一种跨模态文本图片检索模型的建模方法
文献发布时间:2023-06-19 10:29:05
【技术领域】
本发明涉及数据处理技术领域,尤其涉及一种跨模态文本图片检索模型的建模方法。
【背景技术】
随着移动通信与计算能力的不断突破,非结构化数据,如图片、视频、音频、文本等呈爆炸式增长,为用户提供了更加方便的线上体验。但是传统的搜索算法只利用了少部分的产品内容信息,信息利用率较低。如在使用文本搜索图片的场景下,用户输入搜索文本后,计算产品标签和文本的相似度,将具有更相似标签的图片返回给用户。但是用户在搜索资源时使用的检索词通常比较模糊;图片的标签相比于图片本身可能也存在偏差,使得搜索的结果并不能很好的满足用户需求。而对文字和图片的跨模态的学习,能够直接提取图片的特征和标签,计算文本和图片的匹配度,提高了top-N搜索的准确性和可解释性,提升用户的体验感。
在金融场景中,研究员在做分析报告的时候,经常会用到机构发布报告中的一些相关图片,在知道图片的简略描述信息的情况下,需要查找大量的资料,才能找到所需的图片信息,而通过文字描述图片的内容,直接检索图片可以解决这个问题。而且,金融机构中的数据天然具有保密性,有些数据往往只能在机构内部使用和训练,数据的保密性使得开源的工具和技术无法直接应用于该场景,存在局限性。
因此,有必要研究一种跨模态文本图片检索模型的建模方法来应对现有技术的不足,以解决或减轻上述一个或多个问题。
【发明内容】
有鉴于此,本发明提供了一种跨模态文本图片检索模型的建模方法,采用交互式学习文本和图片的特征表示,能够提升文字图片的检索效果,且本发明建模方法能够提升检索效率和准确度。
一方面,本发明提供一种跨模态文本图片检索模型的建模方法,其特征在于,所述方法的步骤包括:
S1、构建训练数据库;所述训练数据库包括若干搜索文本以及每个文本对应的图片集;
S2、通过特征提取以及处理获得图片集中每张图片的向量表示;
S3、对文本进行特征提取,得到文本的向量表示;
S4、对步骤S2和步骤S3中得到的向量表示进行联合学习,得到联合学习特征向量;
S5、将联合学习特征向量进行二分类,完成建模。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S1中每个所述图片集均包括若干正样本和若干负样本;所述正样本和所述负样本的数量比为1:m,其中,m的取值范围为3-10。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S2的具体步骤包括:
S21、提取每张图片的主体检测框、检测框标签和图片2048维向量;
S22、提取检测框标签的特征进行向量表示,并拼接到图片2048维向量上,得到第一拼接向量;
S23、提取主体检测框的特征得到主体检测框的向量表示,再拼接到第一拼接向量上,得到第二拼接向量;
S24、对第二拼接向量做特征提取和降维,得到最终需要的向量表示。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S2中采用Faster R-CNN对图片进行特征提取。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S3的具体步骤包括:
S31、采用ALBERT模型提取文本的句子级别特征表示;
S32、采用GLOVE词向量和双向LSTM模型提取文本的句子级别特征表示;
S33、将步骤S31和S32中得到的句子级别特征表示进行拼接,得到最终需要的向量表示。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S22中的检测框标签的向量表示为采用GLOVE对检测框标签进行特征提取得到的6维向量表示。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S23中主体检测框的向量表示的获得过程包括:将主体检测框的位置信息进行归一化,再计算主体检测框的面积和长宽比,将主体检测框的位置信息、面积和长宽比合并得到6维的向量表示。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S24中采用双向LSTM对第二拼接向量做特征提取和降维,得到最终需要的1024维的向量表示。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S31和S32中的句子级别特征表示均为448维。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,步骤S4中采用多层相互交叉的transformer层进行联合学习,构建文字元素和图片中区域之间的联系,得到联合学习特征向量。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述方法的步骤还包括:
S6、结合业务知识优化模型。
另一方面,本发明提供一种跨模态文本图片检索建模装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上任一所述方法的步骤。
与现有技术相比,本发明可以获得包括以下技术效果:本发明是一种端到端的文本图片检索建模方法,从文本、图片两方面分别进行特征提取后,交互学习完成语义表征,最后构建二分类器学习文本图片之间的隐含距离函数;采用正负样本进行模型训练,多样化的训练样本提升了模型的学习能力以及后续检索的准确性;本发明基于文本以及图片的检测框标签构建候选图片集,大大减少了检索范围,能够提升建模效率和检索效率;结合业务知识优化模型,能够为模型训练提供更多信息,进一步补全文本表述和图片表示的隐含信息。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有技术效果。
【附图说明】
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
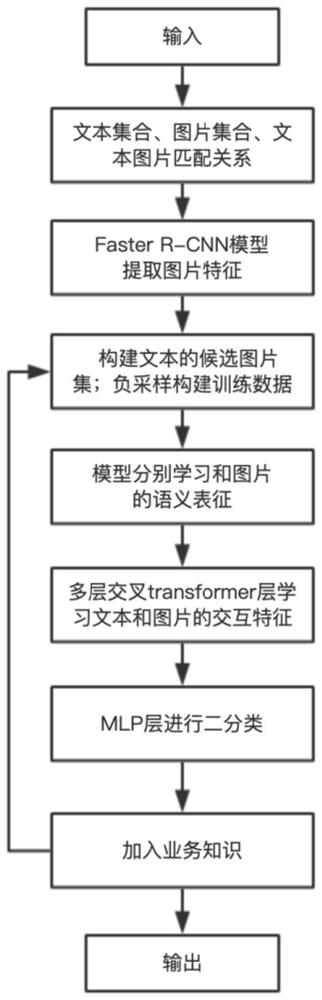
图1是本发明一个实施例提供的跨模态文本图片检索方法的流程图;
图2是本发明一个实施例提供的跨模态文本图片检索方法的模型图。
【具体实施方式】
为了更好的理解本发明的技术方案,下面结合附图对本发明实施例进行详细描述。
应当明确,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
在本发明实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。
针对现有技术的不足,本发明提出一种跨模态的文字图片检索方法,该方法不受数据公开性和类型的局限。该方法是一种端到端的文本图片检索方法,从文本、图片两方面分别进行特征提取后,交互学习完成语义表征,最后构建二分类器学习文本图片之间的隐含距离函数。
本发明可以分为四个部分:图片的标签和特征提取、构建文本的候选图片集合和模型的训练集合、文字检索图片的方法、结合业务知识优化模型。通过以上四个步骤,能够训练一个有效的文本图片匹配模型,通过策略构建训练样本,使得模型更具有鲁棒性,并且能够减少系统检索新文本对应图片的次数。
第一步:图片的标签和特征提取;应用Faster R-CNN算法向量化表示图片数据,Faster R-CNN利用滑动窗口生成锚点,然后通过判定提取出来的锚点属于背景还是前景以及所属的具体类别,来生成图片的主体检测框、检测框的标签和图片的2048维向量表示,来描述图片。
第二步:构建文本的候选图片集合和模型的训练集合;在模型训练时,本发明使用的数据包括文本以及该文本对应的图片集,在模型训练完成后,本发明预先将系统中所有图片,根据第一步的方式生成每张图片的检测框、检测框类别标签、图片向量表示,并存储下来;当需要为文本A找到匹配的图片时,计算系统中已有文本和文本A的重合长度,根据重合长度降序排列文本,选择排名前30%的文本对应的图片作为文本A的候选图片集,这大大减小了检索的范围。同时在模型训练阶段,候选图片集中包含正负样本。其中,正样本是能够与文本内容匹配的图片,负样本是不能够与文本内容匹配的图片。该步骤能够为一个搜索文本构建充足的、复杂的负样本集合,能够提供多样化的训练样本,提升了模型的学习能力。
文字检索图片的方法,使用预训练的ALBERT、GLOVE和BiLSTM模型提取多样化的文本特征,生成文本的向量表征(ALBERT的使用见步骤4.1 1,GLOVE和BiLSTM的使用见步骤4.1 2,三者如何关联见步骤4.1 3)。这里使用的是深度学习模型,文本特征以向量形式表示,本身并不具有可解释性,一般认为其包含了文本的语法、语义等信息。基于Faster R-CNN、GLOVE和BiLSTM模型抽取图片的向量表征(该步向量表征的抽取和本段前面部分说的提取文本特征生成向量表征是不同的步骤,前面是提取文本的向量化表示,后面是提取图片的向量化表示,只有将文本和图片都向量化后才能继续计算)。将不同模态数据映射到不同特征空间后(映射具体指文本和图片的向量化表示过程),通过交互transformer层学习文本和图片的交互特征。通过多层感知机(Multilayer Perceptron,MLP)二分类层,学习文本表示和图片表示的隐含距离函数,为文本返回匹配上的图片(交互特征的学习过程见步骤4.3;通过多层感知机二分类层和学习隐含距离函数的内容和步骤如步骤4.4所述)。
结合业务知识优化模型,业务知识能够为模型训练提供更多信息,补全文本表述和图片表示的隐含信息。
如图1所示,该方法具体内容包括以下步骤:
步骤1:构建训练数据,本发明采用约300G的训练数据,包含大量搜索文本和图片,其中每条数据中包含一个中文搜索文本,以及对应的若干图片及图片的宽高信息。每个文本对应一个图片集合,该图片集合中包含若干符合文本内容的图片,包括正样本和负样本。
步骤2:图片库的特征提取
Faster R-CNN算法广泛应用于目标检测和目标识别领域,将特征抽取、检测框提取、边界框回归、分类整合到一个网络当中。在本发明中,利用Faster R-CNN模型检测图片中的目标,并提取图片中不同主体的检测框的位置,以及每个检测框类别标签和图片的2048维的向量表示。
步骤3:构建文本的候选图片集合和模型的训练集合。在模型的训练中,需要搜索文本和其对应的正负样本,一般来说,在实际应用中比较容易获得正样本:即用户输入搜索文本,点击某一个图片,可标记此图片为正样本。本发明依据搜索文本、图片的检测框类别标签选取负样本。将正样本与负样本的个数比率设定为1:m,m的取值在3-10之间。
步骤3.1:对于某一个搜索文本query来说,根据query与其它搜索文本之间的重合度,即相同的词的个数,对其它文本进行排序,将前30%的文本对应的图片集合,记为N1;
步骤3.2:对于N1中的所有图片,根据query对应的正样本图片的检测框标签随机选择m个图片作为负样本。通过这个方法找出的负样本相当于难样本(Hard sample),HardSample能够增加样本的多样性。
步骤3.3:根据步骤3.1、步骤3.2,生成形式如{搜索文本:正样本,负样本}的训练数据;该数据集为模型训练使用。
步骤3.4:对于新的搜索文本(即模型训练完成后,使用该模型为一条新文本匹配图片),可通过上述步骤构建新文本的候选图片集合,即当需要为文本A找到匹配的图片时,计算系统中已有文本和文本A的重合长度,根据重合长度降序排列文本,选择排名前30%的文本对应的图片作为文本的候选图片集,生成多组{搜索文本,候选图片}数据,大大减少了对图片的匹配次数。
步骤4:训练文字图片的匹配模型。
步骤4.1:学习搜索文本的语义表征,利用多个模型学习搜索文本多样化的向量表示。
1)基于预训练ALBERT模型提取搜索文本的句子级别的特征表示:ALBERT通过几种优化策略获得了比BERT小的多的模型,在保证精度的同时,减少了内存开销。此步骤对过长的搜索文本进行截断,文本的最大长度(比如最大字符数)设为25。将搜索文本输入ALBERT后,取位于倒数第二层的隐含层的输出,做平均池化后得到搜索文本的448维的向量表示,记为Q1。
2)基于GLOVE词向量和双向LSTM模型提取搜索文本的句子级别特征表示:GLOVE基于全局词汇共现的统计信息来学习词向量,搜索文本的GLOVE向量表示,结合了统计信息与局部上下文窗口方法的优点,将GLOVE向量表示输入双向LSTM模型进行特征抽取和降维,得到搜索文本的448维的向量表示,记为Q2。
3)将Q1和Q2横向拼接后得到搜索文本的最终向量表示,得到896维向量。
步骤4.2:学习图片特征
1)基于GLOVE抽取检测框标签的6维向量表示,将所有的向量做平均,得到检测框标签的向量表示,并拼接到图片的2048维特征上,得到2054维向量。该处的图片的2048维特征即为前面所说的图片的标签和特征提取中采用Faster R-CNN算法提取得到的图片2048维特征向量。
2)将检测框的位置信息归一化到[0,1]之间,计算检测框的面积和长宽比,得到6维的向量,再次拼接,得到2060维向量。
3)用双向LSTM对拼接后的向量做特征提取和降维,得到1024维的图片的向量表示。
步骤4.3:多层相互交叉的transformer层学习文本和图片的隐含信息。
文本和图片共同输入多层相互交叉的transformer层,构建文字元素和图片中区域之间的联系,与经典的transformer层的不同之处在于,文本和图片分别使用了自己的query向量和来自另一边的key向量与value向量,attention机制能够在产生文本特征时同时嵌入相应的图片信息,反之也是如此。
步骤4.4将联合学习到的文本和图片的特征进行MLP层二分类。二分类层输出一个[-1,1]之间的分数。
步骤5:结合业务知识优化模型。本发明通过构建关键词字典,更精准的筛选文本候选图片集和负样本集合,进而提高检索效率,举例说明:
在不同的场景下,文本的描述具有局限性,如对于“苹果手机”这个搜索词,表示一个手机品牌,此时我们在构建图片候选集时,设计规则将关键词苹果映射到iPhone,分别比较“苹果手机”和“iPhone手机”和系统中的文本之间的重合度,来筛选候选图片。关键词字典包括:同义词、近义词和中英文转换。
本发明构建一种端到端的文字图片检索方法,对于用户输入的搜索文本,筛选出文本的候选图片集后,训练模型学习文本和待匹配图片的距离函数,最后为用户找到符合文本内容的图片列表,为用户提供更好的查询和搜索体验。该方法较传统的搜索算法,使用了更多的图片内容信息。并且在文字和图片的特征表示上,应用了多种模型的融合特征;同时,交互式学习文本和图片的语义表征,提升了文字图片的检索效果。
如图2所示,左侧是文本的特征提取过程,右侧是图片的特征提取过程。左侧的query表示文本,右侧的image表示图片。
文本的特征提取过程:将query输入模型后,会分别通过ALBERT和GLOVE提取两个向量,ALBERT后续进行平均池化,GLOVE后续通过BILSTM对特征进行压缩;对两个向量做横向拼接(见步骤4.1),query representation是query的最终向量表示。
图片的特征提取过程:将image输入模型后,通过Faster RCNN提取主体检测框(Box position)、检测框类别标签(Box label)、图片的向量表示(Box Feature),三者做横向拼接,然后通过BILSTM进行特征压缩,得到最终的image Representation(见步骤4.2)。
利用transformer层分别学习交互特征。拼接后输入全连接层,激活函数采用sigmoid。
本发明应用Faster R-CNN算法提取图片的标签和特征向量,并且结合多维度的特征来描述图片,为后续步骤提供更准确的图片表示。
构建文本的候选图片集合和模型的训练集合,本发明通过文本和图片的主体检测框标签的相似度来构建候选图片集合和负样本集合。生成搜索文本的候选图片集合,减小了模型需要检索的数据量,同时,充足的负样本集为模型训练提供多样化、具有难度的训练数据。
端到端的文字检索图片的方法,基于多种模型分别学习文本和图片的向量表示,多层相互交叉的transformer层学习文本和图片的隐含信息,能够更好的学习文本和图片间的距离函数。
结合业务知识优化模型,业务知识能够为文本表示提供额外的信息,帮助模型得到更完整准确的检索结果。
以上对本申请实施例所提供的一种基于attention机制的跨模态文本图片检索建模方法,进行了详细介绍。以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
如在说明书及权利要求书当中使用了某些词汇来指称特定组件。本领域技术人员应可理解,硬件制造商可能会用不同名词来称呼同一个组件。本说明书及权利要求书并不以名称的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。如在通篇说明书及权利要求书当中所提及的“包含”、“包括”为一开放式用语,故应解释成“包含/包括但不限定于”。“大致”是指在可接收的误差范围内,本领域技术人员能够在一定误差范围内解决所述技术问题,基本达到所述技术效果。说明书后续描述为实施本申请的较佳实施方式,然所述描述乃以说明本申请的一般原则为目的,并非用以限定本申请的范围。本申请的保护范围当视所附权利要求书所界定者为准。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的商品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种商品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的商品或者系统中还存在另外的相同要素。
应当理解,本文中使用的术语“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
上述说明示出并描述了本申请的若干优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述申请构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求书的保护范围内。
- 一种跨模态文本图片检索模型的建模方法
- 一种视频/图片-文本跨模态检索方法