内容缓存方法及装置
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及通信领域,尤其涉及一种内容缓存方法及装置。
背景技术
多接入边缘云(multi-access edge-cloud,MEC)是在靠近人、物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的开放平台,就近提供边缘计算服务,满足行业数字化在敏捷联接、实时业务、数据优化、安全与隐私保护等方面的关键需求。边缘计算或边缘云技术已经成为5G所支持的重要技术之一,3GPP已经明确将5G核心网支持边缘计算写入标准23.501。
现有技术中,边缘服务节点一般缓存第三方内容提供商或者运营商所提供的高热度的内容。这就导致不同区域的边缘服务节点缓存相同或相似的内容。但是,不同区域的用户可能有不同的需求,这就导致边缘服务节点所缓存的内容可能不能满足边缘服务节点所服务用户的需求。在边缘服务节点不能满足其所服务的区域内的用户的需求的情况下,边缘服务节点所服务的区域内的用户需要向应用服务器请求内容,增加用户获取到内容的时间。
发明内容
本发明提供一种内容缓存方法及装置,用于使得边缘服务节点能够缓存其服务的区域内的大多数用户所喜欢的内容,以提高边缘服务节点向其服务的区域内的用户提供内容的概率。
第一方面,提供一种内容缓存方法,该方法包括:边缘服务节点根据预先训练好的用户分类模型,对所述Q个用户进行分类,生成P个用户集合,所述P个用户集合与P个类型一一对应,所述用户集合包括所述Q个用户中的一个或多个用户,所述用户集合中的用户对应的类型与所述用户集合对应的类型是相同的,Q为正整数,P为小于等于Q的正整数。之后,边缘服务节点根据目标类型的用户集合中各个用户的数据包,确定所述目标类型对应的K个内容的喜好值;其中,所述目标类型为P个类型中的任意一个;所述喜好值用于表征用户集合中的用户使用内容的概率,K为正整数。边缘服务节点根据所述K个内容的喜好值,确定L个待缓存的内容,所述L个待缓存的内容是所述K个内容按照喜好值从大到小的排列顺序中的前L个内容,L为正整数。最后,边缘服务节点缓存所述L个待缓存的内容。
基于上述技术方案,由于不同类型的用户对于内容具有不同的需求,因此为了更好地满足用户的需求,边缘服务节点先将区域内的Q个用户进行分类,确定P个用户集合。然后,对于目标类型的用户集合,边缘服务节点确定目标类型对应的K个内容的喜好值。之后,边缘服务节点根据K个内容的喜好值,确定L个待缓存的内容。可以理解的是,由于所述L个待缓存的内容是所述K个内容按照喜好值从大到小的排列顺序中的前L个内容,而所述喜好值用于表征用户集合中的用户使用内容的概率,因此该L个待缓存的内容即为区域中的用户最有可能使用的L个内容。这样一来,边缘服务节点缓存该L个待缓存的内容,能够提高边缘服务节点向其服务的区域内的目标类型的用户提供内容的概率。从而,本发明的技术方案可以减小区域内目标类型的用户向应用服务器请求内容的概率,从而减少区域内的目标类型的用户获取到所需内容的时间。
第二方面,提供一种边缘服务节点,包括:分类模块,用于根据预先训练好的用户分类模型,对所述边缘服务节点所服务的区域内的所述Q个用户进行分类,生成P个用户集合,所述P个用户集合与P个类型一一对应,所述用户集合包括所述Q个用户中的一个或多个用户,所述用户集合中的用户对应的类型与所述用户集合对应的类型是相同的,Q为正整数,P为小于等于Q的正整数。确定模块,根据目标类型的用户集合中各个用户的数据包,确定所述目标类型对应的K个内容的喜好值;其中,所述目标类型为P个类型中的任意一个;所述喜好值用于表征用户集合中的用户使用内容的概率,K为正整数。所述确定模块,还用于根据所述K个内容的喜好值,确定L个待缓存的内容,所述L个待缓存的内容是所述K个内容按照喜好值从大到小的排列顺序中的前L个内容,L为正整数。存储模块,用于缓存所述L个待缓存的内容。
第三方面,本发明提供了一种通信装置,该通信装置包括处理器和通信接口;通信接口和处理器耦合,处理器用于运行计算机程序或指令,以实现如第一方面、第一方面的任一种可能的实现方式中所描述的内容缓存方法。
第四方面,本发明提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当指令在计算机上运行时,使得计算机执行上述第一方面、第一方面的任一种可能的实现方式中所描述的内容缓存方法。
第五方面,本发明提供一种包含指令的计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行上述第一方面、第一方面的任一种可能的实现方式中所描述的内容缓存方法。
第六方面,本发明提供一种芯片,芯片包括处理器和通信接口,通信接口和处理器耦合,处理器用于运行计算机程序或指令,以实现如第一方面、第一方面的任一种可能的实现方式中所描述的内容缓存方法。
附图说明
图1为本发明实施例提供的一种通信系统的架构示意图;
图2为本发明实施例提供的一种内容缓存方法的流程图;
图3为本发明实施例提供的一种模型训练方法的流程图;
图4为本发明实施例提供的一种边缘服务节点的结构示意图;
图5为本发明实施例提供的一种通信装置的结构示意图。
具体实施方式
本文中字符“/”,一般表示前后关联对象是一种“或者”的关系。例如,A/B可以理解为A或者B。
在本发明的描述中,除非另有说明,“多个”的含义是指两个或两个以上。
此外,本发明的描述中所提到的术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括其他没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
另外,在本发明实施例中,“示例性的”、或者“例如”等词用于表示作例子、例证或说明。本发明中被描述为“示例性的”或“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”、或者“例如”等词旨在以具体方式呈现概念。
下面对本发明实施例所涉及的术语进行介绍。
1、事务、项集
在数据挖掘中,事务数据库中的每个记录代表一个事务,例如顾客的一次购物、一个航班订票。通常,一个事务包含一个唯一的事务标识以及一个或多个组成事务的项。
项集是指事务中的一个或多个项组成的集合。
2、支持度(support)
在数据挖掘中,支持度表示同时包含A和B的事务占所有事务的百分比。
3、归一化(normalization)
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为标量。其中,归一化公式如下:
其中,X
4、信息熵(information entropy)
在机器学习中,信息熵可以作为一个系统复杂程度的度量。系统越混乱,信息熵越大。假如一个随机变量X的取值为X={x1,x2,…,xn},每一种取到的概率分别是{p1,p2,…,pn},则信息熵的计算公式为:
5、信息增益(Kullback–Leibler divergence)
在决策树算法中,信息增益是进行属性选择划分前和划分后信息的差值。信息增益的计算公式为:Gain(S,A)=E(S)–E(S,A)。其中Gain(S,A)为在整体样本S中随机变量A的信息增益,E(S)为整体信息熵,E(S,A)为整体样本中随机变量A的信息熵。
6、余弦相似度
余弦相似度(Cosine similarity)是用向量空间中两向量夹角的余弦值作为衡量两个个体之间差异的大小。给定两个属性向量,A和B,其余弦相似性θ由点积和向量长度给出,如下所示:
其中cos(θ)为余弦值,A和B为给定的两个属性向量,A
以上是本发明实施例所涉及的术语的介绍,以下不再赘述。
如图1所示,为本发明实施例提供的一种通信系统,该通信系统包括终端、基站、边缘服务节点、核心网以及应用服务器。
其中,终端可以是一种具有收发功能的设备。终端可以被部署在陆地上,包括室内或室外、手持或车载;也可以被部署在水面上(如轮船等);还可以被部署在空中(例如飞机、气球和卫星上等)。终端包括具有无线通信功能的手持式设备、车载设备、可穿戴设备或计算设备。示例性地,终端可以是手机(mobile phone)、平板电脑或带无线收发功能的电脑。终端设备还可以是虚拟现实(virtual reality,VR)终端设备、增强现实(augmentedreality,AR)终端设备、工业控制中的无线终端、无人驾驶中的无线终端、远程医疗中的无线终端、智能电网中的无线终端、智慧城市(smart city)中的无线终端、智慧家庭(smarthome)中的无线终端等等。
基站可以包括各种形式的基站,例如:宏基站,微基站(也称为小站),中继站,接入点等。具体可以为:是无线局域网(Wireless Local Area Network,WLAN)中的接入点(access point,AP),全球移动通信系统(Global System for Mobile Communications,GSM)或码分多址接入(Code Division Multiple Access,CDMA)中的基站(BaseTransceiver Station,BTS),也可以是宽带码分多址(Wideband Code Division MultipleAccess,WCDMA)中的基站(NodeB,NB),还可以是LTE中的演进型基站(Evolved Node B,eNB或eNodeB),或者中继站或接入点,或者车载设备、可穿戴设备以及未来5G网络中的下一代节点B(The Next Generation Node B,gNB)或者未来演进的公用陆地移动网(Public LandMobile Network,PLMN)网络中的基站等。
边缘服务节点是对边缘网关、边缘控制器、边缘服务器等边缘侧多种产品形态的基础共性能力的逻辑抽象,这些产品形态具备边缘侧实时数据分析、本地数据存储、实时网络联接等共性能力。可选的,边缘服务节点部署于基站后的网络接入机房内部。或者,边缘服务节点还可以部署于用户面网元所在的机房内部。一个边缘服务节点可以为多个基站提供服务。边缘服务节点存储有各类文件、视频、网页、图片等资源,以服务于终端。
核心网用于管理数据、负责数据的处理和转发。核心网的主要功能为提供用户连接、对用户的管理以及对业务完成承载,作为承载网络提供到外部网络的接口。在不同通信制式下,核心网具有不同的网元,本发明实施例对此不予赘述。
应用服务器用于负责存储、管理各种内容,例如视频、音频、文件等。应用服务器可以向终端提供其存储的内容。
可以理解的是,由于边缘服务节点与基站直接连接,因此若边缘服务节点向终端提供内容的时延低于应用服务器向终端提供内容的时延。
下面结合说明书附图对本发明实施例进行具体说明。
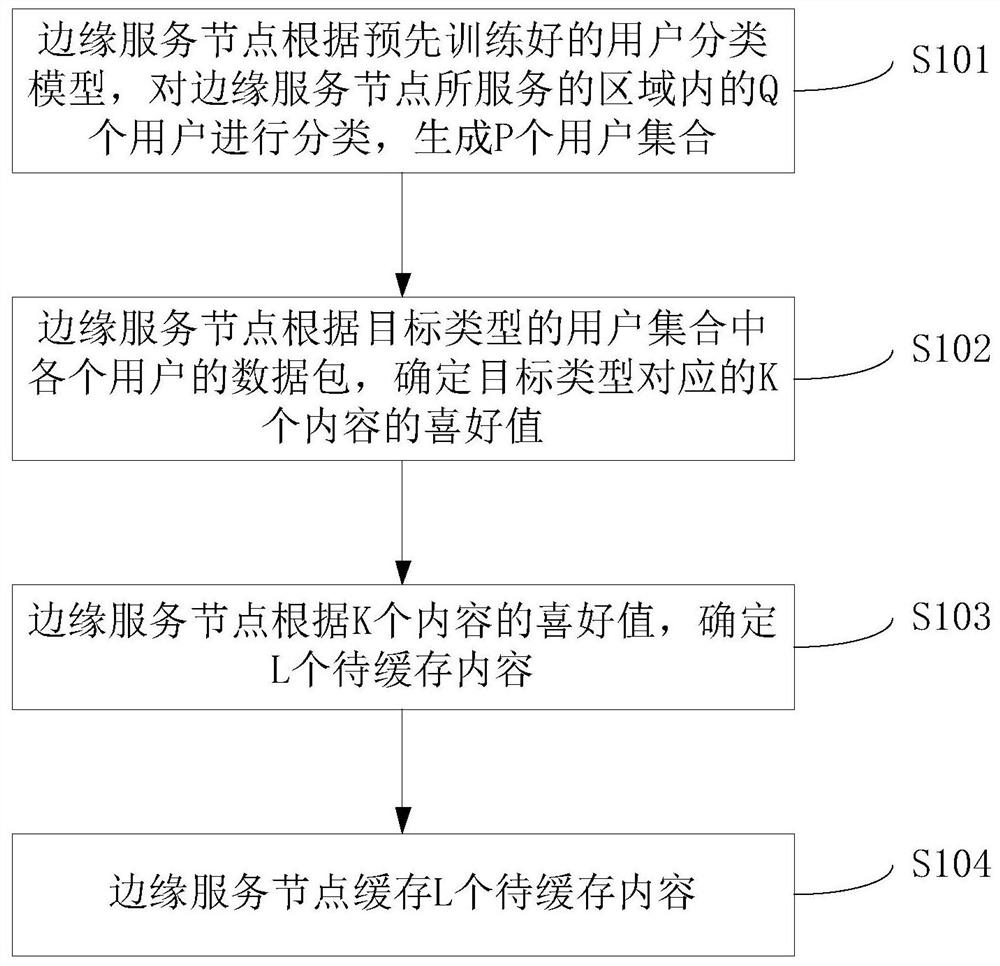
如图2所示,为本发明实施例提供的一种内容缓存方法,该方法包括:
S101、边缘服务节点根据预先训练好的用户分类模型,对边缘服务节点所服务的区域内的Q个用户进行分类,生成P个用户集合。
其中,用户分类模型用于对用户进行分类。
可选的,用户分类模型可以是基于机器学习的算法来构建。示例性的,机器学习的算法可以为决策树算法、随机森林算法、梯度提升迭代决策树(gradient boostingdecision tree,GBDT)算法等。
作为一种可能的实现方式,对于Q个用户中的每一个用户来说,边缘服务节点获取用户的多个特征的数值,并将用户的多个特征的数值输入用户分类模型,确定该用户的类型。在边缘服务节点确定Q个用户中每一个用户的类型之后,边缘服务节点将相同类型的用户组成一个用户集合,从而边缘服务节点可以确定P个用户集合。M、P均为正整数。
可以理解的是,P个用户集合与P个类型一一对应。用户集合包括Q个用户中的一个或多个用户。用户集合对应的类型与用户集合中的用户的类型相同。
需要说明的是,类型的划分可以根据专家经验来确定,或者根据运营商的业务需求来确定。示例性的,上述类型可以为网游类型、视频类型、语音类型。可以理解的是,用户的类型为网游类型,说明该用户最常使用网络游戏应用。用户的类型为视频类型,说明该用户最常使用视频应用。用户的类型为语音类型,说明该用户最常使用语音应用。
S102、边缘服务节点根据目标类型的用户集合中各个用户的数据包,确定目标类型对应的K个内容的喜好值。
其中,目标类型为P个类型中的任意一个。
需要说明的是,上述用户的数据包是指用户所使用的终端与应用服务器之间传输的数据包。上述用户的数据包可以是边缘服务节点从基站获取到的。
可选的,上述用户的数据包可以是指用户在一个时刻内的数据包,或者用户在一个时间段内的所有数据包。
示例性的,在目标类型为视频类型时,目标类型对应的内容即为视频。在目标类型为网游类型时,目标类型对应的内容即为网络游戏的相关数据(例如安装包、更新组件)。
在本发明实施例中,上述K个内容即为目标类型的用户集合中所有用户的数据包中出现的、与目标类型对应的所有内容。
举例来说,目标类型的用户集合中包括用户1、用户2、用户3,用户1的数据包出现内容1和内容2,用户2的数据包出现内容2和内容3,用户3的数据包出现内容4。目标类型对应的内容包括内容1、内容2、以及内容4。从而,边缘服务节点可以确定K个内容即为内容1、内容2、以及内容4。
在本发明实施例中,所述K个内容中第i个内容的喜好值根据以下公式确定:
其中,α为第i个内容的喜好值,β
可选的,γ
举例来说,假设k个内容为内容1、内容2、以及内容3。内容1的平均使用时长为1个小时,内容2的平均使用时长为1.5个小时,内容3的平均使用时长为2.5个小时,则内容1对应的γ
S103、边缘服务节点根据K个内容的喜好值,确定L个待缓存内容。
其中,所述L个待缓存的内容是所述K个内容按照喜好值从大到小的排列顺序中的前L个内容,L为正整数。
可以理解的是,L个待缓存内容为K个内容的子集。
示例性的,以k为5,L为2为例,内容1的喜好值为0.9,内容2的喜好值为0.3,内容3的喜好值为0.5,内容4的喜好值为0.7,内容5的喜好值为0.1,则边缘服务节点可以确定内容1和内容4为待缓存内容。
在本发明实施例中,L的具体取值可以是根据专家经验设置的,或者是根据边缘服务节点的能力设置的。
例如,若边缘服务节点的存储空间较大,则L的取值可以较大;若边缘服务节点的存储空间较小,则L的取值可以较小。
可以理解的是,边缘服务节点在执行步骤S103时可以采用冒泡排序、选择排序、插入排序、快速排序等算法。
S104、边缘服务节点缓存L个待缓存内容。
可以理解的是,在边缘服务节点缓存L个待缓存内容的情况下,若用户需要某一个待缓存内容,则边缘服务节点可以向该用户提供该待缓存内容。
可以理解的是,由于边缘服务节点所服务的区域内的用户时常变动,因此边缘服务节点可以周期性地执行上述步骤S101-S104,以及时缓存新的待缓存内容,从而满足新用户的需求。
基于上述技术方案,由于不同类型的用户对于内容具有不同的需求,因此为了更好地满足用户的需求,边缘服务节点先将区域内的Q个用户进行分类,确定P个用户集合。然后,对于目标类型的用户集合,边缘服务节点确定目标类型对应的K个内容的喜好值。之后,边缘服务节点根据K个内容的喜好值,确定L个待缓存的内容。可以理解的是,由于所述L个待缓存的内容是所述K个内容按照喜好值从大到小的排列顺序中的前L个内容,而所述喜好值用于表征用户集合中的用户使用内容的概率,因此该L个待缓存的内容即为区域中的用户最有可能使用的L个内容。这样一来,边缘服务节点缓存该L个待缓存的内容,能够提高边缘服务节点向其服务的区域内的目标类型的用户提供内容的概率。从而,本发明的技术方案可以减小区域内目标类型的用户向应用服务器请求内容的概率,从而减少区域内的目标类型的用户获取到所需内容的时间。
下面以用户分类模型为决策树为例,具体说明用户分类模型的训练过程。可以理解的是,若用户分类模型为决策树,该决策树是多分类的决策树。
如图3所示,为本发明实施例提供的一种模型训练方法,该方法包括:
S201、边缘服务节点获取多个第一用户数据。
其中,每一个第一用户数据关联一个样本用户。
作为一种可能的实现方式,对于每一个样本用户,边缘服务节点对样本用户的业务流进行包解析和数据预处理,获取样本用户对应的用户数据。可选的,该用户数据包括M个特征的数值,M为大于1的正整数。
可选的,上述数据预处理可以包括:语义分析、特征提取等。
示例性的,特征可以为:国际移动用户识别码(international mobilesubscriberidentity,IMSI)、用户套餐、用户使用的应用程序、应用程序对应的使用时长等。
S202、边缘服务节点根据多个第一用户数据,生成多个用户向量。
可以理解的是,由于第一用户数据所具有的特征较多,并且第一用户数据所具有的特征并不是都适用于用户分类模型训练过程中,因此边缘服务节点有必要先筛选出可以用于用户分类模型训练的特征,以简化用户分类模型训练的过程。
在本发明实施例中,边缘服务节点筛选用于用户分类模型训练的特征,其具体实现方式可以为:边缘服务节点以多个第一用户数据作为多个用户事务。可以理解的是,用户事务包括多个事务项。第一用户数据中的一个特征即为用户事务中的一个事务项。边缘服务节点根据多个用户事务,确定所有的高频项集,高频项集为支持度大于阈值的事务项集合。边缘服务节点根据所有的高频项集,确定N个目标事务项。目标事务项所对应的特征即为目标特征,目标特征为可以用于训练用户分类模型的特征。
下面以举例的方式说明目标事务项的确定过程。用户事务包括事务项A、事务项B、事务项C、事务项D、以及事务项E。边缘服务节点确定的高频项集包括:(事务项A,事务项B)、(事务项B,事务项C)、(事务项A,事务项D)。因此,边缘服务节点将高频项集所涉及的事务项确定为目标事务项,也即事务项A、事务项B、事务项C、以及事务项D均为目标事务项。
在筛选出用于模型训练的特征字段之后,边缘服务节点根据多个第一用户数据,确定多个第二用户数据。可以理解的是,一个第一用户数据对应一个第二用户数据。一个第二用户数据同样关联一个样本用户。
在本发明实施例中,第二用户数据包括N个目标特征的数值。N个目标特征为M个特征的子集,N为正整数。
之后,边缘服务节点对第二用户数据进行归一化处理,确定第三用户数据。第三用户数据包括归一化后的N个目标特征的数值。
对于每一个第三用户数据,边缘服务节点根据专家经验对第三用户数据进行标注,确定第三用户数据对应的标签数据。第三用户数据对应的标签数据用于指示第三用户数据所关联的样本用户的类型。
最后,对于每一个第三用户数据,边缘服务节点根据第三用户数据和第三用户数据对应的标签数据,可以生成用户向量。用户向量包括标签数据和归一化后的N个目标特征的数值。用户向量所包括的标签数据用于指示用户向量所关联的样本用户的类型。
S203、边缘服务节点根据多个用户向量,构建决策树。
作为一种可能的实现方式,边缘服务节点对多个用户向量进行分类,生成多个用户向量集合,用户向量集合包括同一类型的样本用户对应的用户向量。之后,边缘服务节点根据多个用户向量集合,构建决策树。
需要说明的是,边缘服务对多个用户向量进行分类,可以基于余弦相似度算法、正弦相似度算法、k-means算法等来实现,本发明实施例对此不作限制。
需要说明的是,边缘服务节点根据多个用户向量集合,构建决策树,其具体实现方式可以参考现有技术,在此不予赘述。
在本发明实施例中,决策树的根节点和中间节点均为N个目标特征中的一个目标特征。决策树的叶子节点为类型。
在本发明实施例中,决策树的构建需要计算信息熵和信息增益。其中,以信息增益最大的特征作为根节点,以减少树的层级,降低计算复杂度,节省效率。
可以理解的是,该决策树的叶子节点即为样本用户的类型。
基于图3所示的技术方案,边缘服务节点可以训练出用于用户分类的决策树。
需要说明的是,用户分类模型也可以由云服务器进行训练。在云服务器训练好用户分类模型之后,云服务器向边缘服务节点发送训练好的用户分类模型,以便于边缘节点根据该用户分类模型,对边缘服务节点所服务的区域内的用户进行分类。
可以理解的是,云服务器训练用户分类模型的实现方式可以参考图3所示的技术方案,本发明实施例在此不再赘述。
本发明实施例可以根据上述方法示例对边缘服务节点进行功能模块或者功能单元的划分,例如,可以对应各个功能划分各个功能模块或者功能单元,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块或者功能单元的形式实现。其中,本发明实施例中对模块或者单元的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
如图4所示,为本发明实施例提供的一种边缘服务节点。该边缘服务节点包括分类模块401、确定模块402、以及存储模块403。
分类模块401,用于根据预先训练好的用户分类模型,对所述边缘服务节点所服务的区域内的所述Q个用户进行分类,生成P个用户集合,所述P个用户集合与P个类型一一对应,所述用户集合包括所述Q个用户中的一个或多个用户,所述用户集合中的用户对应的类型与所述用户集合对应的类型是相同的,Q为正整数,P为小于等于Q的正整数。
确定模块402,根据目标类型的用户集合中各个用户的数据包,确定所述目标类型对应的K个内容的喜好值;其中,所述目标类型为P个类型中的任意一个;所述喜好值用于表征用户集合中的用户使用内容的概率,K为正整数。
所述确定模块402,还用于根据所述K个内容的喜好值,确定L个待缓存的内容,所述L个待缓存的内容是所述K个内容按照喜好值从大到小的排列顺序中的前L个内容,L为正整数;
存储模块403,用于缓存所述L个待缓存的内容。
一种可能的设计中,所述K个内容中第i个内容的喜好值根据以下公式确定:
一种可能的设计中,所述用户分类模型为决策树。所述分类模块,还用于执行以下步骤:获取多个第一用户数据,每一个第一用户数据关联一个样本用户,一个第一用户数据包括M个特征的数值,M为大于1的正整数;根据所述多个第一用户数据,生成多个用户向量,所述用户向量包括标签数据以及归一化后的N个目标特征的数值,所述标签数据用于指示所述用户向量所关联的样本用户的类型;N个目标特征为M个特征的子集,N为小于M的正整数;根据所述多个用户向量,构建所述决策树。
一种可能的设计中,所述分类模块401,还用于执行以下步骤:以所述多个第一用户数据作为多个用户事务,所述用户事务包括M个事务项,M个事务项与M个特征一一对应;根据所述多个用户事务,确定所有的高频项集,所述高频项集为支持度大于阈值的事务项集合;根据所有的高频项集,确定N个目标事务项,所述N个目标事务项为所述M个事务项的子集,所述N个目标事务项与所述N个目标特征一一对应。
在图4所示的通信装置以图5所示的通信装置来实现的情况下,处理器502用于对装置的动作进行控制管理,例如,执行上述分类模块401、确定模块402执行的步骤,和/或用于执行本文所描述的技术的其它过程。存储器501用于存储通信装置的程序代码和数据,例如执行上述存储模块403执行的步骤,和/或用于执行本文所描述的技术的其它过程。
图5所示的通信装置还可以包括通信模块503和总线504。通信模块503用于使通信装置能够和其他设备进行通信。
其中,上述处理器502可以实现或执行结合本发明公开内容所描述的各种示例性的逻辑方框,单元和电路。该处理器可以是中央处理器,通用处理器,数字信号处理器,专用集成电路,现场可编程门阵列或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本发明公开内容所描述的各种示例性的逻辑方框,单元和电路。所述处理器也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,DSP和微处理器的组合等。
存储器501可以包括易失性存储器,例如随机存取存储器;该存储器也可以包括非易失性存储器,例如只读存储器,快闪存储器,硬盘或固态硬盘;该存储器还可以包括上述种类的存储器的组合。
总线504可以是扩展工业标准结构(Extended Industry StandardArchitecture,EISA)总线等。总线504可以分为地址总线、数据总线、控制总线等。为便于表示,图5中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能单元的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元完成,即将装置的内部结构划分成不同的功能单元,以完成以上描述的全部或者部分功能。上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
本发明实施例还提供一种计算机可读存储介质,计算机可读存储介质中存储有指令,当计算机执行该指令时,该计算机执行上述方法实施例所示的方法流程中的各个步骤。
其中,计算机可读存储介质,例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘。随机存取存储器(Random Access Memory,RAM)、只读存储器(Read-Only Memory,ROM)、可擦式可编程只读存储器(Erasable Programmable Read Only Memory,EPROM)、寄存器、硬盘、光纤、便携式紧凑磁盘只读存储器(Compact Disc Read-Only Memory,CD-ROM)、光存储器件、磁存储器件、或者上述的人以合适的组合、或者本领域数值的任何其他形式的计算机可读存储介质。一种示例性的存储介质耦合至处理器,从而使处理器能够从该存储介质读取信息,且可向该存储介质写入信息。当然,存储介质也可以是处理器的组成部分。处理器和存储介质可以位于特定用途集成电路(Application Specific Integrated Circuit,ASIC)中。在本发明实施例中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何在本发明揭露的技术范围内的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 无线异构网络中的新型缓存内容放置及内容缓存分布优化方法
- 基于内容分发网络缓存文件系统的文件缓存方法及装置