一种数据质量提升和增强的方法及装置
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于中医药实体抽取技术领域,尤其涉及一种数据质量提升和增强的方法及装置。
背景技术
深度学习是由大数据驱动发展的一个领域,目前所有的深度学习神经网络算法都会面临训练数据噪声问题。如果训练数据中噪声数据过多,就无法训练得到一个效果较好的深度学习算法,因此,高质量的数据已经成为AI和深度学习系统所必备的条件,一般会花费较多人力物力进行数据去噪。在中医药实体抽取领域,需要大量的高质量的原始语料来进行模型的抽取训练,一般需要的语料也是10w级别中医药实体,目前,通过训练自动标注模型的方式,但由于只简单训练一个分类模型,使模型的稳定性和精确度都不高,且直接应用模型预测的结果作为标签,没有进一步的处理,因此,使得数据质量不高,噪声数据多,严重影响了AI和深度学习的使用效果。
发明内容
为解决上述问题,本发明提供了一种数据质量提升和增强的方法及装置,通过获取模块获取待训练样本数据,将所述待训练样本数据进行部分标注标签、部分无标签处理,通过A策略预训练:将含标签的所述待训练样本数据均分成n份原始训练集;通过预训练,即通过输入模块将含标签的样本数据输入至深度学习网络模型中训练,分别获得n个实体抽取模型;使用n个所述实体抽取模型分别对无标签的所述待训练样本数据进行匹配预测,获取n份预测结果;通过B策略数据去噪:依据所述预测结果,通过判断模块判断出含标签的所述训练样本数据是否标注有误,对有误的样本数据删除或增补;通过实际环境再校验:即在实际环境中人工进行最终校验,通过校验结果进一步判断是否调整B策略去噪的参数。本发明有效减少了噪声数据,提高了数据质量,使实体抽取模型的稳定性和精确度大大提高,彻底解决了由于中医药实体名称庞大、复杂带来的数据噪声大,难以去除,严重影响了AI和深度学习的使用效果的技术难题。
为实现上述发明目的,本发明的技术方案是:
一种数据质量提升和增强的方法,包括如下步骤:
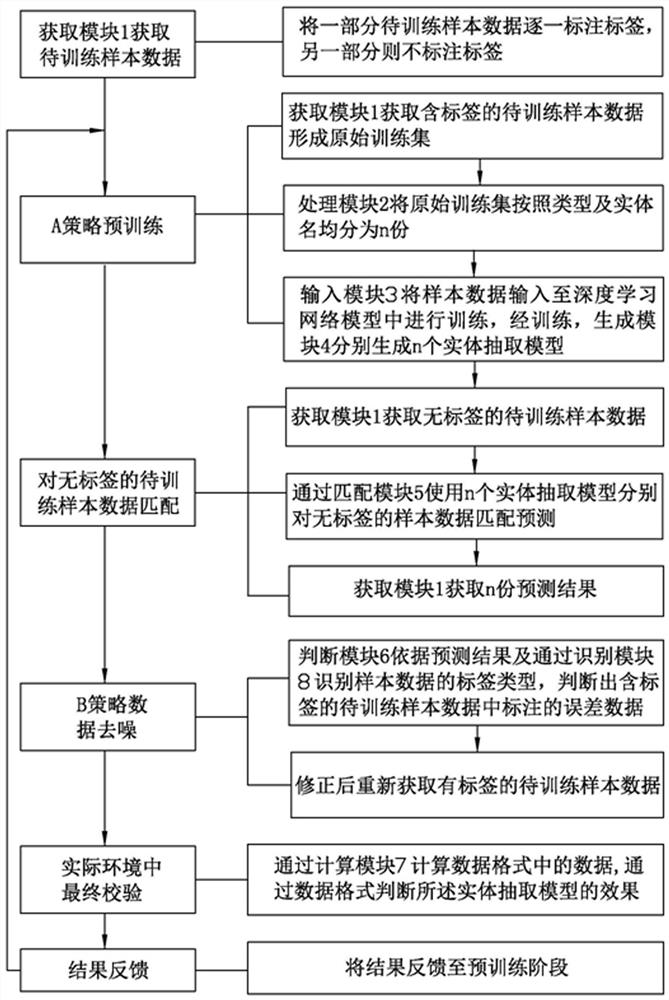
步骤1:获取待训练样本数据,将一部分所述待训练样本数据逐一标注标签,另一部分含相同数据成分的所述待训练样本数据不标注标签;
步骤2:A策略预训练:获取含标签的所述待训练样本数据形成原始训练集,将所述原始训练集均分为n份,并将样本数据输入至深度学习网络模型中进行训练,分别获得n个实体抽取模型;
步骤3:获取无标签的所述待训练样本数据,使用n个所述实体抽取模型分别对无标签的所述待训练样本数据进行匹配预测,获取n份预测结果;
步骤4:B策略数据去噪:依据所述预测结果,判断出含标签的所述待训练样本数据中标注的误差数据,修正后重新获取有标签的待训练样本数据;
步骤5:进行实际环境中最终校验:通过数据格式判断所述实体抽取模型的效果;
步骤6:将结果反馈至预训练阶段,以判断是否调整B策略去噪的参数。
在一些实施例中,步骤1进一步包括:所述样本数据包括中医药实体的类型数据、实体名数据及位置数据。
在一些实施例中,步骤2进一步包括:n份所述原始训练集中每份中的数据类型均相同。
在一些实施例中,步骤3进一步包括:n份所述预测结果中包括样本数据,所述样本数据与所述训练样本数据相同,或者不相同。
在一些实施例中,份数n为大于等于10的正整数。
在一些实施例中,步骤4进一步包括:若某个原始训练集中的第i个实体同时出现在n份所述预测结果中,但没有出现在原始训练集的标注中,则所述预测结果正确,原始训练集的标注有误,因此,将所述第i个实体的标签补充到该训练样本的标注中;若某个原始训练集中的第i个实体均没有出现在n份所述预测结果中,则所述预测结果正确,原始训练集的标注有误,将所述第i个实体的标签从该训练样本的标注中剔除。
在一些实施例中,步骤5进一步包括:所述数据格式为:
n=|n+(m-z)/a|
其中:n为原始训练集的份数;
a为超参数,设a=10
m为所有抽查实体正确次数之和;
z为所有抽查实体错误次数之和;
并把|n+(m-z)/a|四舍五入。
在一些实施例中,依据n判断,m值越大,则z值越小,数据质量越高,引导n值趋小;反之,m值越小,z值越大,数据质量越低,则引导n值趋大。
本发明还公开了一种数据质量提升和增强的装置,所述装置包括:
获取模块:分别获取有标签的待训练样本数据、无标签的待训练样本数据及训练的预测结果;
识别模块:用于识别样本数据的标签类型;
处理模块:将原始训练集按照类型及对应的实体名均分为n份;
输入模块:将待训练样本数据输入至深度学习网络模型中;
生成模块:生成n个实体抽取模型;
匹配模块:使实体抽取模型与无标签样本数据进行匹配;
判断模块:依据预测结果判断原始训练集中的样本数据的标签标注的正确性;
计算模块:计算数据格式中的数据。
本发明的有益效果是:本发明提供了一种数据质量提升和增强的方法及装置,通过获取模块获取待训练样本数据,将所述待训练样本数据进行部分标注标签、部分无标签处理,将含标签的所述待训练样本数据均分成n份原始训练集;通过预训练,即通过输入模块将含标签的样本数据输入至深度学习网络模型中训练,分别获得n个实体抽取模型,使用n个所述实体抽取模型分别对无标签的所述待训练样本数据进行匹配预测,获取n份预测结果;通过数据去噪:依据所述预测结果,通过判断模块判断出含标签的所述训练样本数据是否标注有误,对有误的样本数据删除或增补;通过实际环境再校验:即在实际环境中人工进行最终校验,通过校验结果进一步判断是否调整B策略去噪的参数。本发明有效减少了噪声数据,提高了数据质量,使实体抽取模型的稳定性和精确度大大提高,彻底解决了由于中医药实体名称庞大、复杂带来的数据噪声大,难以去除,严重影响了AI和深度学习的使用效果的技术难题。
附图说明
图1为本申请实施例提供的数据质量提升和增强的方法的一个可选的流程示意图;
其中:
1-获取模块; 2-处理模块;3-输入模块;4-生成模块;5-匹配模块;6-判断模块;7-计算模块;8-识别模块。
具体实施方式
为了使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请作进一步地详细描述,所描述的实施例不应视为对本申请的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。除非另有定义,本申请实施例所使用的所有的技术和科学术语与属于本申请实施例的技术领域的技术人员通常理解的含义相同。本申请实施例所使用的术语只是为了描述本申请实施例的目的,不是旨在限制本申请。
参照图1所示:
本发明实施例:
本发明公开了一种数据质量提升和增强的装置,所述装置包括:
获取模块1:分别获取有标签的待训练样本数据、无标签的待训练样本数据及训练的预测结果;
处理模块2:将原始训练集按照类型及对应的实体名均分为n份;
输入模块3:将待训练样本数据输入至深度学习网络模型中;
生成模块4:生成n个实体抽取模型;
匹配模块5:使实体抽取模型与无标签样本数据进行匹配;
判断模块6:依据预测结果判断原始训练集中的样本数据的标签标注的正确性;
计算模块7:计算数据格式中的数据;
识别模块8:用于识别样本数据的标签类型。
本发明提供一种数据质量提升和增强的方法,包括如下步骤:
步骤S101:获取模块1获取待训练样本数据,部分所述待训练样本数据逐一标注标签,另一部分含相同数据成分的所述待训练样本数据不标注标签;步骤S201:A策略预训练:获取模块1获取含标签的所述待训练样本数据形成原始训练集,处理模块2将原始训练集均分为n份,输入模块3将所有样本数据输入至深度学习网络模型中进行训练,通过生成模块4生成n个实体抽取模型;步骤S301:通过匹配模块5使n个所述实体抽取模型分别对无标签的所述待训练样本数据进行匹配预测,获取模块1获取n份预测结果;步骤S401:B策略数据去噪:判断模块6依据所述预测结果及通过识别模块8识别样本数据的标签类型,判断出含标签的所述待训练样本数据中标注的错误信息,修正原有标签的待训练样本数据;步骤S501:进行实际环境中最终校验;步骤S601:将结果反馈至预训练阶段,以判断是否调整B策略去噪的参数。
下面将结合本申请实施例的示例性应用和实施具体说明:
步骤S101:获取模块1获取待训练样本数据,一部分所述待训练样本数据逐一标注标签, 另一部分含相同数据成分的所述待训练样本数据不标注标签;
在一些实施例中,所述样本数据包括中医药实体的类型数据、实体名数据及位置数据;通过人工标注标签;
步骤S201:预训练:获取模块1获取含标签的所述待训练样本数据形成原始训练集,处理模块2将所述原始训练集按照类型及对应的实体名均分为n份,输入模块3将所有样本数据输入至深度学习网络模型中进行训练,分别获得n个实体抽取模型;
在一些实施例中,n=10,对10个实体抽取模型进行训练,每个实体抽取模型中的数据信息均相同。
例如:在中医药实体抽取时,六味地黄丸的数据信息包括:类型(药品)、实体名(六味地黄丸)、出现位置 [90,95]三部分,在n份原始训练集中上述针对六味地黄丸的三部分内容均应全部出现。
步骤S301:所述获取模块1获取无标签的所述待训练样本数据,通过匹配模块5使10个所述实体抽取模型分别对无标签的所述待训练样本数据进行匹配预测,获取模块1获取10份预测结果,如预测结果为a1~a10。
在一些实施例中,10份所述预测结果中包括样本数据,所述样本数据与所述原始训练集中的样本数据相同,或者不相同。
步骤S401:数据去噪:判断模块6依据所述预测结果,判断出含标签的所述待训练样本数据中标注的错误数据,修正后重新获取有标签的待训练样本数据;
在一些实施例中,若某个原始训练集中的第i个实体(如六味地黄丸)同时出现在a1~a10的10份所述预测结果中,但在所述原始训练集中没有标注出,则所述预测结果正确,将所述第i个实体(如六味地黄丸)的标签补充到原始训练集中;若某个原始训练集中的第i个实体(如六味地黄丸)没有出现在a1~a10的10份所述预测结果中,则所述预测结果错误,标注是错的,将所述第i个实体(如六味地黄丸)的标签从原始训练集的标注中剔除,即原始训练集中没有所述第i个实体(如六味地黄丸),属于误标。
步骤S501:进行实际环境中最终校验:
在实际环境中验证抽查,生成如下的数据格式。
通过计算模块7计算数据格式中的数据,判断所述实体抽取模型的效果;
在一些实施例中,所述数据格式为:
n=|n+(m-z)/a|
其中:n为原始训练集的份数;
a为超参数,设a=10
m为所有抽查实体正确次数之和;
z为所有抽查实体错误次数之和;
并把|n+(m-z)/a|进行四舍五入。
在一些实施例中,依据n判断,所述m值越大,则z值越大,数据质量越高,引导n值趋小;反之,所述m值越小,z值越大,数据质量越低,则引导n值趋大。
步骤S601:将结果反馈至预训练阶段,以判断是否调整B策略去噪的参数。
在一些实施例中,当n值足够大,实体抽取模型要求严格,噪音数据少,数据质量越高,会逐步减小n值;当n值不够大,噪音数据较多,实体抽取模型要求不太严格,会逐步增大n值,以满足AI和深度学习系统对数据的高质量需求。
上述说明示出并描述了本申请的若干优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述申请构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求的保护范围内。
- 一种数据质量提升和增强的方法及装置
- 一种基于数据相关性的电网数据质量提升方法