高丝氨酸乙酰转移酶突变体及其在生产O-乙酰高丝氨酸中的应用
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及一种酶活性和抗反馈抑制提升的高丝氨酸乙酰转移酶突变体及其在制备O-乙酰高丝氨酸中应用,属于生物工程领域。
背景技术
L-甲硫氨酸是一种重要的含硫氨基酸,广泛应用于饲料,食品,医药以及化妆品等领域,具有广阔的应用前景(Huang JF,
发明内容
本发明的首要目的在于提供一种高丝氨酸乙酰转移酶突变体,以使得其酶活性和抗反馈抑制能力得到提高。
本发明提供一种来源于
其中最优选地,仅存在第147位由苯丙氨酸突变为异亮氨酸,第182位由甲硫氨酸突变为苏氨酸以及第240位甲硫氨酸突变为甘氨酸中的组合突变。
本发明进一步提供所述高丝氨酸乙酰转移酶突变体的编码基因。优先地实施方式中,所述高丝氨酸乙酰转移酶突变体的编码基因的核苷酸序列是在SEQ ID No.1所示核苷酸酸序列的基础进行突变获得的。在更具体地实施方式中,所述的高丝氨酸乙酰转移酶突变体的编码基因核苷酸序列优选为SEQ ID No.3(编码G118V-F147I-M182T)、SEQ ID No.4(编码 G118V-F147I-M240G)、SEQ ID No.5(编码F147I-M182T-M240G)以及SEQ ID No.6(编码 G118V-F147I-M182T-M240G)所示。
本发明还提供含有如所述这高丝氨酸乙酰转移酶突变体的编码基因的表达载体和宿主细胞。
本发明还提供所述的高丝氨酸乙酰转移酶突变体或其编码基因在制备
本发明是通过下述的技术思路实现的:将来源于
本发明采用高通量筛选的方法对所述的高丝氨酸乙酰转移酶突变体质粒文库进行高通量筛选,获得了三个酶活性提高的突变体,其突变位点分别为G118V、F147I和M182T(即原始基因序列的第118位由甘氨酸突变为缬氨酸,第147位由苯丙氨酸突变为异亮氨酸,第182位由甲硫氨酸突变为苏氨酸)。
本发明还对所述的高丝氨酸乙酰转移酶进行同源建模,并对底物通道3Å范围内的氨基酸残基(L236,M240,Y267,E270,P348,A349,L356和P357)进行饱和定点突变,经过高通量筛选获得了酶活性和抗反馈抑制能力提高的突变体M240G(即原始基因序列的第240位甲硫氨酸突变为甘氨酸)。最后还所获得的酶活性提高的突变体G118V、F147I、M182T和M240G进行组合突变,获得了最优的突变组合F147I-M182T-M240G,该突变体具有最高的酶活性和抗反馈抑制能力。
其中,在进行研究时,先对所述高丝氨酸乙酰转移酶(HAT)基因进行密码子优化(优化后的核苷酸序列如SEQ ID No.1所示),以更有利于表达和达到最终效果。
本发明针对高丝氨酸乙酰转移酶催化活性低和/或反馈抑制强烈等问题,分别利用易错PCR随机突变和基于结构信息的定点饱和突变方法获得了多种酶活性和/或抗反馈抑制能力提高的高丝氨酸乙酰转移酶突变体。在最最优的突变组合体即F147I-M182T-M240G,其酶活性比野生型提高了15.2倍,并具有较强的反馈抑制抗性,当10 mM
附图说明
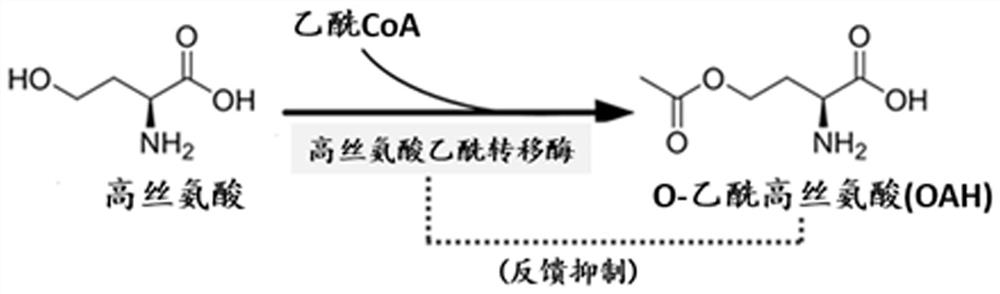
图1 高丝氨酸乙酰转移酶催化反应示意图。
图2高丝氨酸乙酰转移酶有益突变位点的组合突变体的酶活。
具体实施方式
下面通过实施例来进一步说明本发明的内容,但不应理解为对本发明的限制。实施例中所使用的实验方法如无特殊说明,均为常规方法。实施例中所使用的材料、试剂等如无特殊说明,均可从商业途径得到。
实施例1:高丝氨酸乙酰转移酶的诱导表达和酶活测定
1.1重组质粒的构建
本发明将来源于
1.2将重组质粒的转化至大肠杆菌BL21(DE3)中
具体转化方法为:(1)取10 μL重组质粒于50 μL大肠杆菌BL21(DE3)感受态细胞中,冰浴30 min;(2)42℃水浴热激90 s,快速置于冰上1~2 min;(3)加入新鲜LB液体培养基(蛋白胨10 g/L,酵母粉5 g/L,NaCl 10 g/L)600 μL,于37 ºC振荡培养60 min;(4)取200μL菌液涂布于含有100 μg/mL氨苄青霉素的LB固体培养基表面,37 ºC培养12~16 h。
1.3高丝氨酸乙酰转移酶的诱导表达
具体方法为:挑取单菌落至含有氨苄青霉素的LB液体培养基中,37 ºC、200 r/min培养过夜。将过夜培养的种子液以1%的接种量转接到新鲜的含有氨苄青霉素的LB液体培养基中,37 ºC、200 r/min培养至OD
1.4 高丝氨酸乙酰转移酶的酶活测定
收集诱导表达的菌体,离心去除培养基,加入5 mL 50 mM Tris-HCl缓冲液重悬,使用超声波细胞破碎仪破碎细胞,设定200W功率,超声2 s间歇1 s,超声10 min;随后在高速冷冻离心机上8000×g离心10 min,收集上清用于酶活测定。酶活测定体系为:50 mMTris-HCl(pH 7.0),2 mM 高丝氨酸(homoserine),0.12 mM acetyl-CoA,1 mM 5,5'-二硫代双(2-硝基苯甲酸) DTNB,适当稀释的粗酶液。以不加homoserine样品为空白对照,室温下使用酶标仪测定412 nm的吸光值。由于DTNB不稳定,见光易分解,需现配现用,并在测定时需重复制作CoA标准曲线。标准曲线的测定体系为:50 mM Tris-HCl(pH 7.0),2 mMhomoserine,0~0.1 mM CoA,1 mM DTNB。MetX的酶活单位定义为:单位时间内(min)生成1 μmol CoA所需的酶量。
经酶标仪检测,来源于
实施例2:采用易错PCR方法定向进化高丝氨酸乙酰转移酶
2.1 高丝氨酸乙酰转移酶突变体文库的构建
本发明首先采用易错PCR的方法构建高丝氨酸乙酰转移酶突变体文库。本发明采用的易错PCR体系为:10 x Taq 缓冲液,5 μL;25 mmol/L Mg
将上述获得的PCR产物经1%的琼脂糖凝胶电泳检测后,采用胶回收试剂盒进行切胶回收。然后通过限制性内切酶
2.2高丝氨酸乙酰转移酶突变体文库的高通量筛选
将实施例2中的第2.1点获得的含有高丝氨酸乙酰转移酶突变体文库的大肠杆菌,挑取单克隆接种至已含有800 μL LB液体培养基的96 深孔板中,37 ºC、800 r/min震荡培养。当菌体浓度OD
按照实施例1中的第1.4点所述的酶活测定方法,对上述获得的突变体文库进行酶活测定,从约1000个突变体中筛选获得三个酶活明显提升的候选突变体,即G118V、F147I和M182T。然后将三个含有候选突变体的菌株按照实施例1.3所示的方法,重新进行诱导表达和酶活验证。
结果表明,高丝氨酸乙酰转移酶突变体G118V、F147I和M182T的酶活性可达8.37±0.42、7.68±0.51和6.49±0.24 U/mg 蛋白质,分别是野生型高丝氨酸乙酰转移酶活性的9.7倍、8.9倍和7.5倍。然而,上述三个突变体仍然受到目标产物OAH的较明显反馈抑制作用,在10 mM OAH存在时,三个突变体仅能保留20%~25%的剩余酶活。
实施例3:3Å范围内底物通道氨基酸残基的定点饱和突变
本发明首先利用软件RosettaCM,以来源于
本发明所采用定点饱和突变具体方法为:在待突变的氨基酸位点设计随机的兼并引物NNK(其中N代表A、C、G或T,K代表G或T),如下所示;
以含有密码子优化后高丝氨酸乙酰转移酶基因的pET21b质粒为模板,利用上述兼并引物,通过PCR扩增获得基因突变文库;随后采用基于Golden Gate 克隆的片段装配方法连接成完整质粒文库。Golden Gate组装体系为:10 x T4连接酶缓冲液,1.5 μL;100 xBSA,1.5 μL;
按照实施例1中的第1.4点所述的酶活测定方法,将上述获得的突变体文库进行酶活测定。从8个位点的饱和突变中筛选获得1个酶活性提高的候选突变体,即M240G。然后将该突变体菌株按照实施例1中的第1.3点所示的方法重新进行诱导表达和酶活验证。
结果表明,突变体M240G酶活性达到2.73±0.35 U/mg蛋白质,是野生型的3.21倍。同时该突变体酶有较强的反馈抑制能力,在10 mM OAH存在时,仍能保留54.2%的剩余酶活(1.48 U/mg 蛋白质)。
实施例4:有益突变位点的组合突变进一步提高酶活性
4.1有益突变位点的组合突变
为了进一步提高酶的催化能力,将上述获得突变位点G118V、F147I、M182T和M240G进行组合突变。本发明所涉及的定点突变采用QuikChange定点突变试剂盒(QuikChangeSite-Directed Mutagenesis Kit)完成,所涉及的引物如下:
QuikChange定点突变体系为:10´Phusion 缓冲液,5 μL;10 μmol 引物1,2 μL;10μmol 引物2,2 μL;10 mmol/L dNTP,4 μL;50 ng DNA 模板;Phusion High-Fidelity DNA聚合酶,5 U;补充ddH
将上述获得的反应液转化至大肠杆菌BL21(DE3)感受态中,具体转化方法如实施例1中的第1.2点所示。挑取单菌落进行测序验证,最终构建了6个双突变体组合(G118V-F147I、G118V-M182T、G118V-M240G、F147I-M182T、F147I-M240G和M182T-M240G),3个三突变体组合(G118V-F147I-M182T、F147I-M182T-M240G和G118V-M182T-M240G)以及1个四突变体组合(G118V-F147I-M182T-M240G)。
4.2高丝氨酸乙酰转移酶突变体诱导表达及酶活测定
将上述获得的含有高丝氨酸乙酰转移酶组合突变体的菌株接种于含有氨苄青霉素的LB液体培养基中,37ºC、200 r/min培养过夜。将过夜培养的种子液以1%的接种量转接到新鲜的含有氨苄青霉素的LB液体培养基中,37 ºC、200 r/min培养至OD
按照实施例1中的第1.4点所述的方法,进行酶活分析,测定结果如表1和图2所示。表中所列出的突变体均表现相对于贤野生型来说有提高的酶活性(至少是约9.4倍),其中高丝氨酸乙酰转移酶突变体F147I-M182T-M240G表现出最高的酶催化能力,其酶活性为12.96 ± 0.19 U/mg 蛋白质,是野生型的15.25倍。所列出的突变体均表现增加的抗反馈抑制能力,其中仍以高丝氨酸乙酰转移酶突变体F147I-M182T-M240G表现最优,在10 mMOAH存在时,突变体能保留42.7%的剩余酶活,酶性活仍达5.54 ± 0.23 U/mg 蛋白质。其中本实施例中,G118V-F147I-M182T突变的编码核苷酸序列如SEQ ID No.3所示,G118V-F147I-M240G 如SEQ ID No.4所示,F147I-M182T-M240G 如SEQ ID No.5所示,G118V-F147I-M182T-M240G 如SEQ ID No.6所示。
表1高丝氨酸乙酰转移酶有益突变位点的组合突变体的酶活
因此,所述的高丝氨酸乙酰转移酶突变体具有明显优于野生型的催化活性,具有良好的应用前景。
实施例5:构建工程菌株发酵生产
基于实施例4获得的高丝氨酸乙酰转移酶组合突变体,构建微生物细胞工厂用于发酵生产
将上述获得的菌株接种于LB培养基中,过夜培养后,接种于含有50 mL新鲜的种子培养基(5 g/L酵母粉,5 g/L蛋白胨,15 g/L葡萄糖,尿素0.1 g/L,玉米浆 15 g/L,硫酸铵15 g/L,pH为6.5)的500 mL三角瓶中,培养16 h至对数中期。按照10%接种量接种至新鲜发酵培养基中(葡萄糖50 g/L,玉米浆 20 g/L,(NH4)
菌株发酵培养60 h后,取样使用高效液相色谱测定发酵液中O-乙酰高丝氨酸含量。结果如表2所示。
表2 菌株生产O-乙酰高丝氨酸的发酵分析
从结果可知,在大肠杆菌或谷氨酸棒杆菌中过表达高丝氨酸乙酰转移酶突变体F147I-M182T-M240G后,相较于原始出发菌而言,菌株OAH发酵生产能力分别提升13.2倍和10.8倍。因此,构建酶活性和抗反馈抑制能力提高的高丝氨酸乙酰转移酶突变体,对于大肠杆菌或谷氨酸棒杆菌等底盘菌株高效生产O-乙酰高丝氨酸具有重要的应用价值。
序列表
<110> 中国科学院天津工业生物技术研究所
<120> 高丝氨酸乙酰转移酶突变体及其在生产O-乙酰高丝氨酸中的应用
<160> 32
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1137
<212> DNA
<213> Leptospira meyeri
<400> 1
atgccaacct ccgaacagaa cgaattctcc cacggctctg tcggcgtcgt gtacacccaa 60
tccatccgct tcgaatccct caccctggaa ggtggcgaga ccatcacccc tctggaaatt 120
gcctacgaga cctacggcac cctgaacgag aagaaagaca acgccatcct ggtctgccat 180
gccctgtccg gtgacgccca cgcagcaggc ttccacgaag gtgacaagcg ccctggctgg 240
tgggattact acatcggccc aggcaagtct tttgacacca accgctactt catcatctcc 300
tccaacgtga tcggcggttg caaaggttcc tccggcccac tcaccatcaa cggcaagaac 360
ggtaagccat ttcagtccac cttcccattc gtgtccatcg gtgatatggt caacgcccag 420
gagaagctga tctcccattt cggcatccac aagctcttcg cagtggccgg tggttctatg 480
ggcggcatgc aggccctgca atggtccgtc gcctaccctg accgcctcaa gaactgcatt 540
gtgatggcct cctcctctga gcactccgcc cagcagatcg catttaacga ggtgggccgt 600
caggccatcc tgtccgaccc taactggaac caaggcctgt atacccagga gaaccgccct 660
tccaagggtc tggcactggc ccgtatgatg ggccacatca cctacctgtc cgacgagatg 720
atgcgcgaaa aattcggccg caagccacca aagggcaaca tccagtccac cgacttcgca 780
gtgggctcct acctgattta ccagggcgag tccttcgtcg accgcttcga tgcaaactcc 840
tacatctacg tcaccaaggc actggaccac ttctccctgg gcaccggcaa ggaactgacc 900
aaggtgctcg ccaaagtccg ctgccgcttc ctcgtggtcg cctatacctc cgattggctg 960
tacccaccat accagtccga ggagatcgtg aagtccctcg aagtgaacgc agtgcctgtc 1020
tccttcgtgg aactcaataa cccagcaggc cacgattctt tcctgctgcc atccgaacag 1080
caggattcca tcctgcgcga cttcctgtcc tctactgatg aaggcgtgtt cctgtaa 1137
<210> 2
<211> 378
<212> DNA
<213> Leptospira meyeri
<400> 2
MPTSEQNEFS HGSVGVVYTQ SIRFESLTLE GGETITPLEI AYETYGTLNE KKDNAILVCH 60
ALSGDAHAAG FHEGDKRPGW WDYYIGPGKS FDTNRYFIIS SNVIGGCKGS SGPLTINGKN 120
GKPFQSTFPF VSIGDMVNAQ EKLISHFGIH KLFAVAGGSM GGMQALQWSV AYPDRLKNCI 180
VMASSSEHSA QQIAFNEVGR QAILSDPNWN QGLYTQENRP SKGLALARMM GHITYLSDEM 240
MREKFGRKPP KGNIQSTDFA VGSYLIYQGE SFVDRFDANS YIYVTKALDH FSLGTGKELT 300
KVLAKVRCRF LVVAYTSDWL YPPYQSEEIV KSLEVNAVPV SFVELNNPAG HDSFLLPSEQ 360
QDSILRDFLS STDEGVFL 378
<210> 3
<211> 1137
<212> DNA
<213> 人工序列
<400> 3
atgccaacct ccgaacagaa cgaattctcc cacggctctg tcggcgtcgt gtacacccaa 60
tccatccgct tcgaatccct caccctggaa ggtggcgaga ccatcacccc tctggaaatt 120
gcctacgaga cctacggcac cctgaacgag aagaaagaca acgccatcct ggtctgccat 180
gccctgtccg gtgacgccca cgcagcaggc ttccacgaag gtgacaagcg ccctggctgg 240
tgggattact acatcggccc aggcaagtct tttgacacca accgctactt catcatctcc 300
tccaacgtga tcggcggttg caaaggttcc tccggcccac tcaccatcaa cgtcaagaac 360
ggtaagccat ttcagtccac cttcccattc gtgtccatcg gtgatatggt caacgcccag 420
gagaagctga tctcccatat cggcatccac aagctcttcg cagtggccgg tggttctatg 480
ggcggcatgc aggccctgca atggtccgtc gcctaccctg accgcctcaa gaactgcatt 540
gtgacggcct cctcctctga gcactccgcc cagcagatcg catttaacga ggtgggccgt 600
caggccatcc tgtccgaccc taactggaac caaggcctgt atacccagga gaaccgccct 660
tccaagggtc tggcactggc ccgtatgatg ggccacatca cctacctgtc cgacgagatg 720
atgcgcgaaa aattcggccg caagccacca aagggcaaca tccagtccac cgacttcgca 780
gtgggctcct acctgattta ccagggcgag tccttcgtcg accgcttcga tgcaaactcc 840
tacatctacg tcaccaaggc actggaccac ttctccctgg gcaccggcaa ggaactgacc 900
aaggtgctcg ccaaagtccg ctgccgcttc ctcgtggtcg cctatacctc cgattggctg 960
tacccaccat accagtccga ggagatcgtg aagtccctcg aagtgaacgc agtgcctgtc 1020
tccttcgtgg aactcaataa cccagcaggc cacgattctt tcctgctgcc atccgaacag 1080
caggattcca tcctgcgcga cttcctgtcc tctactgatg aaggcgtgtt cctgtaa 1137
<210> 4
<211> 1137
<212> DNA
<213> 人工序列
<400> 4
atgccaacct ccgaacagaa cgaattctcc cacggctctg tcggcgtcgt gtacacccaa 60
tccatccgct tcgaatccct caccctggaa ggtggcgaga ccatcacccc tctggaaatt 120
gcctacgaga cctacggcac cctgaacgag aagaaagaca acgccatcct ggtctgccat 180
gccctgtccg gtgacgccca cgcagcaggc ttccacgaag gtgacaagcg ccctggctgg 240
tgggattact acatcggccc aggcaagtct tttgacacca accgctactt catcatctcc 300
tccaacgtga tcggcggttg caaaggttcc tccggcccac tcaccatcaa cgtcaagaac 360
ggtaagccat ttcagtccac cttcccattc gtgtccatcg gtgatatggt caacgcccag 420
gagaagctga tctcccatat cggcatccac aagctcttcg cagtggccgg tggttctatg 480
ggcggcatgc aggccctgca atggtccgtc gcctaccctg accgcctcaa gaactgcatt 540
gtgatggcct cctcctctga gcactccgcc cagcagatcg catttaacga ggtgggccgt 600
caggccatcc tgtccgaccc taactggaac caaggcctgt atacccagga gaaccgccct 660
tccaagggtc tggcactggc ccgtatgatg ggccacatca cctacctgtc cgacgaggga 720
atgcgcgaaa aattcggccg caagccacca aagggcaaca tccagtccac cgacttcgca 780
gtgggctcct acctgattta ccagggcgag tccttcgtcg accgcttcga tgcaaactcc 840
tacatctacg tcaccaaggc actggaccac ttctccctgg gcaccggcaa ggaactgacc 900
aaggtgctcg ccaaagtccg ctgccgcttc ctcgtggtcg cctatacctc cgattggctg 960
tacccaccat accagtccga ggagatcgtg aagtccctcg aagtgaacgc agtgcctgtc 1020
tccttcgtgg aactcaataa cccagcaggc cacgattctt tcctgctgcc atccgaacag 1080
caggattcca tcctgcgcga cttcctgtcc tctactgatg aaggcgtgtt cctgtaa 1137
<210> 5
<211> 1137
<212> DNA
<213> 人工序列
<400> 5
atgccaacct ccgaacagaa cgaattctcc cacggctctg tcggcgtcgt gtacacccaa 60
tccatccgct tcgaatccct caccctggaa ggtggcgaga ccatcacccc tctggaaatt 120
gcctacgaga cctacggcac cctgaacgag aagaaagaca acgccatcct ggtctgccat 180
gccctgtccg gtgacgccca cgcagcaggc ttccacgaag gtgacaagcg ccctggctgg 240
tgggattact acatcggccc aggcaagtct tttgacacca accgctactt catcatctcc 300
tccaacgtga tcggcggttg caaaggttcc tccggcccac tcaccatcaa cggcaagaac 360
ggtaagccat ttcagtccac cttcccattc gtgtccatcg gtgatatggt caacgcccag 420
gagaagctga tctcccatat cggcatccac aagctcttcg cagtggccgg tggttctatg 480
ggcggcatgc aggccctgca atggtccgtc gcctaccctg accgcctcaa gaactgcatt 540
gtgacggcct cctcctctga gcactccgcc cagcagatcg catttaacga ggtgggccgt 600
caggccatcc tgtccgaccc taactggaac caaggcctgt atacccagga gaaccgccct 660
tccaagggtc tggcactggc ccgtatgatg ggccacatca cctacctgtc cgacgaggga 720
atgcgcgaaa aattcggccg caagccacca aagggcaaca tccagtccac cgacttcgca 780
gtgggctcct acctgattta ccagggcgag tccttcgtcg accgcttcga tgcaaactcc 840
tacatctacg tcaccaaggc actggaccac ttctccctgg gcaccggcaa ggaactgacc 900
aaggtgctcg ccaaagtccg ctgccgcttc ctcgtggtcg cctatacctc cgattggctg 960
tacccaccat accagtccga ggagatcgtg aagtccctcg aagtgaacgc agtgcctgtc 1020
tccttcgtgg aactcaataa cccagcaggc cacgattctt tcctgctgcc atccgaacag 1080
caggattcca tcctgcgcga cttcctgtcc tctactgatg aaggcgtgtt cctgtaa 1137
<210> 6
<211> 1137
<212> DNA
<213> 人工序列
<400> 6
atgccaacct ccgaacagaa cgaattctcc cacggctctg tcggcgtcgt gtacacccaa 60
tccatccgct tcgaatccct caccctggaa ggtggcgaga ccatcacccc tctggaaatt 120
gcctacgaga cctacggcac cctgaacgag aagaaagaca acgccatcct ggtctgccat 180
gccctgtccg gtgacgccca cgcagcaggc ttccacgaag gtgacaagcg ccctggctgg 240
tgggattact acatcggccc aggcaagtct tttgacacca accgctactt catcatctcc 300
tccaacgtga tcggcggttg caaaggttcc tccggcccac tcaccatcaa cgtcaagaac 360
ggtaagccat ttcagtccac cttcccattc gtgtccatcg gtgatatggt caacgcccag 420
gagaagctga tctcccatat cggcatccac aagctcttcg cagtggccgg tggttctatg 480
ggcggcatgc aggccctgca atggtccgtc gcctaccctg accgcctcaa gaactgcatt 540
gtgacggcct cctcctctga gcactccgcc cagcagatcg catttaacga ggtgggccgt 600
caggccatcc tgtccgaccc taactggaac caaggcctgt atacccagga gaaccgccct 660
tccaagggtc tggcactggc ccgtatgatg ggccacatca cctacctgtc cgacgaggga 720
atgcgcgaaa aattcggccg caagccacca aagggcaaca tccagtccac cgacttcgca 780
gtgggctcct acctgattta ccagggcgag tccttcgtcg accgcttcga tgcaaactcc 840
tacatctacg tcaccaaggc actggaccac ttctccctgg gcaccggcaa ggaactgacc 900
aaggtgctcg ccaaagtccg ctgccgcttc ctcgtggtcg cctatacctc cgattggctg 960
tacccaccat accagtccga ggagatcgtg aagtccctcg aagtgaacgc agtgcctgtc 1020
tccttcgtgg aactcaataa cccagcaggc cacgattctt tcctgctgcc atccgaacag 1080
caggattcca tcctgcgcga cttcctgtcc tctactgatg aaggcgtgtt cctgtaa 1137
<210> 7
<211> 41
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 7
caccaggtct caatcaccta cnnktccgac gagatgatgc g 41
<210> 8
<211> 35
<212> DNA
<213> 人工序列
<400> 8
caccaggtct catgatgtgg cccatcatac gggcc 35
<210> 9
<211> 44
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 9
caccaggtct catccgacga gnnkatgcgc gaaaaattcg gccg 44
<210> 10
<211> 35
<212> DNA
<213> 人工序列
<400> 10
caccaggtct cacggacagg taggtgatgt ggccc 35
<210> 11
<211> 39
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 11
caccaggtct catacctgat tnnkcagggc gagtccttc 39
<210> 12
<211> 35
<212> DNA
<213> 人工序列
<400> 12
caccaggtct caggtaggag cccactgcga agtcg 35
<210> 13
<211> 39
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 13
caccaggtct cataccaggg cnnktccttc gtcgaccgc 39
<210> 14
<211> 38
<212> DNA
<213> 人工序列
<400> 14
caccaggtct caggtaaatc aggtaggagc ccactgcg 38
<210> 15
<211> 41
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 15
caccaggtct cacaataacn nkgcaggcca cgattctttc c 41
<210> 16
<211> 37
<212> DNA
<213> 人工序列
<400> 16
caccaggtct caattgagtt ccacgaagga gacaggc 37
<210> 17
<211> 41
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 17
caccaggtct cataacccan nkggccacga ttctttcctg c 41
<210> 18
<211> 42
<212> DNA
<213> 人工序列
<400> 18
caccaggtct cagttattga gttccacgaa ggagacaggc ac 42
<210> 19
<211> 37
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 19
caccaggtct catttcctgn nkccatccga acagcag 37
<210> 20
<211> 33
<212> DNA
<213> 人工序列
<400> 20
caccaggtct cagaaagaat cgtggcctgc tgg 33
<210> 21
<211> 33
<212> DNA
<213> 人工序列
<223> n=a或c或g或t,k=g或t
<400> 21
caccaggtct catgctgnnk tccgaacagc agg 33
<210> 22
<211> 35
<212> DNA
<213> 人工序列
<400> 22
caccaggtct caagcaggaa agaatcgtgg cctgc 35
<210> 23
<211> 41
<212> DNA
<213> 人工序列
<400> 23
tcaccatcaa cgtcaagaac ggtaagccat ttcagtccac c 41
<210> 24
<211> 37
<212> DNA
<213> 人工序列
<400> 24
tggcttaccg ttcttgacgt tgatggtgag tgggccg 37
<210> 25
<211> 37
<212> DNA
<213> 人工序列
<400> 25
ctcccatatc ggcatccaca agctcttcgc agtggcc 37
<210> 26
<211> 40
<212> DNA
<213> 人工序列
<400> 26
gaagagcttg tggatgccga tatgggagat cagcttctcc 40
<210> 27
<211> 38
<212> DNA
<213> 人工序列
<400> 27
cctcaagaac tgcattgtga cggcctcctc ctctgagc 38
<210> 28
<211> 37
<212> DNA
<213> 人工序列
<400> 28
ggaggccgtc acaatgcagt tcttgaggcg gtcaggg 37
<210> 29
<211> 28
<212> DNA
<213> 人工序列
<400> 29
acgagggaat gcgcgaaaaa ttcggccg 28
<210> 30
<211> 28
<212> DNA
<213> 人工序列
<400> 30
cggccgaatt tttcgcgcat tccctcgt 28
<210> 31
<211> 31
<212> DNA
<213> 人工序列
<400> 31
ctagaagctt atgccaacct ccgaacagaa c 31
<210> 32
<211> 31
<212> DNA
<213> 人工序列
<400> 32
ctagggtacc ttacaggaac acgccttcat c 31
- 高丝氨酸乙酰转移酶突变体及其在生产O-乙酰高丝氨酸中的应用
- 高丝氨酸乙酰转移酶突变体及其在生产O-乙酰高丝氨酸中的应用