一种基于值迭代的伺服电机智能优化控制方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明属于控制技术领域,具体涉及一种基于值迭代的伺服电机智能优化控制方法,实 现系统模型未知情况下的伺服电机最优控制。
背景技术
在以往的控制问题中,对于求解连续线性时不变系统的最优控制问题,通常通过计算代 数Raccati方程的解,比如基于特征向量的算法和数值模拟方法,LQR方法,但所有这些方 法及其在数值上有优势的变量都是离线程序,已经被证明能收敛到所需的ARE解。它们要么 在与ARE(基于特征向量和矩阵符号的算法)相关的哈密顿矩阵上操作,要么需要求解 Lyapunov方程(牛顿法)。在所有情况下,都需要一个系统的模型,并且总是需要预先的识 别过程。然而在实际中,系统建模难度大,需要花费大量的时间和精力。此外,即使模型是 可用的,基于该模型得到的状态反馈控制器也仅对实际系统动力学的模型逼近是最优的。
当受控系统的全局模型未知时,考虑应用数据驱动控制理论和方法来解决实际的控制问 题。数据驱动思想是指利用受控系统的在线和离线数据,在不需要对模型完全已知的情况下 实现系统的基于数据的预报、评价、调度、监控、诊断、决策和优化等的各种期望功能,最 早来源于计算机科学领域,于近几年出现在控制领域,仍处于萌芽阶段。目前对于伺服电机 的控制研究,更多的是采用传统的基于模型的控制方法,未能利用数据驱动思想在线实现对 系统的控制,需要对模型的完全已知,这导致需要花费大量的时间建模,同时可能存在模型 不匹配、未建模动态等问题。
发明内容
为了克服现有方法存在不足,本发明提供一种基于值迭代的伺服电机智能优化控制方法, 该方法提出了一种基于自适应值迭代算法,将ADP和智能优化控制系统理论的概念结合起来, 提出了一种新的ADP技术,它能以时间向前的方式解决具有部分未知动力学(即系统矩阵A 指定的内部动力学)的线性系统的连续时间无限时域最优控制问题。根据测量控制器性能的 信号序列更新控制器参数,利用更新控制策略和值函数估计的迭代过程,以使它们更接近最 优控制策略和相应的最优值函数。每个迭代步骤包括基于当前控制策略的值函数估计值的更 新,然后基于新的值函数估计值更新控制策略。
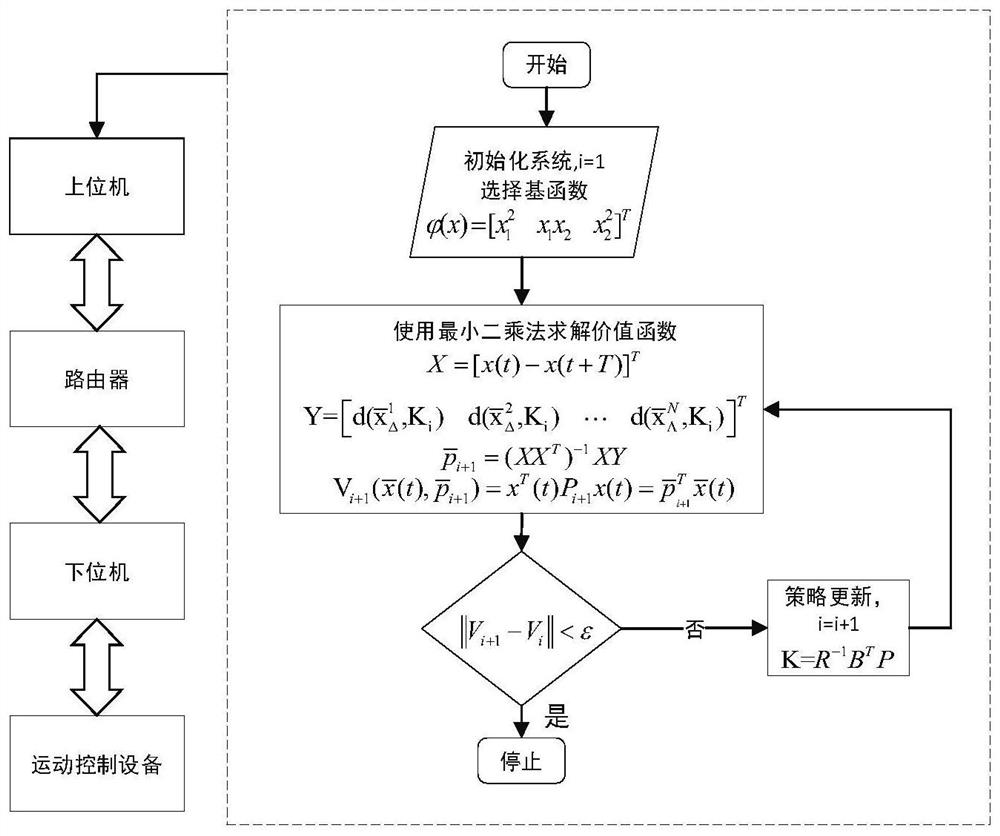
本发明所考虑的具有物理特征的实体对象(网络化多轴运动控制系统)如图1所示,其 主要由上位机、ARM微处理器、AC伺服系统、伺服电机、电源及开关和CAN总线组成。算法 编程基于Visual Studio C++环境,Visual Studio是微软(Microsoft)为以Windows为主的平台开发的一套功能强大的IDE(集成开发环境),支持C#、F#、VB、C/C++等多种语言 的开发。其中,上位机主要的工作是通过TCP/IP协议接收来自ARM微处理器的数据,并运行 内嵌的控制算法,随后发送控制指令至ARM微处理器。ARM微处理器作为数据的中转站,通 过CAN总线从伺服系统中获得伺服电机的速度、位置、力矩等信息,并将这些信息传输给上 位机,同时接收上位机的控制指令并将其下发至伺服系统。AC伺服系统具体型号为台达ASDA-A2系列的高性能通讯型伺服驱动器,其作用是实时响应PC机的控制指令,驱动伺服电机执行相应的动作,电源及开关则负责系统的上电断电。
本发明解决其技术问题所采用的技术方案是:
一种基于值迭代的伺服电机智能优化控制方法,包括以下步骤:
步骤1)建立一个电机系统状态空间方程如下:
其中,A为系统状态矩阵,部分参数未知,其中的信息由当前状态x(t)和下一时刻x(t+T) 获得,B为输入矩阵,x(t)∈R
有限域最优控制问题为:
选取Q=1,R=1,(A,B)能控,控制器的求解由贝尔曼最优原理确认,由u=-Kx,其中 K=R
A
步骤2)对系统进行初始化处理,步骤如下:
2.1)选取基函数:对连续时间LQR,其值在状态下是二次的,
系统控制在状态下是线性的,u=-Kx,以actor神经网络(6)的基函数作为状态分量;
u
2.2)初始化系统:选择初始状态x
步骤3)对系统进行采样,并进行最小二乘法的计算,求得最优值函数,即策略评估过程; 为了得到在策略K
其中
在每个迭代步骤中,在使用相同的控制策略K
其中,X=[x(t)-x(t+T)]
测量时间t和t+T离散时刻的状态,以及在采样时间间隔内观察到的奖励:
步骤4)根据得到的最优值函数,通过贪心算法更新最优参数:
u
当最小二乘法收敛时,策略不再更新,得到最优策略。
本发明中,连续时间ADP算法由(11)和(12)之间的迭代组成。然而,使用(12)更 新控制策略(actor)需要B矩阵,这使得调整算法仅部分无模型。
本发明的工作原理如下:初始化系统,确定系统能控;对系统进行采样,使用最小二乘 法在线计算值函数进行策略评估,当取得最优值函数时使用贪心算法更新策略,最终得到最 优策略。
本发明的有益效果为:通过值迭代的自适应控制,求解最优控制策略来实现对系统进行 智能优化控制,与现有技术相比,在系统部分模型参数未知的情况下,不需要对系统进行辨 识,而是基于值迭代的自适应控制方法,在线对系统实现最优控制。
附图说明
图1是设计方法在平台运行与实现的流程图;
图2是基于值迭代自适应控制的系统输入u变化曲线;
图3是基于值迭代自适应控制的系统状态变化图;
图4是已知系统动力学模型,任意给定策略值下的系统状态变化图;
图5是基于值迭代自适应控制的转移矩阵P的变化图;
图6是基于值迭代自适应控制和任意给定策略K的性能指标变化图。
具体实施方式
为了让本方案的技术特点、目的和优点更加清晰、明朗,下面结合附图和实际实验对本 发明的技术方案作进一步描述。
参照图1-图6,一种基于值迭代的伺服电机智能优化控制方法,先初始化目标系统,选 择合适的基函数;对系统进行采样,由当前时刻状态计算下一时刻状态,在线计算最优值函 数;在得到最优值函数后,利用贪心算法更新策略,策略收敛时达到最优,不再更新,从而 实现对系统的最优控制。
本实施例的基于值迭代的伺服电机最优控制方法,包括以下步骤:
步骤1)建立一个电机系统状态空间方程如下:
其中,A为系统状态矩阵,部分参数未知,其中的信息由当前状态x(t)和下一时刻x(t+T) 获得,B为输入矩阵,x(t)∈R
有限域最优控制问题为:
选取Q=1,R=1,(A,B)能控,控制器的求解由贝尔曼最优原理确认,由u=-Kx,其中 K=R
A
步骤2)对系统进行初始化处理,步骤如下:
2.1)选取基函数:对连续时间LQR,其值在状态下是二次的,
系统控制在状态下是线性的,u=-Kx,以actor神经网络(6)的基函数作为状态分量;
u
2.2)初始化系统:选择初始状态x
步骤3)对系统进行采样,并进行最小二乘法的计算,求得最优值函数,即策略评估过程; 为了得到在策略K
其中
在每个迭代步骤中,在使用相同的控制策略K
其中,X=[x(t)-x(t+T)]
测量时间t和t+T离散时刻的状态,以及在采样时间间隔内观察到的奖励:
步骤4)根据得到的最优值函数,通过贪心算法更新最优参数:
u
当最小二乘法收敛时,策略不再更新,得到最优策略。
本实施例中,所述步骤1)中,考虑二阶电机系统如下:
其中
所述步骤2)中,实验基于值迭代的自适应控制算法,矩阵A仅用来获取采样数据,控制 算法中策略的评估与更新中不涉及矩阵A的使用。x
所述步骤3)中,任意给定某个策略,对系统进行策略评估:在给定初始策略K
所述步骤4)中,对系统进行策略提升:经过策略评估后,得到最优值函数,利用贪心 算法进行策略更新,当策略不随时间而变化时,得到最优策略,控制动作是连续时间控制, 增益在采样点处更新,变化如图2所示。
从实验结果图3来看,策略更新3次后策略收敛不在更新系统状态最终收敛于0。图4 说明通过值迭代求得的P的最终值为
在与已知动力学模型,任意给定策略K=[3 0.3]的情况下的对比中,图5、图6说明本 方法系统状态收敛更平缓快速,且过程中未出现过大超调量,在图6中的性能指标中可以发 现,本方法可以更好更快地取得最佳性能指标。
本发明提供了一种基于值迭代的伺服电机智能优化控制方法,使用值迭代的自适应控制 方法,经过策略评估和策略提升两个步骤实现在线解决系统最优控制问题,与现有技术相比, 本发明的实用性在于:不需要系统模型参数进行辨识,可以通过采集系统轨迹数据获取系统 信息,从而获得最优控制策略。
以上结合附图详细阐述了本发明的技术方案但并不局限于此,在本领域的技术人员所具 备的知识范围内,只要以本发明的构思为基础,还可以做出多种变化和改进。
- 一种基于值迭代的伺服电机智能优化控制方法
- 一种基于策略迭代的伺服电机自适应智能控制方法