应用服务指标监控方法、装置、计算机设备和存储介质
文献发布时间:2023-06-19 10:51:07
技术领域
本申请涉及计算机技术领域,特别是涉及一种应用服务指标监控方法、装置、计算机设备和存储介质。
背景技术
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。全链路监控组件就在这样的问题背景下产生了。
调用链是全链路监控组件的核心,对应用服务进行监控可以通过从调用链数据中聚合计算出包括QPS、响应事件、失败数、异常数等指标来实现应用服务的监控。尽管使用调用链数据具有其优点,比如信息全面,通过落盘调用信息,可以获取到详细的应用服务的使用情况等。但是也存在诸多缺点,例如:由于业务访问量大,不可能每次调用信息都落盘,需要设置落盘的采样率,因此从调用链信息计算业务指标不是完全准确的;由于使用调用链数据计算指标的计算量非常大,导致占用过多的服务器资源计算资源;在流量高峰时如果计算不及时容易造成指标数据延迟。
发明内容
基于此,有必要针对上述技术问题,提供一种应用服务指标监控方法、装置、计算机设备和存储介质,能够实现更加实时、准确、高效对应用服务进行性能监控。
第一方面,提供了一种应用服务指标监控方法,所述方法包括:
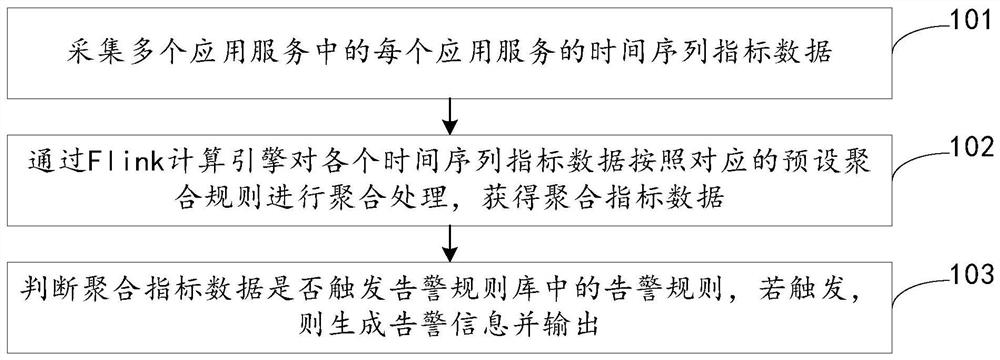
采集多个应用服务中的每个应用服务的时间序列指标数据;
通过Flink计算引擎对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
判断所述聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
进一步地,所述通过Flink计算引擎对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据,包括:
对各所述时间序列指标数据中的各个指标数据进行清洗过滤,获得多个有效指标数据;
在聚合规则库中读取与多个所述有效指标数据匹配的预设聚合规则,按照所述预设聚合规则中的聚合维度,构建各所述有效指标数据对应的聚合模型以及所述聚合模型中的用于聚合计算的聚合键;
对各所述聚合模型对应的有效指标数据按照聚合键进行数据分区,并对数据分区后的具有相同聚合键的所述有效指标数据进行聚合计算,得到聚合指标数据。
进一步地,所述对各所述时间序列指标数据中的各个指标数据进行清洗过滤,获得多个有效指标数据,包括:
对各所述时间序列指标数据中的各个指标数据转换为标准指标数据;
根据预设的白名单和黑名单,对各所述标准指标数据进行过滤,获得多个有效指标数据。
优选地,所述根据预设的白名单和黑名单,对各所述标准指标数据进行过滤,获得多个有效指标数据,包括:
获取各所述标准指标数据的哈希值;
对各所述标准指标数据的哈希值在所述白名单对应的哈希表进行匹配,对匹配成功的所述标准指标数据的哈希值在所述黑名单对应的哈希表中进行过滤,得到多个有效指标数据。
进一步地,所述对数据分区后的具有相同聚合键的所述有效指标数据进行聚合计算,得到聚合指标数据,包括:
在预设时间窗口内对具有相同聚合键的所述有效指标数据进行去重,对去重后的所述有效指标数据进行聚合计算,得到聚合指标数据。
进一步地,所述聚合计算包括求和操作、求平均操作、求最小操作和/或求最大操作。
进一步地,所述方法还包括:
根据各所述指标数据的属性信息,对各所述指标数据创建对应类型的计算任务,所述属性信息包括是否为秒级指标、和/或是否为预设重要级别指标、和/或是否为查询热度指标,不同类型的计算任务由不同的Flink集群执行;
所述通过Flink计算引擎对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据,包括:
根据所述计算任务的类型,将所述计算任务调度至对应的Flink集群上,以执行对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据。
进一步地,所述判断所述聚合指标数据是否触发告警规则库中的告警规则,包括:
判断所述聚合指标数据是否满足所述告警规则中的阈值条件;和/或
判断所述聚合指标数据与所述聚合指标数据的历史聚合指标数据的比较结果是否满足所述告警规则中的比较阈值条件;和/或
判断所述聚合指标数据与其存在正比关系的聚合指标数据之间的比值是否满足所述告警规则中的比值阈值条件。
进一步地,所述方法还包括:
判断所述聚合指标数据与其存在关联关系的聚合指标数据是否同时触发各自对应的告警规则,若是,则生成告警信息并输出。
第二方面,提供了一种应用服务指标监控装置,所述装置包括:
指标采集模块,用于采集多个应用服务中的每个应用服务的时间序列指标数据;
指标聚合模块,用于通过Flink计算引擎对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
监控告警模块,用于判断所述聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
进一步地,所述指标聚合模块包括:
清洗过滤单元,用于对各所述时间序列指标数据中的各个指标数据进行清洗过滤,获得多个有效指标数据;
构建单元,用于在聚合规则库中读取与多个所述有效指标数据匹配的预设聚合规则,按照所述预设聚合规则中的聚合维度,构建各所述有效指标数据对应的聚合模型以及所述聚合模型中的用于聚合计算的聚合键;
分区单元,用于对各所述聚合模型对应的有效指标数据按照聚合键进行数据分区;
聚合单元,用于对数据分区后的具有相同聚合键的所述有效指标数据进行聚合计算,得到聚合指标数据。
进一步地,所述清洗过滤单元具体用于:
对各所述时间序列指标数据中的各个指标数据转换为标准指标数据;
根据预设的白名单和黑名单,对各所述标准指标数据进行过滤,获得多个有效指标数据。
优选地,所述清洗过滤单元具体用于:
获取各所述标准指标数据的哈希值;
对各所述标准指标数据的哈希值在所述白名单对应的哈希表进行匹配,对匹配成功的所述标准指标数据的哈希值在所述黑名单对应的哈希表中进行过滤,得到多个有效指标数据。
进一步地,所述聚合单元具体用于:
在预设时间窗口内对具有相同聚合键的所述有效指标数据进行去重,对去重后的所述有效指标数据进行聚合计算,得到聚合指标数据。
进一步地,所述装置还包括任务创建模块,所述任务创建模块用于:
根据各所述指标数据的属性信息,对各所述指标数据创建对应类型的计算任务,所述属性信息包括是否为秒级指标、和/或是否为预设重要级别指标、和/或是否为查询热度指标,不同类型的计算任务由不同的Flink集群执行;
所述指标聚合模块具体用于:
根据所述计算任务的类型,将所述计算任务调度至对应的Flink集群上,通过所述Flink集群对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据。
进一步地,所述监控告警模块具体用于:
判断所述聚合指标数据是否满足所述告警规则中的阈值条件;和/或
判断所述聚合指标数据与所述聚合指标数据的历史聚合指标数据的比较结果是否满足所述告警规则中的比较阈值条件;和/或
判断所述聚合指标数据与其存在正比关系的聚合指标数据之间的比值是否满足所述告警规则中的比值阈值条件。
进一步地,所述监控告警模块具体还用于:
判断所述聚合指标数据与其存在关联关系的聚合指标数据是否同时触发各自对应的告警规则,若是,则生成告警信息并输出。
第三方面,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
采集多个应用服务中的每个应用服务的时间序列指标数据;
通过Flink计算引擎对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
判断所述聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
采集多个应用服务中的每个应用服务的时间序列指标数据;
通过Flink计算引擎对各个所述时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
判断所述聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
本发明提供一种应用服务指标监控方法、装置、计算机设备和存储介质,通过采集多个应用服务中的每个应用服务的时间序列指标数据;通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;以及判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出,由于采集到的时间序列指标数据是在应用服务侧生成的,并且通过Flink计算引擎采用实时流式计算的方式消费各个应用服务的指标数据,计算出聚合指标,并通过告警规则自动对聚合指标进行告警判定,由此替代了使用调用链数据计算指标的全链路监控框架,能够大大缩容使用调用链数据计算聚合指标的旧框架的服务器资源,使得计算资源占用更少,释放更多的服务器资源;同时也实现了更加实时、准确、高效对应用服务进行性能监控。
附图说明
图1为本发明实施例提供的一种应用服务指标监控方法的流程图;
图2为图1所示方法中步骤102的具体流程图;
图3为本发明实施例提供的一种应用服务指标监控装置的结构图;
图4为本发明实施例提供的一种计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
需要说明的是,除非上下文明确要求,否则整个说明书和权利要求书中的“包括”、“包含”等类似词语应当解释为包含的含义而不是排他或穷举的含义;也就是说,是“包括但不限于”的含义。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
如前述背景所述,现有技术对应用服务进行监控可以通过从调用链数据中聚合计算出包括QPS、响应事件、失败数、异常数等指标来实现应用服务的监控。而使用调用链数据存在诸多缺点,例如:由于业务访问量大,不可能每次调用信息都落盘,需要设置落盘的采样率,因此从调用链信息计算业务指标不是完全准确的;由于使用调用链数据计算指标的计算量非常大,导致占用过多的服务器资源计算资源;在流量高峰时如果计算不及时容易造成指标数据延迟。为此本发明实施例提供一种应用服务指标监控方法,该方法替代了使用调用链数据计算指标的全链路监控框架,实现更加实时、准确、高效对应用服务进行性能监控。
在一个实施例中,如图1所示,提供了一种应用服务指标监控方法,该方法可以由本发明实施例提供的应用服务指标监控装置或服务器来执行,该装置可以采用硬件和/或软件的方式实现,该服务器可以采用独立的服务器或服务器集群来实现。该方法可以包括以下步骤:
101,采集多个应用服务中的每个应用服务的时间序列指标数据。
其中,时间序列指标数据为流式数据。时间序列指标数据可以包括应用服务自身指标,以及其RPC/DB/Redis调用的QPS、响应时间、错误率等,还可以包括诸如JVM指标、Docker指标、中间件和基础设施指标以及用户的业务自定义指标等。时间序列指标数据的级别可以分为秒级和分钟级。
具体地,可以通过运行在每个应用服务的各个实例上的SmartAgent采集各个实例的时间序列指标数据,并上报到kafka中。其中SmartAgent可以基于Flume二次封装,具有动态发现容器以及获取Docker指标的能力,并可以在每台物理机和宿主机上运行,对采集到的文件或日志进行加工适配处理以形成时间序列指标数据。
102,通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据。
其中,Flink计算引擎用于将从kafka中接收到的单机指标数据按照预先配置的聚合规则进行聚合出应用和部署池级别的聚合指标。聚合规则可以根据实际需要进行灵活定义,聚合规则用于对指标数据按预设维度进行聚合计算,聚合计算例如sum、avg、max、min这四类数值统计操作。
具体地,Flink计算引擎可以结合MapReduce计算框架对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理。
其中,MapReduce计算框架包括Mapper阶段和Reduce阶段。Mapper阶段包括:Parse、Filtering以及FlatMap,分别用于入口数据处理、数据清洗以及读取聚合规则构造聚合模型以产生聚合键。Reduce阶段包括KeyBy操作完成数据分区、聚合计算操作以及聚合结果输出,聚合结果可以输出至下游,下游可以是任意能够持久化落地或者能够有能力接受数据的任何服务,例如redis、HDFS、kafka、Flume等。
103,判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
其中,告警规则库中的告警规则可以预先通过提供给前端界面的规则配置界面进行新建修改和删除,前端通过调用增删改接口,将告警规则存储到规则配置表,当点击规则的发布按钮后,规则被更新到规则发布表。
具体地,通过告警引擎判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息,并通过邮件、短信或其他方式发送给相应的接收人进行处理。
本发明提供一种应用服务指标监控方法,通过采集多个应用服务中的每个应用服务的时间序列指标数据;通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;以及判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出,由于采集到的时间序列指标数据是在应用服务侧生成的,并且通过Flink计算引擎采用实时流式计算的方式消费各个应用服务的指标数据,计算出聚合指标,并通过告警规则自动对聚合指标进行告警判定,由此替代了使用调用链数据计算指标的全链路监控框架,能够大大缩容使用调用链数据计算聚合指标的旧框架的服务器资源,使得计算资源占用更少,释放更多的服务器资源;同时也实现了更加实时、准确、高效对应用服务进行性能监控。
在一个实施例中,如图2所示,上述步骤102中通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据,该过程可以包括:
201,对各时间序列指标数据中的各个指标数据进行清洗过滤,获得多个有效指标数据。
具体地,对各时间序列指标数据中的各个指标数据转换为标准指标数据,根据预设的白名单和黑名单,对各标准指标数据进行过滤,获得多个有效指标数据。
其中,Parse阶段可以对从Kafka接收到的json类型的各个指标数据转换为标准指标数据,标准指标数据的数据类型可以是根据实际需要进行设定,此处不作具体限定。Filtering阶段可以基于预先配置的白名单和黑名单,对各标准指标数据进行过滤处理。
示例性地,白名单可以预先配置为:只接受指定namespace下的数据、只接受指定metric name的数据、以及只接受某些app name的数据;黑名单可以预先配置为:Bynamespace屏蔽、By metric name屏蔽、以及By app name屏蔽,其中,在黑白名单中,namespace是必填的字段。
其中,白名单配置示例如下:
#namespace|metricName|appName,namespace是必填项
whitelist=app|*|osp-cart,app|*|osp-checkout
其中,黑名单配置示例如下:
#namespace|metricName|appName,namespace是必填项
blacklist=platform|*|*,app|qps_redis|*
其中,上述根据预设的白名单和黑名单,对各标准指标数据进行过滤,获得多个有效指标数据,该过程可以包括:
获取各标准指标数据的哈希值,对各标准指标数据的哈希值在白名单对应的哈希表进行匹配,对匹配成功的标准指标数据的哈希值在黑名单对应的哈希表中进行过滤,得到多个有效指标数据。
具体地,对每个标准指标数据,按预设顺序查询哈希表,如果查询有结果,则直接返回,不再做后续查询,否则继续查询。
本实施例中,对各时间序列指标数据中的各个指标数据进行清洗过滤过程中,优先应用白名单,只有通过白名单的指标数据,才会进入黑名单过滤。而黑名单的目的是为了过滤一些通过了白名单宽入口的指标数据,但又需要特殊屏蔽的指标。例如白名单里配置whitelist=app|*|*,意味着namespace是app的指标将全部通过,如果需要单独屏蔽mapi-cart域的指标,那么可以通过设置blacklist=app|*|mapi-cart来完成屏蔽,如此过滤方式能够有效提高指标数据的过滤效率。
202,在聚合规则库中读取与多个有效指标数据匹配的预设聚合规则,按照预设聚合规则中的聚合维度,构建各有效指标数据对应的聚合模型以及聚合模型中的用于聚合计算的聚合键。
其中,FlatMap阶段可以具有各有效指标数据的指标标签(tag)对各有效指标数据匹配出对应的预设聚合规则,通过匹配出的预设聚合规则将一个输入指标对象输出成一个或若干个指标对象,以便后续的聚合运算。
具体来说,FlatMap实质是一个创建Aggregation Model的过程,该过程主要完成读取Agg聚合规则,将入口的metrics数据,转换成MetricsAggregation数据模型,为下一阶段的keyBy操作做准备。
其中,聚合规则表可以预先配置,聚合规则维护一个哈希->List的数据结构,可以按照预设顺序执行哈希表查询,一旦匹配成功,则无需执行后续匹配,预设顺序示例如下:
${namespace}|*|*
${namespace}|${metricsName}|*
${namespace}|${metricsName}|${appName}
示例性地,针对如下一条metrics数据:
namespace="app"metric="qps"value="100"tags="app=osp-cart,
pool=gd9-osp-cart-pool-1,host=gd9-osp-cart-001"
timestamp="1521790613044
针对上述指标数据,一种方式可以根据app域名进行聚合,并将新的聚合指标的名称定义为qps_$app;另一种方式可以根据app域名+pool部署池名称进行聚合,并将新的聚合指标的名称定为qps_$app_$pool,这样通过FlatMap的处理,对这一条metric model变成二个聚合模型,它们分别是:
按域名聚合得到的agg model:
namespace="app"aggKey="qps_osp-cart"
aggMetricName="qps_osp-cart:1m"value="100"
timestamp="1521790613044
按域名+pool部署池聚合得到的agg model:
namespace="app"aggKey="qps_osp-cart_gd9-osp-cart-pool-1"
aggMetricName="qps_osp-cart_gd9-osp-cart-pool-1:1m"value="100"
timestamp="1521790613044"
以上列出了agg model最核心的几个字段,包括:
1.namespace:聚合后新的namespace;
2.aggKey:聚合计算的Key,非常关键的一个字段,后续Reduce阶段的KeyBy数据分区将按照这个key来操作;
3.aggMetricName:聚合指标产生后新的metric名。
在实际应用中,聚合规则需要足够灵活,除了上面支持by app,以及by app+pool的聚合外,还能支持任意指标的聚合需求。例如针对购物车增加数的业务指标,可以在聚合规则中进行by地域、By渠道、By移动设备等不同维度的聚合设定。
其中,构建聚合模型中的用于聚合计算的聚合键,可以包括:
通过聚合模型根据预设聚合规则的规则ID和聚合键的键值对按照聚合键的字母排序进行拼接出聚合键。
203,对各聚合模型对应的有效指标数据按照聚合键进行数据分区,并对数据分区后的具有相同聚合键的有效指标数据进行聚合计算,得到聚合指标数据。
其中,相同聚合键的指标将被分为一组进行聚合计算,聚合计算包括sum、avg、max、min这四类数值统计操作。
sum:累加多个实例的指标,例如app级别qps,app级别5xx;
avg:求平均值,例如app级别平均响应时间、app级别heap平均使用率等;
max:统计一个计算窗口内,多个实例中的最大的这个实例的值;
min:统计一个计算窗口内,多个实例中的最小的这个实例的值。
具体地,上述步骤中对数据分区后的具有相同聚合键的有效指标数据进行聚合计算,得到聚合指标数据,该过程可以包括:
在预设时间窗口内对具有相同聚合键的有效指标数据进行去重,对去重后的有效指标数据进行聚合计算,得到聚合指标数据。
本实施例中,由于应用服务通常包含多个实例,部署在多个机器上,每个实例生成独立的指标,例如svr_count、svr_latency、svr_count_5xx等,而各种指标生成和上报的时间是不确定的,因此可能会由于延迟到达的指标,导致在将多个实例的指标进行聚合过程中指标存在重复,因此需要对重复的指标进行过滤或去重。而Flink计算引擎针对所有指标都在同一个窗口内计算,窗口计算时间是相同的,如果窗口过小,则延迟的指标比如无法再次计算告警,如果启用延迟重新计算,则大量重复告警不可避免。因此针对秒级指标,可以在指标聚合引擎内首先进行第一次聚合,聚合等待时间设置为10秒,秒级绝大部分指标的延迟将不会超过10秒,超过10秒的则延迟计算。指标聚合完成后,写入到指定的Kafka,告警引擎消费秒级指标,由于存在指标重复,并且多规则组合告警时需要对多条指标序列同步消费。因此增加一个预设时间窗口(例如5秒),将相同指标在该预设时间窗口内进行去重,对去重后的指标数据在同一计算窗口内进行聚合计算,得到聚合指标数据可进行告警。
对于秒级聚合的指标,计算窗口时间可以定义为1s(redis端还会做一次兜底聚合);对于分钟级的聚合指标,考虑到每个实例上报数据的时间的离散化,可以将计算窗口时间定义为1分钟。例如有3个实例,上报的时间分别为18:00:01、18:00:32、18:00:59,它们都属于18:00~18:01这个窗口的聚合数据。
在一个实施例中,方法还可以包括:
根据各指标数据的属性信息,对各指标数据创建对应类型的计算任务,属性信息包括是否为秒级指标、和/或是否为预设重要级别指标、和/或是否为查询热度指标,不同类型的计算任务由不同的Flink集群执行;
通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据,包括:
根据计算任务的类型,将计算任务调度至对应的Flink集群上,通过Flink集群对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据。
在具体应用中,可以对各指标数据按照是否为秒级指标、是否为预设重要级别指标、是否查询热度高等维度,创建不同类型的计算任务,例如秒级指标计算任务和分钟级指标计算任务。其中,上述预设重要级别指标包括指示核心域秒级指标、核心秒级业务指标。根据指标的出现总次数以及查询总次数之间的比值是否大于阈值,可以确定该指标是否为查询热度指标。核心域的秒级指标计算任务聚合计算结果写入Redis,并且只保留3d~7d热数据,所有域的秒级/分钟级指标聚合计算后写入OpenTSDB,并且永久保留。
另外,为了确保不同计算任务的稳定性,物理上需要将它们部署在不同独立的Flink集群上运行,互不干扰。这样相互之间不会形成资源竞争,同时一个计算任务如果crush,则不会导致另外一个任务crush(JVM隔离),另外不同计算任务互为备份,如果秒级监控出问题,分钟级监控依然可以工作,不会导致对整个生产系统产生监控盲区。
在一个实施例中,上述步骤104判断聚合指标数据是否触发告警规则库中的告警规则,包括:
判断聚合指标数据是否满足告警规则中的阈值条件;和/或
判断聚合指标数据与聚合指标数据的历史聚合指标数据的比较结果是否满足告警规则中的比较阈值条件;和/或
判断聚合指标数据与其存在正比关系的聚合指标数据之间的比值是否满足告警规则中的比值阈值条件。
本实施例中,通常告警规则对每个指标序列设置阀值,如svr_count_5xx大于100,触发告警。一般应用服务中,5xx可能没有,或者量非常少,但是某些域,5xx可能是常态,值得波动范围也较大。特别是定时任务,在任务运行时,异常较多,一旦任务运行结束,异常没有或者非常少,这时候告警必须能够和历史进行比较,比如和昨天指标进行差值比较,或昨天指标进行商值比较。当比较结果满足告警规则中的比较阈值条件时,则确定聚合指标数据触发告警规则库中的告警规则。
此外,告警针对指标的数量值设置阀值判定,在某些场景下不能始用,比如随着请求总数的升高,5xx异常数量可能也跟着一起增长,这种情况大多认为是正常的。仅仅通过阀值,误告必然增多,长时间的话,报警将被用户直接忽视。而请求总数与5xx异常数量这两个指标是存在正比变化关系的,比较稳定的是异常比率,随着总请求数的升高,异常数增长,但两者比率不变,因此当聚合指标数据与其存在正比关系的聚合指标数据之间的比值满足告警规则中的比值阈值条件时,可以确定聚合指标数据触发告警规则库中的告警规则。
在一个实施例中,方法还可以包括:
判断聚合指标数据与其存在关联关系的聚合指标数据是否同时触发各自对应的告警规则,若是,则生成告警信息并输出。
本实施例中,可以针对有关联的指标,如异常比率和响应时间,当两者同时触发设定的规则时,才触发告警,从而能够有效地减少误告。
应该理解的是,虽然流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,附图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
在一个实施例中,如图3所示,提供了一种应用服务指标监控装置,装置300包括:
指标采集模块301,用于采集多个应用服务中的每个应用服务的时间序列指标数据;
指标聚合模块302,用于通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
监控告警模块303,用于判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
在一个实施例中,指标聚合模块包括:
清洗过滤单元,用于对各时间序列指标数据中的各个指标数据进行清洗过滤,获得多个有效指标数据;
构建单元,用于在聚合规则库中读取与多个有效指标数据匹配的预设聚合规则,按照预设聚合规则中的聚合维度,构建各有效指标数据对应的聚合模型以及聚合模型中的用于聚合计算的聚合键;
分区单元,用于对各聚合模型对应的有效指标数据按照聚合键进行数据分区;
聚合单元,用于对数据分区后的具有相同聚合键的有效指标数据进行聚合计算,得到聚合指标数据。
在一个实施例中,清洗过滤单元具体用于:
对各时间序列指标数据中的各个指标数据转换为标准指标数据;
根据预设的白名单和黑名单,对各标准指标数据进行过滤,获得多个有效指标数据。
在一个实施例中,清洗过滤单元具体用于:
获取各标准指标数据的哈希值;
对各标准指标数据的哈希值在白名单对应的哈希表进行匹配,对匹配成功的标准指标数据的哈希值在黑名单对应的哈希表中进行过滤,得到多个有效指标数据。
在一个实施例中,聚合单元具体用于:
在预设时间窗口内对具有相同聚合键的有效指标数据进行去重,对去重后的有效指标数据进行聚合计算,得到聚合指标数据。
在一个实施例中,装置还包括任务创建模块,任务创建模块用于:
根据各指标数据的属性信息,对各指标数据创建对应类型的计算任务,属性信息包括是否为秒级指标、和/或是否为预设重要级别指标、和/或是否为查询热度指标,不同类型的计算任务由不同的Flink集群执行;
指标聚合模块具体用于:
根据计算任务的类型,将计算任务调度至对应的Flink集群上,通过Flink集群对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据。
在一个实施例中,监控告警模块具体用于:
判断聚合指标数据是否满足告警规则中的阈值条件;和/或
判断聚合指标数据与聚合指标数据的历史聚合指标数据的比较结果是否满足告警规则中的比较阈值条件;和/或
判断聚合指标数据与其存在正比关系的聚合指标数据之间的比值是否满足告警规则中的比值阈值条件。
在一个实施例中,监控告警模块具体还用于:
判断聚合指标数据与其存在关联关系的聚合指标数据是否同时触发各自对应的告警规则,若是,则生成告警信息并输出。
关于应用服务指标监控装置的具体限定可以参见上文中对于应用服务指标监控方法的限定,在此不再赘述。上述应用服务指标监控装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图4所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种应用服务指标监控方法。
本领域技术人员可以理解,图4中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现以下步骤:
采集多个应用服务中的每个应用服务的时间序列指标数据;
通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
采集多个应用服务中的每个应用服务的时间序列指标数据;
通过Flink计算引擎对各个时间序列指标数据按照对应的预设聚合规则进行聚合处理,获得聚合指标数据;
判断聚合指标数据是否触发告警规则库中的告警规则,若触发,则生成告警信息并输出。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 应用服务指标监控方法、装置、计算机设备和存储介质
- 信息变更指标监控方法、装置、计算机设备和存储介质