运算方法、装置、计算机设备和存储介质
文献发布时间:2023-06-19 09:57:26
技术领域
本公开涉及计算机技术领域,尤其涉及一种最小池化指令处理方法、装置、计算机设备和存储介质。
背景技术
随着科技的不断发展,机器学习,尤其是神经网络算法的使用越来越广泛。其在图像识别、语音识别、自然语言处理等领域中都得到了良好的应用。但由于神经网络算法的复杂度越来越高,所涉及的数据运算种类和数量不断增大。相关技术中,在对数据进行最小池化运算的效率低、速度慢。
发明内容
有鉴于此,本公开提出了一种最小池化指令处理方法、装置、计算机设备和存储介质,以提高对数据进行最小池化运算的效率和速度。
根据本公开的第一方面,提供了一种最小池化指令处理装置,所述装置包括:
控制模块,用于对获取到的最小池化指令进行解析,得到所述最小池化指令的操作码和操作域,并根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址;
运算模块,用于根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。
根据本公开的第二方面,提供了一种机器学习运算装置,所述装置包括:
一个或多个上述第一方面所述的最小池化指令处理装置,用于从其他处理装置中获取待运算数据和控制信息,并执行指定的机器学习运算,将执行结果通过I/O接口传递给其他处理装置;
当所述机器学习运算装置包含多个所述最小池化指令处理装置时,所述多个所述最小池化指令处理装置间可以通过特定的结构进行连接并传输数据;
其中,多个所述最小池化指令处理装置通过快速外部设备互连总线PCIE总线进行互联并传输数据,以支持更大规模的机器学习的运算;多个所述最小池化指令处理装置共享同一控制系统或拥有各自的控制系统;多个所述最小池化指令处理装置共享内存或者拥有各自的内存;多个所述最小池化指令处理装置的互联方式是任意互联拓扑。
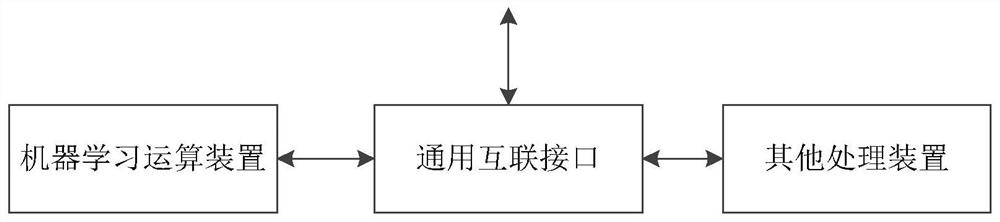
根据本公开的第三方面,提供了一种组合处理装置,所述装置包括:
上述第二方面所述的机器学习运算装置、通用互联接口和其他处理装置;
所述机器学习运算装置与所述其他处理装置进行交互,共同完成用户指定的计算操作。
根据本公开的第四方面,提供了一种机器学习芯片,所述机器学习芯片包括上述第二方面所述的机器学习络运算装置或上述第三方面所述的组合处理装置。
根据本公开的第五方面,提供了一种机器学习芯片封装结构,该机器学习芯片封装结构包括上述第四方面所述的机器学习芯片。
根据本公开的第六方面,提供了一种板卡,该板卡包括上述第五方面所述的机器学习芯片封装结构。
根据本公开的第七方面,提供了一种电子设备,所述电子设备包括上述第四方面所述的机器学习芯片或上述第六方面所述的板卡。
根据本公开的第八方面,提供了一种最小池化指令处理方法,所述方法应用于最小池化指令处理装置,所述方法包括:
对获取到的最小池化指令进行解析,得到所述最小池化指令的操作码和操作域,并根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址;
根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。
根据本公开的第九方面,提供了一种非易失性计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述最小池化指令处理方法。
在一些实施例中,所述电子设备包括数据处理装置、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、服务器、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备、交通工具、家用电器、和/或医疗设备。
在一些实施例中,所述交通工具包括飞机、轮船和/或车辆;所述家用电器包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机;所述医疗设备包括核磁共振仪、B超仪和/或心电图仪。
本公开实施例所提供的最小池化指令处理方法、装置、计算机设备和存储介质,该装置包括控制模块和运算模块,控制模块用于对获取到的最小池化指令进行解析,得到最小池化指令的操作码和操作域,并根据操作域获取执行最小池化指令所需的待运算数据、池化核和目标地址;运算模块用于根据池化核对待运算数据进行最小池化运算,获得运算结果,并将运算结果存入目标地址中。本公开实施例所提供的最小池化指令处理方法、装置及相关产品的适用范围广,对最小池化指令的处理效率高、处理速度快,进行最小池化运算的处理效率高、速度快。
根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
附图说明
包含在说明书中并且构成说明书的一部分的附图与说明书一起示出了本公开的示例性实施例、特征和方面,并且用于解释本公开的原理。
图1示出根据本公开一实施例的最小池化指令处理装置的框图。
图2a-图2f示出根据本公开一实施例的最小池化指令处理装置的框图。
图3示出根据本公开一实施例的最小池化指令处理装置的应用场景的示意图。
图4a、图4b示出根据本公开一实施例的组合处理装置的框图。
图5示出根据本公开一实施例的板卡的结构示意图。
图6示出根据本公开一实施例的最小池化指令处理方法的流程图。
图7a-图7c示出了本公开一实施例的最小池化运算的示意图。
具体实施方式
下面将结合本披露实施例中的附图,对本披露实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本披露一部分实施例,而不是全部的实施例。基于本披露中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本披露保护的范围。
应当理解,本披露的权利要求、说明书及附图中的术语“第零”、“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。本披露的说明书和权利要求书中使用的术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
还应当理解,在此本披露说明书中所使用的术语仅仅是出于描述特定实施例的目的,而并不意在限定本披露。如在本披露说明书和权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。还应当进一步理解,在本披露说明书和权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
如在本说明书和权利要求书中所使用的那样,术语“如果”可以依据上下文被解释为“当...时”或“一旦”或“响应于确定”或“响应于检测到”。类似地,短语“如果确定”或“如果检测到[所描述条件或事件]”可以依据上下文被解释为意指“一旦确定”或“响应于确定”或“一旦检测到[所描述条件或事件]”或“响应于检测到[所描述条件或事件]”。
由于神经网络算法的广泛使用,计算机硬件运算人能力的不断提升,实际应用中所涉及到的数据运算的种类和数量不断提高。最小池化运算(minpool)是取池化核所对应区域中的数据的最小值的运算。由于编程语言的种类多样,在不同的语言环境下,为实现最小池化运算的运算过程,相关技术中,由于现阶段没有能广泛适用于各类编程语言的最小池化指令,技术人员需要自定义对应其编程语言环境的多条指令来实现最小池化运算,导致进行最小池化运算效率低、速度慢。本公开提供一种最小池化指令处理方法、装置、计算机设备和存储介质,仅用一个指令即可以实现最小池化运算,能够显著提高进行最小池化运算的效率和速度。
图1示出根据本公开一实施例的最小池化指令处理装置的框图。如图1所示,该装置包括控制模块11和运算模块12。
控制模块11,用于对获取到的最小池化指令进行解析,得到最小池化指令的操作码和操作域,并根据操作域获取执行最小池化指令所需的待运算数据、池化核和目标地址。其中,操作码用于指示最小池化指令对数据所进行的运算为最小池化运算,操作域包括待运算数据地址、池化核和目标地址。
运算模块12,用于根据池化核对待运算数据进行最小池化运算,获得运算结果,并将运算结果存入目标地址中。
在本实施例中,控制模块可以从待运算数据地址获得待运算数据。控制模块可以通过数据输入输出单元获得指令和数据,该数据输入输出单元可以为一个或多个数据I/O接口或I/O引脚。
在本实施例中,操作码可以是计算机程序中所规定的要执行操作的那一部分指令或字段(通常用代码表示),是指令序列号,用来告知执行指令的装置具体需要执行哪一条指令。操作域可以是执行对应的指令所需的数据的来源,执行对应的指令所需的数据包括待运算数据、池化核等参数以及对应的运算方法等等。对于一个最小池化指令其必须包括操作码和操作域,其中,操作域至少包括待运算数据地址、池化核和目标地址。
应当理解的是,本领域技术人员可以根据需要对最小池化指令的指令格式以及所包含的操作码和操作域进行设置,本公开对此不作限制。
在本实施例中,该装置可以包括一个或多个控制模块,以及一个或多个运算模块,可以根据实际需要对控制模块和运算模块的数量进行设置,本公开对此不作限制。在装置包括一个控制模块时,该控制模块可以接收最小池化指令,并控制一个或多个运算模块进行最小池化运算。在装置包括多个控制模块时,多个控制模块可以分别接收最小池化指令,并控制对应的一个或多个运算模块进行最小池化运算。
本公开实施例所提供的最小池化指令处理装置,该装置包括控制模块和运算模块,控制模块用于对获取到的最小池化指令进行解析,得到最小池化指令的操作码和操作域,并根据操作域获取执行最小池化指令所需的待运算数据、池化核和目标地址;运算模块用于根据池化核对待运算数据进行最小池化运算,获得运算结果,并将运算结果存入目标地址中。本公开实施例所提供的最小池化指令处理装置的适用范围广,对最小池化指令的处理效率高、处理速度快,进行最小池化运算的处理效率高、速度快。
图2a示出根据本公开一实施例的最小池化指令处理装置的框图。在一种可能的实现方式中,如图2a所示,运算模块12可以包括一个或多个比较器120。比较器120用于对池化核所对应的区域中的待运算数据进行比较运算,获得运算结果。
在该实现方式中,可以根据所需进行的比较运算的数据量的大小、对比较运算的处理速度、效率等要求对比较器的数量进行设置,本公开对此不作限制。
图2b示出根据本公开多个实施例的最小池化指令处理装置的框图。在一种可能的实现方式中,如图2b所示,运算模块12可以包括主运算子模块121和多个从运算子模块122。主运算子模块121包括一个或多个比较器。
在一种可能的实现方式中,主运算子模块121,用于利用比较器对池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将运算结果存入目标地址中。
在一种可能的实现方式中,控制模块11,还可以用于对获取到的计算指令进行解析,得到计算指令的操作域和操作码,并根据操作域和操作码获取执行计算指令所需的待运算数据。运算模块12,还可以用于根据计算指令对待运算数据进行运算,得到计算指令的计算结果。其中,运算模块还可以包括多个运算器,用于执行与计算指令的运算类型相对应的运算。
在该实现方式中,计算指令可以是其他对标量、向量、矩阵、张量等数据进行算术运算、逻辑运算等运算的指令,本领域技术人员可以根据实际需要对计算指令进行设置,本公开对此不作限制。
该实现方式中,运算器可以包括加法器、除法器、乘法器、比较器等能够对数据进行算术运算、逻辑运算等运算的运算器。可以根据所需进行的运算的数据量的大小、运算类型、对数据进行运算的处理速度、效率等要求对运算器的种类及数量进行设置,本公开对此不作限制。
在一种可能的实现方式中,如图2b所示,运算模块12可以包括主运算子模块121和多个从运算子模块122。从运算子模块122包括一个或多个比较器。
在一种可能的实现方式中,控制模块11,还用于解析计算指令得到多个运算指令,并将待运算数据和多个运算指令发送至主运算子模块121。
主运算子模块121,用于接收控制模块解析的执行所述最小池化指令所需的待运算数据、池化核和目标地址,并向从运算子模块分配和传输各自执行所述最小池化指令对应的所需的待运算数据、池化核和目标地址。
从运算子模块122,用于接收主运算子模块分配和传输的执行所述最小池化指令对应的所需的待运算数据、池化核和目标地址,利用一个或多个所述比较器对所述池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将所述运算结果存入所述目标地址中。
在该实现方式中,在计算指令为针对标量、向量数据所进行的运算时,装置可以控制主运算子模块利用其中的运算器进行与计算指令相对应的运算。在计算指令为针对矩阵、张量等维度大于或等于2的数据进行运算时,装置可以控制从运算子模块利用其中的运算器进行与计算指令相对应的运算。
需要说明的是,本领域技术人员可以根据实际需要对主运算子模块和多个从运算子模块之间的连接方式进行设置,以实现对运算模块的架构设置,例如,运算模块的架构可以是“H”型架构、阵列型架构、树型架构等,本公开对此不作限制。
图2c示出根据本公开一实施例的最小池化指令处理装置的框图。在一种可能的实现方式中,如图2c所示,运算模块12还可以包括一个或多个分支运算子模块123,该分支运算子模块123用于转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。其中,主运算子模块121与一个或多个分支运算子模块123连接。这样,运算模块中的主运算子模块、分支运算子模块和从运算子模块之间采用“H”型架构连接,通过分支运算子模块转发数据和/或运算指令,节省了对主运算子模块的资源占用,进而提高指令的处理速度。
图2d示出根据本公开一实施例的最小池化指令处理装置的框图。在一种可能的实现方式中,如图2d所示,多个从运算子模块122呈阵列分布。
每个从运算子模块122与相邻的其他从运算子模块122连接,主运算子模块121连接多个从运算子模块122中的k个从运算子模块122,k个从运算子模块122为:第1行的n个从运算子模块122、第m行的n个从运算子模块122以及第1列的m个从运算子模块122。
其中,如图2d所示,k个从运算子模块仅包括第1行的n个从运算子模块、第m行的n个从运算子模块以及第1列的m个从运算子模块,即该k个从运算子模块为多个从运算子模块中直接与主运算子模块连接的从运算子模块。其中,k个从运算子模块,用于在主运算子模块以及多个从运算子模块之间的数据以及指令的转发。这样,多个从运算子模块呈阵列分布,可以提高主运算子模块向从运算子模块发送数据和/或运算指令速度,进而提高指令的处理速度。
图2e示出根据本公开一实施例的最小池化指令处理装置的框图。在一种可能的实现方式中,如图2e所示,运算模块还可以包括树型子模块124。该树型子模块124包括一个根端口401和多个支端口402。根端口401与主运算子模块121连接,多个支端口402与多个从运算子模块122分别连接。其中,树型子模块124具有收发功能,用于转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。这样,通过树型子模块的作用使得运算模块呈树型架构连接,并利用树型子模块的转发功能,可以提高主运算子模块向从运算子模块发送数据和/或运算指令速度,进而提高指令的处理速度。
在一种可能的实现方式中,树型子模块124可以为该装置的可选结果,其可以包括至少一层节点。节点为具有转发功能的线结构,节点本身不具备运算功能。最下层的节点与从运算子模块连接,以转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。特殊地,如树型子模块具有零层节点,该装置则无需树型子模块。
在一种可能的实现方式中,树型子模块124可以包括n叉树结构的多个节点,n叉树结构的多个节点可以具有多个层。
举例来说,图2f示出根据本公开一实施例的最小池化指令处理装置的框图。如图2f所示,n叉树结构可以是二叉树结构,树型子模块包括2层节点01。最下层节点01与从运算子模块122连接,以转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。
在该实现方式中,n叉树结构还可以是三叉树结构等,n为大于或等于2的正整数。本领域技术人员可以根据需要对n叉树结构中的n以及n叉树结构中节点的层数进行设置,本公开对此不作限制。
在一种可能的实现方式中,操作域还可以包括输入高度和输入宽度。
其中,控制模块,还用于从待运算数据地址中,获取对应输入宽度和输入高度的待运算数据。
在该实现方式中,输入高度和输入宽度可以限定所获得的待运算数据的数据量和尺寸。操作域所包括的输入高度和输入宽度可以是具体的数值,还可以是存储输入高度和输入宽度的存储地址。在操作域中直接包括输入高度和输入宽度的具体数值时,将该具体数值分别确定为对应的输入高度和输入宽度。在操作域中包括输入高度和输入宽度的存储地址时,可以分别从输入高度和输入宽度的存储地址中获得输入高度和输入宽度。
在一种可能的实现方式中,在操作域中不包括输入高度和输入宽度时,可以根据预先设置的默认输入高度和默认输入宽度获取待运算数据。
通过上述方式,可以对待运算数据的数据量和尺寸进行限制,保证运算结果的准确性,并保证装置可以执行该最小池化指令。
在一种可能的实现方式中,操作域还可以包括输入通道数。
其中,控制模块,还用于从待运算数据地址中,获取对应输入通道数的待运算数据。
在该实现方式中,输入通道数可以限定所获得的待运算数据的通道数量。操作域所包括的输入通道数可以是具体的数值,还可以是存储输入通道数的存储地址。在操作域中直接包括输入通道数的具体数值时,将该具体数值确定为对应的输入通道数。在操作域中包括输入通道数的存储地址时,可以从输入通道数的存储地址中获得输入通道数度。
在一种可能的实现方式中,在操作域中不包括输入通道数时,可以根据预先设置的默认输入通道数来获取待运算数据。
通过上述方式,可以对待运算数据的输入通道数进行限制,保证运算结果的准确性,并保证装置可以执行该最小池化指令。
在一种可能的实现方式中,操作域还可以包括池化核高度和池化核宽度。
其中,控制模块11,还用于根据池化核高度和池化核宽度来执行最小池化运算。
在一种可能的实现方式中,操作域还可以包括第一步幅。其中,运算模块12,还可以用于按照第一步幅在宽度方向上移动池化核。
在一种可能的实现方式中,操作域还可以包括第二步幅。其中,运算模块12,还可以用于按照第二步幅在高度方向上移动池化核。
在该实现方式中,最小池化运算的步幅是在进行最小池化运算中每一次移动池化核的幅度。第一步幅可以是在宽度方向上移动池化核的幅度,第二步幅可以是在高度方向上移动池化核的幅度。
需要说明的是,在本公开中仅以池化核为二维为例,描述了进行最小池化运算所需的池化核的高度、宽度、第一步幅和第二步幅等参数,若池化核为多维,在相应地池化核的参数则包括其每个维度的尺寸和步幅。
在一种可能的实现方式中,在最小池化指令的操作域中并未给出第一步幅和第二步幅时,运算模块可以以池化核的宽度和宽度分别为其对应维度的步幅,保证最小池化运算的正常进行。例如,运算模块12还可以用于在待运算数据上非重叠移动池化核,并比较池化核所对应的区域中的多个待运算数据,获得运算结果。
在一种可能的实现方式中,在操作域中不包括池化核高度、池化核宽度时,可以获取预先设置的默认池化核高度、默认池化核宽度,使得控制模块和运算模块可以执行最小池化指令。例如,默认池化核高度为3,默认池化核宽度为2,运算模块12还可以用于在待运算数据上在宽度方向上每次将池化核移动两个单位或在高度方向上每次将池化核移动3个单位,并比较池化核所对应的区域中的多个待运算数据,获得运算结果。
图7a-图7c示出了本公开一实施例的最小池化运算的示意图。
在一种可能的实现方式中,运算模块12还用于在待运算数据的尺寸为池化核的尺寸的非整数倍时,对待运算数据中为池化核的尺寸的整数倍的数据进行最小池化运算。其中,待运算数据的尺寸为所述池化核的尺寸的非整数倍,可以包括以下至少一项:当不包含所述第一步幅或者所述第一步幅与所述池化核的宽度相等时,所述待运算数据的输入宽度为所述池化核的宽度的非整数倍;当包含所述第一步幅时,所述待运算数据的输入宽度与所述池化核的宽度之差为所述第一步幅的非整数倍;当不包含所述第二步幅或所述第二步幅与所述池化核的高度相等时,所述待运算数据的输入高度为所述池化核的高度的非整数倍;当包含所述第二步幅时,所述待运算数据的输入高度与所述池化核高度之差为所述第二步幅的非整数倍。
例如,输入数据宽度和高度分别为5和4,池化核的宽度和长度分别为2和2,第一步幅和第二步幅均为2和2。其中,本例子中数据的单位相同,可以为字节、像素等,对此不做限制。由于池化核的宽度和第一步幅相同,并且输入数据宽度为5,不为池化核宽度的整数倍,那么对待运算数据中为池化核的尺寸的整数倍的数据进行最小池化运算,即对输入宽度为前4个数据进行最小池化运算。
在该实现方式中,对于待运算数据中为池化核的非整数倍的剩余数据,其尺寸小于所述池化核尺寸的剩余数据,可以采用多种方式进行处理。
可以如图7a所示,对于待运算数据中为池化核的非整数倍的剩余数据,其尺寸小于所述池化核尺寸的剩余数据,可以不进行最小池化运算。即对于上例而言,宽度方向的每一行的最后一个数据可不进行运算。
还可以如图7a所示,对于待运算数据中为池化核的非整数倍的剩余数据,其尺寸小于所述池化核尺寸的剩余数据,直接进行最小池化运算。即对于上例而言,即使宽度方向的每一行仅剩最后一个数据,小于所述池化核宽度,也对宽度方向的每一行的最后一个数据进行比较运算,获得运算结果。
还可以如图7b所示,对于待运算数据中为池化核的非整数倍的剩余数据其尺寸小于所述池化核尺寸的剩余数据,对所述剩余数据进行补数后进行最小池化运算,获得运算结果。即对于上例而言,可沿宽度方向进行补数,即沿着宽度方向补充1个默认值,如0。此时补数后的输入宽度为6,为池化核宽度的整数倍,而后进行最小池化运算,获得运算结果。
还可以如图7c所示,对于待运算数据中为池化核的非整数倍的剩余数据其尺寸小于所述池化核尺寸的剩余数据,反向移动所述池化核的位置,使得反向移动后的所述池化核对应区域中的数据的尺寸等于所述池化核的尺寸,且反向移动后的所述池化核对应区域中的数据包括所述剩余数据,根据移动后的池化核对应区域中的数据进行最小池化运算,获得运算结果。即对于上例而言,当池化核在第1、2个数和第3、4个数的位置时,为所述池化核的尺寸的整数倍,可进行池化运算。当池化核在第5个数的位置时,不为所述池化核的尺寸的整数倍,则反向移动池化核的位置,即向前移动一个位置,即此时池化核位于第4、5个数的位置,为所述池化核的尺寸的整数倍,进行池化运算,获得运算结果。
在一种可能的实现方式中,如图2a-图2f所示,该装置还可以包括存储模块13。存储模块13用于存储待运算数据和运算结果。
在该实现方式中,存储模块可以为缓存、寄存器中的一种或多种,缓存可以包括高速暂存缓存,还可以包括至少一个NRAM(Neuron Random Access Memory,神经元随机存取存储器)。缓存可以用于存储待运算数据和运算结果,寄存器可以用于存储待运算数据、标量数据、参数等。
在一种可能的实现方式中,缓存可以包括神经元缓存。神经元缓存也即上述神经元随机存取存储器,可以用于存储待运算数据中的神经元数据,神经元数据可以包括神经元向量数据。
在一种可能的实现方式中,该装置还可以包括直接内存访问模块,用于从存储模块中读取或者存储数据。
在一种可能的实现方式中,如图2a-图2f所示,控制模块11可以包括指令存储子模块111、指令处理子模块112和队列存储子模块113。
指令存储子模块111用于存储最小池化指令。
指令处理子模块112用于对最小池化指令进行解析,得到最小池化指令的操作码和操作域。
队列存储子模块113用于存储指令队列,指令队列包括按照执行顺序依次排列的多个待执行指令,多个待执行指令可以包括最小池化指令。
在该实现方式中,可以根据待执行指令的接收时间、优先级别等对多个待执行指令的执行顺序进行排列获得指令队列,以便于根据指令队列依次执行多个待执行指令。
在一种可能的实现方式中,如图2a-图2f所示,控制模块11还可以包括依赖关系处理子模块114。
依赖关系处理子模块114,用于在确定多个待执行命令中的第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系时,将第一待执行指令缓存在指令存储子模块111中,在第零待执行指令执行完毕后,从指令存储子模块111中提取第一待执行指令发送至运算模块12。
其中,第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系包括:存储第一待执行指令所需数据的第一存储地址区间与存储第零待执行指令所需数据的第零存储地址区间具有重叠的区域。
通过这种方式,可以根据第一待执行指令与第一待执行指令之前的第零待执行指令之间的依赖关系,使得在先的第零待执行指令执行完毕之后,再执行在后的第一待执行指令,保证运算结果的准确性。
其中,第一待执行指令可以包括最小池化指令。
在一种可能的实现方式中,最小池化指令的指令格式可以是:
minpool dstsrc0srcChannelsrcHeighsrcWidth
其中,minpool为最小池化指令的操作码,dst、src0、srcChannel、srcHeigh、srcWidth为最小池化指令的操作域。其中,dst为目标地址,src0为待运算数据地址,srcChannel为输入通道数,srcHeigh为输入高度,srcWidth为输入宽度。即从src0处获取的待处理数据,待处理数据的尺寸如下,输入通道数是srcChannel、输入高度是srcHeigh、输入宽度是srcWidth。池化核的尺寸采用默认值。最小池化后的运算结果存入地址为dst处。
minpool dstsrc0srcChannelsrcHeighsrcWidth kernelHeightkernelWidth
其中,minpool为最小池化指令的操作码,dst、src0、srcChannel、srcHeigh、srcWidth为最小池化指令的操作域。其中,dst为目标地址,src0为待运算数据地址,srcChannel为输入通道数,srcHeigh为输入高度,srcWidth为输入宽度,kernelHeight为池化核高度,kernelWidth为池化核宽度。即从src0处获取的待处理数据,待处理数据的尺寸如下,输入通道数是srcChannel、输入高度是srcHeigh、输入宽度是srcWidth。池化核的尺寸如下,池化核高度为kernelHeight,池化核宽度为kernelWidth。每次池化核的移动步长为默认值,如宽度方向上每次移动的步长为kernelWidth,高度方向上每次移动的步长为kernalHeight。最小池化后的运算结果存入地址为dst处。
在一种可能的实现方式中,最小池化指令的指令格式可以是:
minpool dstsrc0srcChannelsrcHeighsrcWidthkernelHeightkernelWidthstrideX strideY
其中,minpool为最小池化指令的操作码,dst、src0、srcChannel、srcHeigh、srcWidth、kernelHeight、kernelWidth、strideX、strideY为最小池化指令的操作域。其中,dst为目标地址,src0为待运算数据地址,srcChannel为输入通道数,srcHeigh为输入高度,srcWidth为输入宽度,kernelHeight为池化核高度,kernelWidth为池化核宽度,strideX为池化核在宽度方向上进行移动的第一步幅,strideY为池化核在高度方向上进行移动的第二步幅。即从src0处获取的待处理数据,待处理数据的尺寸如下,输入通道数是srcChannel、输入高度是srcHeigh、输入宽度是srcWidth。池化核的尺寸如下,池化核高度为kernelHeight,池化核宽度为kernelWidth。每次池化核在宽度方向上每次移动的步长为strideX,高度方向上每次移动的步长为strideY。最小池化后的运算结果存入地址为dst处。
应当理解的是,本领域技术人员可以根据需要对最小池化指令的操作码、指令格式中操作码和操作域的位置进行设置,本公开对此不作限制。
在一种可能的实现方式中,该装置可以设置于图形处理器(Graphics ProcessingUnit,简称GPU)、中央处理器(Central Processing Unit,简称CPU)和嵌入式神经网络处理器(Neural-network Processing Unit,简称NPU)的一种或多种之中。
需要说明的是,尽管以上述实施例作为示例介绍了最小池化指令处理装置如上,但本领域技术人员能够理解,本公开应不限于此。事实上,用户完全可根据个人喜好和/或实际应用场景灵活设定各模块,只要符合本公开的技术方案即可。
应用示例
以下结合“利用最小池化指令处理装置进行最小池化运算”作为一个示例性应用场景,给出根据本公开实施例的应用示例,以便于理解最小池化指令处理装置的流程。本领域技术人员应理解,以下应用示例仅仅是出于便于理解本公开实施例的目的,不应视为对本公开实施例的限制
图3示出根据本公开一实施例的最小池化指令处理装置的应用场景的示意图。如图3所示,最小池化指令处理装置对最小池化指令进行处理的过程如下:
控制模块11对获取到的最小池化指令1(如最小池化指令1为minpool50010056432212 1)进行解析,得到最小池化指令1的操作码和操作域。其中,最小池化指令1的操作码为minpool,目标地址为500,待运算数据地址为100,输入通道数为5,输入高度为64,输入宽度为32,池化核高度为2,池化核宽度为1,第一步幅为2,第二步幅为1。控制模块11从待运算数据地址100中获取64×32×5的待运算数据。
运算模块12利用池化核分别在5个输入通道上对64×32规模的待运算数据进行最小池化运算,得到运算结果,并将运算结果存入目标地址500中。
以上各模块的工作过程可参考上文的相关描述。
这样,可以高效、快速地对最小池化指令进行处理,且进行最小池化运算的效率和速度也有显著提高。
本公开提供一种机器学习运算装置,该机器学习运算装置可以包括一个或多个上述最小池化指令处理装置,用于从其他处理装置中获取待运算数据和控制信息,执行指定的机器学习运算。该机器学习运算装置可以从其他机器学习运算装置或非机器学习运算装置中获得最小池化指令,并将执行结果通过I/O接口传递给外围设备(也可称其他处理装置)。外围设备譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口,服务器。当包含一个以上最小池化指令处理装置时,最小池化指令处理装置间可以通过特定的结构进行链接并传输数据,譬如,通过PCIE总线进行互联并传输数据,以支持更大规模的神经网络的运算。此时,可以共享同一控制系统,也可以有各自独立的控制系统;可以共享内存,也可以每个加速器有各自的内存。此外,其互联方式可以是任意互联拓扑。
该机器学习运算装置具有较高的兼容性,可通过PCIE接口与各种类型的服务器相连接。
图4a示出根据本公开一实施例的组合处理装置的框图。如图4a所示,该组合处理装置包括上述机器学习运算装置、通用互联接口和其他处理装置。机器学习运算装置与其他处理装置进行交互,共同完成用户指定的操作。
其他处理装置,包括中央处理器CPU、图形处理器GPU、神经网络处理器等通用/专用处理器中的一种或以上的处理器类型。其他处理装置所包括的处理器数量不做限制。其他处理装置作为机器学习运算装置与外部数据和控制的接口,包括数据搬运,完成对本机器学习运算装置的开启、停止等基本控制;其他处理装置也可以和机器学习运算装置协作共同完成运算任务。
通用互联接口,用于在机器学习运算装置与其他处理装置间传输数据和控制指令。该机器学习运算装置从其他处理装置中获取所需的输入数据,写入机器学习运算装置片上的存储装置;可以从其他处理装置中获取控制指令,写入机器学习运算装置片上的控制缓存;也可以读取机器学习运算装置的存储模块中的数据并传输给其他处理装置。
图4b示出根据本公开一实施例的组合处理装置的框图。在一种可能的实现方式中,如图4b所示,该组合处理装置还可以包括存储装置,存储装置分别与机器学习运算装置和所述其他处理装置连接。存储装置用于保存在机器学习运算装置和所述其他处理装置的数据,尤其适用于所需要运算的数据在本机器学习运算装置或其他处理装置的内部存储中无法全部保存的数据。
该组合处理装置可以作为手机、机器人、无人机、视频监控设备等设备的SOC片上系统,有效降低控制部分的核心面积,提高处理速度,降低整体功耗。此情况时,该组合处理装置的通用互联接口与设备的某些部件相连接。某些部件譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口。
本公开提供一种机器学习芯片,该芯片包括上述机器学习运算装置或组合处理装置。
本公开提供一种机器学习芯片封装结构,该机器学习芯片封装结构包括上述机器学习芯片。
本公开提供一种板卡,图5示出根据本公开一实施例的板卡的结构示意图。如图5所示,该板卡包括上述机器学习芯片封装结构或者上述机器学习芯片。板卡除了包括机器学习芯片389以外,还可以包括其他的配套部件,该配套部件包括但不限于:存储器件390、接口装置391和控制器件392。
存储器件390与机器学习芯片389(或者机器学习芯片封装结构内的机器学习芯片)通过总线连接,用于存储数据。存储器件390可以包括多组存储单元393。每一组存储单元393与机器学习芯片389通过总线连接。可以理解,每一组存储单元393可以是DDR SDRAM(英文:Double Data Rate SDRAM,双倍速率同步动态随机存储器)。
DDR不需要提高时钟频率就能加倍提高SDRAM的速度。DDR允许在时钟脉冲的上升沿和下降沿读出数据。DDR的速度是标准SDRAM的两倍。
在一个实施例中,存储器件390可以包括4组存储单元393。每一组存储单元393可以包括多个DDR4颗粒(芯片)。在一个实施例中,机器学习芯片389内部可以包括4个72位DDR4控制器,上述72位DDR4控制器中64bit用于传输数据,8bit用于ECC校验。
在一个实施例中,每一组存储单元393包括多个并联设置的双倍速率同步动态随机存储器。DDR在一个时钟周期内可以传输两次数据。在机器学习芯片389中设置控制DDR的控制器,用于对每个存储单元393的数据传输与数据存储的控制。
接口装置391与机器学习芯片389(或者机器学习芯片封装结构内的机器学习芯片)电连接。接口装置391用于实现机器学习芯片389与外部设备(例如服务器或计算机)之间的数据传输。例如在一个实施例中,接口装置391可以为标准PCIE接口。比如,待处理的数据由服务器通过标准PCIE接口传递至机器学习芯片289,实现数据转移。在另一个实施例中,接口装置391还可以是其他的接口,本公开并不限制上述其他的接口的具体表现形式,接口装置能够实现转接功能即可。另外,机器学习芯片的计算结果仍由接口装置传送回外部设备(例如服务器)。
控制器件392与机器学习芯片389电连接。控制器件392用于对机器学习芯片389的状态进行监控。具体的,机器学习芯片389与控制器件392可以通过SPI接口电连接。控制器件392可以包括单片机(Micro Controller Unit,MCU)。如机器学习芯片389可以包括多个处理芯片、多个处理核或多个处理电路,可以带动多个负载。因此,机器学习芯片389可以处于多负载和轻负载等不同的工作状态。通过控制器件可以实现对机器学习芯片中多个处理芯片、多个处理和/或多个处理电路的工作状态的调控。
本公开提供一种电子设备,该电子设备包括上述机器学习芯片或板卡。
电子设备可以包括数据处理装置、计算机设备、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、服务器、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备、交通工具、家用电器、和/或医疗设备。
交通工具可以包括飞机、轮船和/或车辆。家用电器可以包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机。医疗设备可以包括核磁共振仪、B超仪和/或心电图仪。
图6示出根据本公开一实施例的最小池化指令处理方法的流程图。该方法可以应用于包含存储器和处理器的如计算机设备等,其中,存储器用于存储执行方法过程中所使用的数据;处理器用于执行相关的处理、运算步骤,如执行下述步骤S51和步骤S52。如图6所示,该方法应用于上述最小池化指令处理装置,该方法包括步骤S51和步骤S52。
在步骤S51中,对获取到的最小池化指令进行解析,得到最小池化指令的操作码和操作域,并根据操作域获取执行最小池化指令所需的待运算数据、池化核和目标地址。其中,操作码用于指示最小池化指令对数据所进行的运算为最小池化运算,操作域包括待运算数据地址、目标地址和池化核。
在步骤S52中,根据池化核对待运算数据进行最小池化运算,获得运算结果,并将运算结果存入目标地址中。
在一种可能的实现方式中,根据池化核对待运算数据进行最小池化运算,获得运算结果,可以包括:
利用运算模块中的多个比较器对池化核所对应的区域中的多个待运算数据进行比较运算,获得运算结果。
在一种可能的实现方式中,运算模块包括主运算子模块和多个从运算子模块,主运算子模块包括比较器,
其中,根据池化核对待运算数据进行最小池化运算,获得运算结果,并将运算结果存入目标地址中,包括:
利用比较器对池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将运算结果存入目标地址中。
在一种可能的实现方式中,操作域还可以包括输入高度和输入宽度。其中,根据操作域获取执行最小池化指令所需的待运算数据、池化核和目标地址,可以包括:
从待运算数据地址中,获取对应输入宽度和输入高度的待运算数据。
在一种可能的实现方式中,操作域还可以包括输入通道数。其中,根据操作域获取执行最小池化指令所需的待运算数据、池化核和目标地址,可以包括:
从待运算数据地址中,获取对应输入通道数的待运算数据。
在一种可能的实现方式中,操作域还可以包括池化核高度和池化核宽度。
在一种可能的实现方式中,操作域还可以包括第一步幅。其中,根据池化核对待运算数据进行最小池化运算,可以包括:按照第一步幅在宽度方向上移动池化核。
在一种可能的实现方式中,操作域还可以包括第二步幅。其中,根据池化核对待运算数据进行最小池化运算,可以包括:按照第二步幅在高度方向上移动池化核。
在一种可能的实现方式中,根据池化核对待运算数据进行最小池化运算,获得运算结果,可以包括:
在待运算数据上非重叠移动池化核,并比较池化核所对应的区域中的多个待运算数据,获得运算结果。
在一种可能的实现方式中,根据池化核对待运算数据进行最小池化运算,获得运算结果,可以包括:在待运算数据的尺寸为池化核的尺寸的非整数倍时,对待运算数据中为池化核的尺寸的整数倍的数据进行最小池化运算。
其中,待运算数据的尺寸为池化核的尺寸的非整数倍,包括以下至少一项:当不包含所述第一步幅或者所述第一步幅与所述池化核的宽度相等时,所述待运算数据的输入宽度为所述池化核的宽度的非整数倍;当包含所述第一步幅时,所述待运算数据的输入宽度与所述池化核的宽度之差为所述第一步幅的非整数倍;当不包含所述第二步幅或所述第二步幅与所述池化核的高度相等时,所述待运算数据的输入高度为所述池化核的高度的非整数倍;当包含所述第二步幅时,所述待运算数据的输入高度与所述池化核高度之差为所述第二步幅的非整数倍。
在一种可能的实现方式中,根据池化核对待运算数据进行最小池化运算,获得运算结果,还可以包括:当所述待运算数据中剩余数据的尺寸小于所述池化核尺寸时,对所述剩余数据不进行最小池化运算。
在一种可能的实现方式中,根据池化核对待运算数据进行最小池化运算,获得运算结果,还可以包括:当所述待运算数据中剩余数据的尺寸小于所述池化核尺寸时,对所述剩余数据进行最小池化运算或者进行补数后进行最小池化运算,获得运算结果。
在一种可能的实现方式中,根据池化核对待运算数据进行最小池化运算,获得运算结果,还可以包括:当所述待运算数据中的剩余数据的尺寸小于所述池化核尺寸时,反向移动所述池化核的位置,使得反向移动后的所述池化核对应区域中的数据的尺寸等于所述池化核的尺寸,且反向移动后的所述池化核对应区域中的数据包括所述剩余数据,根据移动后的池化核对应区域中的数据进行最小池化运算,获得运算结果。
在一种可能的实现方式中,该方法还可以包括:利用装置的存储模块存储待运算数据和运算结果。
在一种可能的实现方式中,对获取到的最小池化指令进行解析,得到最小池化指令的操作码和操作域,可以包括:
存储最小池化指令;
对最小池化指令进行解析,得到最小池化指令的操作码和操作域;
存储指令队列,指令队列包括按照执行顺序依次排列的多个待执行指令,多个待执行指令可以包括最小池化指令。
在一种可能的实现方式中,该方法还可以包括:在确定多个待执行指令中的第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系时,缓存第一待执行指令,在第零待执行指令执行完毕后,执行第一待执行指令,
其中,第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系包括以下至少一种:
存储所述第一待执行指令所需数据的第一存储地址区间与存储所述第零待执行指令所需数据的第零存储地址区间具有重叠的区域;
执行所述第一待执行指令所需使用的第一运算部件与执行所述第零执行指令所需使用的第零运算部件全部相同或者部分相同。
需要说明的是,尽管以上述实施例作为示例介绍了最小池化指令处理方法如上,但本领域技术人员能够理解,本公开应不限于此。事实上,用户完全可根据个人喜好和/或实际应用场景灵活设定各步骤,只要符合本公开的技术方案即可。
本公开实施例所提供的最小池化指令处理方法的适用范围广,对最小池化指令的处理效率高、处理速度快,进行最小池化运算的效率高、速度快。
本公开还提供一种非易失性计算机可读存储介质,其上存储有计算机程序指令,其特征在于,所述计算机程序指令被处理器执行时实现上述最小池化指令处理方法。
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本披露并不受所描述的动作顺序的限制,因为依据本披露,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本披露所必须的。
进一步需要说明的是,虽然图6的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图6中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
应该理解,上述的装置实施例仅是示意性的,本披露的装置还可通过其它的方式实现。例如,上述实施例中所述单元/模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。例如,多个单元、模块或组件可以结合,或者可以集成到另一个系统,或一些特征可以忽略或不执行。
另外,若无特别说明,在本披露各个实施例中的各功能单元/模块可以集成在一个单元/模块中,也可以是各个单元/模块单独物理存在,也可以两个或两个以上单元/模块集成在一起。上述集成的单元/模块既可以采用硬件的形式实现,也可以采用软件程序模块的形式实现。
所述集成的单元/模块如果以硬件的形式实现时,该硬件可以是数字电路,模拟电路等等。硬件结构的物理实现包括但不局限于晶体管,忆阻器等等。若无特别说明,若无特别说明,上述存储模块可以是任何适当的磁存储介质或者磁光存储介质,比如,阻变式存储器RRAM(Resistive Random Access Memory)、动态随机存取存储器DRAM(Dynamic RandomAccess Memory)、静态随机存取存储器SRAM(Static Random-Access Memory)、增强动态随机存取存储器EDRAM(Enhanced Dynamic Random Access Memory)、高带宽内存HBM(High-Bandwidth Memory)、混合存储立方HMC(Hybrid Memory Cube)等等。
所述集成的单元/模块如果以软件程序模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储器中。基于这样的理解,本披露的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储器中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本披露各个实施例所述方法的全部或部分步骤。而前述的存储器包括:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。上述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
依据以下条款可以更好的理解前述内容:
条款A1、一种最小池化指令处理装置,所述装置包括:
控制模块,用于对获取到的最小池化指令进行解析,得到所述最小池化指令的操作码和操作域,并根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址;
运算模块,用于根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。
条款A2、根据条款A1所述的装置,所述运算模块,包括:
比较器,用于对所述池化核所对应的区域中的待运算数据进行比较运算,获得运算结果。
条款A3、根据条款A2所述的装置,所述运算模块包括主运算子模块和多个从运算子模块,所述主运算子模块包括一个或多个所述比较器,
所述主运算子模块,用于利用一个或多个所述比较器对所述池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将所述运算结果存入所述目标地址中。
条款A4、根据条款A2所述的装置,所述运算模块包括主运算子模块和多个从运算子模块,所述从运算子模块包括一个或多个所述比较器,
所述主运算子模块,用于接收控制模块获取的执行所述最小池化指令所需的待运算数据、池化核和目标地址,并向从运算子模块分配和传输各自执行所述最小池化指令对应的所需的待运算数据、池化核和目标地址;
所述从运算子模块,用于接收主运算子模块分配和传输的执行所述最小池化指令对应的所需的待运算数据、池化核和目标地址,利用一个或多个所述比较器对所述池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将所述运算结果存入所述目标地址中。
条款A5、根据条款A1所述的装置,所述操作域还包括输入高度和输入宽度,
其中,所述控制模块,还用于从所述待运算数据地址中,获取对应所述输入宽度和所述输入高度的待运算数据。
条款A6、根据条款A1所述的装置,所述操作域还包括输入通道数,
其中,所述控制模块,还用于从所述待运算数据地址中,获取对应所述输入通道数的待运算数据。
条款A7、根据条款A1所述的装置,所述操作域还包括池化核高度和池化核宽度,
其中,所述运算模块,还用于根据所述池化核高度和所述池化核宽度对所述待运算数据进行最小池化运算。
条款A8、根据条款A1所述的装置,所述操作域还包括第一步幅,
其中,所述运算模块,还用于按照所述第一步幅在宽度方向上移动所述池化核。
条款A9、根据条款A1所述的装置,所述操作域还包括第二步幅,
其中,所述运算模块,还用于按照所述第二步幅在高度方向上移动所述池化核。
条款A10、根据条款A1所述的装置,所述运算模块,还用于在所述待运算数据上移动所述池化核,并比较所述池化核所对应的区域中的多个待运算数据,获得所述运算结果。
条款A11、根据条款A1所述的装置,所述运算模块,还用于在所述待运算数据的尺寸为所述池化核的尺寸的非整数倍时,对所述待运算数据中为所述池化核的尺寸的整数倍的数据进行最小池化运算,获得运算结果,
其中,所述待运算数据的尺寸为所述池化核的尺寸的非整数倍,包括以下至少一项:当不包含所述第一步幅或者所述第一步幅与所述池化核的宽度相等时,所述待运算数据的输入宽度为所述池化核的宽度的非整数倍;当包含所述第一步幅时,所述待运算数据的输入宽度与所述池化核的宽度之差为所述第一步幅的非整数倍;当不包含所述第二步幅或所述第二步幅与所述池化核的高度相等时,所述待运算数据的输入高度为所述池化核的高度的非整数倍;当包含所述第二步幅时,所述待运算数据的输入高度与所述池化核高度之差为所述第二步幅的非整数倍。
条款A12、根据条款A11所述的装置,所述运算模块,还用于当所述待运算数据中剩余数据的尺寸小于所述池化核尺寸时,对所述剩余数据进行最小池化运算或者进行补数后进行最小池化运算,获得运算结果。
条款A13、根据条款A11所述的装置,所述运算模块,还用于当所述待运算数据中的剩余数据的尺寸小于所述池化核尺寸时,反向移动所述池化核的位置,使得反向移动后的所述池化核对应区域中的数据的尺寸等于所述池化核的尺寸,且反向移动后的所述池化核对应区域中的数据包括所述剩余数据,根据移动后的池化核对应区域中的数据进行最小池化运算,获得运算结果。
条款A14、根据条款A1所述的装置,所述装置还包括:
存储模块,用于存储所述待运算数据和所述运算结果。
条款A15、根据条款A1所述的装置,所述控制模块,包括:
指令存储子模块,用于存储所述最小池化指令;
指令处理子模块,用于对所述最小池化指令进行解析,得到所述最小池化指令的操作码和操作域;
队列存储子模块,用于存储指令队列,所述指令队列包括按照执行顺序依次排列的多个待执行指令,所述多个待执行指令包括所述最小池化指令。
条款A16、根据条款A15所述的装置,所述控制模块,还包括:
依赖关系处理子模块,用于在确定所述多个待执行指令中的第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系时,将所述第一待执行指令缓存在所述指令存储子模块中,在所述第零待执行指令执行完毕后,从所述指令存储子模块中提取所述第一待执行指令发送至所述运算模块,
其中,所述第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系包括以下至少一种:
存储所述第一待执行指令所需数据的第一存储地址区间与存储所述第零待执行指令所需数据的第零存储地址区间具有重叠的区域;
所述第一待执行指令包括最小池化指令。
条款A17、一种机器学习运算装置,所述装置包括:
一个或多个如条款A1至条款A16任一项所述的最小池化指令处理装置,用于从其他处理装置中获取待运算数据和控制信息,并执行指定的机器学习运算,将执行结果通过I/O接口传递给其他处理装置;
当所述机器学习运算装置包含多个所述最小池化指令处理装置时,所述多个所述最小池化指令处理装置间可以通过特定的结构进行连接并传输数据;
其中,多个所述最小池化指令处理装置通过快速外部设备互连总线PCIE总线进行互联并传输数据,以支持更大规模的机器学习的运算;多个所述最小池化指令处理装置共享同一控制系统或拥有各自的控制系统;多个所述最小池化指令处理装置共享内存或者拥有各自的内存;多个所述最小池化指令处理装置的互联方式是任意互联拓扑。
条款A18、一种组合处理装置,所述组合处理装置包括:
如条款A17所述的机器学习运算装置、通用互联接口和其他处理装置;
所述机器学习运算装置与所述其他处理装置进行交互,共同完成用户指定的计算操作,
其中,所述组合处理装置还包括:存储装置,该存储装置分别与所述机器学习运算装置和所述其他处理装置连接,用于保存所述机器学习运算装置和所述其他处理装置的数据。
条款A19、一种机器学习芯片,所述机器学习芯片包括:
如条款A17所述的机器学习运算装置或如条款A18所述的组合处理装置。
条款A20、一种电子设备,所述电子设备包括:
如条款A19所述的机器学习芯片。
条款A21、一种板卡,所述板卡包括:存储器件、接口装置和控制器件以及如条款A19所述的机器学习芯片;
其中,所述机器学习芯片与所述存储器件、所述控制器件以及所述接口装置分别连接;
所述存储器件,用于存储数据;
所述接口装置,用于实现所述机器学习芯片与外部设备之间的数据传输;
所述控制器件,用于对所述机器学习芯片的状态进行监控。
条款A22、一种最小池化指令处理方法,所述方法应用于最小池化指令处理装置,所述方法包括:
对获取到的最小池化指令进行解析,得到所述最小池化指令的操作码和操作域,并根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址;
根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。
条款A23、根据条款A22所述的方法,根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,包括:
利用所述运算模块中的比较器对所述池化核所对应的区域中的待运算数据进行比较运算,获得运算结果。
条款A24、根据条款A23所述的方法,所述运算模块包括主运算子模块和多个从运算子模块,所述主运算子模块包括所述比较器,
其中,根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,并将所述运算结果存入所述目标地址中,包括:
利用所述比较器对所述池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将所述运算结果存入所述目标地址中。
条款A25、根据条款A23所述的方法,所述运算模块包括主运算子模块和多个从运算子模块,所述从运算子模块包括所述比较器,
其中,根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,并将所述运算结果存入所述目标地址中,包括:
利用所述多个比较器对所述池化核所对应的区域中的多个待运算数据进行比较运算,得到运算结果,并将所述运算结果存入所述目标地址中。
接收所述最小池化指令所需的待运算数据、池化核和目标地址,并向从运算子模块分配和传输各自执行所述最小池化指令对应的所需的待运算数据、池化核和目标地址;
接收主运算子模块分配和传输的执行所述最小池化指令对应的所需的待运算数据、池化核和目标地址,利用一个或多个所述比较器对所述池化核所对应的区域中的待运算数据进行比较运算,得到运算结果,并将所述运算结果存入所述目标地址中。
条款A26、根据条款A22所述的方法,所述操作域还包括输入高度和输入宽度,
其中,根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址,包括:
从所述待运算数据地址中,获取对应所述输入宽度和所述输入高度的待运算数据。
条款A27、根据条款A22所述的方法,所述操作域还包括输入通道数,
其中,根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址,包括:
从所述待运算数据地址中,获取对应所述输入通道数的待运算数据。
条款A28、根据条款A22所述的方法,所述操作域还包括池化核高度和池化核宽度,
其中,根据所述操作域获取执行所述最小池化指令所需的待运算数据、池化核和目标地址,包括:
根据所述池化核高度和所述池化核宽度对所述待运算数据进行最小池化运算。
条款A29、根据条款A22所述的方法,所述操作域还包括第一步幅,
其中,根据所述池化核对所述待运算数据进行最小池化运算,包括:
按照所述第一步幅在宽度方向上移动所述池化核。
条款A30、根据条款A22所述的方法,所述操作域还包括第二步幅,
其中,根据所述池化核对所述待运算数据进行最小池化运算,包括:
按照所述第二步幅在高度方向上移动所述池化核。
条款A31、根据条款A22所述的方法,所述根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,包括:
在所述待运算数据上移动所述池化核,并比较所述池化核所对应的区域中的多个待运算数据,获得所述运算结果。
条款A32、根据条款A22所述的方法,所述根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,包括:
在所述待运算数据的尺寸为所述池化核的尺寸的非整数倍时,对所述待运算数据中为所述池化核的尺寸的整数倍的数据进行最小池化运算,
其中,所述待运算数据的尺寸为所述池化核的尺寸的非整数倍,包括以下至少一项:当不包含所述第一步幅或者所述第一步幅与所述池化核的宽度相等时,所述待运算数据的输入宽度为所述池化核的宽度的非整数倍;当包含所述第一步幅时,所述待运算数据的输入宽度与所述池化核的宽度之差为所述第一步幅的非整数倍;当不包含所述第二步幅或所述第二步幅与所述池化核的高度相等时,所述待运算数据的输入高度为所述池化核的高度的非整数倍;当包含所述第二步幅时,所述待运算数据的输入高度与所述池化核高度之差为所述第二步幅的非整数倍。
条款A33、根据条款A32所述的方法,所述根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,还包括:
当所述待运算数据中剩余数据的尺寸小于所述池化核尺寸时,对所述剩余数据进行最小池化运算或者进行补数后进行最小池化运算,获得运算结果。
条款A34、根据条款A32所述的方法,所述根据所述池化核对所述待运算数据进行最小池化运算,获得运算结果,还包括:
所述待运算数据中的剩余数据的尺寸小于所述池化核尺寸时,反向移动所述池化核的位置,使得反向移动后的所述池化核对应区域中的数据的尺寸等于所述池化核的尺寸,且反向移动后的所述池化核对应区域中的数据包括所述剩余数据,根据移动后的池化核对应区域中的数据进行最小池化运算,获得运算结果。
条款A35、根据条款A22所述的方法,所述方法还包括:
利用所述装置的存储模块存储所述待运算数据和所述运算结果。
条款A36、根据条款A22所述的方法,对获取到的最小池化指令进行解析,得到所述最小池化指令的操作码和操作域,包括:
存储所述最小池化指令;
对所述最小池化指令进行解析,得到所述最小池化指令的操作码和操作域;
存储指令队列,所述指令队列包括按照执行顺序依次排列的多个待执行指令,所述多个待执行指令包括所述最小池化指令。
条款A37、根据条款A36所述的方法,所述方法还包括:
在确定所述多个待执行指令中的第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系时,缓存所述第一待执行指令,并在确定所述第零待执行指令执行完毕后,控制进行所述第一待执行指令的执行,
其中,所述第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系包括以下至少一种:
存储所述第一待执行指令所需数据的第一存储地址区间与存储所述第零待执行指令所需数据的第零存储地址区间具有重叠的区域;
执行所述第一待执行指令所需使用的第一运算部件与执行所述第零执行指令所需使用的第零运算部件全部相同或者部分相同。
条款A38、一种非易失性计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现条款A22至条款A37任一项所述的方法。
以上对本申请实施例进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 卷积运算方法、装置、计算机设备及计算机可读存储介质
- 神经网络的运算方法、装置、计算机设备和存储介质