基于拖拽编排方式的流式数据处理系统及其处理方法
文献发布时间:2023-06-19 09:49:27
技术领域
本发明涉及一种数据处理系统及其处理方法,尤其涉及一种基于拖拽编排方式的流式数据处理系统及其处理方法。
背景技术
目前,流式数据处理被广泛运用在大数据平台中,专门用来解决那些对于实时性要求比较高的业务问题。流处理平台已经成为大数据平台中的一个子平台。流式数据处理框架主要有三大类:Apache Storm、Spark Streaming和Apache Flink。Apache Flink是其中性能最好、架构设计最优秀的框架。
目前为止,市面上所提供的流数据处理系统一般提供两种方式来开发流数据处理的业务逻辑:上传代码文件或在线编辑SQL脚本。在流数据处理系统的建设方面,主要的研发的产品有:华为的“智能数据湖运营平台DAYU”、阿里云的“实时计算Flink版”、数澜科技“数据中台”。
流处理系统底层有强大的硬件资源做支撑,提供了对不同流处理业务的管理和运行调度的功能,开发人员只需要专注于流处理业务逻辑的开发实现,流处理业务代码的调度运行由流处理系统来完成。这些系统都是技术平台,没有扎实技术能力的用户难以使用这些平台。
目前市面上的流处理系统往往存在以下的缺点:
1.流处理框架使用门槛高。开发者必须能够熟练使用流处理框架,需要懂得流处理框架的原理、代码结构、api的使用、框架部署;还需要了解如何进行性能调优等。
2.流处理框架的学习成本高。流处理框架的学习需要相当长的一段时间。
3.非技术人员难以使用平台,无法做到脱离代码实现业务功能。
4.开发成本高,开发周期较长。
5.代码重复利用率低。
6.代码维护困难。
有鉴于上述的缺陷,本设计人,积极加以研究创新,以期创设一种基于拖拽编排方式的流式数据处理系统及其处理方法,使其更具有产业上的利用价值。
发明内容
为解决上述技术问题,本发明的目的是提供一种基于拖拽编排方式的流式数据处理系统及其处理方法。
本发明的基于拖拽编排方式的流式数据处理系统,其中:包括有用于让用户处理业务流程的组件拖拽编排工具,用于解析用户使用组件拖拽编排工具构建的流处理流程的组件流程解析模块,用于管理流处理任务运行的任务调度管理模块,用于输入数据来源管理的数据源管理模块,所述拖拽编排工具至少配置有数据输入组件、数据处理组件、数据输出组件,所述数据输入组件、数据转换组件、数据输出组件之间的数据传输通过动态数据表的形式传递。
进一步地,上述的基于拖拽编排方式的流式数据处理系统,其中,所述数据输入组件,用于用户选择流数据的来源,包括kafka输入组件、rabbitMQ输入组件;
所述数据转换组件包括:数据过滤组件、增加字段组件、字段选择组件、字段格式转换组件、字符串替换组件、数据集连接组件、数据统计组件;
所述数据输出组件,将数据保存到数据库中,包括:kafka输出组件、mysql输出组件、postgresql输出组件、人大金仓输出组件。
更进一步地,上述的基于拖拽编排方式的流式数据处理系统,其中,所述数据过滤组件,用于对数据进行过滤,将不满足条件的数据过滤掉,用户按照系统提供的数据过滤脚本规范,编写满足业务的脚本;
所述增加字段组件,用于增加新的字段,能设置新字段的名称、类型和值,新字段的值是常量、随机值和序列中的一种或是多种;
所述字段选择组件,用于选择指定的字段列表,将不需要的字段过滤掉,使用flink table api的select字段选择工具进行字段选择,通过反向选择过滤不需要的字段;
所述字段格式转换组件,用于转换字段的数据格式,使用flink table api的数据类型转换工具进行字段格式的转换;
所述字符串替换组件,用于替换字符串字段的值;使用jdk自带的字符串替换方法或者flinktableapi提供的字符串替换工具实现字符串替换;
所述数据集连接组件,用于对多个数据集进行连接操作,将多个数据集连接成一个数据集,多个数据集指的是来自不同输入组件的数据集;
所述数据统计组件,用于对数据集做统计操作,包括总量统计、平均值计算。
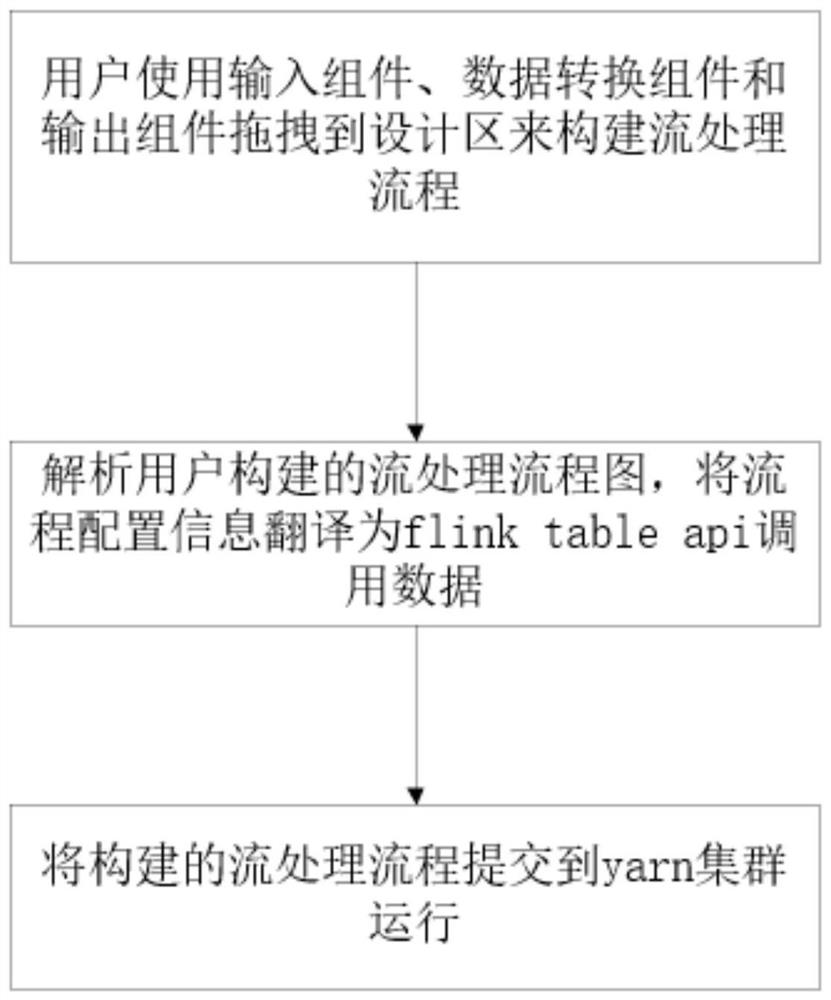
基于拖拽编排方式的流式数据处理方法,其包括以下步骤:
步骤一,将数据输入组件、数据处理组件、数据输出组件拖拽到编排面板构建流处理流程,并生成流处理任务流程的配置元数据;
步骤二,解析用户构建的流处理流程配置元数据,解析各个组件的配置、各组件之间的关系和组件的输入输出格式,通过flink的table api来实现各个组件的业务逻辑。
进一步地,上述的基于拖拽编排方式的流式数据处理方法,其中,所述步骤一中,用户选择所需的数据输入组件、一个或多个数据转换组件和数据输出组件,拖拽到编排面板,用单向箭头将组件进行衔接,形成有向无环图;
对数据输入组件、数据处理组件、数据输出组件设置需要的组件参数,设置任务运行的运行参数,最终构建完成一个完整的流处理流程。
更进一步地,上述的基于拖拽编排方式的流式数据处理方法,其中,所述元数据通过JSON格式保存。
更进一步地,上述的基于拖拽编排方式的流式数据处理方法,其中,所述解析流程为,将用户构建的流处理流程图,通过拓扑排序算法解析出任务执行的有向无环图,得到Flink执行的算子队列,根据算子队列的顺序将任务流程封装成flinktableapi的处理逻辑。
更进一步地,上述的基于拖拽编排方式的流式数据处理方法,其中,所述解析期间提供对任务执行的开启和停止功能,通过心跳机制实时监控任务运行的状态,通过api的方式对外提供日志查看的能力。
借由上述方案,本发明至少具有以下优点:
1、使用组件拖拽组装流处理流程,交互友好。
2、低代码开发,使用门槛低。用户不需要关注代码如何实现,只需要根据需设计流处理流程;流处理系统会自动将流处理流程配置信息转变成代码逻辑。
3、底层代码和上层业务解耦,底层代码具有高可重用性。
4、流处理流程可以被复用,开发效率高,迭代速度快。
5、开发成本低廉。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1是基于拖拽编排方式的流式数据处理方法的简易实施流程示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1的基于拖拽编排方式的流式数据处理系统,其与众不同之处在于:包括有用于让用户处理业务流程的组件拖拽编排工具,用于解析用户使用组件拖拽编排工具构建的流处理流程的组件流程解析模块。实施期间,组件流程解析模块会解析每个组件的配置、组件之间的关系、组件执行的顺序,并使用flink的tableapi来实现流处理流程的业务逻辑。还包括用于管理流处理任务运行的任务调度管理模块用于输入数据来源管理的数据源管理模块。并且,数据源管理模块可用于管理流处理任务的运行,将需要运行的流处理任务以JAR包的方式运行在yarn集群上,并使用yarn集群对流处理任务进行监控。拖拽编排工具至少配置有数据输入组件、数据处理组件、数据输出组件,数据输入组件、数据转换组件、数据输出组件之间的数据传输通过动态数据表的形式传递。以增加字段组件为例,输入数据是一张有a、b、c三个字段的动态表,输出数据是一张具有a、b、c、d四个字段的动态表。每个组件的输出数据作为下一个组件的输入数据。同时,输入数据源的信息是预先定义好的,本系统专门提供了数据源管理的模块,用于管理不同的数据源连接信息。用户在编辑输入组件时,只需要选择数据源管理模块中已经存在的数据源信息。然后选择需要的消息主题,并给出消息的数据结构。
结合本发明一较佳的实施方式来看,本说明采用的数据输入组件,用于用户选择流数据的来源,包括kafka输入组件、rabbitMQ输入组件。目前,流数据的主要来源是消息中间件,如kafka和rabbitMQ,用户需要选择具体的数据源、数据源的消息主题。
kafka和rabbitMQ输入的消息示例如下:
同时,数据转换组件包括:数据过滤组件、增加字段组件、字段选择组件、字段格式转换组件、字符串替换组件、数据集连接组件、数据统计组件。并且,通过数据输出组件将数据保存到数据库中。具体来说,采用的数据输出组件包括:kafka输出组件、mysql输出组件、postgresql输出组件、人大金仓输出组件。再者,为了支持更多的输出数据源,需要扩展flink支持的输出数据源,通过java实现新的数据源输出工具。
具体来说,数据过滤组件,用于对数据进行过滤,将不满足条件的数据过滤掉,用户按照系统提供的数据过滤脚本规范,编写满足业务的脚本。统获取到用户编写的脚本后,会将脚本解析,并转换成代码逻辑。
增加字段组件,用于增加新的字段,能设置新字段的名称、类型和值,新字段的值是常量、随机值和序列中的一种或是多种也可以是其他新增数值。
字段选择组件,用于选择指定的字段列表,将不需要的字段过滤掉,使用flinktable api的select字段选择工具进行字段选择,通过反向选择过滤不需要的字段。
字段格式转换组件,用于转换字段的数据格式,使用flink table api的数据类型转换工具进行字段格式的转换。
字符串替换组件,用于替换字符串字段的值。使用jdk自带的字符串替换方法或者flinktableapi提供的字符串替换工具实现字符串替换。
数据集连接组件,用于对多个数据集进行连接操作,将多个数据集连接成一个数据集,多个数据集指的是来自不同输入组件的数据集。实际实施期间,首先将多个数据集定义为多张动态表,使用表连接工具讲多张动态表连接在一起。
数据统计组件,用于对数据集做统计操作,包括总量统计、平均值计算等等。可以使用flinktableapi提供的能力来实现这些统计功能。
为了更好的实施本发明,现提供一种基于拖拽编排方式的流式数据处理方法,其包括以下步骤:
步骤一,将数据输入组件、数据处理组件、数据输出组件拖拽到编排面板构建流处理流程,并生成流处理任务流程的配置元数据;
步骤二,解析用户构建的流处理流程配置元数据,解析各个组件的配置、各组件之间的关系和组件的输入输出格式,通过flink的table api来实现各个组件的业务逻辑。
结合实际实施来看,在步骤一中,用户选择所需的数据输入组件、一个或多个数据转换组件和数据输出组件,拖拽到编排面板,用单向箭头将组件进行衔接,形成有向无环图。对数据输入组件、数据处理组件、数据输出组件设置需要的组件参数。同时,能够在实施期间可设置任务运行的运行参数,包括如内存大小,任务运行并行度等,最终构建完成一个完整的流处理流程。并且,采用的元数据通过JSON格式保存。这样,其作为一种轻量级的数据交换格式,JSON具有良好的可读性,支持跨平台,兼容性高。
考虑数据处理的便利,本发明各个组件所涉及的组件参数大致如下:对于kafka输入组件,需要配置kafka的连接信息、kafka中消息的主题、消息的分组名称、消息的格式和消息读取方式等。对于增加字段组件,需要配置增加字段的名称、字段的类型、字段取值的方式。对于mysql输出组件,需要配置mysql数据库的连接信息和数据库字段的的映射关系。其他没有特别说明的,可以遵照该组件在业内常规的默认配置进行使用。
kafka输入组件的配置参数如下:
为了更好的实施本发明,采用的解析流程大致如下:将用户构建的流处理流程图,通过拓扑排序算法解析出任务执行的有向无环图,得到Flink执行的算子队列,根据算子队列的顺序将任务流程封装成flinktableapi的处理逻辑。同时,解析期间提供对任务执行的开启和停止功能,通过心跳机制实时监控任务运行的状态,通过api的方式对外提供日志查看的能力。
同时,为了使得单个流处理任务具有较高的性能和可靠性,本发明将任务运行的方式设计为每个流处理任务单独运行,根据任务本身的业务特性自由配置资源参数。
并且,本发明将Flink流式处理逻辑封装成了可视化、可拖拽的组件,用户可以根据自己的业务需求定制流处理流程,用户将需要的组件拖拽到面板,再将其按照数据的处理流程连线,设置完毕后点击保存、运行,然后就可以时刻查看任务的运行状态,整个流程操作简便、并且高效。
通过上述的文字表述并结合附图可以看出,采用本发明后,拥有如下优点:
1、使用组件拖拽组装流处理流程,交互友好。
2、低代码开发,使用门槛低。用户不需要关注代码如何实现,只需要根据需设计流处理流程;流处理系统会自动将流处理流程配置信息转变成代码逻辑。
3、底层代码和上层业务解耦,底层代码具有高可重用性。
4、流处理流程可以被复用,开发效率高,迭代速度快。
5、开发成本低廉。
此外,本发明所描述的指示方位或位置关系,均为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或构造必须具有特定的方位,或是以特定的方位构造来进行操作,因此不能理解为对本发明的限制。
术语“主”、“副”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“主”、“副”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“若干”的含义是两个或两个以上,除非另有明确具体的限定。
同样,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“连接”、“设置”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个组件内部的连通或两个组件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。并且它可以直接在另一个组件上或者间接在该另一个组件上。当一个组件被称为是“连接于”另一个组件,它可以是直接连接到另一个组件或间接连接至该另一个组件上。
需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或组件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 基于拖拽编排方式的流式数据处理系统及其处理方法
- 基于STORM流式计算的数据处理方法和数据处理系统