没有抑郁倾向,不进行任何操作;当结果显示有抑郁倾向,所述抑郁检测系统私发消息给用户,询问是否参加问卷调查以便进一步确认状态信息,并策划方案为用户进行心理疏导。
本发明与现有技术相比具有以下优点:
本发明的一种基于文本和图像社交网络抑郁检测方法,无需测试者配合进行数据收集,可以方便的从网络上获得大量的数据,考虑了用户的文本、图像、人格、用户的互相影响、用户本身的社交网络指标等多项特征,使用机器学习的方法提取特征,集成算法分类检测,能够提前发现有用户的抑郁倾向,及早对其开导以起到预防的效果。
附图说明
图1为本发明的一种基于文本和图像社交网络抑郁检测方法主要流程示意图;
图2为本发明的一种基于文本和图像社交网络抑郁检测方法详细流程示意图;
图3为本发明中使用残差网络获取图像特征示意图;
图4为本发明中权重分配网络结构图。
具体实施方式
以下结合附图,通过详细说明一个较佳的具体实施例,对本发明做进一步阐述。
如图1和图2结合所示,为本发明的一种基于文本和图像社交网络抑郁检测方法的流程示意图,该方法包含:
S1、获取用户文本和图像数据集,将其分为训练集和测试集。
在本实施例中,从社交网络获取用户数据即每次所发动态的文本和图像数据集,可选的,数据集中还包含状态发布的时间、每次和其他用户互动的内容及时间、次数等,并进行标注。将数据集分成训练集和测试集,所述测试集和训练集的内容相同,只是数量更少。
S2、对训练集数据进行数据预处理。
所述步骤S2具体包含:在Python中使用jieba分词对训练集中的文本数据进行分词,去停止词。停用词过滤中文表达中最常用的功能性词语是限定词,如“的”、“一个”、“这”、“那”等。这些词语的作用仅仅是协助一些文本的名词描述和概念表达,并没有太多的实际含义。
进一步的,对训练集中的图像进行随机旋转、裁剪、变形、缩放以扩充数据。
S3、对经预处理后的数据进行特征提取。
经预处理后的数据汇聚于数据集中,针对文本和图像数据,进行多项不同的特征提取。在本实施例中,提取的特征包含:文本特征、网络指标、人格特征、图像特征和好友对用户的影响指标。
其中,获取文本特征的方法包含:基于情感词典对数据集中的文本数据进行词性标注,使用文本分析算法LIWC进行分析,得到文本数据中反映情感状态及各种词类的词频,以得到用户的文本特征,可以体现出用户语言中的情感表达。
具体地,LIWC词库包含4个描述类别、22个语言特性类别、32个心理特性类别、7个个人化类别、3个副语言学类别以及12个标点符号类别,总计拥有80个字词类别、约4500个字词。LIWC可以精确识别语言使用中的情感表达。例如,在写积极经历时,个体更多使用积极情绪词;而写作消极经历时,更多的出现负面情绪词。同时情绪词的使用也被用作评价个体书写投入程度的指标。
获取网络指标的方法包含:使用Python中的统计函数提取社交网络指标,所述网络指标为辅助特征以便对用户状态进行判断。
所述网络指标即社交习惯包含:状态总数、平均字符数、夜间活动指数、社交规模、动态频率变化。其中,所述状态总数为数据集中每个用户的状态更新总数,其表示用户在社交网络中的活动程度。所述平均字符数为用户在所有状态更新中使用的平均字符数,其为用户参与社交网络的指标。所述夜间活动指数为用户在夜间发布状态的活动情况,其表示用户夜间活动情况,可选的,我们将一天中的6点至20点定义为白天,将20点至第二天早上6点定义为夜间。计算每个用户在白天和夜间发布的状态更新数量,并将夜间活动指数定义为夜间的帖子占总帖子的百分比。所述社交规模为用户在社交网络中的连接好友数,其表示用户参与社交网络的规模。所述动态频率变化为用户相邻两次发布动态的时间间隔,其表示用户活动习惯。
在本实施例中,使用Python中的sum函数可以统计出用户的状态总数,同样的可以统计出用户白天和夜间的发帖数量,然后进行数学计算可以得到夜间的活动指数,好友数量也可以通过sum函数求出,对于动态变化率可通过求相邻动态的发帖时间差得出。
用户人格特征可以表达他们对外部环境的反应。在本实施例中,获取人格特征的方法包含:将用户的文本特征作为特征输入到MLP(多重感知器)进行分类预测,并以神经质、外倾性、经验开放性、宜人性、认真性五种人格的所占百分比作为输出。
获取图像特征的方法包含:构建残差网络进行识别和分类,具体地,获取用户所发动态的图片作为特征,将其送入所述残差网络中,经残差网络中的多层网络的训练输出积极图片、消极图片或其他无感情色彩的图片。
如图3所示,在本实施例中,所述残差网络包含输入层、多个残差块进行堆叠、全连接层、输出层。首先构造基本残差块,残差块有两个3×3卷积组成,再添加快捷链接所构成,整个残差网络由基本残差块叠而成,最后一层为全连接层进行输出。所获取的用户图像进行多层卷积运算后,可以提取到图像的高维特征用于图像分类,在本实施例中,可以分为积极、消极和其他三类。
获取好友对用户的影响指标的方法包含:由数据集得到用户之间的互动次数和用户互动的日期,由日期可以获取用户之间互动的天数,通过用户互动情况计算得到用户之间的影响指数。
在本实施例中,原始互动分C=1,原始互动指数D=1.5,他们之间每互动一次C加0.1分,每互动一天则D加0.1分,用户之间的影响指数为:
INF=F(W
其中,W
权重需要网络自己学习。用户U有i个影响者[N1,N2...Ni],影响者的分数由高到低进行排序,其中I=0为不抑郁,I=1为抑郁,第i个影响者Ni对用户U的影响可能性为:
我们选取前15名影响者的影响分数作为他人对用户的影响指数之和为:
SCORE=∑(P(U|Ni)) (3)。
S4、对步骤S3所得的数据进行特征权重分配。
所述步骤S4具体包含:将获得的各个特征进行融合,进行归一化处理,将归一化处理的结果送入权重分配网络中,给不同的特征赋予不同的权重。
具体地,如图4所示,权重分配网络的构成是由全连接层、relu函数、sigmoid函数构成,可以实现权重的分配。将输入特征融合为一维向量送入到全连接层,经过relu函数加入非线性项,再经过全连接层,最后接个sigmoid生成权重,最后乘回原输入特征,完成对特征的权重分配。
S5、采用集成网络对步骤S4所得的数据进行分类检测,输出用户是否有抑郁症及其程度,以完善形成抑郁检测系统。
具体地,将步骤S4所得的数据送入到集成网络的判断模型中,判断是否有抑郁倾向。在本实施例中,判断模型包括随机森林、神经网络、SVM模型,使用这3个模型算法对最终结果进行投票决策得到最终结果,多个模型相结合,有助于减少使用单一模型造成的误差。
所述步骤S5中,输出用户是否有抑郁症及其程度具体为:当结果显示用户没有抑郁倾向,所述抑郁检测系统不进行任何操作;当结果显示有抑郁倾向,所述抑郁检测系统私发消息给用户,询问是否愿意参加问卷调查以便进一步确认状态信息,并策划方案为用户进行心理疏导,例如给用户匹配心理咨询师,根据其意愿为其进行线上或者线下的心理疏导。
S6、采用测试集对所述抑郁检测系统进行测试,当测试合格时将所述抑郁检测系统投入使用,当测试不合格时,采用训练集重新对所述抑郁检测系统进行训练,直至测试合格。
具体地,使用训练集对网络进行训练完毕后,需要使用测试集对整个网络进行测试,将测试集数据输入网络,观察测试准确率是否达到要求,如测试效果不好需要进一步进行训练,直至在测试集中达到预定的测试效果(注:预定的测试效果不确定,可由具体的使用者来确定),才能真正投入使用。
S7、定期从网络上采集新数据对所述抑郁检测系统进行更新训练,当训练测试结果优于现有测试结果时,更新所述抑郁检测系统的模型参数。
综上所述,本发明的一种基于文本和图像社交网络抑郁检测方法,从多维度进行考量,该方法通过用户的数据集获取、数据预处理、特征提取(提取用户文本特征、图像特征、社交网络指标、他人对用户的影响指数),然后对特征进行权重分配,最后输入到分类网络进行判断用户抑郁症程度,完成对用户状态的检测,当检测结果显示用户的抑郁症倾向较大时,策划对用户进行心理的咨询与疏导,及早地发现用户的心理状况。
进一步的,现在的大多数抑郁症检测的方法,都需要用户配合做一些测试进行数据采集,还有进行对实验者情绪刺激,查看其面部表情变化、瞳孔、语音等变化,进而检测是否有抑郁症,这些方法都需要实验者的认真配合才行。本发明的优点在于无需实验者参与就可以方便的从线上获取大量数据,考虑了用户的文本、图像、人格、用户的互相影响、用户本身的社交网络指标等多项特征,使用机器学习的方法提取特征,集成算法分类检测能够提前发现有抑郁的人的倾向,及早对其开导起到预防的效果。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 一种基于文本和图像社交网络抑郁检测方法
- 一种基于文本语义及层次结构的社交网络欺凌检测方法