一种高保真靶标基因建库方法及其试剂盒
文献发布时间:2023-06-19 11:22:42
技术领域
本发明涉及基因测序技术领域,具体涉及一种高保真靶标基因建库方法及其试剂盒。
背景技术
NGS靶向文库的制备流程(包括新型建库方法单链建库)一般分为两套流程,主流的捕获建库方法需要经历文库构建、捕获前扩增、杂交捕获、捕获后扩增四个必需步骤,全流程一般长达2到3天。另一种常见方法称为扩增子建库,一般先做多重PCR,后对PCR产物建库,有的商业化试剂盒会在做多重PCR时,在引物的5′端外侧加上对应NGS平台的接头序列,以将上述两步整合为一步。
第一种主流技术路线必须将文库构建和杂交捕获严格分开,步骤繁多周期长,且依赖基于链霉亲和素与生物素连接的磁珠捕获,磁珠价格昂贵且依赖进口。第二种技术路线虽然流程较前者更简洁,但因其基于多重PCR,有如下诸多问题:1、建库起始投入量需求较高;2、同一反应体系里plex数无法过多,导致较大panel的基因检测很难通过单管反应完成,只能分成多个单管反应,然后合并产物来实现,大大升高了成本,延长了操作时间,限制了单管反应检测通量,不利于推广;3、PCR需要两端引物配对,导致无法检测融合基因(novel fusion)和病毒插入位点等结构性变异;4、PCR的指数性扩增导致其无法检测基因拷贝数变异;5、多重PCR不可避免的扩增偏好性导致均一度低,导致panel中部分区域不能很好覆盖,而部分区域过多覆盖。
单链建库方法能实现对严重降解的样本的建库,但其所需单链接头连接或发卡时接头连接的物料成本高昂,且连接效率低于常规的双链接头连接,此外,单链建库只是一种建库方法,建库之后仍需做靶向捕获才能实现对靶标基因的富集,整体而言步骤繁多且昂贵。
发明内容
根据第一方面,一种实施例中提供一种高保真靶标基因建库方法,包括:
磷酸化步骤,包括在模板分子的5’端修饰磷酸基团;
退火延伸步骤,包括将第一引物退火于模板分子的靶核苷酸区域并延伸,得到含有靶核苷酸延伸链的双链分子,即靶核苷酸分子,所述第一引物含有酶切位点;
第一测序接头连接步骤,包括将第一测序接头连接至所述靶核苷酸分子,获得第一测序接头连接产物;
酶切步骤,包括使用酶切断第一测序接头连接产物上具有酶切位点的第一引物,然后去除第一引物中的酶切位点5’端的核苷酸序列,得到切除了第一引物部分序列后的第一测序接头连接产物;
双链末端修平步骤,包括切除第一测序接头连接产物中原始模板链3’端突出的单链序列,得到平末端第一测序接头连接产物;
第二测序接头连接步骤,包括将第二测序接头连接至平末端第一测序接头连接产物,得到第二测序接头连接产物;
扩增步骤,包括使用第二引物、第三引物扩增第二测序接头连接产物,得到测序文库。
根据第二方面,一种实施例中提供第一方面所述方法构建得到的文库。
根据第三方面,一种实施例中提供试剂盒,包括:第一引物、第二引物、第三引物、第一测序接头、第二测序接头,所述第一引物含有酶切位点。由于第一引物含有酶切位点,因此,可以被相应的酶切断部分序列。该试剂盒可以用于文库构建。
依据上述实施例的高保真靶标基因建库方法及其试剂盒,将常规的建库和捕获分开的步骤整合为一个流程,有效简化流程,减少操作过程中DNA的损失,有效缩短操作流程,且直接对原始模板分子链建库,且两端的接头连接都是双链连接,连接效率高,是一种高性价比且高保真的建库方法。
附图说明
图1显示为一种实施例的带分子标签的测序接头制备流程示意图;
图2显示为一种实施例的文库构建流程图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。其中不同实施方式中类似元件采用了相关联的类似的元件标号。在以下的实施方式中,很多细节描述是为了使得本申请能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他元件、材料、方法所替代。在某些情况下,本申请相关的一些操作并没有在说明书中显示或者描述,这是为了避免本申请的核心部分被过多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。
另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
本文中为部件所编序号本身,例如“第一”、“第二”等,仅用于区分所描述的对象,不具有任何顺序或技术含义。而本申请所说“连接”、“联接”,如无特别说明,均包括直接和间接连接(联接)。
本文中,MAF(Minor Allele Frequency)是最小等位基因频率,通常是指在给定人群中的不常见的等位基因发生频率,例如TT、TC、CC三个基因型,在人群中C的频率=0.36,T的频率=0.64,则等位基因C就为最小等位基因频率,MAF=0.36。
根据第一方面,在一实施例中,提供一种高保真靶标基因建库方法,包括:
磷酸化步骤,包括在模板分子的5’端修饰磷酸基团;
退火延伸步骤,包括将第一引物退火于模板分子的靶核苷酸区域并延伸,得到含有靶核苷酸延伸链的双链分子,即靶核苷酸分子,所述第一引物含有酶切位点;
第一测序接头连接步骤,包括将第一测序接头连接至靶核苷酸分子,获得第一测序接头连接产物;
酶切步骤,包括使用酶切断第一测序接头连接产物上具有酶切位点的第一引物,然后去除第一引物中的酶切位点5’端的核苷酸序列,得到切除了第一引物部分序列后的第一测序接头连接产物;
双链末端修平步骤,包括切除第一测序接头连接产物中原始模板链3’端突出的单链序列,得到平末端第一测序接头连接产物;
第二测序接头连接步骤,包括将第二测序接头连接至平末端第一测序接头连接产物,得到第二测序接头连接产物;
扩增步骤,包括使用第二引物、第三引物扩增第二测序接头连接产物,得到测序文库。该文库为靶核苷酸序列两端连接有测序接头的完整文库。
在一实施例中,所述模板分子为单链DNA和/或双链DNA。模板分子可以为单链DNA、双链DNA或不规则(单双链混合)形式,可适用于严重降解的样本和微量样本,包括亚硫酸氢盐处理后的DNA。模板分子也可以是由RNA样本逆转录得到的cDNA。
在一实施例中,磷酸化步骤中,所述模板分子包括但不限于如下DNA分子中的至少一种:
a)长度≤500bp的DNA分子;
b)亚硫酸氢盐处理过的DNA分子;
c)胞外游离DNA;
d)由RNA样本逆转录得到的单链或双链的cDNA。
胞外游离DNA亦称cfDNA,简称循环核酸(circulating free DNA),通常是指体液(如血液)中游离于细胞外的部分降解了的机体内源性DNA。
在一实施例中,起始模板分子可以是各类DNA(长度在500bp以下)或亚硫酸氢盐(bisulfite)处理过的各类DNA、RNA逆转录得到的第一链cDNA或双链cDNA。
在一实施例中,在模板分子的5’端修饰磷酸基团后,通过热变性,将模板分子解离为单链DNA分子,同时使体系中的酶变性,然后进入下一步反应。当然,磷酸化酶既可以对单链DNA分子进行磷酸化修饰,也可以对双链DNA分子进行磷酸化修饰。
在一实施例中,在模板分子的5’端修饰磷酸基团后,将模板分子加热至80-98℃保持1-10min,一方面使得模板分子解离为单链,另一方面,使得磷酸化酶变性失活,反应结束后,将装有模板分子的容器至于冰上保持2-10min,避免模板分子复性为双链,然后进入下一步反应。在一些实施例中,模板分子的加热温度包括但不限于80℃、81℃、82℃、83℃、84℃、85℃、86℃、87℃、88℃、89℃、91℃、92℃、93℃、94℃、95℃、96℃、97℃、98℃等等,保持时间包括但不限于1min、2min、3min、4min、5min、6min、7min、8min、9min、10min等等。装有模板分子的容器至于冰上保持的时间包括但不限于2min、3min、4min、5min、6min、7min、8min、9min、10min等等。
在一实施例中,在模板分子的5’端修饰磷酸基团后,将模板分子加热至90-98℃保持1-10min。
在一实施例中,磷酸化步骤中,使用的酶包括但不限于T4多聚核苷酸激酶(T4polynucleotide kinase,又称T4磷酸激酶)。
在一实施例中,所述第一引物含有酶切位点、串联至所述酶切位点3’端且可与模板分子上的靶核苷酸序列互补配对的第一序列、串联至所述酶切位点5’端且不与模板分子上的核苷酸序列互补配对的第二序列。第二序列将标记分子(如生物素)和第一引物连接的靶核苷酸退火区域间隔开,增加空间位阻,让第一引物能充分施展,有利于退火。
在一实施例中,所述第二序列的长度可以为3-30nt,第二序列没有连续三个或更多同样核苷酸聚集一起,不能和第二引物、第三引物、第一接头、第二接头的序列有70%以上的相似性,且不易自身退火形成二级结构,根据该设计原则设计的第二序列均适用于本发明。第二序列的长度包括但不限于3nt、4nt、5nt、6nt、7nt、8nt、9nt、10nt、11nt、12nt、13nt、14nt、15nt、16nt、17nt、18nt、19nt、20nt、21nt、22nt、23nt、24nt、25nt、26nt、27nt、28nt、29nt、30nt等等。
在一实施例中,所述第二序列包括但不限于如下碱基序列:CAAGGACATCCG。
在一实施例中,所述第一引物的酶切位点含有尿嘧啶。
在一实施例中,所述第一引物的5’端修饰有标记分子。第一测序接头连接产物中所含第一引物的5’端含有生物素等标记分子,能和链霉亲和素包被的磁珠表面链霉亲和素共价结合,用磁力架收集磁珠,可同时将第一测序接头连接产物收集。
在一实施例中,所述标记分子包括但不限于生物素。
在一实施例中,所述第一测序接头含有第一分子标签。
在一实施例中,所述第一测序接头内侧5’端修饰有磷酸基团,所述第一测序接头内侧是指第一测序接头上可串联至靶核苷酸分子的一侧。
在一实施例中,所述第一测序接头外侧3’端修饰有磷酸基团,所述第一测序接头外侧是指第一测序接头上不可串联至靶核苷酸分子的一侧。这里的磷酸基团修饰是一种封闭修饰,目的是阻断,因为两条DNA链之间的串联连接的分子机制是一条链5’端的磷酸基和另一条链的3’端羟基脱水形成共价键,如果5’端没有磷酸基团则无法引发此反应,若3’端末尾的基团不是羟基亦无法完成此反应,故在3’端修饰磷酸基团(用磷酸基代替原本的羟基)可起到封阻DNA连接反应的效果。依此原理,第一测序接头外侧3’端修饰磷酸基后,第二测序接头内侧5’端的磷酸基就无法与第一测序接头外侧3’端做串联连接反应,从而避免在后续的第二接头连接反应中,第二测序接头串联连接在第一测序接头的外侧而形成非标准文库结构的副产物。
在一实施例中,所述第一测序接头含有可互补配对的正向链、反向链,所述正向链的5’端串联有第一分子标签,所述反向链的3’端串联有与所述第一分子标签互补配对的核苷酸序列,所述第一分子标签的5’端修饰有磷酸基团。
在一实施例中,所述第一测序接头正向链的3’端也修饰有磷酸基团,起到封闭修饰的作用。
在一实施例中,第一测序接头连接步骤中,使用包被有链霉亲和素的磁珠收集第一测序接头连接产物,然后进入酶切步骤。由于第一测序接头连接产物含串联有标记分子的第一引物,包被有链霉亲和素的磁珠结合至标记分子,通过磁力架将磁珠结合物收集于PCR管内壁,吸取PCR管内的上清并弃掉,PCR管内的保留物即为第一测序接头连接产物。
在一实施例中,酶切步骤中,使用包被有链霉亲和素的磁珠收集从第一引物上切断的酶切位点5’端所串联的第二序列,剩下的第一测序接头连接产物保留于上清液中,将上清液转入另一容器中,进入后续双链末端修平步骤。酶切位点被UDG酶所消化。
在一实施例中,酶切步骤中,使用的酶可以为UDG酶(即Uracil-DNAGlycocasylase,尿嘧啶-DNA糖基化酶)。UDG酶可以从市场上购买得到。
在一实施例中,双链末端修平步骤中,使用T4DNA聚合酶切除第一测序接头连接产物中原始模板链3’端突出的单链序列(overhang)。突出的单链序列即为第一测序接头连接产物中原始模板链3’端的未形成双链的核苷酸序列,该段序列未与第一引物延伸链互补配对形成双链。
在一实施例中,所述第二测序接头内侧5’端修饰有磷酸基团,所述第二测序接头内侧是指第二测序接头上可串联连接至第一测序接头连接产物的一侧。
在一实施例中,所述第二测序接头含有或不含有第二分子标签。
在一实施例中,所述第二测序接头包括可互补配对的正向链、反向链。
在一实施例中,所述第二测序接头不含有第二分子标签时,所述第二测序接头的反向链的5’端修饰有磷酸基团。
在一实施例中,所述第二测序接头含有第二分子标签时,所述第二测序接头的反向链的5’端串联有第二分子标签,所述第二分子标签的5’端修饰有磷酸基团,所述第二测序接头的正向链的3’端串联有可与所述第二分子标签互补配对的核苷酸序列。
在一实施例中,所述第一分子标签、第二分子标签独立地为随机核苷酸序列。
在一实施例中,所述第一分子标签、第二分子标签的长度可以独立地为4-19nt,包括但不限于4nt、5nt、6nt、7nt、8nt、9nt、10nt、11nt、12nt、13nt、14nt、15nt、16nt、17nt、18nt、19nt等等。
在一实施例中,所述第二引物含有第一样本标签。
在一实施例中,所述第二引物含有从3’端到5’端依次串联的内接头、第一样本标签、外接头,所述内接头可与第一测序接头的反向链互补配对。
在一实施例中,所述第三引物含有或不含有第二样本标签。
在一实施例中,所述第三引物不含有第二样本标签时,所述第三引物含有从3’端到5’端依次串联的内接头、外接头,所述内接头可与所述第二测序接头的反向链互补配对。
在一实施例中,所述第三引物含有第二样本标签时,所述第三引物含有从3’端到5’端依次串联的内接头、第二样本标签、外接头,所述内接头可与所述第二测序接头的反向链互补配对。
在一实施例中,所述第一样本标签、第二样本标签的长度可以独立地为4-19nt,包括但不限于4nt、5nt、6nt、7nt、8nt、9nt、10nt、11nt、12nt、13nt、14nt、15nt、16nt、17nt、18nt、19nt等等。
在一实施例中,所述第一测序接头为高通量测序平台右侧测序接头。
在一实施例中,所述第一测序接头包括但不限于Illumina测序平台的P7端测序接头、MGI测序平台的P1端测序接头或其他高通量测序平台右侧测序接头中的任意一种。
在一实施例中,所述第二测序接头为高通量测序平台左侧测序接头。
在一实施例中,所述第二测序接头包括但不限于Illumina测序平台的P5端测序接头、MGI测序平台的P2端测序接头或其他高通量测序平台左侧测序接头中的任意一种。
根据第二方面,在一实施例中,提供利用第一方面所述高保真靶标基因建库方法构建得到的文库。
根据第三方面,在一实施例中,提供一种试剂盒,包括:第一引物、第二引物、第三引物、第一测序接头、第二测序接头,所述第一引物含有酶切位点。由于第一引物含有酶切位点,因此,可以被相应的酶切断部分序列。该试剂盒可以用于测序文库构建。
在一实施例中,所述第一引物还含有串联至所述酶切位点3’端且可与模板分子上的靶核苷酸序列互补配对的第一序列、串联至所述酶切位点5’端且不与模板分子上的核苷酸序列互补配对的第二序列。
在一实施例中,所述第二序列的长度可以为3-30nt,第二序列没有连续三个或更多同样核苷酸聚集一起,不能和第二引物、第三引物、第一接头、第二接头的序列有70%以上的相似性,且不易自身退火形成二级结构,根据该设计原则设计的第二序列均适用于本发明。第二序列的长度包括但不限于3nt、4nt、5nt、6nt、7nt、8nt、9nt、10nt、11nt、12nt、13nt、14nt、15nt、16nt、17nt、18nt、19nt、20nt、21nt、22nt、23nt、24nt、25nt、26nt、27nt、28nt、29nt、30nt等等。
在一实施例中,所述第二序列包括但不限于如下碱基序列:CAAGGACATCCG。
在一实施例中,所述第一引物的酶切位点含有尿嘧啶。
在一实施例中,所述第一引物的5’端修饰有标记分子。
在一实施例中,所述标记分子包括但不限于生物素。
在一实施例中,所述第二引物含有第一样本标签。
在一实施例中,所述第二引物含有从3’端到5’端依次串联的内接头、第一样本标签、外接头,所述内接头可与第一测序接头的反向链互补配对。
在一实施例中,所述第三引物含有或不含有第二样本标签。
在一实施例中,所述第三引物不含有第二样本标签时,所述第三引物含有从3’端到5’端依次串联的内接头、外接头,所述内接头可与所述第二测序接头的反向链互补配对。
在一实施例中,所述第三引物含有第二样本标签时,所述第三引物含有从3’端到5’端依次串联的内接头、第二样本标签、外接头,所述内接头可与所述第二测序接头的反向链互补配对。
在一实施例中,所述第一样本标签、第二样本标签的长度独立地为4-19nt,包括但不限于4nt、5nt、6nt、7nt、8nt、9nt、10nt、11nt、12nt、13nt、14nt、15nt、16nt、17nt、18nt、19nt等等。
在一实施例中,所述第一测序接头含有第一分子标签。
在一实施例中,所述第一测序接头内侧5’端修饰有磷酸基团,所述第一测序接头内侧是指第一测序接头上可串联至靶核苷酸分子的一侧。
在一实施例中,所述第一测序接头外侧3’端修饰有磷酸基团,所述第一测序接头外侧是指第一测序接头上不可串联至靶核苷酸分子的一侧。
在一实施例中,所述第一测序接头含有互补配对的正向链、反向链,所述正向链的5’端串联有第一分子标签,所述反向链的3’端串联有与所述第一分子标签互补配对的核苷酸序列,所述第一分子标签的5’端修饰有磷酸基团。
在一实施例中,所述第二测序接头内侧5’端修饰有磷酸基团,所述第二测序接头内侧是指第二测序接头上可串联至第一测序接头连接产物的一侧。
在一实施例中,所述第二测序接头含有或不含有第二分子标签。
在一实施例中,所述第二测序接头含有互补配对的正向链、反向链。
在一实施例中,所述第二测序接头不含有第二分子标签时,所述第二测序接头的反向链的5’端修饰有磷酸基团。
在一实施例中,所述第二测序接头含有第二分子标签时,所述第二测序接头的反向链的5’端串联有第二分子标签,第二分子标签的5’端修饰有磷酸基团,所述第二测序接头的正向链的3’端串联有可与所述第二分子标签互补配对的核苷酸序列。
在一实施例中,所述第一分子标签、第二分子标签独立地为随机核苷酸序列。
在一实施例中,所述第一分子标签、第二分子标签的长度可以独立地为4-19nt,包括但不限于4nt、5nt、6nt、7nt、8nt、9nt、10nt、11nt、12nt、13nt、14nt、15nt、16nt、17nt、18nt、19nt等等。
在一实施例中,所述第一测序接头包括高通量测序平台右侧测序接头。
在一实施例中,所述第一测序接头包括但不限于Illumina测序平台的P7端测序接头、MGI测序平台的P1端测序接头或其他高通量测序平台右侧测序接头中的任意一种。
在一实施例中,所述第二测序接头包括高通量测序平台左侧测序接头。
在一实施例中,所述第二测序接头包括但不限于Illumina测序平台的P5端测序接头、MGI测序平台的P2端测序接头或其他高通量测序平台左侧测序接头中的任意一种。
以下实施例中,以Illumina平台测序文库制备为例,其他NGS平台同样适用于本发明,只是测序接头序列需做相应改变。
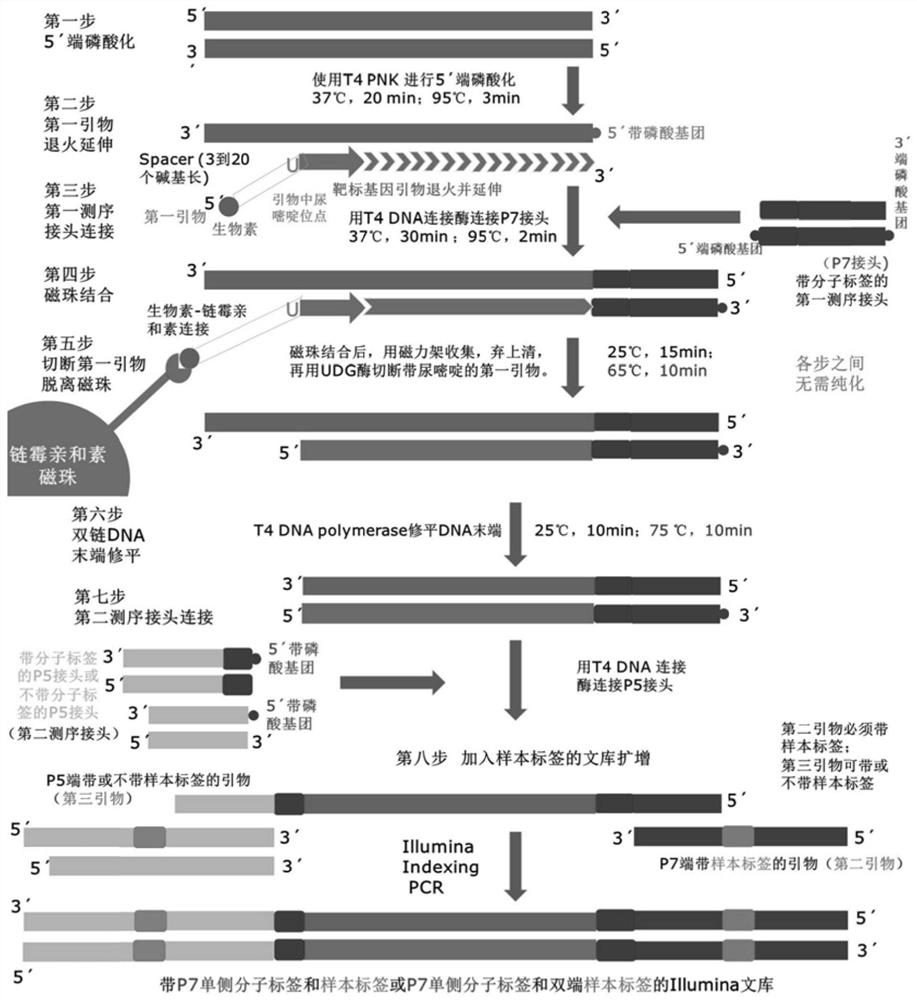
在一实施例中,本发明的建库方法主要包括如下步骤:1、模板DNA5′端磷酸化;2、靶向引物退火延伸;3、第一接头连接;4、磁珠结合;5、UDG酶切;6、平末端修复;7、第二接头连接;8、加样本标签的文库扩增。
在一实施例中,图1所示为带分子标签的测序接头制备流程图,图2所示为建库方法主要流程图,主要包括如下步骤:
1、使用T4磷酸激酶对DNA进行5’端磷酸化处理,在PCR仪中进行如下反应:37℃,20分钟;95℃,1-10分钟,并立即对产物进行冰浴处理,冰浴处理时间为2分钟至1小时,得到单链模板分子。
2、使用5’端带生物素且3’端带可与靶标基因互补配对的核苷酸序列的第一引物(引物含有用于后续酶切的尿嘧啶位点,尿嘧啶位点5’端串联有不会与靶核苷酸序列互补的序列,尿嘧啶位点3’端串联有可与靶核苷酸序列互补配对的核苷酸序列),在靶标基因分子上进行引物退火并延伸。
3、在PCR仪中采用T4DNA连接酶连接P7接头(即第一测序接头)。此P7接头靠近模板分子的一端带有第一分子标签,且内侧(可与模板分子串联的一侧)的5’端修饰有磷酸基团。
4、连接完成以后,用包被有链霉亲和素的磁珠抓取带生物素的第一引物延伸产物,去除上清,双链文库分子保留在PCR管内,向PCR管中加入UDG酶,切断第一引物上的尿嘧啶位点及其5’端的核苷酸序列,然后使用T4DNA聚合酶修平产物,再加入内侧5’端带磷酸基团的发夹式P5接头(即第二测序接头),使得修平产物连接至P5端发卡接头,25-37℃下孵育30-120分钟,然后95℃下热变性2分钟,使得T4DNA连接酶变性失活,以彻底终止接头连接反应。
5、直接在连接反应产物中加入DNA聚合酶及其配套缓冲液、P5端带或不带样本标签的第三引物、P7端带样本标签的第二引物、dNTP,配成反应体系,做加样本标签的PCR,反应条件如下:95℃,3分钟;6-30个循环,每个循环如下:95-98℃,30秒;60℃,10-30秒;72℃,10-30秒;循环反应结束后,在72℃下反应1-10分钟。
6、反应完成后,采用诺唯赞磁珠纯化反应,得到带P7单侧分子标签和样本标签的Illumina文库,或带P7单侧分子标签和双端样本标签的Illumina文库,或带双侧分子标签、双端样本标签的Illumina文库。
图2中的“各步之间无需纯化”,具体是指酶切步骤与双链末端修平步骤之间、双链末端修平步骤与第二测序接头连接步骤之间、第二测序接头连接步骤与扩增步骤之间无需纯化。各步骤之间无需纯化,不仅节省时间和试剂,也节省了原始DNA样本,因为每一步纯化都会造成DNA的损失,因此各步骤之间无需纯化也是本发明的一大优势。
在一实施例中,将常规的建库和捕获分开的步骤整合为一个流程,有效缩短操作流程,从磷酸化步骤开始,到文库构建完成,只需约9小时,操作简易。
在一实施例中,本发明可完全基于双链接头连接(第一测序接头、第二测序接头连接至模板分子时均为双链连接),连接时间只需15-30min,接头连接效率比单链建库高。
在一实施例中,本发明的建库起始模板可以为单链、双链或不规则(即单双链混合)形式,可适用于严重降解的样本和微量样本,包括亚硫酸氢盐处理后的DNA。
在一实施例中,基于单向引物延伸并直接抓取原始的DNA链,可实现基因组结构性变异检测(包括但不限于基因拷贝数变化、融合基因和病毒插入序列检测等)。
在一实施例中,本发明可直接将原始的DNA链用于建库,有利于更准确的捕获并鉴定突变。
在一实施例中,本发明当原始双链DNA分子中只有一条链上有突变时亦可鉴定,因为本技术是将原始DNA样本的两条链分开,分别建入测序文库。
在一实施例中,RNA样本逆转录为第一链cDNA后可自动兼容本发明,且无需二链合成,节省物料和时间,且避免常规的二链合成过程中随机引物带来的一些列错误和偏好性。
在一实施例中,本发明还可适用于亚硫酸氢盐处理后的DNA、cfDNA、打断后的基因组DNA等等样本的建库。
在一实施例中,本发明中,模板分子两端的接头均采用常规的双链连接,更廉价,且原始样本分子利用率更高。
在一实施例中,本发明需要的DNA投入量至少20ng,组织样本提取的基因组DNA需要打断至200bp到600bp之间。
在一实施例中,本发明依赖一种进口的酶Thermolabile
在一实施例中,本发明的建库方法及其试剂盒可以用于检测超低频基因突变,在一实施例中,可以用于检测突变频率低至0.03%的样本。
现有技术一般都是对原始DNA分子的扩增产物做文库构建,在一实施例中,本发明是直接对原始模板分子链建库,且两端的接头连接都是双链连接,连接效率高,能高保真地将原始模板分子建入测序文库。
实施例1
本实施例的建库方法参照图1和图2进行。
本实施例首先制备突变频率为万分之三的突变游离核酸(cfDNA)标准品,然后取三等份该cfDNA标准品各用于三个独立的文库构建实验,每份cfDNA标准品的质量为60ng,分别采用本实施例的方法、现有的杂交捕获建库方法(对比例1)和现有的扩增子建库方法(对比例2)作为测序文库的文库制备方法,且三组实验所设计的靶标基因区域基本一致,然后在同样的高通量测序平台上上机测序,并测序相同数据量,最后采用同样的数据分析流程,检查同样的8个靶标基因突变位点(这8个位点分布于4个基因的外显子区域,4个基因分别为NRAS、KRAS、PIK3CA、EGFR)的检测情况,以评估三种高通量测序靶标基因文库构建技术的性能差别。
本实施例以国际常用的Illumina测序平台的文库为例,其他高通量测序平台也适用于本发明,只是测序接头序列需做相应替换。
实验材料和设备:
本实施例的标准品购自菁良基因科技(深圳)有限公司,具体为肺癌ctDNA标准品套装GW-OCTM009,其中含有野生型DNA标准品和突变频率为0.1%的ctDNA标准品,将两者按照7:3的质量比混合,得到突变频率为0.03%的稀释标准品。
靶标检测位点如下表1所示。
表1
所需寡聚体(oligo)如下表2、表3所示(由南京金斯瑞生物科技有限公司合成、HPLC纯化)。
表2
表3:5’端带生物素修饰的靶标基因探针(第一引物)
对表2、表3中的符号说明如下:(1)“Biotin-”代表生物素标记。
(2)IS2-RC-N和IS2退火成双链DNA分子,即第一测序接头;IS1-RC-N(或IS1-RC)和IS1退火成双链DNA分子,即第二测序接头。
(3)“N”代表核苷酸中的随机碱基,随机碱基可以是A、T、C、G碱基中的任意一种。
(4)含靶标基因互补配对序列的第一引物(Biotin-U-GSP)中,X代表和靶标基因区域互补配对的序列,20个核苷酸长,在靶标基因区域每10个核苷酸向前排布一个该种序列,即2x瓦片式覆盖。
(5)“Pho”代表磷酸基团。
(6)“U”代表带尿嘧啶的脱氧核苷酸,即dUTP。
(7)带样本标签的P7端引物-标签1中,下划直线标记的序列“TGATAG”为样本标签。
试剂及仪器说明如下:
1)对各类DNA模板做5’端磷酸化采用的是T4Polynucleotide Kinase(10U/μL),购自英潍捷基(上海)贸易有限公司,货号EK0031。
2)第一测序接头制备反应采用的是DNA polymerase I Klenow Fragment(5U/μL),购自南京诺唯赞生物科技股份有限公司,货号:N104-01。
3)第一引物延伸反应采用的是
4)各接头连接反应均采用的是T4DNA Ligase(Rapid),购自南京诺唯赞生物科技股份有限公司,货号:N103-01。
5)将带dUTP的第一引物延伸产物切断时,采用的是Thermolabile
6)将与第一引物延伸产物互补配对的原始模板链的3’端突出的单链核苷酸序列(overhang)切除时,采用的是T4DNA polymerase,购自南京诺唯赞生物科技股份有限公司,货号:N101-01。
7)文库扩增反应采用的是VAHTS HiFi Amplification Mix,购自南京诺唯赞生物科技股份有限公司,货号:N616-01。
8)PCR产物纯化磁珠VAHTS DNA Clean Beads购自南京诺唯赞生物科技股份有限公司,货号:N411-01。
9)结合单链连接产物所用的链霉亲和素磁珠Dynabeads
10)各步实验所用超纯水均为ULtraPure
11)仪器:ABI veriti96型PCR仪(英潍捷基(上海)贸易有限公司出品),恒温混匀仪(杭州佑宁仪器有限公司,货号HC-100),四维旋转混合仪(海门市其林贝尔仪器制造有限公司,BE-1100),磁力架(无锡百格生物科技有限公司,货号BMB16-1.5-2),Qubit
12)本实施例的TE缓冲液组成如下:10mmol/L Tris-HCl、1mmol/L EDTA,pH=8.0。
如图1、图2所示,本实施例的实验步骤如下:
1、取菁良基因-肺癌ctDNA标准品套装-GW-OCTM009(20ng/μL),其中含有野生型DNA标准品和突变频率为0.1%的ctDNA标准品,按照野生型DNA标准品:突变频率为0.1%的ctDNA标准品=7:3的质量比混合,形成突变频率为0.03%的cfDNA样本60ng。
2、对DNA样本做磷酸化反应:
在上一步反应产物的原200微升PCR管中配制如下反应体系:
表4
然后将PCR管置于PCR仪中,进行如下反应:37℃,20分钟;95℃,3分钟。95℃反应3分钟可以使得DNA样本解离为单链,而且使得反应体系中的酶变性失活。然后置于冰上5分钟,避免其复性为双链,得到5’端磷酸化的单链cfDNA样本20μL。
3、制备第一测序接头(带分子标签)
3.1在200μL PCR管中配置以下反应体系:
表5 第一测序接头制备体系
3.2置于PCR仪中,进行如下反应:95℃,10s;以RAMP 4%(0.1℃/s)速率缓慢降温至14℃。
3.3形成第一测序接头前体,浓度为200pmol/μL。
3.4在200μL PCR管中配制以下反应体系:
表6
3.5置于PCR仪中进行如下反应:37℃,15min;95℃,3min(95℃反应3min的目的是使Klenow Fragment酶变性);形成第一测序接头,终浓度为100pmol/μL。反应结束后,自然降至室温(室温是指23℃±2℃,后续提及室温之处的定义均与此相同),备用。
制得的产物可置于-20℃环境中长期保存,或者置于4℃保存8小时。
4、制备第二测序接头(带分子标签)
4.1在200μL PCR管中配制以下反应体系:
表7 第二测序接头退火体系
4.2退火反应条件:95℃,10秒;以RAMP 4%(0.1℃/s)的速率缓慢降温至14℃。
4.3形成第二测序接头(带分子标签)前体,浓度为200pmol/μL。
4.4在200μL PCR管中配制以下反应体系:
表8
4.5置于PCR仪中,进行如下反应:37℃,15min;95℃,3min(95℃反应3min的目的是使Klenow Fragment酶变性)。形成第二测序接头(带分子标签),终浓度为100pmol/μL。反应结束后,自然降至室温,备用。
制得的产物可置于-20℃环境中长期保存,或者置于4℃环境中保存8小时。
5、制备第二测序接头(不带分子标签)
5.1在200μL PCR管中配制以下反应体系:
表9 第二测序(不带分子标签)接头退火体系
5.2退火反应条件:95℃,10秒;以RAMP 4%(0.1℃/s)的速率缓慢降温至14℃。
5.3在上述反应产物(50μL)中加入50μL的TE buffer,得到第二测序接头,终浓度为100pmol/μL,即100μM。
制得的产物可置于-20℃环境中长期保存,或者置于4℃环境中保存8小时。
6、将表3中各5′端带生物素修饰的靶标基因探针(第一引物)按等摩尔数混合成200pmol/μL的终浓度。
7、第一引物的退火和延伸
对每个单管反应,检测的靶标基因位点数可从1到1万个,每个位点对应一个带有特定靶标基因结合区的第一引物,因此对每个单管反应最多可混合1万个该类探针。本实施例的靶标基因检测位点数为8个,具体如表1所示,这8个靶标基因位点的第一引物如表3所示,每个位点2条引物,共16条。将这16条第一引物等摩尔数混合,得到本实施例所需的第一引物混合液,终浓度为200μM。
在200微升PCR管里配制如下反应体系(本反应采用购自南京诺唯赞生物科技股份有限公司的多重PCR试剂
表10
涡旋混匀并短暂离心,置于PCR仪中做如下反应:
多重靶标基因位点第一引物混合物在cfDNA样本的靶标区域退火和延伸,在PCR仪中反应条件如下:95℃,3分钟;55℃,60秒;72℃,5分钟。反应结束后,自然降至室温,备用。
8、第一测序接头连接反应
直接在上一步产物所在的200微升PCR管里配制如下反应体系:
表11
在PCR仪内进行如下反应:37℃反应半小时,此环节是做连接反应,然后95℃下反应1到10分钟(本实施例为2分钟),使T4DNA连接酶失活。反应结束后,自然降至室温,备用。
9、链霉亲和素磁珠结合并纯化第一测序接头连接产物
取3至20微升(本实施例为5微升)Dynabeads
10、酶切切断带尿嘧啶的引物
直接向盛磁珠的PCR管内加入如下反应体系:
表12
充分涡旋将磁珠均匀重悬,短暂离心,置于PCR仪中进行如下反应:25℃,15min;65℃,10min。反应结束后,将该PCR管置于磁力架上静置1至10分钟(本实施例为5分钟),待结合有切断物的磁珠全部被磁力架收集后,吸取上清并转移至一个新的PCR管内。
11、第一引物延伸产物中末端修平(切除3’端突出的单链序列,即3’overhang):
直接向上一步的PCR管内加入如下试剂:
表13
反应体系总体积60微升,涡旋混匀并短暂离心,置于PCR仪中做如下反应:25℃,10min;75℃,10min。反应结束后,自然降至室温,备用。
12、第二测序接头(不带分子标签)连接反应
直接在上一步的200微升PCR管里配制如下反应体系:
表14
总反应体积80微升,在PCR仪内37℃反应半小时(接头连接),95℃反应2分钟(将T4DNA Ligase变性失活)。反应结束后,自然降至室温,备用。
13、将第二测序接头连接反应产物等分成两份(每份各自做PCR和纯化,最后将纯化产物合并),每份40微升,加入含与第一测序接头反向链互补配对序列的第二引物、含与第二测序接头反向链互补配对序列的第三引物,PCR反应,得到完整文库(Illuminaindexing PCR)。具体地,反应体系如下:
表15
按上表配成100微升反应体系做PCR,反应条件如下:
表16
反应完成后,采用VAHTS DNA Clean Beads磁珠纯化产物,按该磁珠纯化PCR产物的标准操作进行,最后一步用22.5微升超纯水洗脱最终产物,并将同一样本的两份洗脱产物合并,建成P7端带样本标签的Illumina靶标基因文库。
对比例1
本对比例提供杂交捕获对照实验。
取菁良基因-肺癌ctDNA标准品套装-GW-OCTM009中含有野生型DNA标准品和突变频率为0.1%的ctDNA标准品,按照7:3的质量比混合形成0.03%的突变频率的DNA样本60ng。捕获基因清单如下:NRAS、KRAS、PIK3CA、EGFR。按前述基因清单在南京金斯瑞生物科技股份有限公司下单合成杂交捕获探针(按照杂交捕获探针的通用设计理念,覆盖基因清单所列基因的全部外显子区域,此为定制产品,无货号),杂交捕获探针捕获区域完全涵盖了实施例1中全部探针覆盖的基因组区域,采用金斯瑞生物科技股份有限公司所提供的建库和杂交捕获试剂盒,按照标准操作流程进行文库构建,包括捕获前扩增、杂交捕获和捕获后扩增,并送测序。
对比例2
本对比例提供基于多重PCR技术的扩增子建库对照实验。
取菁良基因-肺癌ctDNA标准品套装-GW-OCTM009中含有野生型DNA标准品和突变频率为0.1%的ctDNA标准品,按照7:3的质量比混合形成0.03%的突变频率的DNA样本60ng。靶标基因清单如下:NRAS、KRAS、PIK3CA、EGFR。按前述靶标基因清单在南京金斯瑞生物科技股份有限公司下单合成多重PCR探针套装(按照扩增子建库的通用设计理念,覆盖基因清单所列基因的全部外显子区域,此为定制产品,无货号),探针的靶标区域完全涵盖了实施例1中全部探针覆盖的基因组区域,采用金斯瑞生物科技股份有限公司所提供的扩增子建库试剂盒,按照标准操作流程进行扩增子建库,并送测序。
上机测序
上述实施例1、对比例1、对比例2的产物均用Qubit4.0测定浓度,并各取20ng,送上机测序。仪器型号Illumina Hiseq 4000,策略为PE150,数据量为1Gb每个样本。
测序数据质控和分析流程
原始数据处理采用fastp软件,基因组比对采用BWA软件(即Burrows-Wheeler-Alignment Tool,算法为BWA-MEM),参考基因组采用GRCh38(亦称hg38,为国际通用人类参考基因组序列),使用sambamba软件进行标记(markdup)。
分析结果
实施例1构建的文库的测序结果为10个index拆分的读段数(reads数)的合集,具体见下表:
表17
由上表可见,各index间reads数分布偏好性低(各index所拆分的reads数相近),且无法列入index的reads数仅占总reads数的0.12%,说明实施例1使用的P7端带样本标签的indexing扩增系统可以精准地对多个样本进行混合靶标基因建库和测序。
突变检测结果如下:
表18
上表中,raw base是指原始数据量。
GC含量是指鸟嘌呤(Guanine)和胞嘧啶(Cytosine)所占的比率。
Q30代表正确率在99.9%的reads占总reads数的比例。
depth in target是指靶标位点的测序深度。
ref_reads表示人类参考基因组上对应的reads数。
alt reads表示突变(variant)的reads数。
MAF(Mutation Allele Frequency)为突变频率,具体为alt reads与ref_reads的比值。
由上表可见,实施例1所构建的文库的测序数据质量相对于其他两项现有技术所构建文库的测序结果更高,具体地,Q30比例更高;且基于实施例1所构建的文库所检测得到的靶标基因突变的频率更接近真实值,更接近0.03%这一预设值。因此,实施例1的文库构建方法在对人类等复杂基因组的特定靶标基因做测序检测时的性能更优,且耗时更短。杂交捕获建库需72-80小时,扩增子建库需24-32小时,实施例1仅需9小时。且实施例1所需步骤少,所需各种实际和耗材少,因此成本低。综上,实施例1的建库方法在临床检测、分子医学研究和基因组科学研究中有更广泛的应用。
实施例1中采用带分子标签的第二测序接头和不带样本标签的第三引物,得到的靶标基因文库为双端分子标签和单端样本标签的测序文库;在实际应用中亦可根据需要选择用不带分子标签的第二测序接头和带样本标签的第三引物,可得到带单端分子标签和双端样本标签的测序文库;双端分子标签可提高鉴定超低频突变时的准确度;双端样本标签理论上可更好的降低多样本混合测序时拆分不同分子标签的文库时的样本间的分子标签串扰,提高各样本数据拆分准确度和数据有效利用率。
实施例2
本实施例使用从福尔马林固定和石蜡包埋(FFPE)组织标准品(购自菁良基因科技(深圳)有限公司,包括肿瘤野生型FFPE标准品和肿瘤SNV 5%FFPE标准品)中所提取的DNA,制备成突变频率为万分之五的肿瘤突变标准品,取三等份各300ng该DNA标准品,各用于三个独立的文库构建实验,分别采用本实施例的方法、现有的杂交捕获建库方法和现有的扩增子建库方法作为测序文库的文库制备方法,且三组实验所设计的靶标基因区域基本一致,然后在同样的高通量测序平台上上机测序,并测序相同数据量,最后采用同样的数据分析流程,检查同样的7个靶标基因突变位点(这7各位点分布于4个基因的外显子区域,这4个基因分别为NRAS、KRAS、PIK3CA、EGFR)的检测情况,以评估三种高通量测序靶标基因文库构建方法的性能差别(三种文库构建方法即本实施例的建库方法、现有的杂交捕获建库方法和现有的扩增子建库方法)。
本实施例以国际常用的Illumina测序平台的文库为例,其他高通量测序平台流程也适用于本发明,只是测序接头序列需做相应替换。
实验材料和设备:
DNA标准品采用购自菁良基因科技(深圳)有限公司的肿瘤野生型FFPE标准品(突变频率为0,货号GW-OPSM005)和肿瘤SNV 5%FFPE标准品(货号GW-OPSM003)。
FFPE标准品的DNA提取采用广州美基生物科技有限公司磁珠法石蜡包埋组织DNA提取试剂盒(货号:D6323-02B)。
FFPE总DNA片段化(即将10kb以上的长片段总DNA打断成200-500bp长的短片段)时,采用购自罗氏诊断产品(上海)有限公司的KAPA Frag Kit for EnzymaticFragmentation试剂盒(货号KK8600)做酶切打断。
靶标检测位点如下:
表19
所需寡聚物(oligo)如下:
表20
表21:5’端带生物素修饰的靶标基因探针(第一引物)
说明:(1)“Biotin-”代表生物素标记。
(2)IS2-RC-N和IS2退火成双链DNA分子,即第一测序接头;IS1-RC-N(或IS1-RC)和IS1退火成双链DNA分子,即第二测序接头。
(3)”N”代表核苷酸中的随机碱基。
(4)“X”代表和靶标基因区域互补配对的序列,20个核苷酸长,在靶标基因区域每10个核苷酸向前排布一个该种序列,即2x瓦片式覆盖。
(5)“Pho”代表磷酸基团。
(6)“U”代表带尿嘧啶的脱氧核苷酸,即dUTP。
(7)带样本标签的P7端引物-标签1中,下划直线标记的序列“TGATAG”为样本标签。
对各类DNA模板做5’端磷酸化时,采用T4Polynucleotide Kinase(10U/μL)(购自英潍捷基(上海)贸易有限公司,货号EK0031)。
第一测序接头制备时,采用DNA polymerase I Klenow Fragment(5U/μL),货号:N104-01,购自南京诺唯赞生物科技股份有限公司。
第一引物延伸反应时,采用
各接头连接反应均采用T4DNA Ligase(Rapid),货号:N103-01,购自南京诺唯赞生物科技股份有限公司。
将带dUTP的第一引物延伸产物切断时,采用Thermolabile
将与第一引物延伸产物配对的原始模板链的3’端突出的单链部分切除时,采用T4DNA polymerase,货号:N101-01,购自南京诺唯赞生物科技股份有限公司。
文库扩增反应采用VAHTS HiFi Amplification Mix,货号:N616-01,购自南京诺唯赞生物科技股份有限公司。
PCR产物纯化磁珠为VAHTS DNA Clean Beads,货号:N411-01,购自南京诺唯赞生物科技股份有限公司。
结合第一引物延伸产物所用链霉亲和素磁珠为Dynabeads
各步实验所用超纯水均为ULtraPure
仪器:ABI veriti96型PCR仪(英潍捷基(上海)贸易有限公司),恒温混匀仪(杭州佑宁,货号HC-100),四维旋转混合仪(海门市其林贝尔仪器制造有限公司,BE-1100),磁力架(无锡百格生物科技有限公司,货号BMB16-1.5-2),Qubit
本实施例的步骤如下:
1、采用购自广州美基生物科技有限公司的磁珠法石蜡包埋组织DNA提取试剂盒(货号:D6323-02B),对购自菁良基因科技(深圳)有限公司的肿瘤野生型FFPE标准品(突变频率为0,货号GW-OPSM005)和肿瘤SNV 5%FFPE标准品(货号GW-OPSM003)做总DNA提取,按照该试剂盒标准操作流程进行,最终按50微升体积洗脱获得DNA提取物。
2、用Qubit4.0测定浓度,野生型和5%SNV的FFPE DNA浓度分别为15.54ng/μL和14.78ng/μL,总量分别为777ng和739ng,取297ng肿瘤野生型FFPE标准品DNA和3ng肿瘤SNV5%FFPE标准品DNA。混合(即按质量比99:1混合),形成0.05%的突变频率的FFPE DNA样本300ng,涡旋充分混匀。
3、将上一步产物放入一个200微升PCR管中,采用KAPA Frag Kit for EnzymaticFragmentation试剂盒做酶切打断,打断后的片段长度范围为200-600bp,主峰在300bp左右。用0.9倍体积VAHTS DNA Clean Beads(货号:N411-01)按标准操作流程做纯化,最后用23.5微升纯水洗脱纯化产物,取其中1微升,用Qubit4.0测定其浓度,结果为7.28ng/μL,即得到片段化并纯化后的FFPE样本DNA 163.8ng。
4、对DNA样本做磷酸化反应:
在上一步反应产物的原200微升PCR管中配制如下反应体系:
表22
置于PCR仪中,进行如下反应:37℃,20min;95℃,3min。95℃反应3分钟可以使得反应体系中的酶变性失活,同时使得DNA分子解离为单链,然后置于冰上5分钟,避免其复性为双链,得到5’端磷酸化的DNA样本30μL,取其中1μL用Qubit4.0测定其浓度,结果为5.42ng/μL。
5、制备第一测序接头(带分子标签)
5.1在200μL PCR管中配制以下反应体系:
表23 第一测序接头制备体系
5.2置于PCR仪中进行如下反应:95℃,10s;以RAMP 4%(0.1℃/s)速率缓慢降温至14℃。
5.3形成第一测序接头前体,浓度为200pmol/μL。
5.4在200μL PCR管中配制以下反应体系:
表24
5.5置于PCR仪中进行如下反应:37℃,15min;95℃,3min(使Klenow Fragment酶变性),形成第一测序接头,终浓度为100pmol/μL。反应结束后,自然降至室温,备用。
制得的产物可置于-20℃环境中长期保存,或者置于4℃环境中保存8小时。
6、制备第二测序接头(带分子标签)
6.1在200μL PCR管中配制以下反应体系:
表25
6.2退火反应,条件如下:95℃,10秒;以RAMP 4%(0.1℃/s)速率缓慢降温至14℃。
6.3形成第二测序接头(带分子标签)前体,浓度为200pmol/μL。
6.4在200μL PCR管中配制以下反应体系:
表26
6.5置于PCR仪中进行如下反应:37℃,15min;95℃,3min(使Klenow Fragment酶变性);形成第二测序接头(带分子标签),终浓度为100pmol/μL。反应结束后,自然降至室温,备用。
制得的产物可置于-20℃环境中长期保存,或者置于4℃环境中保存8小时。
7、制备第二测序接头(不带分子标签)
7.1在200μL PCR管中配制以下反应体系:
表27 第二测序(不带分子标签)接头退火体系
7.2退火反应条件:95℃,10秒;以RAMP 4%(0.1℃/s)速率缓慢降温至14℃。
7.3在上述反应产物(50μL)中加入50μL的TE buffer,得到第二测序接头,终浓度为100pmol/μL,即100μM。
制得的产物可置于-20℃环境中长期保存,或者置于4℃环境中保存8小时。
8、将表21中各5′端带生物素修饰的靶标基因探针(第一引物)按等摩尔数混合成200pmol/μL的终浓度。
9、第一引物的退火和延伸
对每个单管反应,检测的靶标基因位点数可以为1个到1万个,每个位点对应一个带有特定靶标基因结合区的第一引物,因此对每个单管反应最多可混合1万个该类探针。本实施例的靶标基因检测位点数为7个,具体如表19所示,这7个靶标基因位点的第一引物如表21所示,每个位点2条引物,共14条。将这14条第一引物等摩尔数混合,得到本实施例所需的第一引物混合液,终浓度为200μM。
在200微升PCR管里配制如下反应体系(本反应采用购自南京诺唯赞生物科技股份有限公司的多重PCR试剂
表28
涡旋混匀并短暂离心,置于PCR仪中做如下反应:
多重靶标基因位点第一引物混合物在基因组的靶标区域退火和延伸,在PCR仪中进行,反应条件如下:95℃,3分钟;55℃,60秒;72℃,5分钟。反应结束后,自然降至室温,备用。
10、第一测序接头连接反应
直接在上一步产物所在的200微升PCR管里配制如下反应体系:
表29
总反应体积100微升,在PCR仪内进行如下反应:37℃反应30分钟,此环节是做连接反应,然后95℃下反应1到10分钟(本实施例为2分钟),使连接酶变性失活。反应结束后,自然降至室温,备用。
11、链霉亲和素磁珠结合并纯化第一测序接头连接产物
取3至20微升(本实施例为5微升)Dynabeads
12、酶切切断带尿嘧啶的引物
直接向盛磁珠的PCR管内加入如下反应体系:
表30
充分涡旋,将磁珠均匀重悬,短暂离心,置于PCR仪中做如下反应:25℃,15min;65℃,10min(65℃反应10min的目的是使得Thermolabile
13、第一引物延伸产物中末端修平(切除3’端突出序列,即3’overhang)
直接向上一步的PCR管内加入如下试剂:
表31
反应体系总体积60微升,涡旋混匀并短暂离心,置于PCR仪中做如下反应:25℃,10min;75℃,10min(将T4 DNA polymerase变性失活)。反应结束后,自然降至室温,备用。
14、第二测序接头(不带分子标签)连接反应
直接在上一步的200微升PCR管里配制如下反应体系:
表32
总反应体积80微升,在PCR仪内进行如下反应:37℃反应30分钟(接头连接);95℃反应2分钟(将T4DNA Ligase变性失活)。反应结束后,自然降至室温,备用。
15、将第二测序接头连接反应产物两等分,每份40微升,加入含与第一测序接头反向链互补配对序列的第二引物、含与第二测序接头反向链互补配对序列的第三引物,做PCR反应,得到完整文库(Illumina indexing PCR)。具体地,反应体系如下:
表33
按上表配成100微升反应体系做PCR,反应条件如下:
表34
反应完成后,采用VAHTS DNA Clean Beads磁珠纯化产物,按该磁珠纯化PCR产物的标准操作进行,最后一步用20微升超纯水洗脱最终产物,将每个样本对应的两等分的两个PCR得纯化洗脱液混合,得到40微升纯化产物,建成P7端带样本标签的Illumina靶标基因文库。
本实施例中采用不带分子标签的第二测序接头和不带样本标签的第三引物,得到的靶标基因文库为单端分子标签和单端样本标签的测序文库。在一些实施例中,亦可根据需要选择用带分子标签的第二测序接头和带样本标签的第三引物,可得到带双端分子标签和双端样本标签的测序文库;双端标签可提高鉴定超低频突变时的准确度。
对比例3
本对比例提供杂交捕获对照实验。
取购自菁良基因科技(深圳)有限公司的肿瘤野生型FFPE标准品和肿瘤SNV 5%FFPE标准品,按照99:1的质量比混合,形成0.05%的突变频率的DNA样本300ng,并按与实施例2相同的酶切方式做片段化筛选和磁珠纯化。按靶标基因清单(靶标基因具体为:NRAS、KRAS、PIK3CA、EGFR)在南京金斯瑞生物科技股份有限公司下单合成杂交捕获探针(按照杂交捕获探针的通用设计理念,覆盖该表所列基因的全部外显子区域,此为定制产品,无货号),采用金斯瑞生物科技股份有限公司所提供的建库和杂交捕获试剂盒,按照标准操作流程进行文库构建,包括捕获前扩增、杂交捕获和捕获后扩增,并送测序。
对比例4
本对比例提供基于多重PCR技术的扩增子建库对照实验。
取购自菁良基因科技(深圳)有限公司的肿瘤野生型FFPE标准品和肿瘤SNV 5%FFPE标准品,按照99:1的质量比混合,形成0.05%的突变频率的DNA样本300ng,并按与实施例2相同的酶切方式做片段化筛选和磁珠纯化。按靶标基因清单(靶标基因具体为:NRAS、KRAS、PIK3CA、EGFR)在南京金斯瑞生物科技股份有限公司下单合成多重PCR探针套装(按照扩增子建库的通用设计理念,覆盖该表所列基因的全部外显子区域,此为定制产品,无货号),采用金斯瑞生物科技股份有限公司所提供的扩增子建库试剂盒,按照标准操作流程进行扩增子建库,并送测序。
上机测序
取实施例2、对比例3、对比例4制得的文库产物,均用Qubit4.0测定浓度,并各取20ng,送上机测序。仪器型号illumina Hiseq 4000,策略为PE150,数据量为1Gb每个样本。
测序数据质控和分析流程
原始数据处理采用fastp软件,基因组比对采用BWA软件(即Burrows-Wheeler-Alignment Tool,算法为BWA-MEM),参考基因组采用GRCh38/hg38(国际通用人类基因组参考序列),使用sambamba软件进行标记(markdup)。
分析结果
实施例1构建的文库的测序结果为10个index拆分的reads数的合集,具体见下表:
表35
由上表可见,各index间reads数分布偏好性低(各index所拆分的reads数相近),且无法列入index的reads数仅占总reads数的0.10%,说明实施例2的P7端带样本标签的indexing扩增系统可以精准地对多个样本进行混合靶标基因建库和测序。
突变检测结果如下:
表36
由上表可见,实施例2所构建文库的测序数据质量相对于其他两项技术所构建文库的测序结果更高,具体地,Q30比例更高,Q30代表正确率在99.9%的reads占总reads数的比例;且基于实施例2构建的文库所检测得到的靶标基因突变的频率(MAF:mutationallele frequency)更接近真实值,更接近0.05%的预设值。因此,本专利技术在对人类等复杂基因组的特定靶标基因做测序检测时的性能更优,且耗时更短(杂交捕获建库需72-80小时,扩增子建库需24-32小时,实施例2仅需9小时)。且其所需步骤少,所需各种实际和耗材少,因此成本低。各主要实验步骤之间无需纯化,不仅节省时间和物料,更避免了每一步纯化过程中的DNA损失,最大限度的保留了原始模板DNA。综上,实施例2的建库技术在临床检测、分子医学研究和基因组科学研究中具有更广泛的应用价值。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
SEQUENCE LISTING
<110> 深圳市睿法生物科技有限公司
<120> 一种高保真靶标基因建库方法及其试剂盒
<130> 20I30445
<160> 32
<170> PatentIn version 3.3
<210> 1
<211> 34
<212> DNA
<213> 人工序列
<400> 1
gtgactggag ttcagacgtg tgctcttccg atct 34
<210> 2
<211> 46
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (1)..(12)
<223> n is a, c, g, or t
<400> 2
nnnnnnnnnn nnagatcgga agagcacacg tctgaactcc agtcac 46
<210> 3
<211> 33
<212> DNA
<213> 人工序列
<400> 3
acactctttc cctacacgac gctcttccga tct 33
<210> 4
<211> 42
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (1)..(9)
<223> n is a, c, g, or t
<400> 4
nnnnnnnnna gatcggaaga gcgtcgtgta gggaaagagt gt 42
<210> 5
<211> 33
<212> DNA
<213> 人工序列
<400> 5
agatcggaag agcgtcgtgt agggaaagag tgt 33
<210> 6
<211> 60
<212> DNA
<213> 人工序列
<400> 6
caagcagaag acggcatacg agattgatag gtgactggag ttcagacgtg tgctcttccg 60
<210> 7
<211> 60
<212> DNA
<213> 人工序列
<400> 7
caagcagaag acggcatacg agattatacg gtgactggag ttcagacgtg tgctcttccg 60
<210> 8
<211> 60
<212> DNA
<213> 人工序列
<400> 8
caagcagaag acggcatacg agatcgatca gtgactggag ttcagacgtg tgctcttccg 60
<210> 9
<211> 60
<212> DNA
<213> 人工序列
<400> 9
caagcagaag acggcatacg agatatacac gtgactggag ttcagacgtg tgctcttccg 60
<210> 10
<211> 60
<212> DNA
<213> 人工序列
<400> 10
caagcagaag acggcatacg agatatagcg gtgactggag ttcagacgtg tgctcttccg 60
<210> 11
<211> 60
<212> DNA
<213> 人工序列
<400> 11
caagcagaag acggcatacg agattgttca gtgactggag ttcagacgtg tgctcttccg 60
<210> 12
<211> 60
<212> DNA
<213> 人工序列
<400> 12
caagcagaag acggcatacg agatagatac gtgactggag ttcagacgtg tgctcttccg 60
<210> 13
<211> 60
<212> DNA
<213> 人工序列
<400> 13
caagcagaag acggcatacg agattagctg gtgactggag ttcagacgtg tgctcttccg 60
<210> 14
<211> 60
<212> DNA
<213> 人工序列
<400> 14
caagcagaag acggcatacg agatgtatgt gtgactggag ttcagacgtg tgctcttccg 60
<210> 15
<211> 60
<212> DNA
<213> 人工序列
<400> 15
caagcagaag acggcatacg agatggctca gtgactggag ttcagacgtg tgctcttccg 60
<210> 16
<211> 51
<212> DNA
<213> 人工序列
<400> 16
aatgatacgg cgaccaccga gatctacact ctttccctac acgacgctct t 51
<210> 17
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 17
caaggacatc cgntgatttg tagtggagaa gga 33
<210> 18
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 18
caaggacatc cgntggcctg gcttgcttac ctt 33
<210> 19
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 19
caaggacatc cgngcatctg cctcacctcc acc 33
<210> 20
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 20
caaggacatc cgntccagga ggcagccgaa ggg 33
<210> 21
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 21
caaggacatc cgnggaaact gaattcaaaa aga 33
<210> 22
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 22
caaggacatc cgngacctta ccttatacac cgt 33
<210> 23
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 23
caaggacatc cgngaaataa atacagatct gtt 33
<210> 24
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 24
caaggacatc cgnaaaagga attccataac ttc 33
<210> 25
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 25
caaggacatc cgngacgata cagctaattc aga 33
<210> 26
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 26
caaggacatc cgnacaagtt tatattcagt cat 33
<210> 27
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 27
caaggacatc cgntgagaga ccaatacatg agg 33
<210> 28
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 28
caaggacatc cgntatgtcc aacaaacagg ttt 33
<210> 29
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 29
caaggacatc cgnagaaggt gagaaagtta aaa 33
<210> 30
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 30
caaggacatc cgntcacatc gaggatttcc ttg 33
<210> 31
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 31
caaggacatc cgnccctccc tccaggaagc cta 33
<210> 32
<211> 33
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is u
<400> 32
caaggacatc cgnaggcaga tgcccagcag gcg 33
- 一种高保真靶标基因建库方法及其试剂盒
- 一种Cas蛋白特异结合靶标DNA、调控靶标基因转录的方法及试剂盒