一种用于城市管理的智能分类方法及其系统
文献发布时间:2023-06-19 09:44:49
技术领域
本申请涉及计算机技术领域,尤其涉及一种用于城市管理的智能分类方法及其系统。
背景技术
数据分类就是把具有某种共同属性或特征的数据归并在一起,通过其类别的属性或特征来对数据进行区别,以便方便实现数据共享和提高处理效率。但目前很多城市案件管理混乱,责、权不清,很难把城市某一案件与责权单位对应,存在数据管理效率低和处理不及时的问题。
另外,因各部门、单位和人员之间没有一个统一的、互联互通的信息化平台对数据进行统一管理,存在数据不能实时传输,实时共享,数据融合时存在大量冗余的问题。
发明内容
本申请的目的在于提供一种用于城市管理的智能分类方法及其系统,对接收到的数据进行处理和智能分类,从而提高管理效率和处理效果。
为达到上述目的,本申请提供一种用于城市管理的智能分类方法,包括如下步骤:获取至少一个粗数据;其中,每个粗数据至少包括:数据内容和基础信息;数据内容包括:视频数据、图像数据、语音数据和文字数据中的一个或多个;基础信息包括:时间信息,位置信息和账户信息;根据基础信息对获取到的粗数据进行筛选处理,获得真数据;对真数据进行优化处理,获得优化数据;根据数据内容对优化数据进行处理,获得待分类数据;根据预先构建的分类表对待分类数据进行分类,获得分类数据,并存储。
如上的,其中,根据基础信息对粗数据进行筛选处理,获得真数据的子步骤如下:利用基础信息中的账户信息进行预判断,并生成预判断结果,其中,预判断结果至少包括:账户可信度;分析预判断结果,当预判断结果小于可信度阈值,对粗数据进行核真处理,生成核真结果,其中,核真结果包括:真实和虚假,当生成的核真结果为真实时,对粗数据进行去重处理,获得真数据,当生成的核真结果为虚假时,则终止后续处理,生成警告信息并反馈;当预判结果大于或等于可信度阈值,对粗数据进行去重处理,获得真数据。
如上的,其中,生成账户可信度的公式如下:
如上的,其中,对真数据的清晰度进行处理,将获得的符合数据清晰度预设标准的数据作为优化数据。
如上的,其中,对优化数据进行处理,获得待分类数据的子步骤如下:对优化数据进行预分类,确定优化数据的类别信息,其中,类别信息至少包括:数据类别和类别个数;根据类别信息生成模型调取指令,获取执行模型;利用执行模型对优化数据进行识别处理,获得子待分类数据;对所有的子待分类数据进行综合分析,获得待分类数据。
本申请还提供一种用于城市管理的智能分类系统,包括:数据获取系统、数据处理中心和至少一个收发端;其中,数据获取系统:用于实时获取粗数据,并将粗数据上传至数据处理中心;数据处理中心:用于执行上述的用于城市管理的智能分类方法;收发端:用于访问数据处理中心的分类数据或者上传分类数据的处理结果。
如上的,其中,数据处理中心包括:获取装置、预处理系统、分类系统和存储系统;其中,获取装置:用于获取粗数据,并将粗数据发送至预处理系统;预处理系统:用于对粗数据进行处理,获得优化数据,并将优化数据发送至分类系统;分类系统:用于对优化数据进行处理,获得分类数据,并将分类数据发送至存储系统;存储系统:用于对分类数据进行存储。
如上的,其中,预处理系统包括:筛选单元和优化单元;其中,筛选单元:用于对粗数据进行筛选处理,获得真数据,并将真数据发送至优化单元;优化单元:用于对真数据进行优化处理,获得优化数据,并将优化数据发送至分类系统。
如上的,其中,分类系统包括:识别单元和分类单元;其中,识别单元:用于对优化数据进行识别处理,获得待分类数据;分类单元:用于对待分类数据进行分类,获得分类数据,并将分类数据上传至存储系统进行存储。
如上的,其中,数据获取系统包括:至少一个固定位置设置的摄像头、至少一个移动终端和至少一个子服务器。
本申请对接收到的数据进行处理和智能分类,从而提高管理效率和处理效果。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1为智能分类系统一种实施例的结构示意图;
图2为智能分类方法一种实施例的流程图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本申请提供一种用于城市管理的智能分类系统,包括:数据获取系统110、数据处理中心120和至少一个收发端130。
其中,数据获取系统110:用于实时获取粗数据,并将粗数据上传至数据处理中心。
数据处理中心120:用于执行下述的用于城市管理的智能分类方法。
收发端130:用于访问数据处理中心的分类数据或者上传分类数据的处理结果。
进一步的,数据处理中心120包括:获取装置、预处理系统、分类系统和存储系统。
其中,获取装置:用于获取粗数据,并将粗数据发送至预处理系统。
预处理系统:用于对粗数据进行处理,获得优化数据,并将优化数据发送至分类系统。
分类系统:用于对优化数据进行处理,获得分类数据,并将分类数据发送至存储系统。
存储系统:用于对分类数据进行存储。
进一步的,预处理系统包括:筛选单元和优化单元。
其中,筛选单元:用于对粗数据进行筛选处理,获得真数据,并将真数据发送至优化单元。
优化单元:用于对真数据进行优化处理,获得优化数据,并将优化数据发送至分类系统。
进一步的,分类系统包括:识别单元和分类单元。
其中,识别单元:用于对优化数据进行识别处理,获得待分类数据。
分类单元:用于对待分类数据进行分类,获得分类数据,并将分类数据上传至存储系统进行存储。
进一步的,数据获取系统110包括:至少一个固定位置设置的摄像头、至少一个移动终端和至少一个子服务器。
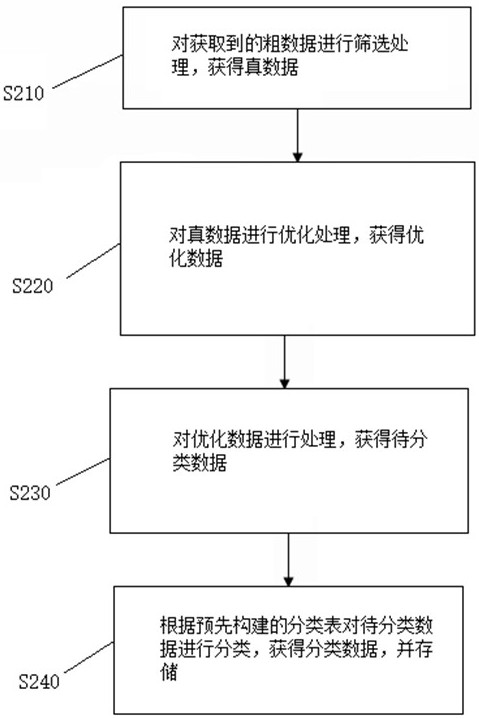
如图2所示,本申请提供一种用于城市管理的智能分类方法,包括如下步骤:
S210:对获取到的粗数据进行筛选处理,获得真数据。
进一步的,对获取到的粗数据进行筛选处理,获得真数据的子步骤如下:
S2101:获取至少一个粗数据,其中,每个粗数据至少包括:数据内容和基础信息。
具体的,通过数据获取系统获取粗数据,并将粗数据上传至数据处理中心。其中,粗数据表示数据获取系统实时采集的未经过处理的用于记录事件的原始数据。粗数据至少包括:数据内容和基础信息。
其中,数据内容包括:视频数据、图像数据、语音数据和文字数据中的一个或多个。
其中,基础信息包括:时间信息,位置信息和账户信息。
具体的,粗数据的时间信息至少包括:事件发生的时间和粗数据上传的时间。位置信息至少包括:事件发生的位置和粗数据上传的位置。账户信息至少包括:所有的历史粗数据和每个历史粗数据的真实值。其中,历史粗数据指账户除本次上传的粗数据外的所有曾经上传过的粗数据。
S2102:根据基础信息对粗数据进行筛选处理,获得真数据。
具体的,数据处理中心通过获取装置获取到粗数据后,将粗数据发送至预处理系统,由预处理系统的筛选单元进行筛选处理,获得真数据,并将真数据发送至优化单元。
进一步的,根据基础信息对粗数据进行筛选处理,获得真数据的子步骤如下:
S21021:利用基础信息中的账户信息进行预判断,并生成预判断结果,其中,预判断结果至少包括:账户可信度。
具体的,账户可信度是指根据该账户上传的所有历史粗数据的真实性所得出的用于预判断本次该账户上传粗数据的可信程度的指标。
进一步的,筛选单元中具有预先设置的预判断模型。
具体的,将粗数据输入至预判断模型,由预判断模型读取粗数据中的账号信息并计算,生成账户可信度,并将该账户可信度作为预判断结果。
进一步的,预判断模型计算账号信息,生成账户可信度的公式如下:
其中,
S21022:分析预判断结果,当预判断结果小于可信度阈值,则执行S21023;当预判结果大于或等于可信度阈值,则执行S21024。
具体的,筛选单元中具有预先设置的可信度阈值。对预判断结果进行分析,当账户可信度小于可信度阈值,表示该账号上传的粗数据存在虚假事件的可能性高,则执行S21023;当账户可信度大于或等于可信度阈值,表示该账号上传的粗数据存在虚假事件的可能性低,则执行S21024。
S21023:对粗数据进行核真处理,并生成核真结果,其中,核真结果包括:真实和虚假;当生成的核真结果为真实时,执行S21024。
具体的,核真结果包括:真实和虚假。根据粗数据的时间信息和位置信息对粗数据进行核真处理,若确认在事件发生的时间和事件发生的位置确实存在该事件,则生成的核真结果为:真实。当生成的核真结果为真实时,执行S21024。
若确认在事件发生的时间和事件发生的位置不存在该事件,则生成的核真结果为:虚假。当生成的核真结果为虚假时,则终止后续处理,生成警告信息并反馈。
S21024:对粗数据进行去重处理,获得真数据。
具体的,根据粗数据的时间信息和位置信息对粗数据进行去重处理,即根据时间信息和位置信息进行检索,若检索到时间信息中事件发生的时间和位置信息中事件发生的位置相同的由其他账户上传的粗数据,则表示存在重复粗数据,保留其中一个粗数据作为真数据,其余的则终止处理,但当该真数据处理后,生成与该真数据相同的处理结果。
若未检索到时间信息中事件发生的时间和位置信息中事件发生的位置相同的由其他账户上传的粗数据,则表示不存在重复粗数据,直接将该粗数据作为真数据。
S220:对真数据进行优化处理,获得优化数据。
具体的,筛选单元获得真数据后,将真数据发送至优化单元进行优化处理,获得优化数据,并将优化数据发送至识别单元,执行S230。
作为一个实施例,优化数据表示对真数据的清晰度进行处理,获得的符合数据清晰度预设标准的数据。
S230:对优化数据进行处理,获得待分类数据。
进一步的,根据数据内容对优化数据进行处理,获得待分类数据的子步骤如下:
S2301:对优化数据进行预分类,确定优化数据的类别信息,其中,类别信息至少包括:数据类别和类别个数。
具体的,数据类别至少包括:视频类型、图像类型、语音类型和文字类型。一个优化数据属于至少一个数据类别。
例如:若优化数据为无文字的纯图像的数据,则该优化数据仅属于图像类型,类别个数等于1。若优化数据为具有文字和图像的数据,则该优化数据既属于图像类型,也属于文字类型,类别个数等于2。若优化数据为纯文字的数据,则该优化数据属于文字类型,类别个数等于1。若优化数据为纯音频的数据,则该优化数据属于语音类型,类别个数等于1。若优化数据为无文字、无语音的纯图像组成的视频数据,则该优化数据属于视频类型,类别个数等于1。若优化数据为有文字、无音频、有图像组成的视频数据,则该优化数据属于视频类型,也属于文字类型,类别个数等于2。若优化数据为无文字、有音频、有图像组成的视频数据,则该优化数据属于视频类型,也属于语音类型,类别个数等于2。若优化数据为有文字、有音频、有图像组成的视频数据,则该优化数据属于视频类型,也属于语音类型和文字类型,类别个数等于3。
S2302:根据类别信息生成模型调取指令,获取执行模型。
进一步的,根据类别信息生成模型调取指令,获取执行模型的子步骤如下:
S23021:根据类别信息中的类别个数确定需要调取的识别模型的模型个数。
具体的,模型个数与优化数据的类别个数相等。
S23022:根据类别信息中的数据类别确定需要调取的识别模型的模型名称。
具体的,模型名称至少包括:视频识别模型、图像识别模型、和文字识别模型。视频类型对应视频识别模型,图像类型对应图像识别模型、语音类型对应语音识别模型和文字类型对应文字识别模型。
S23023:根据模型名称调取识别模型,并将调取的所有识别模型作为执行模型。
具体的,识别模型预先设置于识别单元内,根据模型名称调取识别模型。若一个优化数据仅对应一个模型名称,则直接将根据模型名称调取的识别模型作为执行模型。若一个优化数据对应多个模型名称,则将根据多个模型名称调取的多个识别模型均作为执行模型。
S2303:利用执行模型对优化数据进行识别处理,获得子待分类数据。
具体的,利用执行模型对优化数据进行识别,获得子待分类数据,其中,子待分类数据的个数等于模型个数。
进一步的,作为一个实施例,当优化数据为视频数据时,利用视频识别模型获得子待分类数据的步骤如下:
R1:对优化数据进行转换处理,获得多个子数据。
具体的,利用视频识别模型中预先设置的转换软件将优化数据按照播放顺序转换为多帧子图像,该子图像即为子数据。
R2:对所有子数据进行分割处理,获得每个子数据的子分割结果。
具体的,将子数据输入至预先训练好的第一语义分割模型中,由第一语义分割模型对子数据进行语义分割,将子数据分割为背景区域和目标区域后,再通过第一语义分割模型内的卷积神经网络模型对背景区域和目标区域进行语义识别,并将识别结果作为子分割结果。
目标区域中的目标包括:人类、机动车以及其他多个类中的一个或多个目标。背景区域:即子数据中除目标区域外的区域。
进一步的,获得子分割结果后,利用分割优化公式对子分割结果进行优化,从而得到更好的语义分割结果,其中分割优化公式如下:
其中,
R3:对所有的子分割结果进行合并处理,获得第一识别结果。
具体的,获得所有的子分割结果后,按照转换顺序对所有的子分割结果进行合并处理,获得第一识别结果。
R4:对所有子数据进行提取处理,获得每个子数据的子提取结果。
进一步的,对所有子数据进行提取处理,获得每个子数据的子提取结果的子步骤如下:
R410:对每个子数据进行计算,获得深度数据。
具体的,利用视频识别模型中预先设置的计算模型对所有的子数据进行处理,获得每个子数据的Depth(深度)数据。其中,作为一个实施例,计算模型通过对子数据进行RGB计算获得子数据的深度数据。
R420:对深度数据进行转化,获得转化数据。
进一步的,转化数据
其中,
R430:对转化数据进行分割识别,获得子提取结果。
具体的,利用第二语义分割模型对转化数据进行分割识别,将分割识别的结果作为子提取结果。
R5:对所有的子提取结果进行合并处理,获得第二识别结果。
具体的,获得所有的子提取结果后,按照转换顺序对所有的子提取结果进行合并处理,获得第二识别结果。
R6:融合第一识别结果和第二识别结果,获得优化数据的子待分类数据。
S2304:对所有的子待分类数据进行综合分析,获得待分类数据。
具体的,当处理一个优化数据,获得的子待分类数据为一个时,则直接将这一个子待分类数据作为待分类数据。当处理一个优化数据,获得的子待分类数据为多个时,对所有的子待分类数据进行综合分析,对所有子待分类数据中相同的识别内容进行去重,仅保留一个作为主干内容,将每个子待分类数据中不同的识别内容作为补入内容,并将所有补入内容与主干内容进行合并,得到一个完整的识别内容作为待分类数据。
S240:根据预先构建的分类表对待分类数据进行分类,获得分类数据,并存储。
具体的,预先构建的分类表存储于分类单元中。分类单元根据预先构建的分类表对待分类数据进行分类,获得分类数据,并将分类数据发送至存储系统,并存储。
分类表至少包括:存储语义库和存储位置。
其中,存储语义库至少包括:预先定义的存储类别,每个存储类别对应至少一个语义表,利用语义表对待分类数据进行判断,若待分类数据对应于语义表中的语义,则认为待分类数据属于该语义表,并根据语义表确定存储位置进行存储。
作为一个实施例,本申请的用于城市管理的智能分类方法和用于城市管理的智能分类系统应用于城市管理。
本申请对接收到的数据进行处理和智能分类,从而提高管理效率和处理效果。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,本申请的保护范围意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请保护范围及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 一种用于城市管理的智能分类方法及其系统
- 一种用于城市管理的智能派单系统