特定场景手语视频的翻译模型训练方法、翻译方法及系统
文献发布时间:2023-06-19 09:47:53
技术领域
本发明属于视频自然语言生成领域,应用于手语视频识别,具体涉及一种特定场景手语视频的翻译模型训练方法、翻译方法及系统。
背景技术
我国拥有约达到7200万的语言与听力障碍群体,这个群体使用手语这一工具来进行沟通交流,但手语并未在全社会得到广泛普及,当语言与听力障碍群体进行社会活动时存在诸多不便,目前的公共环境设施、产品设计等往往忽略了这一群体的特殊需求。特别是在一些公共场所诸如车站、机场、民政服务场所,对于不会手语的正常人来说,理解手语的意思是非常困难的。这种情况阻碍了人与人之间的沟通与交流,导致语言与听力障碍人群难以融入到社会中,因此使用计算机视觉技术自动识别手语一直是业界的研究热点。
近几年,随着5G和人工智能的发展,深度神经网络得到了广泛的应用,这使得计算机视觉技术实时理解手语视频有了新的解决方案。例如申请号为202010176300.0的中国专利公开了一种基于计算机视觉的手语翻译系统,该专利中其利用openpose模型对每个手语视频的数据进行处理,并获取所述关键点在视频画面中的坐标,并逐帧将画面的点坐标输出。申请号为202010243856.7的中国专利公开了一种基于BP神经网络的手语翻译方法,结合神经网络及传感技术实现了手语自动实时翻译识别,其利用树莓派3B通过可穿戴数据手套采集手势电压信号,再将每次收到的手势电压信号通过BP神经网络框架模型转换为手语词语。再如申请号为202010103960.6的中国专利公开了一种基于多层次语义解析的手语翻译系统及方法,其搭建并训练基于循环神经网络的序列转换模型,用于对所述手语动作块特征所构成的序列进行转换,得到一连串解码的单词序列,并使用联结主义时序分类模型对所述单词序列进行翻译,从而输出完整的手语自然语句。
虽然深度学习、深度强化学习等技术极大提升了视频图像序列的编码和特征提取的效率,但是手语是由一系列连贯的手势动作组成的,语言与听力障碍人士进行手语表达往往以句子为单位,表达完一个完整的长句之后才会出现停顿,因此识别手语需要对连续动态的视频图像序列进行建模,现有技术实际上是通过单帧静态图像简单地对手语视频进行词汇分类,无法对动态连续的手语进行识别,导致翻译的结果不够准确,因此有必要探索新的方法来提高手语视频翻译的准确性。
发明内容
技术问题:本发明针对现有对手语视频翻译时,翻译准确性差的问题,提供一种特定场景手语视频的翻译模型训练方法,收集特定场景的数据集,通过对手语视频翻译模型进行有效训练,得到翻译准确性高的手语视频翻译模型,并基于所训练出的手语视频翻译模型,提供一种特定场景手语视频的翻译方法及系统,从而有效地提高了手语视频翻译的准确性。
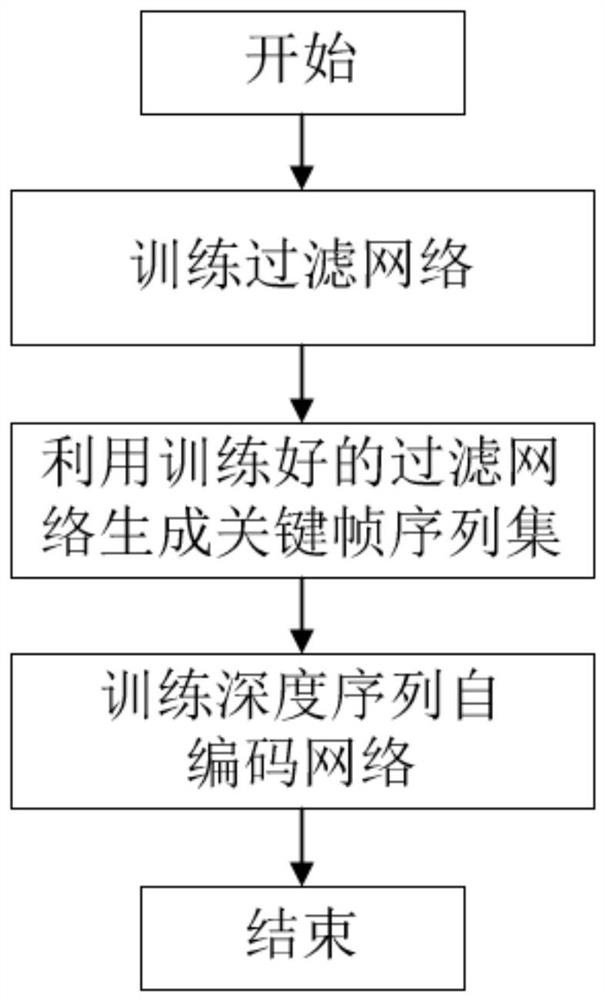
技术方案:本发明的特定场景手语视频的翻译模型训练方法中手语视频翻译模型包括过滤网络和深度序列自编码网络,首先通过构建的actor-double-critic深度强化学习训练架构对过滤网络进行训练,再利用训练好的过滤网络筛选出手语视频的关键帧序列集,最后基于深度学习对深度序列自编码网络进行训练;
训练时,训练过滤网络的方法为:
步骤1:视频的第一帧默认被选择,将视频的后续帧序列按照每间隔p帧为一组,每一组叫作空间帧子集,所有分组形成动作空间帧集合,依次输入空间帧子集作为动作空间,过滤网络依次在每组空间帧子集里选择一帧;
步骤2:将第一组空间帧子集进行灰度二值化,平展成一维向量进行拼接,将拼接后的向量作为e-状态S
步骤3:将e-状态S
步骤4:将下一组空间帧子集进行灰度二值化,平展成一维向量进行拼接,将拼接后的向量作为新的e-状态S
步骤5:将e-状态S
步骤6:将i-状态S
步骤7:计算TD误差δ
步骤8:利用新的e-状态S
进一步地,步骤4中,计算e-奖励R
定义视觉独特性指标VU,所述视觉独特性指标包括变化性指标VU
式中,VU
进一步地,计算变化性指标VU
(1)输入的动作空间帧子集,依次将每帧进行差分,得到两帧之间的帧间差分强度D
(2)将所有帧按照各自的帧间差分强度D
其中,排名前三的赋值为10,排名第四至第六的赋值为5,排名第七到第九的赋值为1,其他的赋值为0;
(3)在数据集上进行若干次随机试验,得到每训练一次数据集里的所有视频积累得到的VU
进一步地,计算差异性指标VU
(1)计算各帧之间的余弦相似度,并将余弦相似度的值赋予VU
(2)在数据集上进行若干次随机试验,得到每训练一次数据集里的所有视频积累得到的VU
进一步地,步骤4中,计算i-奖励R
定义动作轨迹相似度指标TS,采用DTW算法计算视频帧之间的轨迹相似度,并在数据集上进行若干次随机试验,得到每训练一次数据集里的所有视频积累得到的TS总和,进而得到每一次动作的平均轨迹相似度TS
利用如下公式计算R
R
进一步地,步骤5中,采用如下公式计算external critic网络的TD误差δ
δ
其中,γ表示衰减因子。
进一步地,步骤6中,采用如下公式计算internal critic网络的TD误差δ
δ
其中,γ表示衰减因子。
进一步地,步骤7中,过滤网络的损失函数L(θ
L(θ
其中,θ
进一步地,其特征在于,深度序列自编码网络包括二维卷积神经网络、第一门控循环单元、注意力机制和第二门控循环单元,训练方法为:
步骤1):将数据集输入训练好的过滤网络进行关键帧筛选,构建关键帧序列集;
步骤2):将关键帧序列输入二维卷积神经网络提取视频特征;
步骤3):利用第一门控循环单元将特征向量编码称为一个定长的语义向量;
步骤4):通过注意力机制给语义向量赋予权重;
步骤5):利用第二门控循环单元进行解码,生成手语视频内容文本;
步骤6):迭代运算直到收敛,得到训练好的深度序列自编码网络。
本发明的特定场景手语视频的翻译方法,利用所述的特定场景手语视频的翻译模型训练方法对手语视频翻译模型进行训练,包括以下步骤:
步骤A1:获取手语视频序列;
步骤A2:将手语视频序列输入训练好的过滤网络,进行关键帧筛选,得到关键帧序列;
步骤A3:将关键帧序列输入深度序列自编码网络,生成手语视频文本。
进一步地,步骤A3包括以下子步骤:
步骤A3.1:将关键帧序列输入二维神经网络中提取关键帧序列的视频特征,得到特征向量序列;
步骤A3.2:将特征向量序列输入第一门控循环单元,编码为语义向量;
步骤A3.3:利用注意力机制对语义向量进行赋权重;
步骤A3.4:将赋权重后的语义向量输入第二门控循环单元进行解码,生成手语视频内容文本。
本发明的特定场景手语视频的翻译系统,利用所述的特定场景手语视频的翻译模型训练方法对手语视频翻译模型进行训练,并利用所述的特定场景手语视频的翻译方法对手语视频进行翻译,包括:
摄像头,用于获取手语视频序列;
手语翻译模块,内置有训练好的过滤网络和深度序列自编码网络;
显示器,用于将利用手语翻译模块输出的手语视频内容文本显示输出;
语音模块,用于将手语视频内容文本语音播报。
有益效果:本发明与现有技术相比,具有以下优点:
(1)本发明中,手语视频翻译模型包括过滤网络和深度序列自编码网络,首先通过构建的actor-double-critic深度强化学习训练架构对过滤网络进行训练,再利用训练好的过滤网络筛选出手语视频的关键帧序列集,最后基于深度学习对深度序列自编码网络进行训练。在训练过滤网络时,根据行为心理学构建了actor-double-critic训练算法架构,认为深度强化学习中智能体所做出的行为不仅与外部环境给出的状态有关,还与智能体在历史当中做出选择后形成的智能体性格有关,利用该方法,训练出过滤网络,使得训练出的网络能够去除视频帧之间的时空冗余,提升了关键帧的采样效率,从而,能够更好地对手语视频帧进行筛选过滤,从而有效提高手语翻译的准确率。
(2)本发明中,在训练过滤网络时,基于“比平均水平高多少”的思想设计奖励函数,并引入视觉独特性指标和动作轨迹相似度指标用来分别生成e-奖励和i-奖励,从而解决了深度强化学习训练模型时中回报稀疏与奖励不明确的问题。
(3)本发明利用训练好的过滤网络对数据集进行筛选,生成关键帧序列集,并基于深度学习对深度序列自编码网络进行训练。训练时,将关键帧序列输入二维卷积神经网络提取视频特征,然后利用第一门控循环单元将特征向量编码称为一个定长的语义向量;并利用注意力机制给语义向量赋予权重,最后再输入到第二门控循环单元进行解码,在训练时,引入了注意力机制,从而使得训练出的深度序列自编码网络能够更加准确地对手语视频进行特征提取及语义识别,进而在应用时,提高了手语视频翻译的准确性。
(4)本发明的特定场景手语视频的翻译方法,利用所提出的特定场景手语视频的翻译模型训练方法对翻译模型进行训练,因为训练出的模型具有较高的翻译准确率,从而在进行手语视频翻译时,能够高效准确的翻译手语视频。
(5)本发明的手语视频翻译系统,利用本发明所提出的手语视频模型训练方法训练模型,并利用所提出的特定场景手语视频的翻译方法进行手语视频翻译,利用该系统,能够准确地对手语视频进行翻译。
附图说明
图1为本发明的特定场景手语视频的翻译模型训练方法的流程图;
图2为本发明中训练过滤网络的actor-double-critic深度强化学习训练架构图;
图3为本发明中训练过滤网络的流程图;
图4为本发明中训练过滤网络算法的伪代码图;
图5为本发明中深度序列自编码网络的框架图;
图6为SE-ResNeXt-50的架构图;
图7为本发明中第一门控循环单元以及第二门控循环单元的输入输出结构图;
图8为本发明中注意力机制架构图;
图9为本发明的特定场景手语视频的翻译方法具体应用的示例图。
具体实施方式
下面结合实施例和说明书附图对本发明作进一步的说明。
本发明中,手语翻译模型包括过滤网络和深度序列自编码网络,其中过滤网络用于对视频进行帧采样,从而筛选过滤出关键帧序列;深度序列自编码网络用于进行特征提取,并经过编码-解码过程完成对手语视频的翻译,生成手语视频内容文本。
本发明的实施例中,为了对模型进行训练,根据不同的公共场所构建不同的数据集,例如针对车站这一场景,借鉴了中国手语数据集CSL500,构建了车站无障碍窗口的手语数据集。数据集标注了大量词汇,如:我们,挂失,补办,身份证,车票,姐妹,保安等等,该数据集由多名参与者对每个词汇都进行多次演示。为了公平评估,选择80%参与者的数据用于训练,20%参与者的数据用于测试。
因此,本发明在训练时,如图1所示,首先手语翻译模型包括过滤网络和深度序列自编码网络,首先通过构建的actor-double-critic深度强化学习训练架构对过滤网络进行训练,再利用训练好的过滤网络筛选出手语视频的关键帧序列集,最后基于深度学习对深度序列自编码网络进行训练。
首先,对过滤网络的训练过程进行说明。
在将视频帧送入卷积神经网络之前,一般都会对视频进行帧采样,目前视频帧采样通常采用等间隔帧方法,但是不能保证选择的所有帧都包含有意义的信息,并且确定适当的间隔也是困难的,如果间隔太长,则可能会丢失一些有用的信息并导致错误的描述,如果间隔太短,由于视觉内容可能不会发生很大变化,时空冗余度高,则会产生重复的描述,因此有必要探索一种更高效的视频帧采样策略来减少时空冗余。在视频帧不断输入这样的环境下需要智能体进行判断做出行为,选择哪些帧入选特征提取的关键帧集合,因此可以将这个选择帧的过程看成一个序列决策过程,这符合深度强化学习机制,通过深度强化学习训练出过滤网络(FN,Filtration Network)。
在针对深度强化学习应用在视觉环境中奖励不明确、反馈稀疏的问题,借鉴著名德国心理学家勒温的行为心理学公式:
B=f(P·E) (1)
式(1)中,B表示个体的行为Behavior,P表示人的性格Personality,E表示环境Environment,这个公式的意思是说,一个人的行为是其人格与其当时所处情景或环境的函数。
基于此公式,本发明基于actor-critic(演员评论家)深度学习算法的思想,设计了用于训练过滤网络的actor-double-critic深度强化学习训练架构。本方法认为深度强化学习中智能体所做出的行为不仅与外部环境给出的状态有关,还与智能体在历史当中做出选择后形成的智能体性格状态有关,通过“比平均值好多少”的奖励设计理念,训练出过滤网络,去除了视频帧之间的时空冗余,提升了关键帧采样的效率。
如图2所示,给出了本发明的actor-double-critic深度强化学习训练架构,在该架构里,状态由e-状态和i-状态两部分组成,其中e-状态指的是外部环境引导的状态,i-状态指的是历史决策中形成的智能体性格状态,该框架包含actor(演员)、external critic(外部评论家)和internal critic(内部评论家)。其中actor表示策略函数P(状态,动作空间),external critic表示环境对动作的价值函数Qe(e-状态,动作),internal critic表示历史决策中形成的智能体性格对动作的价值函数Q
在本发明的方法中,actor网络即过滤网络,过滤网络、external critic网络、internal critic网络均为4个全连接层构成的网络,在发明的实施例中,学习率均为0.01,其中第一层有100个隐藏单位,第二层和第三层有200个隐藏单位,第四层有100个隐藏单位。基于图2所示框架,给出训练过滤网络的具体方法,结合图3所示,训练过滤网络包括以下步骤:
步骤1:视频的第一帧默认被选择,将视频的后续帧序列按照每间隔p帧为一组,每一组叫作空间帧子集,所有分组形成动作空间帧集合,依次输入空间帧子集作为动作空间,过滤网络依次在每组空间帧子集里选择一帧;
步骤2:将第一组空间帧子集进行灰度二值化,平展成一维向量进行拼接,将拼接后的向量作为e-状态S
步骤3:将e-状态S
步骤4:将下一组空间帧子集进行灰度二值化,平展成一维向量进行拼接,将拼接后的向量作为新的e-状态S
步骤5:将e-状态S
步骤6:将i-状态S
步骤7:计算TD误差δ
步骤8:利用新的e-状态S
说明的是,利用该方法对过滤网络训练时,初始化状态时,选择的是每个视频的首帧作为第一帧关键帧,而在训练过程中,选择的关键帧均是智能体通过学习决策产生的,例如在本发明的一个实施例中,p取24,如果一个视频是96帧,默认第1帧被选择,剩下的95帧被分成4段,从每一段会选择1帧,最后会从这个视频中选择出5个关键帧。在步骤2中,二维卷积神经网络可采用ResNeXt-101、Inception-V3、VGG-19、Inception-V4、InceptionResNetV2、SE-ResNeXt-50等,在本发明的优选实施例中,采用的是SE-ResNeXt-50。
研究更丰富的奖励设计来解决深度强化学习中回报稀疏与奖励不明确的问题在视觉环境中使用深度强化学习存在着一个困难,因为只有少数动作产生非零的回报结果,这导致回报是稀疏的。此外,奖励是不明确并且难以设计的,因为计算机视觉环境不像标准的强化学习模型,可以轻易地通过现有状态与期望达到目标之间进行对比的核心思想进行奖励设计,在视频描述这一课题中,反而是相反的,知道现有模型能达到的分数,但是希望能提高这一分数,但是这一分数能提高到多少并不知晓。
本发明的实施例中,在训练时,采取“比平均水平高多少”这一核心思想来设计奖励函数e-奖励R
因此,步骤4中,计算e-奖励R
定义视觉独特性指标VU(Visual Uniqueness),该指标是由外部环境输入而产生的,因为手语翻译模型要求关键帧集合里的所有帧在视觉上具有独特性,联合起来能代表整个视频,因此视觉独特性指标VU包括两个指标,分别为变化性指标VU
VU=(VU
其中,变化性指标VU
(1)读取视频后,输入动作空间帧子集,依次将每帧进行差分,得到两帧之间的帧间差分强度D
具体的,记一个视频的总帧数为n,动作空间帧子集一共是n/p个,第q帧和第q-1帧图像的对应像素点的灰度值记为g
(2)将所有帧按照各自的帧间差分强度D
其中,排名前三的赋值为10,排名第四至第六的赋值为5,排名第七到第九的赋值为1,其他的赋值为0,即不在前九的赋值为0。
(3)在数据集上进行若干次随机试验,得到每训练一次数据集里的所有N个视频积累得到的VU
在本发明的实施例中,在数据集上进行了三次随机试验,从而计算VU
进一步地,差异性指标VU
(1)计算各帧之间的余弦相似度,并将余弦相似度值赋予VU
(2)在数据集上进行若干次随机试验,得到每训练一次数据集里的所有N个视频积累得到的VU
在本发明的实施例中,在数据集上进行了三次随机试验,从而得到计算VU
视觉独特性指标VU是由每次动作形成的VU
进一步地,计算i-奖励R
定义动作轨迹相似度指标,即两个不同长度时间序列之间的轨迹形状相似度。过滤网络对于每个视频的过滤决策应该是相同的,因此每个视频筛选出来的关键帧集合C的特征向量映射到空间中的轨迹形状应该是相近的,在这里使用DTW(Dynamic TimeWarping)算法来计算轨迹形状相似度,衡量两个不同长度时间序列之间的轨迹形状相似度。
具体的,假设A视频帧的特征序列映射到空间中为A={a
TS(A,B)=D(i,j)=d(a
接着在数据集上进行若干次随机试验,得到每训练一次数据集里的所有N个视频积累得到的TS总和,进而得到每一次动作的平均轨迹相似度TS
然后由于这是智能体自己做的历史决策导致的,每个动作形成一个TS,产生一个奖励函数R
R
两个critic网络使用时序差分法输出TD-误差进行联合评分传给actor网络,并使用均方差作为两个critic网络各自的损失函数,其中,external critic网络的TD误差δ
δ
式(11)中,γ表示衰减因子。
从而损失函数loss
loss
使用loss
internal critic网络的TD误差δi:
δ
式(12)中,γ表示衰减因子。
从而损失函数loss
loss
使用loss
过滤网络(即actor网络)使用联合的TD-误差作为损失函数来更新网络参数θ
L(θ
图4给出了进行过滤网络训练的伪代码,通过迭代运算,直到收敛,即得到训练好的过滤网络。
利用本发明所提的训练方法,对过滤网络进行训练,使得训练出的网络能够去除视频帧之间的时空冗余,提升了关键帧的采样效率使得过滤网络能够更加准确地对手语视频进行关键帧的过滤筛选,从而有利于提高手语视频的翻译准确性。
进一步,对深度序列自编码网络进行训练,如图5给出了深度序列自编码网络的框架,深度序列自编码网络包括二维卷积神经网络、第一门控循环单元、注意力机制和第二门控循环单元,深度序列自编码网络用于进行特征提取,并经过编码-解码过程完成对手语视频的翻译。其中,二维卷积神经网络用于对视频帧进行特征提取,产生特征向量;第一门控循环单元用于将特征向量序列编码为语义向量;注意力机制用于给语义向量赋权重;第二门控循环单元用于将赋权重后的语义向量解码,生成手语视频内容文本。
在本发明的实施例中,深度序列自编码网络中的二维卷积神经网络可以采用ResNeXt-101、Inception-V3、VGG-19、Inception-V4、InceptionResNetV2、SE-ResNeXt-50等,在本发明的优选实施例中,采用的是SE-ResNeXt-50,当然,除了所列举的二维卷积神经网络外,其他的二维卷积神经网络也可进行替代,本发明中优选SE-ResNeXt-50的目的在于,SE-ResNeXt-50具有较高的精度和运算效率。SE-ResNeXt-50的架构如图6所示。
第一门控循环单元和第二门控循环单元的结构相同,具体结构如图7所示,但二者的作用不同;对于第一门控循环单元,用于把特征向量编码成一个定长的语义向量,这个向量既包含了视频的特征信息,又包含了帧的时序信息,门控循环单元(GRU,Gate RecurrentUnit)有一个当前的输入x
对于第二门控循环单元,神经元每个时刻接受两个输入,一个是帧序列的编码v,一个是上一个生成单词的编码w
其中,w
注意力机制可以选用BahdanauAttention、LuongAttention、全局注意力机制、局部注意力机制等,在本发明的优选实施例中,选择的是BahdanauAttention,通过借鉴人类视觉的选择性注意力机制,通过在输入序列上引入权重,优先考虑存在相关信息的位置集,以生成下一个输出。
Bahdanau Attention的结构图如图8所示,给一个源句子(X
第i个单词上下文向量P
对于每个h
其中
u
u
根据深度序列自编码网络的结构,得到训练深度序列自编码网络的方法,具体为:
步骤1):将数据集输入训练好的过滤网络进行关键帧筛选,构建关键帧序列集;
步骤2):将关键帧序列输入二维卷积神经网络提取视频特征;
步骤3):利用第一门控循环单元将特征向量编码称为一个定长的语义向量;
步骤4):通过注意力机制给语义向量赋予权重;
步骤5):利用第二门控循环单元进行解码,生成手语视频内容文本;
步骤6):迭代运算直到收敛,得到训练好的深度序列自编码网络。
在具体的实施例中,由Adam优化器进行优化,训练时学习率为0.01,批量大小为32,使用规模为5的波束搜索,SE-ResNeXt-50中特征向量的维数为4096,两层门控循环单元各有1024个隐藏单元,注意力状态大小设置为1024。手语视频翻译的标签句子集合记为M=(m
其中,θ
迭代运算直到收敛,得到训练好的深度序列自编码网络,本发明训练深度序列自编码网络时,通过引入注意力机制,提高了模型的识别准确性,使得训练出的模型能够准确地对手语视频进行特征提取,从而得到准确地翻译结果。
本发明的手语模型训练方法,能够训练出翻译准确率高的手语翻译模型,从而便于在应用时,更加准确地对手语视频进行翻译。
进一步地,本发明提供一种特定场景手语视频的翻译方法,该方法利用本方的特定场景手语视频的翻译模型训练方法对手语视频翻译模型进行训练,手语视频翻译的过程包括以下步骤:
步骤A1:获取手语视频序列;
步骤A2:将手语视频序列输入训练好的过滤网络,进行关键帧序列筛选,得到关键帧序列;
步骤A3:将关键帧序列输入深度序列自编码网络,生成手语视频文本;
其中,步骤A3包括以下子步骤:
步骤A3.1:将关键帧序列输入二维神经网络中提取关键帧序列的视频特征,得到特征向量;
步骤A3.2:将特征向量输入第一门控循环单元,将特征向量编码为语义向量;
步骤A3.3:利用注意力机制对语义向量进行赋权重;
步骤A3.4:将赋权重后的语义向量输入第二门控循环单元进行解码,生成手语视频内容文本。
该翻译方法利用本发明中提供的训练方法对翻译模型进行训练,由于利用本发明的训练方法训练出的手语视频翻译模型的翻译准确率高,因此进行手语视频翻译时,使得手语翻译的准确率提高。
更进一步的,本发明提供了一种特定场景手语视频的翻译系统,该系统利用特定场景手语视频的翻译模型训练方法对手语视频翻译模型进行训练,并利用特定场景手语视频的翻译方法对手语视频进行翻译,该系统包括:摄像头,用于获取手语视频序列;
手语翻译模块,内置有训练好的过滤网络和深度序列自编码网络;
显示器,用于将利用手语翻译模块输出的翻译文本显示;
语音模块,用于手语视频内容文本语音播报,可以采用音响等设备作为语音模块。
实际应用场景中,为了保证翻译质量,可以单独设置手语视频采集区域,可将背景设置为白色背景,然后语言与听力障碍人士在白色背景区域内面对摄像头完成手语表达,摄像头采集手语视频序列,通过过滤网络筛选出关键帧序列。
如图9所示,给出了一个利用本发明的训练方法训练出翻译模型,并将训练手语翻译模型应用于手语翻译方法中,同时在所提供的翻译系统平台上,进行手语翻译的一个实际应用,在该实例中,获取的手语视频共673帧,经过过滤筛选后,得到关键帧序列共29帧,将29帧关键帧序列输入深度序列自编码网络,然后输出结果,所得结果和实际手语内容一致,也验证了本发明的方法能够准确地对手语视频进行翻译。
利用本发明所提的方案,在银行、车站、医院等特定场景中,对手语视频进行翻译时,翻译准确率得到提高,从而便于有聋哑障碍的人士与工作人员进行沟通交流。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 特定场景手语视频的翻译模型训练方法、翻译方法及系统
- 一种手语视频翻译模型的训练方法、翻译方法及系统