一种货车停靠点提取方法和出行特征确定方法、装置
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及交通运输统计技术领域,具体而言,涉及一种货车停靠点提取方法和出行特征确定方法、装置。
背景技术
城市物流是以城市为主体,围绕城市的需求所发生的物流活动。城市物流相对于国际物流、区域物流而言,城市物流的范围比较小,城市物流有非常明显的短程物流特征和短程物流派生的特征。国际物流、区域物流的始发点和最终目的地基本都是城市,因此在广泛区域运作的物流,最后都归结到城市之中,这是造成城市物流高密度的重要原因。另外,城市本身的产业高密度及人口高密度也带来了高密度的物流需求。因此,需要对城市物流的情况进行监管分析控制,以确保城市交通的有序进行。
传统的物流分析是通过交通调查方法进行支撑的,在进行物流分析时,调查数据不足以支撑精细化的物流运行特征。一般的,城市物流是以货车出行为主,以能反映货运运行特征的停靠点为例,现有的货车停靠点提取方法得到的停靠点数据不准确,因此,迫切需要一种能够得到较准确停靠点数据的提取方法,以得到较准确的分析数据,便于后续为交通管理者提供可靠的决策分析数据。
发明内容
本发明解决的问题是现有的货车停靠点提取方法得到的停靠点数据不准确。
为解决上述问题,本发明提供一种货车停靠点提取方法,包括:
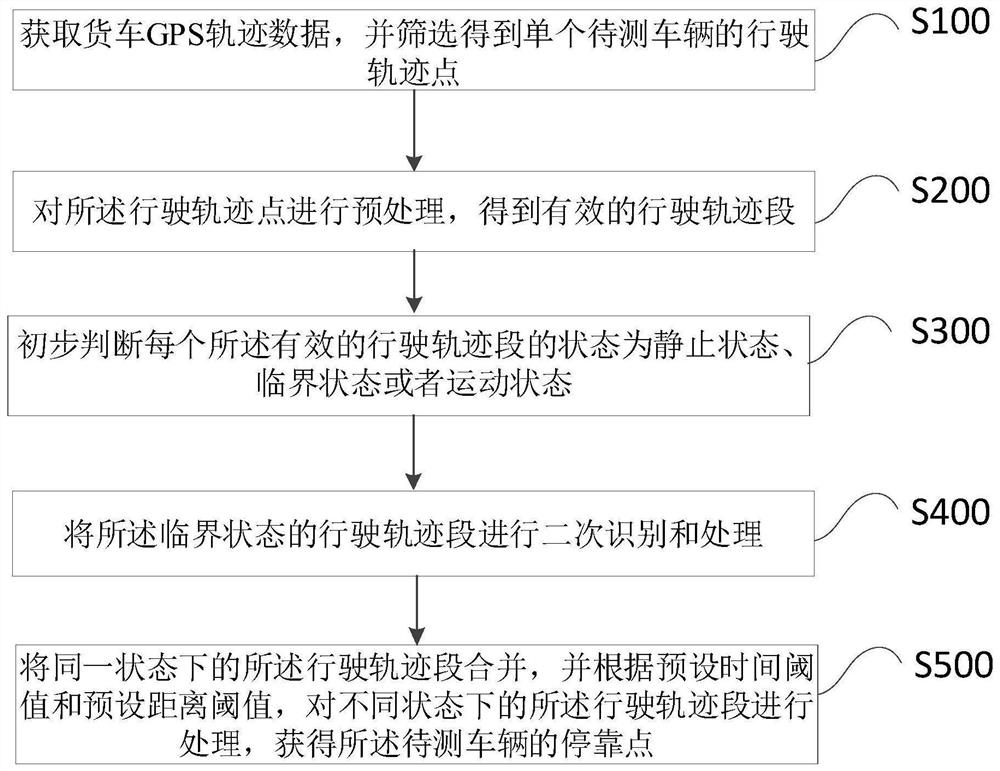
获取货车GPS轨迹数据,并筛选得到单个待测车辆的行驶轨迹点;
对所述行驶轨迹点进行预处理,得到有效的行驶轨迹段;
初步判断每个所述有效的行驶轨迹段的状态为静止状态、临界状态或者运动状态;
将所述临界状态的行驶轨迹段进行二次识别和处理;
将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点。
这样,通过货车GPS数据获取得到较全面的包括时间和空间维度的货运数据,接着对得到的原始数据进行处理,剔除异常数据,以提高数据质量,然后,对保留下来的数据进行多次识别处理,通过不断地优化识别结果,尽可能减小与实际场景的偏差,最后判别得到较准确的停靠点位置。其次,通过得到较准确的停靠点位置,进而可以较准确的反映货车活动特征,从而得到较准确的分析数据,便于后续为交通管理者提供可靠的决策分析数据。
可选地,所述对所述行驶轨迹点进行预处理,得到有效的行驶轨迹段,包括:
剔除瞬时速度异常的所述行驶轨迹点;
将剔除后的相邻的两个所述行驶轨迹点合并为一行驶轨迹段,计算每个所述行驶轨迹段的行驶距离和平均行驶速度;
将所述行驶距离小于距离阈值或所述平均行驶速度大于速度阈值的所述行驶轨迹段剔除,剩余的所述行驶轨迹段作为所述有效的行驶轨迹段。
这样,在第一次数据清洗的时候,通过将瞬时速度过大或者过小的异常值剔除,而在第二次数据清洗的时候,将行驶距离以及平均行驶速度异常的行驶轨迹段剔除,通过两次对异常数据的清洗剔除,大大减小了异常数据的影响,提高了计算结果的精度,同时减少了数据的计算量。
可选地,所述将所述临界状态的行驶轨迹段进行二次识别和处理中,将所述临界状态识别为与上一个所述行驶轨迹段同一状态。
这样,根据临界状态的前一状态进行“状态的延续”,将所述临界状态识别为与上一个所述行驶轨迹段同一状态,这样与真实的车辆状态更加接近,获得的判断结果更准确。
可选地,所述将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点,包括:
将连续的所述静止状态下的行驶轨迹段合并得到多个候选停靠段,将连续的所述运动状态下的行驶轨迹段合并得到多个移动段;
根据所述预设时间阈值和所述预设距离阈值,判断所述候选停靠段和所述移动段是否满足预设条件,若满足所述预设条件,则将当前候选停靠段对应的位置确定为所述待测车辆的停靠点。
这样,首先使用简单的速度判别准则,将轨迹初步分为停留/移动类型子轨迹,并根据有意义的停留与移动在持续时间、跨越距离上的限制,动态更新子轨迹的停留/移动标签,并通过逐级合并相同类型相邻的子轨迹来优化识别结果。防止运动状态的判别有误,实现动态更新,从而得到更准确的状态识别。
可选地,所述预设条件为当前所述候选停靠段的累计时间大于所述预设时间阈值,且当前移动段的累计距离大于所述预设距离阈值。
这样,通过将当前所述候选停靠段的累计时间大于预设时间阈值,且当前移动段的累计距离大于预设距离阈值,根据有意义的停留与移动在持续时间、跨越距离上的限制,从而得到更准确的停靠点位置。
其次,提供一种货车停靠点提取装置,包括:
获取单元,其用于获取货车GPS轨迹数据,并筛选得到单个待测车辆的行驶轨迹点;
预处理单元,其用于对所述行驶轨迹点进行预处理,得到有效的行驶轨迹段;
第一识别单元,其用于初步判断每个所述有效的行驶轨迹段的状态为静止状态、临界状态或者运动状态;
第二识别单元,其用于将所述临界状态的行驶轨迹段进行二次识别和处理;
第三识别单元,其用于将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点。
这样,通过货车GPS数据获取得到较全面的包括时间和空间维度的货运数据,接着对得到的原始数据进行处理,剔除异常数据,以提高数据质量,然后,对保留下来的数据进行多次识别处理,通过不断地优化识别结果,尽可能减小与实际场景的偏差,最后判别得到较准确的停靠点位置。其次,通过得到较准确的停靠点位置,进而可以较准确的反映货车活动特征,从而得到较准确的分析数据,便于后续为交通管理者提供可靠的决策分析数据。
再次,提供一种出行特征确定方法,包括:
获取货车GPS数据,并从中提取不同货车的出行OD,形成出行OD表;
根据所述货车GPS数据,提取所述不同货车的停靠点,并更新所述出行OD表,其中,所述停靠点通过如上述所述货车停靠点提取方法获得;
对所述货车GPS数据进行地图匹配和最优匹配路段选择处理,得到GPS轨迹数据;
根据更新后的所述出行OD表和所述GPS轨迹数据提取车辆轨迹,并对所述车辆轨迹进行处理和指标计算,确定出行特征。
这样,基于GPS数据的物流运行特征分析,可以更好的帮助交通管理者精确掌握货运的运行规律,推演城市内部物流的演变发现,为相关政策的实施提供可靠支撑。
从次,提供一种出行特征确定装置,包括:
第一提取单元,其用于获取货车GPS数据,并从中提取不同货车的出行OD,形成出行OD表;
第二提取单元,其用于根据所述货车GPS数据,提取所述不同货车的停靠点,并更新所述出行OD表,其中,所述停靠点通过如上述所述货车停靠点提取方法获得;
匹配单元,其用于对所述货车GPS数据进行地图匹配和最优匹配路段选择处理,得到GPS轨迹数据;
确定单元,其用于根据更新后的所述出行OD表和所述GPS轨迹数据提取车辆轨迹,并对所述车辆轨迹进行处理和指标计算,确定出行特征。
这样,基于GPS数据的物流运行特征分析,可以更好的帮助交通管理者精确掌握货运的运行规律,推演城市内部物流的演变发现,为相关政策的实施提供可靠支撑。
再次,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器读取并运行时,实现如上述所述货车停靠点提取方法或者实现如上述所述的出行特征确定方法。
本发明计算机可读存储介质相对于现有技术所具有的有益效果与上述货车停靠点提取方法或者出行特征确定方法一致,在此不予赘述。
最后,提供一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机可读指令,所述处理器执行所述计算机可读指令时实现如上述所述货车停靠点提取方法或者实现上述所述的出行特征确定方法。
本发明终端设备相对于现有技术所具有的有益效果与上述货车停靠点提取方法或者出行特征确定方法一致,在此不予赘述。
附图说明
图1为本发明一实施例货车停靠点提取方法流程示意图;
图2为本发明另一实施例货车停靠点提取方法流程示意图;
图3为本发明再一实施例货车停靠点提取方法流程示意图;
图4为本发明一实施例货车停靠点提取装置结构示意图;
图5为本发明一实施例出行特征确定方法流程示意图;
图6为本发明一实施例出行特征确定装置结构示意图。
附图标记说明:
10-获取单元;20-预处理单元;30-第一识别单元;40-第二识别单元;50-第三识别单元;60-第一提取单元;70-第二提取单元;80-匹配单元;90-确定单元。
具体实施方式
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。
城市物流是以城市为主体,围绕城市的需求所发生的物流活动。城市物流相对于国际物流、区域物流而言,城市物流的范围比较小。城市物流的主要特点,是城市主体的一元化,所有的城市都有统一的政府行政组织,城市行政组织可以统筹和管理物流,因此,城市物流有非常强的可控性。受城市范围的制约,城市物流的短程性非常突出,再大的城市,城市的最大直径无非在百多公里,城市中心物流密度最大的部位,还要远远低于这个数字。因此,城市物流有非常明显的短程物流特征和短程物流派生的特征。国际物流、区域物流的始发点和最终目的地基本都是城市,因此在广泛区域运作的物流,最后都归结到城市之中,这是造成城市物流高密度的重要原因。另外,城市本身的产业高密度及人口高密度也带来了高密度的物流需求。
传统的物流分析是通过交通调查方法进行支撑的,在进行物流分析时,调查数据不足以支撑精细化的物流运行特征。一般的,城市物流是以货车出行为主,以能反映货运运行特征的停靠点为例,现有的货车停靠点提取方法得到的停靠点数据不准确,因此,迫切需要一种能够得到较准确停靠点数据的提取方法,以得到较准确的分析数据,便于后续为交通管理者提供可靠的决策分析数据。
针对上述情况,本发明基于GPS数据的物流运行特征分析,通过货车GPS轨迹数据获取全时间和空间维度的货运交通数据,通过获取具体的车辆时空信息,从而处理得到较准确停靠点数据。
具体地,参见图1,图1为本发明一实施例货车停靠点提取方法流程示意图。本申请公开了一种货车停靠点提取方法,包括:
S100,获取货车GPS轨迹数据,并筛选得到单个待测车辆的行驶轨迹点。
其中,针对海量的GPS数据,里面包含了多辆车辆的数据。在获取得到的GPS数据中包含车辆唯一ID信息,在进行筛选以得到单个待测车辆的数据时,对原始数据针对ID进行数据去重,得到唯一车辆ID的序列数据,从而得到单个待测车辆的行驶轨迹点。从原始数据中筛选得到单个车辆的数据之后,按照数据定位时间对行驶轨迹点进行排序。另外,GPS数据还包括时间信息、经度信息和纬度信息等数据。
S200,对所述行驶轨迹点进行预处理,得到有效的行驶轨迹段。
其中,对行驶轨迹点进行预处理指的是将原始数据的异常点进行剔除,留下非异常的行驶轨迹点,接着将相邻的行驶轨迹点进行合并形成行驶轨迹段,然后将距离较短或平均速度过大的异常轨迹段进行剔除处理。这样,通过两次剔除处理,减少GPS数据噪声的影响,提高数据的质量,以减少对后续数据特征计算的影响,从而得到有效的行驶轨迹段。
S300,初步判断每个所述有效的行驶轨迹段的状态为静止状态、临界状态或者运动状态。
初步判断每个行驶轨迹段的状态,其中行驶轨迹段的状态包括静止状态、临界状态和运动状态,判断每个行驶轨迹段分别属于这三个状态中的哪个状态。
其中,运动状态的判定条件是平均行驶速度大于速度阈值vmin(明显的运动状态的速度最小值),静止状态的判定条件是速度小于速度阈值vmax(明显的静止状态的速度最大值),临界状态是速度介于速度阈值vmin和vmax之间。
速度阈值vmin(明显的运动状态的速度最小值)推荐采用2.5m/s(9km/h),是根据手动挡汽车1挡起步的速度而设定;速度阈值vmax(明显的静止状态的速度最大值)推荐使用0.25m/s,是根据车辆GPS定位精度为10m,一个采样间隔(40s)内的GPS信号漂移速度而设定的。然后将初步识别的结果进行连续状态的归并,完成运动状态的初始判定。
例如,假如A1-A2、A2-A3、A3-A4、A4-A5、A5-A6、A6-A7、A7-A8均为有效的行驶轨迹,A1-A2、A2-A3、A3-A4、A4-A5、A5-A6、A6-A7、A7-A8它们的平均速度分别为3m/s、4m/s、1m/s、2m/s、2.5m/s、0.1m/s、0.2m/s,根据速度阈值的判断,从而得到A1-A2,A2-A3为运动状态,A3-A4、A4-A5、A5-A6均为临界状态,A6-A7、A7-A8为静止状态。
S400,将所述临界状态的行驶轨迹段进行二次识别和处理;
进行二次状态识别时,完成对于临界状态的识别和处理。根据临界状态的前一状态进行“状态的延续”。由于状态为临界状态的轨迹段的运动特点是持续低速,对应的真实车辆状态可能是在减速停车或者是低速起步,其都与前一状态较为接近,因此可以作为临界状态判定的标准,即将所述临界状态识别为与上一个所述行驶轨迹段同一状态。
还是以A1-A2、A2-A3、A3-A4、A4-A5、A5-A6、A6-A7、A7-A8均为有效的行驶轨迹为例,根据速度阈值的判断,得到A1-A2、A2-A3为运动状态,A3-A4、A4-A5、A5-A6均为临界状态,A6-A7、A7-A8为静止状态之后,接着进一步判断临界状态对应的行驶轨迹段具体对应为运动状态还是静止状态,接下来就判断临界状态的A3-A4、A4-A5、A5-A6具体为什么状态,由于A3-A4的上一状态A2-A3为运动状态,所以A3-A4为运动状态,又因为A3-A4为运动状态,所以A4-A5为运动状态,同样的A4-A5为运动状态,所以A5-A6也为运动状态。
S500,将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点。将经过预处理后保留的行驶轨迹段进行多次状态识别并进行处理,具体地,首先,根据每个行驶轨迹段的平均速度初步识别每个行驶轨迹段的状态,所述行驶轨迹段的状态包括三种状态,分别为运动状态、临界状态和静止状态。在初步判断得到每个行驶轨迹段的状态之后,对判断为临界状态的行驶轨迹段进一步识别判断该行驶轨迹段具体划分为运动状态还是静止状态。在每个行驶轨迹段的具体状态都确定的情况下,根据预设时间阈值和预设距离阈值,进一步判断哪些轨迹段对应的是停靠点的位置,从而得到待测车辆的停靠点。其中,货车的停靠点包含一段轨迹中,中途停车进行装/卸货等货运活动的点,筛选出这些停靠点,可以帮助识别进行频繁货运活动的货运场站。
这样,通过货车GPS数据获取得到较全面的包括时间和空间维度的货运数据,接着对得到的原始数据进行处理,剔除异常数据,以提高数据质量,然后,对保留下来的数据进行多次识别处理,通过不断地优化识别结果,尽可能减小与实际场景的偏差,最后判别得到较准确的停靠点位置。其次,通过得到较准确的停靠点位置,进而可以较准确的反映货车活动特征,从而得到较准确的分析数据,便于后续为交通管理者提供可靠的决策分析数据。
可选地,需要说明的是,在获取得到货车的GPS数据时,可以得到初始的OD,其中,OD代表的是货车的起终点。由于初始得到的OD可能会在经过数据清洗、处理后,被剔除掉,这样一来,初始的OD就不准确,OD就需要进行更新。在通过货车停靠点提取方法确认了停靠点之后,在得到完整真实无误的轨迹后,该轨迹的起终点就是OD,从而得到更新的OD。而在获得OD之后,可以根据数据的特征去判断它从事哪种货运活动。
另外,对于OD和停靠点之间的关系满足,一段轨迹中的OD,可能存在很多停靠点,而在一个停靠点位置中的两个数据点之间的距离很短,说明货车在场站内进行了短时移动,可能是在从事装卸货运活动。
参见图2,图2为本发明另一实施例货车停靠点提取方法流程示意图。可选地,所述S200,对所述行驶轨迹点进行预处理,得到有效的行驶轨迹段,包括:
S210,剔除瞬时速度异常的所述行驶轨迹点。
其中,对行驶轨迹点进行预处理首先是剔除瞬时速度异常的轨迹点,原始数据中有各个回传点的瞬时速度,通过设置一个阈值,对于小于或大于阈值的瞬时速度剔除掉。若不剔除异常的数据点会影响后续的特征计算,导致结果精度很低,通过剔除异常的数据点,提高数据的质量。
例如,以A1-A5,5个轨迹点为例,假如A1-A5是一辆货车的数据轨迹点,首先剔除瞬时速度异常的轨迹点,假如A1-A5的瞬时速度分别为0.1m/s、5m/s、6m/s、9m/s、40m/s,例如将瞬时速度过大过小的都剔除掉,若瞬时速度在5m/s-10m/s的范围内时则认为是正常的瞬时速度,因此在剔除瞬时速度异常的轨迹点时就是将A1、A5剔除,剩下A2、A3、A4。需要说明的是,对于瞬时速度的取值以及轨迹点选取只是为了进行举例说明,不代表在实际数据就是如此设计。
S220,将剔除后的相邻的两个所述行驶轨迹点合并为一行驶轨迹段,计算每个所述行驶轨迹段的行驶距离和平均行驶速度;
还是以上面的例子为例,在剔除瞬时速度异常的轨迹点之后,剩下A2、A3、A4这三个轨迹点,接着将相邻的行驶轨迹点合并为行驶轨迹段,则得到A2-A3、A3-A4这两个轨迹段,接着计算A2-A3、A3-A4之间的平均速度和行驶距离。
需要说明的是,A1和A2、A2和A3、A3和A4,A4和A5这些相邻两个点之间的平均速度是不一致的,虽然数据上传的间隔一致,但实际中,对于不同时刻每个点位的行驶状态不一致,由于受到路况、其他车辆、红绿灯、限速等一些因素的影响,A1和A2、A2和A3之间的形式距离不对等,因此两个连续点之间的平均速度也不一致。
S230,将所述行驶距离小于距离阈值或所述平均行驶速度大于速度阈值的所述行驶轨迹段剔除,剩余的所述行驶轨迹段作为所述有效的行驶轨迹段。
进行第二次剔除异常数据的操作,还是以上面的例子为例,假设A2-A3的平均速度为0.2m/s,A3-A4之间的平均速度为5m/s,此时又剔除平均行驶速度比较小的0.2m/s的,在算平均行驶速度后,数据由“数据点”合成了“数据条”,A2-A3异常,则剔除A2-A3这条数据,保留A3-A4这条数据。
需要说明的是,剔除完瞬时速度异常后,轨迹点合并成轨迹段,此时计算平均速度才有意义。其中,轨迹段包括两个轨迹点组成。在计算相邻两个点的平均行驶速度和行驶距离时,此时相邻的两个数据点合并成为一条数据,例如第一条数据是A2-A3,第二条数据是A3-A4;同样,设置一个速度和距离的阈值,剔除小于和大于阈值的异常数据。
这样,在第一次数据清洗的时候,通过将瞬时速度过大或者过小的异常值剔除,而在第二次数据清洗的时候,将行驶距离以及平均行驶速度异常的行驶轨迹段剔除,通过两次对异常数据的清洗剔除,大大减小了异常数据的影响,提高了计算结果的精度,同时减少了数据的计算量。
可选地,将两个相邻的GPS数据采样点视为整个行驶轨迹中的一个有限的轨迹元(也称为轨迹段),根据经纬度信息,计算两个相邻采样点之间的直线行驶距离和平均行驶速度,可以通过以下公式计算轨迹元的平均行驶速度v。
其中,v是轨迹元的平均行驶速度,l是轨迹元的起点s与终点e之间的直线行驶距离;t指轨迹元中GPS点的定位时间,其中行驶距离采用相邻采样点的经纬度坐标,平均行驶速度即为行驶距离除以相邻采样点的时间差。
基于行驶平均速度计算结果对异常噪声进行清洗。主要包括采样时间间隔过短、平均行驶速度过大这两类异常情况,清洗的手段是直接删除异常数据,保证数据的有效性。其中采样时间间隔的阈值拟选用5s,速度阈值拟选用38m/s(高速公路的最高行驶速度为140km/h)。
可选地,所述S400,将所述临界状态的行驶轨迹段进行二次识别和处理中,将所述临界状态识别为与上一个所述行驶轨迹段同一状态。
这样,根据临界状态的前一状态进行“状态的延续”,将所述临界状态识别为与上一个所述行驶轨迹段同一状态。由于状态为临界状态的轨迹段的运动特点是持续低速,对应的真实车辆状态可能是在减速停车或者是低速起步,其都与前一状态较为接近,因此可以作为临界状态判定的标准,即将所述临界状态识别为与上一个所述行驶轨迹段同一状态。这样使得与真实的车辆状态更加接近,获得的判断结果更准确。
参见图3,图3为本发明再一实施例货车停靠点提取方法流程示意图。可选地,所述S500,将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点,包括:
S510,将连续的所述静止状态下的行驶轨迹段合并得到多个候选停靠段,将连续的所述运动状态下的行驶轨迹段合并得到多个移动段。
将连续的所述静止状态下的行驶轨迹段进行合并,所谓的连续的所述静止状态指的是当前行驶轨迹段的状态为静止状态,与当前行驶轨迹段相邻的行驶轨迹段的状态也为静止状态,这样则认为是连续。若当前行驶轨迹段为静止状态,下一行驶轨迹段为运动状态,下下一行驶轨迹段为静止状态,则当前行驶轨迹段与下下一行驶轨迹段为不连续的,则这样的同一静止状态下的行驶轨迹段不进行合并。这样,将连续的所述静止状态下的行驶轨迹段可以合并得到多个候选停靠段。同样地,对于运动状态下的行驶轨迹段合并也是同样的道理。
S520,根据预设时间阈值和预设距离阈值,判断所述候选停靠段和所述移动段是否满足预设条件,若满足预设条件,则将当前候选停靠段对应的位置确定为所述待测车辆的停靠点。
停靠点为一段轨迹中,中途停车进行装/卸货等货运活动的点,也就是上下货的点。根据其普遍的上下货这个事件的时空特征,通常表现为上下货的时间较长,两次上下货之间的持续行驶距离较远。根据预设时间阈值,其时间是相较于一般性停车的时间要更长,因此根据经验,推荐选用900s(15min)时间来作为上下货点识别的标准,大于该阈值的停车点被定义为上下货点。
同时根据预设距离阈值,其两次停车之间的行驶距离相较于一般要更远,因此根据经验,推荐选用1500m来作为上下货点识别的标准,大于该阈值的停车点被定义为上下货点。由于通常的货运距离和时间是较为持续的,因此持续距离过短的行驶状态将动态更新为停车状态,实现了客货运车辆的上下货点的识别。
例如,假设A1-A2、A2-A3、A3-A4、A4-A5、A5-A6为运动状态,A6-A7,A7-A8为静止状态,A8-A9、A9-A10、A10-A11为运动状态,A11-A12、A12-A13为静止状态。将同一状态下的连续行驶轨迹段进行合并,得到A1-A6为第一移动段,A6-A8为第一候选停靠段,A8-A11为第二移动段;A11-A13为第二候选停靠段,如果第一候选停靠段的时间例如为16min,第二候选停靠段的时间有17min,且第一移动段的距离有1550m,则第一候选停靠段认为是一个停靠点,第二候选停靠段也为一个停靠点。
这样,首先使用简单的速度判别准则,将轨迹初步分为停留/移动类型子轨迹,并根据有意义的停留与移动在持续时间、跨越距离上的限制,动态更新子轨迹的停留/移动标签,并通过逐级合并相同类型相邻的子轨迹来优化识别结果,防止运动状态的判别有误,实现动态更新,从而得到更准确的状态识别。
可选地,所述预设条件为当前所述候选停靠段的累计时间大于预设时间阈值,且当前移动段的累计距离大于预设距离阈值。
这样,通过将当前所述候选停靠段的累计时间大于预设时间阈值,且当前移动段的累计距离大于预设距离阈值,根据有意义的停留与移动在持续时间、跨越距离上的限制,从而得到更准确的停靠点位置。
可选地,将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点中,从所述静止状态的行驶轨迹段中,提取满足预设状态的行驶轨迹段确定为所述停靠点的位置。
这样,从静止状态的行驶轨迹段中确定得到停靠点的位置,根据不同含义的静止点时空特征,对于静止点的状态有效性进行判定,提取出来具有不同含义的静止点从而实现状态的更新,得到可靠的停靠点位置。
可选地,一车辆对应唯一的ID,从GPS轨迹数据筛选得到单个待测车辆的行驶轨迹点之后,按照时间进行排序,剔除掉没用的数据点后就得到了真实有用的完整轨迹。即在经过数据预处理以及运动状态识别后得到的完整真实的轨迹后,就可以知道该段轨迹的OD和停靠点。一个车辆的轨迹就是一对OD,n多轨迹组成就是n个OD对,组成OD表。
可选地,在得到停靠点之后,计算静止状态下GPS数据的经纬度平均值作为停留点位置,计算OD对的时间差作为停留时长。通过计算得到停留时间的长短,为后续交通管理者提供可靠的决策分析数据。例如,一个货运区域停留的时间比较长,且停留货车比较多,可能货运厂站需求会比较大,通过长期的跟踪通过特征的判断,就会向相关的管理部门提供依据,来确定这个区域是否要扩容,或者需要重点监管。另外,对于货车的监管是比较严格的,这个范围内货车运行比较多,时间比较长,那么它就有可能对周围的交通有影响,那么就会有货运的相关政策,以深圳地区的为例,深圳的道路白天是进货的,货运是不能通行的,只有在晚上的7点到10点之后才能通行,模型得到停留点时间,从而为政策提供数据基础。
参见图4,图4为本发明一实施例货车停靠点提取装置结构示意图。本发明还提供一种货车停靠点提取装置,包括:
获取单元10,其用于获取货车GPS轨迹数据,并筛选得到单个待测车辆的行驶轨迹点;
预处理单元20,其用于对所述行驶轨迹点进行预处理,得到有效的行驶轨迹段;
第一识别单元30,其用于初步判断每个所述有效的行驶轨迹段的状态为静止状态、临界状态或者运动状态;
第二识别单元40,其用于将所述临界状态的行驶轨迹段进行二次识别和处理;
第三识别单元50,其用于将同一状态下的所述行驶轨迹段合并,并根据预设时间阈值和预设距离阈值,对不同状态下的所述行驶轨迹段进行处理,获得所述待测车辆的停靠点。
这样,通过货车GPS数据获取得到较全面的包括时间和空间维度的货运数据,接着对得到的原始数据进行处理,剔除异常数据,以提高数据质量,然后,对保留下来的数据进行多次识别处理,通过不断地优化识别结果,尽可能减小与实际场景的偏差,最后判别得到较准确的停靠点位置。其次,通过得到较准确的停靠点位置,进而可以较准确的反映货车活动特征,从而得到较准确的分析数据,便于后续为交通管理者提供可靠的决策分析数据。
进一步地,所述预处理单元20还用于剔除瞬时速度异常的所述行驶轨迹点,将剔除后的相邻的两个所述行驶轨迹点合并为一行驶轨迹段,计算每个所述行驶轨迹段的行驶距离和平均行驶速度,将所述行驶距离小于距离阈值或所述平均行驶速度大于速度阈值的所述行驶轨迹段剔除,剩余的所述行驶轨迹段作为所述有效的行驶轨迹段。
进一步地,所述第二识别单元40中将所述临界状态识别为与上一个所述行驶轨迹段同一状态。
进一步地,所述第三识别单元50还用于将连续的所述静止状态下的行驶轨迹段合并得到多个候选停靠段,将连续的所述运动状态下的行驶轨迹段合并得到多个移动段;根据预设时间阈值和预设距离阈值,判断所述候选停靠段和所述移动段是否满足预设条件,若满足预设条件,则将当前候选停靠段对应的位置确定为所述待测车辆的停靠点。
进一步地,所述第三识别单元50中所述预设条件为当前所述候选停靠段的累计时间大于预设时间阈值,且当前移动段的累计距离大于预设距离阈值。
参见图5,图5为本发明一实施例出行特征确定方法流程示意图。本发明还提供一种出行特征确定方法,包括:
S10,获取货车GPS数据,并从中提取不同货车的出行OD,形成出行OD表;
S20,根据所述货车GPS数据,提取所述不同货车的停靠点,并更新所述出行OD表,其中,所述停靠点通过如上述所述货车停靠点提取方法获得;
S30,对所述货车GPS数据进行地图匹配和最优匹配路段选择处理,得到GPS轨迹数据。
通过空间匹配技术将GPS数据与路网路段进行匹配绑定,并基于匹配结果数据提取货车行驶轨迹。
S40,根据更新后的所述出行OD表和所述GPS轨迹数据提取车辆轨迹,并对所述车辆轨迹进行处理和指标计算,确定出行特征。
利用货车匹配数据和OD对计算货运量、OD量、出行时长、通道流量等特征指标,从货运需求、运行特征和货运重点区域角度分析城市货车活动特点
传统的物流分析是通过交通调查方法进行支撑的,调查方案得到的数据没有具体的车辆时空信息,因此在用于物流分析时,调查数据不足以支撑精细化的物流运行特征,因此无法为交通管理者提供可靠的决策分析依据。相对于传统的物流分析方法,本申请提供了基于GPS数据的物流运行特征分析,可以更好的帮助交通管理者精确掌握货运的运行规律,推演城市内部物流的演变发现,为相关政策的实施提供可靠支撑。
另外,本发明的货车GPS数据相较于出租车GPS、公交车GPS数据存在不同,其中,货运GPS数据包含车辆所属企业信息,帮助追踪车辆的源头。
可选地,本发明提出了通过基于货车GPS数据的城市内部物流在线推演技术,基于货车GPS数据对货车出行特征进行分析。具体为,首先通过空间匹配技术将GPS数据与路网路段进行匹配绑定,并基于匹配结果数据提取货车行驶轨迹。其次,通过识别货车停留点提取货车多次出行的OD对,通过聚类识别货车集散区域点。最后利用货车匹配数据和OD对计算货运量、OD量、出行时长、通道流量等特征指标,从货运需求、运行特征和货运重点区域角度分析某一城市的货车活动特点。
可选地,地图匹配采用分层空间索引的方法,首先通过对路网文件的格网化处理,形成深圳市域范围内的多个格网的范围数据并建立格网索引值,利用GPS点经纬度计算点所在格网的索引完成格网层面的地图匹配。然后计算GPS点与格网包含路段的距离,选择距离最小路段作为候选匹配路段。当路网规模达到一定程度时,直接对点和所有路段进行距离计算进行匹配的速度较慢,而空间索引技术可提高空间匹配的速度,只需利用GPS点的经纬度进行简单逻辑计算即可获取GPS点的所在格网的索引值,然后只需要与格网所包含的少量路段进行距离计算匹配,可大大提高地图匹配的速度。
可选地,基于OD点提取车辆轨迹后需要对车辆轨迹进行处理,包括删除重复路段、对轨迹不连续路段进行补全两方面,具体的,当GPS数据回传时间间隔较低时,车辆可能会在同一路段产生多个GPS记录,在路径中该路段ID会连续出现多次。因此在路径序列中对于重复路段则只需要保留其中之一,保证后续行驶距离计算正确;当GPS数据回传时间间隔较高时,车辆相邻两个GPS记录在空间上的距离较大,导致路径中前后路段并非相邻且连续的两个路段,因此需要对路径中非连续部分进行处理,当前使用最短路算法对非连续路段进行补全处理。
可选地,根据车辆GPS行驶路段和时间标签,可获取车辆出行途经的路段序列信息,并计算车辆行驶距离和行程速度。基于轨迹提取结果后续可用于进行路段流量统计、出行需求分析、OD分布分析和出行特征分析等方面。
其中,出行特征例如以交通发生量、OD交通量、通道流量为例。交通发生量是指在一定时间范围内出行起点的交通出发总量或出行讫点的到达总量,用
OD交通量分布
通道流量
参见图6,图6为本发明一实施例出行特征确定装置结构示意图,本发明还提供一种出行特征确定装置,包括:
第一提取单元60,其用于获取货车GPS数据,并从中提取不同货车的出行OD,形成出行OD表;
第二提取单元70,其用于根据所述货车GPS数据,提取所述不同货车的停靠点,并更新所述出行OD表,其中,所述停靠点通过如上述所述货车停靠点提取方法获得;
匹配单元80,其用于对所述货车GPS数据进行地图匹配和最优匹配路段选择处理,得到GPS轨迹数据;
确定单元90,其用于根据更新后的所述出行OD表和所述GPS轨迹数据提取车辆轨迹,并对所述车辆轨迹进行处理和指标计算,确定出行特征。
这样,基于GPS数据的物流运行特征分析,可以更好的帮助交通管理者精确掌握货运的运行规律,推演城市内部物流的演变发现,为相关政策的实施提供可靠支撑。
再次,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器读取并运行时,实现如上述所述货车停靠点提取方法或者实现如上述所述的出行特征确定方法。
本发明计算机可读存储介质相对于现有技术所具有的有益效果与上述货车停靠点提取方法或者出行特征确定方法一致,在此不予赘述。
最后,提供一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机可读指令,其特征在于,所述处理器执行所述计算机可读指令时实现如上述所述货车停靠点提取方法或者实现上述所述的出行特征确定方法。
本发明终端设备相对于现有技术所具有的有益效果与上述货车停靠点提取方法或者出行特征确定方法一致,在此不予赘述。
虽然本公开披露如上,但本公开的保护范围并非仅限于此。本领域技术人员在不脱离本公开的精神和范围的前提下,可进行各种变更与修改,这些变更与修改均将落入本发明的保护范围。
- 一种货车停靠点提取方法和出行特征确定方法、装置
- 一种车辆停靠点信息的确定方法及装置