一种基于加权软件网络的工作量感知缺陷预测方法
文献发布时间:2023-06-19 10:46:31
技术领域
本发明属于软件缺陷预测领域,涉及一种基于加权软件网络的工作量感知缺陷预测方法。
背景技术
软件开发过程中不可避免地存在缺陷,这些缺陷将会导致严重的经济损失。因此,如何能够快速、准确地发现软件缺陷,对于保证软件系统的质量起着至关重要的作用。
软件缺陷预测技术致力于识别高风险的有缺陷模块,缩小开发者审查和测试代码的范围,从而实现有限资源的合理分配。基于度量信息的缺陷预测方法是最常用的方法,其度量元信息主要包括人工设计度量元以及基于抽象语法树的自主学习度量元。
然而,这些基于抽象语法树学习的特征以及人工设计度量元,仍然不能充分展现源代码的语义信息,特别是软件模块间丰富的依赖关系(如数据依赖及调用依赖等),因此,导致这些度量元在实际的软件工程项目中进行软件缺陷预测时,效果不太理想。
专利文献1公开了一种基于图卷积神经网络的软件缺陷预测方法,该软件缺陷预测方法利用GCN算法训练模型对输入的代码文件进行缺陷类型的预测,具体原理如下:
首先通过构建抽象语法树实现源代码中的文件关联,再通过关联算法Apriori将代码中可能具有缺陷传递的文件进行关系,最后将源文件特征及关联关系输入到GCN模型中训练。
然而,本篇专利文献构建的软件网络图主要是根据抽象语法树以及通过管理算法挖掘的特征向量之间的关系,并没有考虑模块间的依赖以及同开发者协作等关联关系。
专利文献2公开了一种基于模块依赖图的软件缺陷预测方法,该方法的原理如下:
根据软件模块间的依赖关系建立软件模块依赖图,将开发者作为模块依赖图中的节点,采用网络表示学习提取软件模块依赖图中的依赖特征,构建基于模块依赖图的缺陷预测模型。
然而,本篇专利文献构建的软件网络图,没有考虑模块间依赖强度对缺陷识别的影响,另外,在利用上述缺陷预测模型进行评估时,没有考虑工作量感知的影响。
综上,现有技术文献为基于依赖关系的缺陷预测提供了良好的研究基础,然而,当前软件网络度量元的缺陷预测能力尚未充分挖掘,主要体现在:
1. 在构建软件网络时,没有考虑模块间关联强度对缺陷识别的影响;
2. 缺乏工作量感知模块,得到的缺陷分类结果仍需大量时间审查代码,缺乏可操作性。
软件缺陷严重影响软件的质量,甚至造成严重的经济损失。软件模块间包含丰富的语义及结构信息,这些丰富的语义及结构关系影响着缺陷的传递。
充分考虑模块间关联强度信息,挖掘软件模块间的结构语义信息对工作量感知缺陷预测的影响,有助于提出更有效的工作量感知缺陷预测模型,实现测试资源的合理分配。
专利文献
专利文献1:中国发明专利申请 公开号:CN110888798A,公开日期:2020.03.17;
专利文献2:中国发明专利申请 公开号:CN111209211A,公开日期:2020.05.29。
发明内容
本发明的目的在于提出一种基于加权软件网络的工作量感知缺陷预测方法,在构建加权软件网络图时分考虑了模块间关联强度对缺陷识别的影响,同时将发现缺陷的审查代码工作量考虑到缺陷预测方法构建中,符合软件开发实际需求,便于快速、准确地发现软件缺陷。
本发明为了实现上述目的,采用如下技术方案:
一种基于加权软件网络的工作量感知缺陷预测方法,包括如下步骤:
I. 数据收集与融合;
收集软件系统数据以及缺陷跟踪系统的缺陷报告;其中,收集的软件系统数据包括版本控制仓库中的源代码、代码提交以及版本信息数据;
在代码提交和缺陷报告之间建立连接,实现代码提交及缺陷报告数据的融合;
II. 缺陷模块标记;
II.1. 提取代码提交及缺陷报告的文本相似度特征、人员一致性特征以及时间戳特征;
基于提取的上述三类特征以及步骤I已建立的代码提交和缺陷报告的连接,发现代码提交与缺陷报告的缺失连接,从而确定修复缺陷的代码提交;
II.2. 基于修复缺陷的代码提交,识别出引入缺陷的代码提交;
II.3. 基于步骤II.1修复缺陷的代码提交和步骤II.2引入缺陷的代码提交,结合版本控制仓库中的版本信息,将各个软件模块进行标记,得到各个软件模块的缺陷标签数据;
III. 构建加权软件网络图;
III.1. 提取并聚合软件系统每个软件模块源代码中的注释,得到每个软件模块的文档信息,同时根据代码提交的提交者信息及修改文件信息,得到每个软件模块的开发者信息;
建立软件模块间的数据依赖及调用依赖关联,利用软件模块间的同一开发者信息建立软件模块间协同开发者关联;
如果任意两个软件模块间存在数据依赖、调用依赖或协同开发者关联的一种,则表明两个软件模块间存在关联,构建如下结构的软件网络图,其中:
每个软件模块作为软件网络图的节点,两个关联的软件模块表示的节点之间建立一条边;
III.2. 根据每个软件模块的文档信息以及开发者信息,计算软件网络图中每条边所连接的两个软件模块之间的关联强度,将关联强度值赋值为软件网络图中该条边的权值;
对同一软件模块依赖的各个软件模块的边的权值进行归一化处理,得到加权软件网络图;
IV. 基于图嵌入技术,得到加权软件网络图的软件网络度量元表示;
IV.1. 将步骤III中的加权软件网络图转换为概率共现矩阵,将概率共现矩阵转换为点式互信息矩阵,对得到的点式互信息矩阵的负值进行调整,得到正点互信息矩阵;
IV.2. 将正点互信息矩阵的每一行当成是一个节点的输入,训练自动编码模型,自主学习加权软件网络图中丰富的模块间结构语义信息,得到加权软件网络图的网络度量元表示;
V. 构建工作量感知缺陷预测方法;
V.1. 基于版本控制仓库中的源代码和代码提交信息,提取每个软件模块的代码度量元及过程度量元,组合步骤IV得到的网络度量元,构成缺陷数据集的特征数据;
将特征数据与步骤II中得到的缺陷标签数据组合,共同构成软件缺陷数据集;
V.2. 将缺陷数据集中每种类型的度量元以及至少两种以上类型度量元的组合,分别组成不同的训练集,并用这些训练集训练分类器,形成基学习器;
V.3. 采用优化算法以优化最少工作量发现最多的缺陷为目标,优化基学习器的组合,形成工作量感知缺陷预测方法,得到每个软件模块发生缺陷的概率,进而给出每个软件模块的缺陷检测顺序。
优选地,步骤I中,在代码提交中搜集缺陷报告的编号关键词,若代码提交中包含该缺陷报告的编号,则在代码提交和缺陷报告中建立连接,实现代码提交及缺陷报告数据的融合。
优选地,步骤II.1中,文本相似度特征的提取过程如下:
基于步骤I收集与融合的代码提交及缺陷报告数据,通过分词和TF-IDF技术处理提取代码提交及缺陷报告的文本信息,得到代码提交及缺陷报告之间的文本相似度特征;
步骤II.1中,人员一致性特征的提取过程如下:
利用步骤I收集的代码提交的提交者及缺陷报告的修复者信息提取人员一致性特征;
步骤II.1中,时间戳特征的提取过程如下:
利用步骤I收集的代码提交的提交时间及缺陷报告的修复时间提取时间戳特征。
优选地,步骤II.3中,将步骤II.1修复缺陷的代码提交和步骤II.2引入缺陷的代码提交之间修改的软件模块标记为有缺陷模块,其他各个软件模块标,则标记为无缺陷模块。
优选地,步骤III.2中,软件模块之间关联强度计算公式如下:
其中,
|
|&
优选地,IV.1中,生成加权软件网络图的概率共现矩阵
首先构建邻接矩阵
若节点
对每个节点引入行向量
其中,a表示重新回到初始节点的概率,
组合每个节点的向量表示
优选地,IV.1中,概率共现矩阵
其中,
#(
对得到的点式互信息矩阵的负值进行调整,得到正点互信息矩阵
其中,
优选地,步骤V.1中,代码度量元及过程度量元的提取过程如下:
基于步骤I收集的版本控制仓库中的源代码,采用Understand工具提取每个软件模块的代码度量元,代码度量元包括代码行数、类的函数个数以及注释行数信息;
基于步骤I收集的版本控制仓库中的代码提交信息,提取每个软件模块的过程度量元,过程度量元包括添加行数、删除行数、修改行数以及开发者数量信息。
优选地,步骤V.2中,分类器采用随机森林分类器;
基于所述随机森林分类器形成计算每个软件模块缺陷概率的公式,如下述公式所示;
其中,
基于每个软件模块得到的缺陷概率
为了确定最优的
其中,
调整
本发明具有如下优点:
如上所述,本发明述及了一种基于加权软件网络的工作量感知缺陷预测方法,该方法根据软件模块间依赖及同开发者两种关联关系设计软件模块间的关联强度计算方法,构建有效的加权软件网络结构,采用图嵌入技术的强大的学习能力,自主学习加权软件网络图中软件模块的特征表示,从而更好地反应软件模块间的数据、调用依赖及协同开发者的依赖关系;同时,将发现缺陷的审查代码工作量考虑到缺陷预测方法构建中,符合软件开发实际需求,便于快速、准确地发现软件缺陷,从而大大缩减了软件开发的时间成本和经费成本。
附图说明
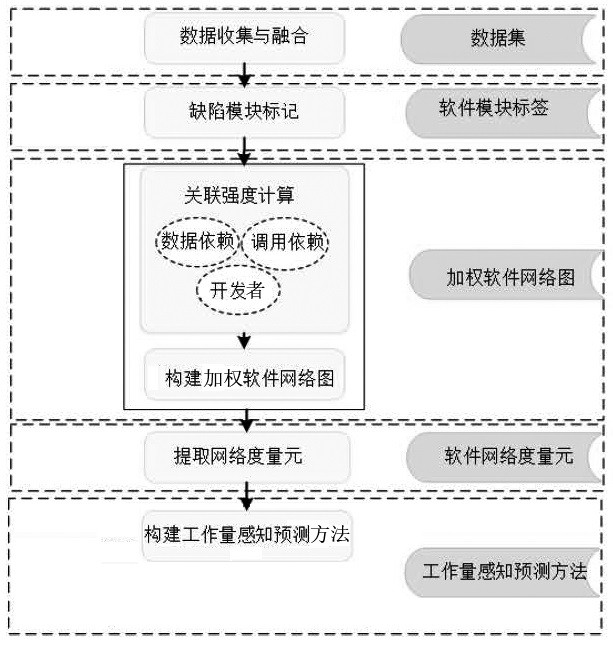
图1为本发明实施例中基于加权软件网络的工作量感知缺陷预测方法的流程框图;
图2为本发明实施例中构建的加权软件网络图的结构示意图。
具体实施方式
本发明的基本思想为:提出一种基于加权软件网络的工作量感知缺陷预测方法,便于根据模块间依赖类型、依赖次数以及开发者对模块的贡献设计出模块间关联强度表示方法,进而提出更加有效地基于加权软件网络的工作量感知缺陷预测方法(模型),得到每个软件模块发生缺陷的概率,进而给出每个软件模块的缺陷检测顺序,从而给出软件开发公司以最少的工作量检测出最多缺陷的测试资源分配方案,提高软件质量,指导软件项目的开发。
下面结合附图以及具体实施方式对本发明作进一步详细说明。
实施例
如图1所示,基于加权软件网络的工作量感知缺陷预测方法,包括如下步骤:
I. 数据收集与融合。
收集软件系统数据以及缺陷跟踪系统(如Bugzilla和JIRA)的缺陷报告。收集的软件系统数据包括版本控制仓库(例如Git和SVN)中的源代码、代码提交以及版本信息数据。
代码提交数据包括标题、描述、讨论、修改文件信息、提交者以及提交时间信息。缺陷报告数据包括编号、标题、描述、讨论、修复者以及修复时间信息。
本实施例中缺陷跟踪系统的缺陷报告,为缺陷跟踪系统中已经修复完毕的缺陷报告。
在代码提交和缺陷报告之间建立连接,实现代码提交及缺陷报告数据的融合。
代码提交和缺陷报告建立连接的过程如下:在代码提交数据(标题、描述以及讨论)中搜集缺陷报告的编号关键词;如果代码提交数据中包含该缺陷报告的编号,则在代码提交和该缺陷报告中建立连接,从而实现代码提交及缺陷报告数据的融合。
II. 缺陷模块标记。
II.1. 提取代码提交及缺陷报告的文本相似度特征、人员一致性特征以及时间戳特征。
具体提取过程如下:
基于步骤I收集与融合的代码提交及缺陷报告数据,处理并提取代码提交及缺陷报告的文本信息(标题、描述以及讨论),得到代码提交及缺陷报告之间的文本相似度特征;
上述文本信息的处理过程,例如通过分词和TF-IDF技术实现。
利用步骤I收集的代码提交的提交者及缺陷报告的修复者信息,对比是否为同一人,从而得到人员一致性特征。利用步骤I收集的代码提交的提交时间及缺陷报告的修复时间,得到俩时间之间的差值从而得到时间戳特征。
结合提取的文本相似度、人员一致性和时间戳特征以及已建立的代码提交和缺陷报告的连接,发现代码提交与缺陷报告的缺失连接,从而确定修复缺陷的代码提交。
本实施例优选采用PU(Positive and Unlabeled ) Learning学习算法发现代码提交与缺陷报告之间的缺失连接。PU Learning学习算法为已知算法,此处不再赘述。
II.2. 基于修复缺陷的代码提交,利用改进的
II.3. 基于步骤II.1修复缺陷的代码提交和步骤II.2引入缺陷的代码提交,结合版本控制仓库中的版本信息,将各个软件模块进行标记,得到各个软件模块的缺陷标签数据。
具体标记过程如下:
将步骤II.1修复缺陷的代码提交和步骤II.2引入缺陷的代码提交之间修改的软件模块标记为有缺陷模块,同一版本下的其他各个软件模块标,则标记为无缺陷模块。
通过以上标记过程,得到相应版本下软件模块的缺陷标签。
III. 构建加权软件网络图。
III.1. 提取并聚合软件系统每个软件模块源代码中的注释,得到每个软件模块的文档信息,同时根据代码提交的提交者及修改文件信息,得到每个软件模块的开发者信息。
利用Understand工具建立软件模块间的数据依赖及调用依赖关联,利用软件模块间的同一开发者信息建立软件模块间协同开发者关联。
其中,利用Understand工具建立软件模块间的数据依赖及调用依赖关联的过程已知。
如果任意两个软件模块间存在数据依赖、调用依赖或协同开发者关联的一种,则表明两个软件模块间存在关联,则构建如下结构的软件网络图;其中:
每个软件模块作为软件网络图的节点,两个关联的软件模块表示的节点之间建立一条边。
基于以上原则,构建了基于数据依赖、调用依赖以及协同开发者关联的软件网络图。
III.2. 根据每个软件模块的文档信息以及开发者信息,提出基于引文影响的软件模块之间的关联强度的计算方式,其中,关联强度计算公式如下:
其中,
|
|&
将经过上述计算求得关联强度值,赋值为软件网络图中该条边的权值。同时,对同一软件模块依赖的各个软件模块的边的权值进行归一化处理,得到加权软件网络图。
以图2为例,软件模块B依赖于软件模块A、D、E,则对边BA、BD、BE的权值进行归一化处理,使得他们的和等于1,得到的加权软件网络图如图2所示。
由于本实施例述及的关联强度计算公式,正确地表示了软件模块间的关联强度,因此,使得构建的加权软件网络图,更能够符合实际软件模块间的关系。
IV. 基于图嵌入技术,得到加权软件网络图的软件网络度量元表示。
IV.1. 采用随机冲浪模型将步骤III中的加权软件网络图转换为概率共现矩阵,进而基于加权软件网络图的全部节点,将概率共现矩阵转化为正点互信息矩阵。
概率共现矩阵的具体生成过程如下:
首先构建邻接矩阵
若节点
对每个节点引入行向量
其中,a表示重新回到初始节点的概率;
根据得到的行向量
将上述步骤得到的概率共现矩阵
其中,
#(
对得到的点式互信息矩阵的负值进行调整,得到正点互信息矩阵
其中,
通过正点互信息矩阵能够保证后续自动编码模型可以捕获更高阶的近似度。
IV.2. 将正点互信息矩阵的每一行当成是一个节点的输入,输入自动编码器,进行自动编码模型训练,自动编码器由编码器和解码器两部分组成。
自动编码器的损失函数
通过自主学习加权软件网络图中丰富的模块间结构语义信息,从而获取更好地反应软件模块之间的数据依赖、调用依赖及协同开发者的依赖关系的网络度量元。
由于本实施例中基于图嵌入技术的网络度量元,正确地表示了加权软件网络图中软件模块的依赖关系,因此,能够很好地利用模块之间的关联关系来发现缺陷。
V. 构建工作量感知缺陷预测方法。
V.1. 基于版本控制仓库中的源代码和代码提交信息,提取每个软件模块的代码度量元及过程度量元,具体过程如下:
基于步骤I收集的版本控制仓库中的源代码,采用Understand工具提取每个软件模块的代码度量元,包括代码行数、类的函数个数以及注释行数等信息;
基于步骤I收集的版本控制仓库中的代码提交信息(提交者、修改文件信息、diff等信息),提取每个软件模块的过程度量元,包括添加行数、删除行数、修改行数和开发者数量等信息。
组合代码度量元、过程度量元以及步骤IV中的网络度量元,构成缺陷数据集的特征数据;将特征数据与步骤II中得到的缺陷标签数据组合,共同构成软件缺陷数据集。
V.2. 考虑到每种类型的度量元对缺陷的预测效果不一样,本实施例将缺陷数据集中每种类型的度量元以及至少两种以上类型度量元的组合(包括任意两种类型的组合以及三种类型的组合),分别组成不同的训练集,并用这些训练集训练分类器,形成基学习器。
本实施例中分类器优选采用随机森林分类器,当然还可以是贝叶斯、逻辑回归等分类器。以随机森林分类器为例,计算每个软件模块缺陷概率的公式为:
其中,
基学习器
其中,
V.3. 采用优化算法以优化最少工作量发现最多的缺陷为目标,优化基学习器的组合,形成工作量感知缺陷预测方法,得到每个软件模块发生缺陷的概率,进而给出每个软件模块的缺陷检测顺序。基于每个软件模块的缺陷检测顺序,能够给出软件开发公司以最少的工作量检测出最多缺陷的测试资源分配方案,提高软件质量,指导软件项目的开发。
基于每个软件模块得到的缺陷概率
此处需要说明,若软件模块的缺陷概率相等,则代码行数小的软件模块排在前面。
为了确定最优的
其中,
调整
本发明实施例中上述各个步骤是协同作用的,其协同过程体现在:
首先步骤I中的数据收集与融合,为本发明提供了数据保证;紧接着,基于步骤II提出的缺陷模块标记方法,为构建基于加权软件网络的工作量感知缺陷预测方法提供高质量标签数据,步骤III中通过构建加权软件网络图以及步骤IV中基于图嵌入软件网络度量元表示,为构建基于加权软件网络的工作量感知缺陷预测方法提供高质量的网络度量元表示,最后通过步骤V构建了工作量感知缺陷预测方法对缺陷预测,应用于实践提供有力保障。
当然,以上说明仅仅为本发明的较佳实施例,本发明并不限于列举上述实施例,应当说明的是,任何熟悉本领域的技术人员在本说明书的教导下,所做出的所有等同替代、明显变形形式,均落在本说明书的实质范围之内,理应受到本发明的保护。
- 一种基于加权软件网络的工作量感知缺陷预测方法
- 一种基于复杂加权软件网络的软件缺陷预测方法