基于分布式深度确定性策略梯度的HEV能量管理方法
文献发布时间:2023-06-19 10:06:57
技术领域
本发明涉及混合动力汽车能量管理技术领域,尤其涉及基于分布式深度确定性策略梯度的HEV能量管理方法。
背景技术
能源与环境问题已经引起了世界各国的广泛关注。车辆是能源与环境问题不可忽视的关键因素,减少车辆能源消耗和排放是应对能源与环境问题最切实有效的方法。在新能源汽车中,混合动力汽车由于相比于传统燃油汽车需要更少的燃料,相比于纯电动汽车具有更远的行驶里程,成为目前最行之有效的解决方案。混合动力汽车(HEV)节能减排潜力大,但其能量管理系统复杂,其能量管理方法涵盖了传统汽车、纯电动汽车和油电混合动力汽车能量管理内容,成为国内外汽车领域研究的热点。
能量管理策略优化的目标是得到发动机和电机最优能量分配关系以及变速器的挡位,本质是一个动态最优控制问题。对于HEV的多目标(燃油经济性、动力性、排放、驾驶性等)优化问题,一般通过设置多个目标的权值将问题转化为单目标优化问题。能量管理方法通常分为离线优化方法和在线优化方法。离线优化算法(动态规划、进化算法、凸优化和神经网络)能够获得车辆在特定工况循环下的最优或者接近最优结果,但是需要预知车辆的全部行驶工况,耗用的计算资源很大,无法用于实时控制。在线优化策略(模型预测控制,基于庞特里亚金最小值原理的等效燃油消耗策略,等效燃油最低原则)实时性较好,但是由于采用部分历史信息计算系统的等效燃油消耗,历史信息不一定能代表未来的行驶状态,导致这种算法的鲁棒性不好,需要采用性能更好的策略弥补上述算法的缺陷。机器学习(数据驱动优化),特别是近年来发展起来的强化学习(Reinforcement Learning)算法,为系统模型及控制参数优化、道路工况特征以及驾驶行为特征提取提供了有力的研究工具。在强化学习算法中,Q Learning和Deep Q Network(DQN)使用最为广泛,但是上述算法只适用于离散的和低维的动作空间,HEV能量管理控制任务具有高维和连续的动作空间。上述算法需要将动作空间离散化,这样做不可避免地丢失动作空间的重要的信息而且还会构成维度灾难(curse of dimensionality)问题。
发明内容
本发明通过提供基于分布式深度确定性策略梯度的HEV能量管理方法,解决了现有技术中HEV能量管理方法无法高效地适应于所有类型的道路工况、实时性较差的问题。
本发明提供基于分布式深度确定性策略梯度的HEV能量管理方法,包括以下步骤:
步骤1、获取混合动力汽车的状态需求信息;
步骤2、将所述状态需求信息作为输入量,基于神经网络构建回报函数;
步骤3、基于所述回报函数,构建分布式深度确定性策略梯度控制器;
步骤4、训练所述分布式深度确定性策略梯度控制器,获得稳定状态下的控制动作参数;
步骤5、通过训练好的分布式深度确定性策略梯度控制器执行能量管理策略。
优选的,所述状态需求信息包括:车辆状态信息、驾驶员需求信息;
所述车辆状态信息包括:电池荷电状态、发动机燃油消耗;
所述驾驶员需求信息包括:车辆转矩需求;所述车辆转矩需求包括:发动机输出转矩。
优选的,所述回报函数表示为:
其中,R
优选的,所述SOC平衡加权因子δ表示为:
其中,α表示加权因子的指数项。
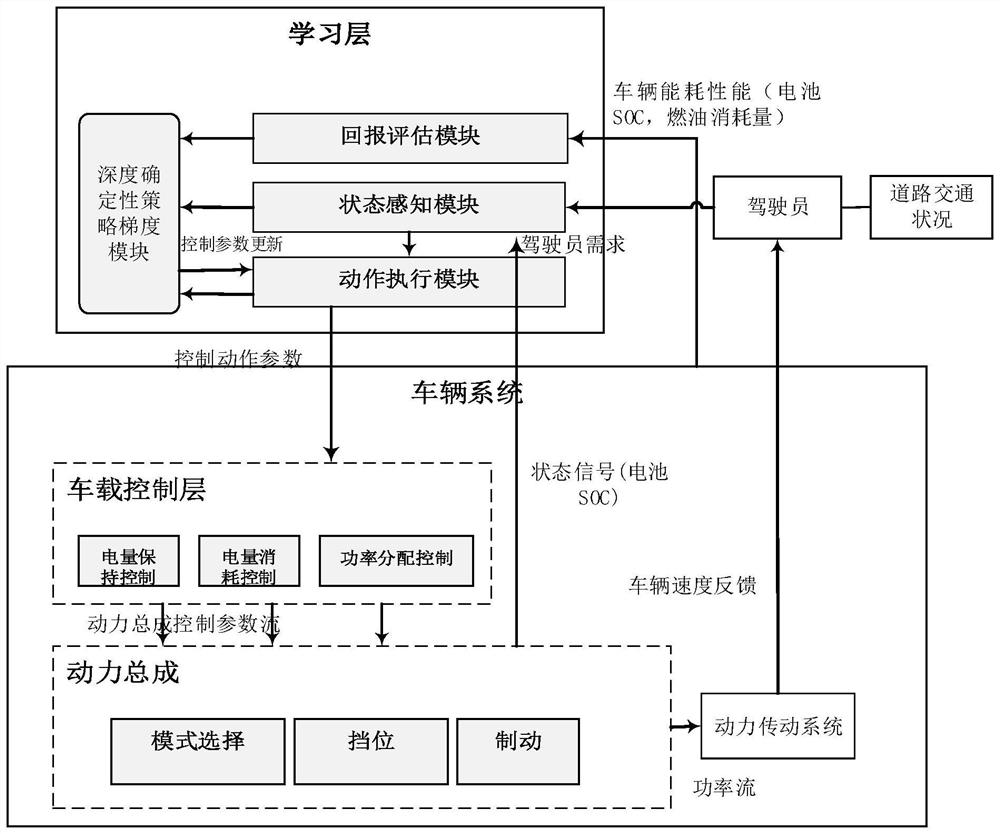
优选的,所述分布式深度确定性策略梯度控制器包括:学习层、控制层、执行层;
所述学习层接收来自驾驶员的所述驾驶员需求信息和来自所述执行层的所述车辆状态信息,执行深度确定性策略梯度算法,评估当前时刻控制策略的价值,与实际得到的回报进行对比,优化控制动作参数,将更新后的控制动作参数发送至所述控制层;
所述控制层基于所述控制动作参数,通过基于规则的控制策略进行功率分配控制,调节电池荷电状态在预设合理范围内,得到动力总成控制参数,并将所述动力总成控制参数发送至所述执行层;
所述执行层根据所述动力总成控制参数,选择驱动模式、变速器挡位,传递动力至动力传动系统。
优选的,所述学习层包括:状态感知模块、动作执行模块、回报评价模块、深度确定性策略梯度模块;
所述深度确定性策略梯度模块分别与所述状态感知模块、所述动作执行模块、所述回报评价模块连接;所述状态感知模块与所述动作执行模块连接。
优选的,所述状态感知模块接收所述车辆状态信息、所述驾驶员需求信息,并得到车辆系统当前时刻的状态;将所述车辆系统当前时刻的状态传递到所述深度确定性策略梯度模块和所述动作执行模块;
所述动作执行模块根据所述车辆系统当前时刻的状态选择控制动作参数,并将所述控制动作参数分别发送至所述深度确定性策略梯度模块、所述控制层;
所述回报评价模块接收动作被执行后的车辆状态信息,并根据所述回报函数对执行后的车辆状态信息进行评估,得到回报变量信息,并将所述回报变量信息发送至所述深度确定性策略梯度模块;
所述深度确定性策略梯度模块接收所述车辆系统当前时刻的状态、所述控制动作参数、所述回报变量信息,执行深度确定性策略梯度算法,优化所述控制动作参数,并将更新后的控制动作参数传递给所述动作执行模块。
优选的,所述动作执行模块根据所述状态需求信息得到控制动作参数的具体实现方式为:根据控制策略π:π(a|s)=P(A
其中,控制策略π(a|s)表示t时刻在状态s时采取动作a的概率,A
根据选择执行的动作得到所述控制动作参数,所述控制动作参数包括:发动机输出转矩。
优选的,所述深度确定性策略梯度模块包含演员网络、评论家网络;所述演员网络根据所述车辆系统当前时刻的状态选择执行的动作,所述评论家网络对所述选择执行的动作的价值进行评价,得到动作价值v
优选的,所述动作价值表示为:
v
其中,v
本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:
在发明中,首先获取混合动力汽车的状态需求信息,将状态需求信息作为输入量,基于神经网络构建回报函数;然后基于回报函数,构建分布式深度确定性策略梯度控制器;训练分布式深度确定性策略梯度控制器,获得稳定状态下的控制动作参数;最后,通过训练好的分布式深度确定性策略梯度控制器执行能量管理策略。本发明中的分布式深度确定性策略梯度控制器包括学习层、控制层、执行层。本发明采用具有分层拓扑结构的强化学习算法(DDPG)自适应在线优化控制策略,在顶层(学习层)基于贝尔曼理论的强化学习算法优化控制策略,底层(控制层和执行层)执行基于规则的实时控制策略。学习层和控制层、执行层分别布置在服务器电脑和车载控制器中,进行参数的实时处理,层与层通过V2X网络保证信息高效传递,充分保证车辆控制的实时性。本发明不仅仅保证深度确定性策略梯度算法的优化性能,而且保证层与层之间的策略参数的有效传递。通过该方法可以很大程度提高算法的实时性并且适用于多种道路工况。
附图说明
图1为本发明实施例提供的基于分布式深度确定性策略梯度的HEV能量管理方法的框架示意图;
图2为本发明实施例提供的基于分布式深度确定性策略梯度的HEV能量管理方法中深度确定性策略梯度智能体神经网络参数更新的示意简图;
图3为本发明实施例提供的基于分布式深度确定性策略梯度的HEV能量管理方法中加权因子的指数项分别取1、3、5时加权因子的变化趋势图。
具体实施方式
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)是强化学习算法中的一种,该算法吸收了演员-评论家算法和策略梯度算法单步更新的优势而且借鉴了DQN的精华,使用经验回放来解决维度灾难的问题,即深度确定性策略在确定性策略中引入了深度学习方法,结合了DQN的结构,提高了算法的稳定性和收敛性,该算法可以很好地处理连续的动作空间而不需要对动作空间进行离散化。本发明所采用的多层分布式深度确定性策略梯度能量管理方法,将学习层、控制层和执行层合理的分开,并保证各层之间恰当的配合。本发明不仅能使得算法更加高效,运算成本下降,而且能够提高算法的实时性,可以适用于多数复杂的行驶工况。
本实施例提供了基于分布式深度确定性策略梯度的HEV能量管理方法,参见图1,包括以下步骤:
步骤1、获取混合动力汽车的状态需求信息。
所述状态需求信息包括:车辆状态信息、驾驶员需求信息。所述车辆状态信息包括:电池荷电状态、发动机燃油消耗。所述驾驶员需求信息包括:车辆转矩需求;所述车辆转矩需求包括:发动机输出转矩。
车辆转矩需求对发动机燃油消耗和电池荷电状态都有影响。发动机转矩分配越多,油耗就高。驾驶员模型会根据道路工况计算出车辆转矩需求。
步骤2、将所述状态需求信息作为输入量,基于神经网络构建回报函数。
在车辆运行过程中,电池SOC基本保持在[0.3,0.8]范围内,所以为了减少不必要的计算成本,本发明所采用的算法在SOC∈[0.3,0.8]范围内进行优化和调整,在每一个时间步,瞬时SOC保持在范围[0.3,0.8],也有利于保护电池避免过充电和过放电。
因此,所述回报函数表示为:
其中,R
所述SOC平衡加权因子δ表示为:
其中,α表示加权因子的指数项。设置SOC平衡加权因子δ以在行驶过程中维持电池SOC的平衡。δ不仅能够反映SOC值与初始值SOC
步骤3、基于所述回报函数,构建分布式深度确定性策略梯度控制器。
所述分布式深度确定性策略梯度控制器包括:学习层、控制层、执行层。
所述学习层接收来自驾驶员的所述驾驶员需求信息和来自所述执行层的所述车辆状态信息,执行深度确定性策略梯度算法,评估当前时刻控制策略的价值,与实际得到的回报进行对比,优化控制动作参数,将更新后的控制动作参数发送至所述控制层。
所述控制层基于所述控制动作参数,通过基于规则的控制策略进行功率分配控制,使得发动机工作在高效率区,调节电池荷电状态在预设合理范围内,如果电池SOC低于合理范围,发动机提供一部分功率给电池充电;如果电池SOC高于合理范围内,则根据道路工况需求,适时关闭发动机,采取纯电驱动模式,实现电量保持控制;得到发动机工作模式,变速器挡位,制动能量回收命令等动力总成控制参数,并将所述动力总成控制参数发送至所述执行层。
所述执行层根据所述动力总成控制参数,选择驱动模式(并联驱动模式或者纯电动驱动模式)、变速器挡位,传递动力至动力传动系统,驱动车辆行驶,并且将车速信息反馈到驾驶员,驾驶员通过实际车速与工况车速偏差,道路工况坡度,风阻等变化调整车辆需求转矩,并传递到学习层。
其中,所述学习层包括:状态感知模块、动作执行模块、回报评价模块、深度确定性策略梯度模块。所述深度确定性策略梯度模块分别与所述状态感知模块、所述动作执行模块、所述回报评价模块连接;所述状态感知模块与所述动作执行模块连接。
所述状态感知模块接收所述车辆状态信息、所述驾驶员需求信息,并得到车辆系统当前时刻的状态;将所述车辆系统当前时刻的状态传递到所述深度确定性策略梯度模块和所述动作执行模块,对动作执行模块执行控制策略提供依据。
所述动作执行模块根据所述车辆系统当前时刻的状态选择控制动作参数,并将所述控制动作参数分别发送至所述深度确定性策略梯度模块、所述控制层。
所述回报评价模块接收动作被执行后的车辆状态信息(包括车辆燃油消耗和剩余电池SOC),并根据所述回报函数对执行后的车辆状态信息进行评估,得到回报变量信息,并将所述回报变量信息发送至所述深度确定性策略梯度模块。
所述深度确定性策略梯度模块接收所述车辆系统当前时刻的状态、所述控制动作参数、所述回报变量信息,执行深度确定性策略梯度算法,优化所述控制动作参数,并将更新后的控制动作参数传递给所述动作执行模块。
下面对各个模块做进一步的说明。
(1)状态感知模块:状态感知模块主要负责根据传感器信号决定车辆的当前状态。
电池荷电状态(SOC)和车辆转矩需求作为状态变量以最小的计算工作量获得学习系统的最佳性能。状态变量会被送到深度确定性策略梯度模块和动作执行模块分别进行并行计算和控制车载控制器。
S(t)=[Eng
其中,S(t)、Eng
(2)动作执行模块:动作执行模块连接了状态感知模块,深度确定性策略梯度模块和车载控制器,车载控制器包括发动机-起动机组控制器和电池管理控制器。动作执行模块的初衷是选择可以最大化累计奖励的动作。
所述动作执行模块根据所述状态需求信息得到控制动作参数的具体实现方式为:根据控制策略π:π(a|s)=P(A
(3)回报评价模块:回报评价模块评价动力传动系统的性能,包括能量消耗和电池剩余SOC,该模块可以直接影响深度网络参数的调整。在控制动作被执行以后,该模块通过回报函数评估车辆的性能。在每一个采样时刻回报函数都会被返回到深度确定性策略梯度模块。这有助于训练最优控制策略,使得累计燃油消耗小的同时保持电池SOC在一定范围。
(4)深度确定性策略梯度模块:该模块从其他三个模块接收状态,动作和回报变量,然后执行DDPG算法通过更新回报函数优化动作执行策略。DDPG算法参数更新简图如图2所示。所述深度确定性策略梯度模块包含演员网络、评论家网络;所述演员网络根据所述车辆系统当前时刻的状态选择执行的动作,所述评论家网络对所述选择执行的动作的价值进行评价,得到动作价值v
所述动作价值表示为:
v
其中,v
即演员网络负责根据接收到的状态决定输出的控制动作,评论家网络接收来自演员网络的控制动作并预测该动作的价值。将算法运行后得到的实际回报和评论家网络给出的价值进行对比,会得到一个误差。根据这个误差判断评论家网络应该怎样调整参数才能够得到更加准确的价值,同时判断当前动作的好坏,由此达到参数更新的目的。
步骤4、训练所述分布式深度确定性策略梯度控制器,获得稳定状态下的控制动作参数。
即通过训练获得调整优化后得到的控制动作参数。
步骤5、通过训练好的分布式深度确定性策略梯度控制器执行能量管理策略。
下面对本发明做进一步的说明。
本发明通过传感器采集分布式深度确定性策略梯度控制器所需的状态需求信息,例如车辆总需求转矩信号,电池SOC值,发动机输出转矩,当前时刻车辆挡位以及混合动力车辆运行的模式(纯电驱动模式或者油电混合驱动模式)等,并将采集到的信息传递到相应的模块。根据实际控制需求,设计简洁高效的回报函数。构建分布式深度确定性策略梯度控制器。在标准工况或者实际道路工况训练分布式深度确定性策略梯度控制器,获得稳定状态下的控制参数。实际应用中,在构建分布式深度确定性策略梯度控制器时,根据实际需要微调参数。
其中,分布式深度确定性策略梯度控制器执行的深度确定性策略梯度算法,即DDPG算法的步骤如表1所示:
综上,本发明不仅仅保证深度确定性策略梯度算法的优化性能,而且保证层与层之间的策略参数的有效传递,能够很大程度提高算法的实时性并且适用于多种道路工况。
本发明实施例提供的基于分布式深度确定性策略梯度的HEV能量管理方法至少包括如下技术效果:
(1)本发明采用多层分布式深度确定性策略梯度,将优化学习层和控制层以及执行层分离,在不同的处理器处理,能够有效提高运算速度,精确度,提高车辆的实时控制性能。不仅仅研究深度确定性策略梯度算法,而且注重层与层之间参数交互。
(2)本发明根据车辆实时运行时电池SOC范围[0.3,0.8],精简设计回报函数,减少不必要的运算成本。
(3)本发明权重因子取值考虑了电池SOC的变化,能够反映电池SOC和初值的瞬时偏差和累积偏差以及制动能量回收。
最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 基于分布式深度确定性策略梯度的HEV能量管理方法
- 一种基于确定性策略梯度学习的PHEV能量管理方法