工作流引擎工具
文献发布时间:2023-06-19 13:46:35
背景技术
在大数据和人工智能(AI)时代,对数据的智能利用已经成为许多企业成功的重要因素。数据通常是高级分析、人工智能,以及业务运营效率的基础。随着越来越多的企业成为数据驱动并且数据量在快速增长,越来越需要管理和执行复杂的数据处理流水线,这些流水线从各种来源提取数据,转换数据以用于消费(例如,提取特征和训练AI模型),并且保存用于后续使用。工作流引擎通常被用于管理大规模的数据工作流流水线。
尽管工作流引擎有多个益处,但由于陡峭的学习曲线和创作复杂工作流流水线所需的努力,对工作流引擎的充分利用仍然是繁重的。有向无环图(DAG)定义了用于利用数据来产生一些想要的结果的工作流流水线。通常,用户(例如,工程师和科学家)与图形用户界面(GUI)交互以手动构建DAG,或者必须学习特殊语法以编程方式生成DAG。这些方法都不是自然的或直观的,并且两者都容易出错。当DAG变得庞大和复杂时,生成以及调整和审查DAG的生成可能引入大量的开销努力。
发明内容
下面参考下文所列出的附图详细描述所公开的示例。提供以下发明内容以说明本文所公开的一些示例。然而,这并不意味着将所有示例限制为任何特定配置或操作序列。
本文公开了一种工作流引擎工具,该工作流引擎工具使得科学家和工程师能够几乎没有开销地以编程方式创作工作流(例如,有向无环图DAG),使用更简单的脚本,该脚本几乎不需要修改即可在用于多个不同的工作流引擎之间进行移植。这准许用户专注于项目的业务逻辑,避免与工作流管理有关的分散注意力的繁琐开销(诸如,上传模块、绘制边、设置参数,以及其他任务)。工作流引擎工具提供了在工作流引擎之上的抽象层,引入了将编程语言函数(例如,常规python函数)转换为工作流模块定义的绑定函数。工作流引擎工具通过从编程语言脚本中推断构建DAG来推断模块实例并且自动归纳边依赖性。
示例工作流引擎工具包括:处理器;以及存储指令的计算机可读介质,该指令当由处理器执行时用于:从编程语言脚本提取模块定义;从编程语言脚本提取执行流信息;针对第一工作流引擎,从所提取的模块定义生成模块;针对第一工作流引擎,生成用于连接针对第一工作流引擎生成的模块的边;以及至少基于所提取的执行流信息,用针对第一工作流引擎生成的边来连接针对第一工作流引擎生成的模块,以生成针对第一工作流引擎的第一工作流流水线。
附图说明
下面参考下文所列出的附图详细描述本公开的示例:
图1示出了可以有利地使用示例性工作流引擎工具的布置;
图2示出了示例工作流模块创作页面;
图3示出了由图1的工作流引擎工具使用的示例脚本的一部分;
图4示出了图3的示例脚本的另一部分;
图5示出了图1的工作流引擎工具操作图3和图4所示的脚本的中间结果;
图6示出了由图1的工作流引擎工具对各种数据字段中的信息的提取;
图7是与操作图1的工作流引擎工具相关联的操作的流程图;
图8是与操作图1的工作流引擎工具相关联的操作的另一流程图;
图9是适合用于实现本文所公开的各种示例中的一些示例的示例计算环境的框图。
整个附图中对应的附图标记表示对应的部分。
具体实施方式
各种示例将参考附图被详细描述。在可能的情况下,在整个附图中相同的附图标记被用于指代相同或相似的部件。贯穿本公开的与特定示例和实施方式相关的参考被提供仅用于说明目的,但除非有相反指示,否则并不意味着限制所有示例。
在大数据和人工智能(AI)时代,对数据的智能利用已经成为许多企业成功的重要因素。数据通常是高级分析、人工智能,以及业务运营效率的基础。随着越来越多的企业成为数据驱动并且数据量在快速增长,越来越需要管理和执行复杂的数据处理流水线的增长的需要,这些流水线从各种来源提取数据,转换数据以用于消费(例如,提取特征和训练AI模型),并且保存用于后续使用。工作流引擎通常被用于管理大规模的数据工作流流水线。工作流由经编排并且可重复的业务活动模式组成,工作流能够通过将资源系统地组织为转换材料、提供服务或处理信息的流程而实现,工作流可以被描述为一系列的操作、个人或团队的工作、员工组织的工作,或一个或多个简单或复杂的机制。流(flow)可以指从一个步骤被转移到另一步骤的文档、服务或产品。
工作流可以被视为一个基本构建块,该基本构建块将与组织结构的其他部分(诸如信息技术、团队、项目和层级)相结合。工作流管理系统的益处包括:
-管理作业(job)之间的依赖性;
-跨异构计算集群的编排;
-透明性、可再现性、可重用性(模块和数据的共享)、协作、快速开发;
-故障处理、警报、回顾,以及调度;
-离线实验和在线生产之间的平等;
-可视化、监控、管理工作;工作的历史查看;以及
-版本控制、差异化,以及来源控制
AI应用中的工作流通常是一个长期的、周期性的批处理过程;AI工程应用通常包含大量工作流,包括数据清洗和处理、模型训练实验,以及度量仪表盘生成。典型的工作流流水线类型包括:
-数据仓库;
-数据基础设施维护;
-模型训练和实验;
-在线产生;以及
-报告和遥测。
有向无环图(DAG)定义了一个工作流流水线,用于利用数据来产生一些想要的结果。通常,用户(例如,工程师和科学家)与图形用户界面(GUI)交互以手动构建DAG,或者必须学习特殊语法以编程方式生成DAG。这些方法都不是自然的或直观的,并且两者都容易出错。当DAG变得庞大和复杂时,生成以及调整和审查DAG的生成可能引入大量的开销努力。作业模块的手动创建需要指定边以将模块连接到DAG,这很乏味、劳动强度大且容易出错。以编程方式对DAG的创建需要编写代码,诸如,诸如使用C#、python,或其他编程语言等编程语言编写的脚本。虽然这省去了由手工绘制图形的繁琐工作,但它仍然需要用户编写大量的额外代码、上传模块、连接节点等,这对工作的核心逻辑来说是开销。此外,额外的代码是特定于工作流引擎的,这不仅增加了学习成本,而且阻止了时间投入与其他工作流引擎的重用。尽管工作流引擎有多个益处,但由于陡峭的学习曲线和创作复杂工作流流水线所需的努力,对工作流引擎的充分利用仍然是繁重的。
因此,本文提供了一种工作流引擎工具,该工作流引擎工具使得科学家和工程师能够几乎没有开销地以编程方式创作工作流(例如,DAG),使用更简单的脚本,该脚本几乎不需要修改即可在用于多个不同的工作流引擎之间进行移植。这准许用户专注于项目的业务逻辑,避免与工作流管理有关的分散注意力的繁琐开销(诸如,上传模块、绘制边、设置参数,以及其他任务)。工作流引擎工具提供了在工作流引擎之上的抽象层,引入了将编程语言函数(例如,普通的python函数)转换为工作流模块定义的绑定函数。工作流引擎工具通过从编程语言脚本中推断构建DAG来推断模块实例并且自动归纳边依赖性。
工作流引擎工具从编程脚本(例如,python脚本)中归纳工作流图,使得模块定义从函数定义(例如,包含文档字符串的函数定义)中被推断,包括归纳输入、参数,以及输出。模块实例(任务和节点)是通过脚本中的函数调用而被自动检测和创建的,一些示例涉及从上游依赖性和模块自己的参数生成唯一的模块ID。基于一个函数调用生成的变量来推断边和执行依赖性,并且作为输入和参数被提供给其他函数。因此,工作流引擎工具创建抽象层来作为用户脚本和目标工作流引擎之间的桥梁。为了适配各种底层的工作流引擎,通过实现不同版本的抽象层,脚本可以运行在多个不同的工作流引擎上来生成DAG,而无需进行繁琐的更改。通过提供虚拟(dummy)抽象层,相同的脚本甚至可以在没有工作流引擎的情况下运行。此外,工作流引擎工具自动解决任务和数据依赖性,自然地处理数据持久性缓存,准许相同的脚本在本地和工作流集群上运行——用于多个不同的工作流引擎。这消除了需要手动创建DAG或用特殊API来编程的需要。
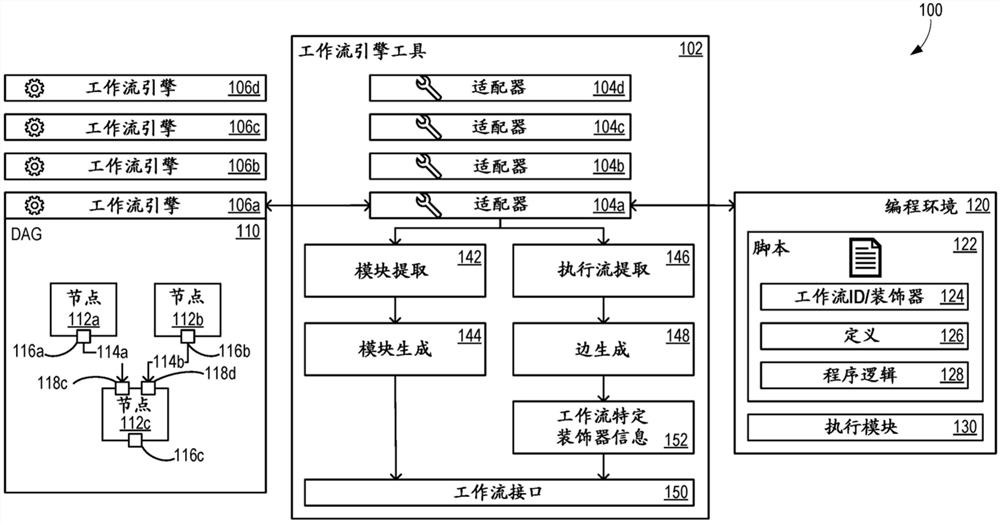
图1示出了可以有利地使用示例性工作流引擎工具102的布置100。工作流引擎工具102包括与多个不同的工作流引擎106a-106d相对应的多个适配器104a-104d,允许编程环境120中的公共脚本122在多个不同的工作流引擎106a-106d中的任何一个工作流引擎上运行。应当理解,在一些示例中,可以支持不同数目的工作流引擎。在一些示例中,工作流引擎106b-106d中的至少一个工作流引擎是虚拟抽象层,准许工作流引擎工具102在没有工作流引擎的情况下运行。DAG110是针对工作流引擎106a而生成的,并且包括节点112a-112c以及边114a和114b,边114a和114b分别将节点112a和112b的输出116a和116b与节点112c的输入118c和118d连接起来。如图所示,节点112c还具有输出116c。
工作流DAG(例如,DAG 110)由节点(例如,节点112a-112c)和有向边(例如,边114a和114b)组成。节点(例如,模块)是工作流中任务执行的基本单元。它可以是函数、脚本或可执行程序,对应于由用户定义的单个任务。每个节点具有零个或更多个输入、零个或更多个参数、以及零个或更多个输出。输入和输出是从一个节点传递到另一节点的数据。取决于实际的工作流引擎设计,交换的数据可以是多种不同的形式,诸如,存储器对象、共享文件、分布式文件以及其他。一个节点的输出可以成为另一节点的输入,这至少部分决定了节点之间的执行依赖性。例如,因为节点112c具有来自节点112a的输出116a的输入118c,所以节点112c不能被执行,直到节点112a被成功执行并且产生输出116a。节点之间的依赖性可以被表示为工作流DAG中的边。模块可以具有多个输入和多个输出。通常,每个输入和输出都与作为其标识符的唯一名称相关联。
参数是用于节点的特定执行运行所需的基本数据,但尚未由另一节点输出。例如,用于训练AI模型的节点可以具有诸如“时期(epoch)数目”或“学习率”的参数。输入和参数两者都是执行节点所需的基本数据。输入和参数的区别是,输入是由上游节点在运行期间动态生成的数据,因此指示节点之间的执行流程依赖性(边),而参数不是由上游节点生成的数据,而是由用户在运行之前指定的数据。因此,参数不会影响节点之间的依赖性。参数通常是一些可以容易地被指定的简单值。在某些情况下,用户可以具有将数据指定为输入或参数的选择。例如,如果数据复杂,那么即使它可以是参数,函数也可以被编写来生成它,从而使该数据成为输入。此外,在某些情况下,输入、输出以及参数可以具有强制数据类型,诸如,整数、浮点数、字符串、日期时间或其他预定义的数据类型。在这种情况下,当输出被连接到输入时,数据类型应该一致。
边是有向的(有方向,从输出指向输入),并且因此至少规定了节点(模块和任务)之间执行依赖性的某些方面。DAG中的边必须被定义为使得DAG是无环的,以便准许对执行顺序的确定。因此,由于节点112c具有来自节点112a的输出116a的输入118c(通过边114a),节点112a不能具有依赖(直接地或通过中间模块)于节点112c的输出116c的输入。在一些示例中,两个模块之间可以存在多个边,因为边将输入连接到输出,并且每个模块可以具有多个输入或输出。但是,为了防止循环依赖性,在这种情况下,所有边都应该具有相同的方向。当一个模块生成的数据被多个其他模块消费时,单个输出可以连接到多个输入。然而,模块的输入可以只来自一个来源。
DAG流水线的执行表示DAG的特定运行。参数在DAG可以被执行之前必须被预先指定,而且DAG可以还需要一些来自外部数据源的数据,这些数据是由某些加载模块带入DAG的。DAG运行是确定性的,这意味着,在给定相同的输入数据和参数的情况下,针对多次执行运行的最终输出将保持一致。在某些情况下,工作流引擎(例如,工作流引擎106a)可以在输入依赖性和参数没有被改变时缓存由成功执行模块生成的中间结果,以便在下一运行期间使用缓存的结果可以,以替代再次执行模块。这可以加速用于DAG的执行时间。针对缓存系统,检测输入的更改,使得缓存的结果不会不适当地重用。
编程环境120表示通用编程环境,诸如,python或C#。执行模块130准许以高级编程语言编写的脚本122执行。例如,针对逐行解释语言,执行模块130提供执行虚拟机。在所示出的示例中,编程环境120是python环境。脚本122被示出为包括三个部分:工作流标识符和装饰器124、函数定义部分126(例如,包括文档字符串的函数定义),以及程序逻辑部分128。Python提供了装饰器,装饰器是函数,该函数接受另一函数并且扩展该另一函数的行为,而无需显式修改该另一函数函数。在一些示例中,工作流标识符和装饰器124被实现为“绑定”函数,“绑定”函数是用于将函数转换为可以在工作流引擎中识别和使用的模块定义的行代码中的单个行。示例和进一步细节将参考图5被提供。工作流标识符和装饰器124使得工作流引擎工具102能够选择适配器104a-104d中的一个目标适配器,使得工作流引擎工具102可以针对不同的底层工作流引擎来创建不同的引擎封装器。这准许函数定义部分126和程序逻辑部分128在工作流引擎106a-106d中的任何一个工作流引擎被定为目标时仍然不改变。为清楚起见,在图2至图4的描述之后,将结合图5描述组件142-152。
图2示出了示例工作流模块创作页面200。工作流模块创作页面200被用于针对DAG手动生成模块,并且具有用于用户完成的多个数据字段。工作流引擎工具102能够从与工作流模块创作页面200中的多个数据字段相对应的脚本122中提取、推断或以其他方式生成信息,从而使得工作流模块创作页面200在各种用例场景中过时。
图3示出了提供与工作流引擎工具102一起使用的函数定义的脚本部分300,其中用户利用工作流引擎工具102来使用标准编程语言语法来指定DAG。具体地,脚本部分300形成函数定义部分126的示例。脚本部分300的图示示例使用以下函数,以用于示例性AI训练和测试操作:
-prepare_data(),加载数据集,将数据集拆分为训练和测试部分,并且分别返回训练和测试数据。该函数不接收输入或参数,并且生成四个输出。
-train(),接收训练数据(输入和标签),训练模型,并且返回经训练的模型。该函数生成经训练的模型作为输出,并且接收三个实参(argument);前两个实参是输入,并且第三个实参是参数。
-test(),接收经训练的模型和测试数据,预测模型输出,并且在输出处生成分类报告。
脚本部分300的文本是:
函数参数对应于模块输入和模块参数,因为它们是函数在通用编程环境中运行和模块在工作流环境中运行所需的数据。函数也具有返回值,返回值对应于模块输出。通过从脚本部分300中提取该数据,工作流引擎工具102使用户不必手动指定模块的输入、参数和输出。例如,函数定义包括指定以下各项的文档字符串:(1)哪些函数参数是模块输入,(2)哪些函数参数是模块参数,以及(3)函数返回什么来作为模块输出或输出。
例如,prepare_data()使用
:return:<train_x,train_y,test_x,test_y>.
:rtype:<npy,npy,npy,npy>.
来指定type npy的四个输出,即,train_x、train_y、test_x,以及test_y。函数train()使用文档字符串来定义输入train_x和train_y,作为与prepare_data()的train_x和train_y输出相同的npy数据类型,以及pkl类型的被命名为分类器的输出。这准许生成将基于对应于prepare_data()的模块的train_x的输出连接到基于对应于train()的模块的train_x的输入的边。对于相同的模块,使用基于train_y的输入和输出生成类似的边。函数test()使用文档字符串来定义输入test_x和test_y,作为与prepare_data()的test_x和test_y输出相同的npy数据类型,和被命名为分类器的输入,其与使用相同名称的train()的输出具有相同的pkl数据类型。这准许生成三个边,其中两个边从与prepare_data()相对应的模块的输出到与test()相对应的模块的输入,并且一个边从与train()相对应的模块的输出到与test()相对应的模块的第三输入。
函数test()必须在prepare_data()和train()两者之后执行,并且train()必须在prepare_data()之后执行。这意味着执行顺序是prepare_data(),然后是train(),然后是test()。工作流引擎工具102提取该信息以生成具有正确输入、参数和输出的模块,然后生成连接模块的边。
图4示出了可以用于与脚本部分300组合以与工作流引擎工具102一起使用的脚本部分400。具体地,脚本部分400提供有利地使用脚本部分300中所提供的函数定义的程序逻辑,并且形成程序逻辑部分128的示例。脚本部分400的图示示例将上述函数用于示例性AI训练和测试操作:
train_x,train_y,test_x,test_y=prepare_data()
classifier=train(train_x,train_y,0.001)
res=test(classifier,test_x,test_y).
该示例程序(包括脚本部分300和400)加载数据,将它分成训练和测试部分,使用训练数据进行训练,使用测试数据进行测试,并且返回报告。这里,通过这个示例,可以推断(提取)执行流程。
图5示出了工作流引擎工具102操作脚本522的中间结果。在该示例中,脚本522包括脚本部分300和400(分别为图3和图4),以及工作流标识符和装饰器124,装饰器124指定适配器104a(用于工作流引擎106a)并且调用python装饰器来将所定义的函数转换为工作流模块定义。工作流标识符和装饰器124的一个示例是:
lf_a=LightflowEngine()
prepare_data,train,test=lf_a.bind_functions(prepare_data,train,test).
DAG 510具有与上述prepare_data()函数相对应的节点512a、与上述train()函数相对应的节点512b,以及与上述test()函数相对应的节点512c。此外,边在节点之间被示出。为简单起见,边514a和514b被示出为单个边,尽管每个边都有两个输出,以匹配节点512a的四个值输出(train_x、train_y、test_x,以及test_y),为了图示清楚,输出被示出为单个输出516a。具体地,边514a将来自输出516a的test_x和test_y连接到节点512c的输入518a(实际上将有两个);边514b将train_x和train_y从输出516a连接到节点512b的输入518b(实际上有两个);并且边514c将来自节点512b的输出516b的分类器连接到节点512c的输入518c。这与节点512b的参数618和来自节点512c的输出616一起在图6中被示出。
返回到图5,执行信息提取以及模块和边生成活动的组件142-152被描述。模块提取组件142使用脚本522(例如,脚本部分300)中的函数定义来提取由模块生成组件144使用的信息以生成模块(例如,节点512a-512c)。当模块被创建时,它们将需要标签或模块ID,以便由工作流引擎106a寻址和处理。生成用于分配给节点512a-512c的模块ID的一个方式是使用上游依赖性。例如,节点512a是节点512b和512c两者的上游,并且节点512b是节点512c的上游。然后可以使用来自节点512a和512c的信息来生成针对节点512c的模块ID,例如,通过组合它们的模块ID并且将它们传递给不太可能产生模块ID冲突的函数。工作流接口组件150将生成的模块发送到工作流引擎106a。执行流提取组件146使用输入和输出信息来提取执行流信息,并且边生成组件148生成将输出(例如,输出516a和516b)与由模块生成组件144生成的模块的输入(518a-518c)连接的边。工作流接口组件150将生成的模块发送到工作流引擎106a。工作流装饰器组件152根据特定的目标工作流引擎(例如,工作流引擎106a)来绑定函数,使得DAG 510可以被生成。工作流接口组件150执行DAG 510和针对工作流引擎106a的底层系统调用。
在一些示例中,可以将一系列函数调用可以被分组为更复杂的结构,例如通过创建子图并且在顶级工作流流水线中使用子图。使用先前标识的函数的示例精简脚本是:
此外,在某些示例中,基于条件分支逻辑,诸如if-then分支和for-循环,DAG可以根据需要被创建,——在从脚本中提取信息时,编译DAG所需的信息可用。装饰器函数准许使用在某些参数中经标识的特定于工作流的函数。例如,根据脚本部分400(图4的)的以下示例修改,一些工作流可以支持模式规范:
train_x,train_y,test_x,test_y=prepare_data(mode=’cpu’)
classifier=train(train_x,train_y,0.001,mode=’gpu’)
res=test(classifier,test_x,test_y,mode=’gpu’)
当工作流引擎工具102读取附加参数时,它将基于文档字符串中模块函数的原始参数将它们识别为工作流特定参数。为了使得脚本522能够在有或没有支持附加参数的工作流引擎的任何地方运行,虚拟(dummy)封装器绑定函数,但消除附加参数并且仅将原始参数传递给原始函数。这样,只要改变一行,脚本522就可以正常运行了,无需任何进一步的改变。
图7是与操作工作流引擎工具102相关联的操作的流程图700。如上所述,工作流引擎工具102极大地简化了用于用户的工作流生成。用户只需要执行如图所示的操作702到710,而不需要手动创建模块(例如,针对每个模块使用工作流模块创作页面200),然后手动连接模块。在操作702中,用户开发任务函数,包括文档字符串定义,产生脚本部分300(图3的)的等价物。在操作704中,用户以通用编程语言编写程序逻辑,产生脚本部分400(图4)的等价物。在操作706中,用户标识目标工作流引擎,并且在操作708中使用工作流标识符和装饰器124来绑定函数。这准许用户在操作710中仅通过运行脚本来生成工作流。
图8是与操作工作流引擎工具102相关联的操作的流程图800。在一些示例中,以下操作被实现为存储在计算设备900上并且由计算设备900执行的计算机可执行指令。操作802包括在编程环境中编写编程语言脚本。在一些示例中,编程语言包括python编程语言并且编程语言脚本是python脚本。在一些示例中,C#被使用。操作804包括接收编程语言脚本的工作流引擎工具。操作806包括从编程语言脚本提取模块定义,并且操作808包括从编程语言脚本提取执行流信息。操作810然后包括针对工作流引擎从所提取的模块定义生成模块。在一些示例中,这包括使用绑定函数。操作812包括至少基于上游依赖性为针对工作流引擎生成的模块生成模块ID。
操作814包括针对工作流引擎生成用于连接针对工作流引擎生成的模块的边,并且操作816包括至少基于所提取的执行流信息,用针对工作流引擎生成的边来连接针对工作流引擎生成的模块,以生成针对工作流引擎的工作流流水线。在一些示例中,工作流流水线包括DAG。操作818包括识别工作流特定参数。如果目标工作流引擎被支持(如判定操作820所确定的),则操作822包括将工作流特定参数传递给工作流引擎。否则,操作824消除工作流特定参数,并且不传递它。操作826然后包括运行工作流引擎以执行工作流流水线。
如果在判定操作828中确定另一不同的工作流引擎将与编程语言脚本一起使用,则操作830包括稍微修改第二工作流引擎的编程语言脚本。在一些示例中,这与修改单个行(例如,图1和图5中的工作流标识符和装饰器124)一样简单,然后流程图800返回到操作804,其中工作流引擎工具接收经过稍微修改的编程语言脚本。
本文所公开的一些方面和示例涉及一种工作流引擎工具,包括:处理器;以及存储指令的计算机可读介质,指令当由处理器执行时用于:从编程语言脚本提取模块定义;从编程语言脚本提取执行流程;针对第一工作流引擎,从所提取的模块定义生成模块;针对第一工作流引擎,生成用于连接针对第一工作流引擎生成的模块的边;以及至少基于所提取的执行流信息,用针对第一工作流引擎生成的边来连接针对第一工作流引擎生成的模块,以生成针对第一工作流引擎的第一工作流流水线。
本文所公开的附加的方面和示例涉及一种用于工作流引擎管理的过程,包括:从编程语言脚本提取模块定义;从编程语言脚本提取执行流程;针对第一工作流引擎,从所提取的模块定义生成模块;针对第一工作流引擎,生成用于连接针对第一工作流引擎生成的模块的边;以及至少基于所提取的执行流信息,用针对第一工作流引擎生成的边来连接针对第一工作流引擎生成的模块,以生成针对第一工作流引擎的第一工作流流水线。
本文所公开的附加的方面和示例涉及一个或多个计算机存储设备,其上存储有用于工作流引擎管理的计算机可执行指令,该计算机可执行指令在由计算机执行时,使计算机执行操作,该操作包括:从编程语言脚本提取模块定义;从编程语言脚本提取执行流程;针对第一工作流引擎,从所提取的模块定义生成模块;针对第一工作流引擎,生成用于连接针对第一工作流引擎生成的模块的边;以及至少基于所提取的执行流信息,用针对第一工作流引擎生成的边来连接针对第一工作流引擎生成的模块,以生成针对第一工作流引擎的第一工作流流水线;针对第二工作流引擎,从所提取的模块定义生成模块;针对第二工作流引擎,生成用于连接针对第二工作流引擎生成的模块的边;以及至少基于所提取的执行流信息,用针对第二工作流引擎生成的边来连接针对第二工作流引擎生成的模块,以生成针对第二工作流引擎的第二工作流流水线。
备选地,或者除了本文的其他示例之外,示例包括以下内容的任何组合:
-编程语言包括python编程语言;
-第一工作流流水线包括DAG;
-运行第一工作流引擎以执行第一工作流流水线;
-针对第二工作流引擎,从所提取的模块定义生成模块;针对第二工作流引擎,生成用于连接针对第二工作流引擎生成的模块的边;以及至少基于所提取的执行流信息,利用针对第二工作流引擎生成的边来连接针对第二工作流引擎生成的模块,以生成针对第二工作流引擎的第二工作流流水线。
-第二工作流流水线包括DAG;
-运行第二工作流引擎已执行第二工作流流水线;
-识别工作流特定参数;以及至少基于第一工作流引擎是否支持工作流特定参数,将工作流特定参数传递给第一工作流引擎;
-至少基于上游依赖性,为针对第一工作流引擎生成的模块生成模块ID;
-至少基于上游依赖性,为针对第二工作流引擎生成的模块生成模块ID。
虽然已经根据各种示例及其相关操作描述了本公开的多个方面,但是本领域技术人员将理解,来自任何数目的不同示例的操作的组合也在本公开的方面的范围内。
图9是用于实现本文所公开的多个方面的示例计算设备900的框图,并且通常被指定为计算设备900。计算设备900只是合适的计算环境的一个示例并且不旨在暗示对本文公开的示例的使用范围或功能性的任何限制。计算设备900也不应被解释为对所示出的任何一个或组件/模块的组合具有任何依赖性或要求。本文公开的示例可以在计算机代码或机器可用指令的一般上下文中描述,包括由计算机或其他机器执行的计算机可执行指令,诸如由计算机或其他机器执行的程序组件,诸如个人数据助理或其他手持设备。通常,程序组件包括例程、程序、对象、组件、数据结构等,指代执行特定任务或实现特定抽象数据类型的代码。可以在各种系统配置中实践所公开的示例,包括个人计算机、膝上型计算机、智能电话、移动平板电脑、手持设备、消费电子产品、专业计算设备等。当任务由通过通信网络链接的远程处理设备执行时,还可以在分布式计算环境中实践所公开的示例。
计算设备900包括直接或间接耦合以下设备和组件的总线910:计算机存储存储器912、一个或多个处理器914、一个或多个呈现组件916、输入/输出(I/O)端口918、I/O组件920、电源922,以及网络组件924。计算设备900不应被解释为具有与其中所示的任何单个组件或组件的组合相关的任何依赖性或要求。虽然计算设备900被描绘为看似单个设备,但是多个计算设备900可以一起工作并且共享所描绘的设备资源。例如,存储器912可以跨多个设备分布,(多个)处理器914可以提供安装在不同设备上,等等。
总线910表示什么可以是一个或多个总线(诸如,地址总线、数据总线或其组合)。尽管为了清楚起见,图9的各个块用线条示出,但实际上,描绘各个部件并不是那么清楚,并且比喻地,线条将更准确地是灰色和模糊的。例如,人们可以将诸如显示设备的呈现组件视为I/O组件。此外,处理器具有存储器。这就是本领域的本质,并且重申图9的图表仅仅是示例性计算设备的说明,该示例性计算设备可以与一个或多个公开的示例结合使用。在诸如“工作站”、“服务器”、“膝上型电脑”、“手持设备”等的类别之间没有区别,因为在图9的范围内以及本文对“计算设备”的引用都考虑了这些类别。存储器912可以采用以下计算机存储介质引用的形式,并且可操作地为计算设备900提供计算机可读指令、数据结构、程序模块和其他数据的存储。例如,存储器912可以存储操作系统、通用应用平台或其他程序模块和程序数据。存储器912可以被用于存储和访问被配置为执行本文所公开的各种操作的指令。
如下所述,存储器912可以包括易失性和/或非易失性存储器、可移除或不可移除存储器、虚拟环境中的数据盘或其组合形式的计算机存储介质。存储器912可以包括与计算设备900相关联或可由计算设备900访问的任何数目的存储器。存储器912可以在计算设备900内部(如图9所示)、在计算设备900外部(未示出)或两者(未示出)。存储器912的示例包括但不限于随机存取存储器(RAM);只读存储器(ROM);电可擦可编程只读存储器(EEPROM);闪存或其他存储技术;CD-ROM、数字多功能光盘(DVD)或其他光学或全息介质;盒式磁带、磁带、磁盘存储器或其他磁性存储设备;被连线到模拟计算设备的存储器;或用于编码所需信息并且用于供计算设备900访问的任何其他介质。附加地或备选地,存储器912可以分布在多个计算设备900上,例如,在其中指令处理在多个计算设备900上执行的虚拟化环境中。为了本公开的目的,“计算机存储介质”、“计算机存储存储器”、“存储器”和“存储器设备”是存储器912的同义术语,并且这些术语都不包括载波或传播信令。
(多个)处理器914可以包括任何数目的从各种实体读取数据的处理单元,诸如存储器912或I/O组件920。具体地,处理器914被编程为执行用于实现本所公开的多个方面的计算机可执行指令。指令可由处理器、计算设备900内的多个处理器或计算设备900外部的处理器执行。在一些示例中,(多个)处理器914被编程为执行诸如在下面讨论的流程图中示出和在附图中描绘的那些的指令。此外,在一些示例中,(多个)处理器914表示模拟技术的实现以执行本文所描述的操作。例如,这些操作可以由模拟客户端计算设备900和/或数字客户端计算设备900来执行。呈现组件916向用户或其他设备呈现数据指示。示例性呈现组件包括显示设备、扬声器、打印组件、振动组件等。本领域技术人员将理解和理解,计算机数据可以以多种方式呈现,例如在图形用户界面(GUI)中可视化、通过扬声器可听、在计算设备900之间无线地、通过有线连接或以其他方式。端口918允许计算设备900逻辑被耦合到包括I/O组件920的其他设备,其中一些可以内置。示例I/O组件920包括,例如但不限于,麦克风、操纵杆、游戏手柄、卫星天线、扫描仪、打印机、无线设备等。
计算设备900可以使用到一个或多个远程计算机的逻辑连接经由网络组件924在联网环境中操作。在一些示例中,网络组件924包括网络接口卡和/或用于操作网络接口卡的计算机可执行指令(例如,驱动程序)。计算设备900和其他设备之间的通信可以使用任何协议或机制通过任何有线或无线连接进行。在一些示例中,网络组件924可操作以使用传输协议在公共、私人或混合(公共和私人)上传输数据,使用短距离通信技术(例如,近场通信(NFC)、Bluetooth
尽管结合示例计算设备900进行了描述,但是本公开的示例能够用许多其他通用或专用计算系统环境、配置或设备来实现。可能适合与本公开的方面一起使用的众所周知的计算系统、环境和/或配置的示例包括但不限于智能电话、移动平板电脑、移动计算设备、个人计算机、服务器计算机、手持设备或膝上型设备、多处理器系统、游戏机、基于微处理器的系统、机顶盒、可编程消费电子产品、移动电话、移动计算和/或可穿戴或附件形式的通信设备(例如,手表、眼镜、耳机、或耳机)、网络PC、小型计算机、大型计算机、包括上述任何系统或设备的分布式计算环境、虚拟现实(VR)设备、全息设备,等等。这样的系统或设备可以以任何方式接受来自用户的输入,包括来自诸如键盘或定点设备的输入设备、经由手势输入、接近输入(诸如通过悬停)和/或经由语音输入。
本公开的示例可以在由一个或多个计算机或其他设备以软件、固件、硬件或其组合执行的计算机可执行指令的一般上下文中描述,诸如程序模块。计算机可执行指令可以被组织成一个或多个计算机可执行组件或模块。通常,程序模块包括但不限于执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件和数据结构。本公开的多个方面可以用任何数目和组织的这种组件或模块来实现。例如,本公开的多个方面不限于特定的计算机可执行指令或图中所示出和本文所描述的特定组件或模块。本公开的其他示例可包括不同的计算机可执行指令或组件,其具有比本文所示出和描述的更多或更少的功能。在涉及通用计算机的示例中,当被配置为执行本文所描述的指令时,本公开的多个方面将通用计算机转换为专用计算设备。
作为示例而非限制,计算机可读介质包括计算机存储介质和通信介质。计算机存储介质包括以任何方法或技术实现的易失性和非易失性、可移除和不可移除存储器,用于存储诸如计算机可读指令、数据结构、程序模块等的信息。计算机存储介质是有形的,与通信介质互斥。计算机存储介质以硬件实现,不包括载波和传播信号。用于本公开目的的计算机存储介质本身不是信号。示例性计算机存储介质包括硬盘、闪存驱动器、固态存储器、相变随机存取存储器(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、闪存或其他存储技术、压缩盘只读存储器(CD-ROM)、数字多功能磁盘(DVD)或其他光存储、盒式磁带、磁带、磁盘存储装置或其他磁存储设备,或任何其他可用于存储信息以供计算设备访问的非传输介质。相比之下,通信介质通常在诸如载波或其他传输机制的调制数据信号中包含计算机可读指令、数据结构、程序模块等,并且包括任何信息传递介质。
本文所示出和描述的本公开的示例中的操作的执行或执行的顺序不是必要的,并且可以在各种示例中以不同的顺序方式执行。例如,预期在另一操作之前、同时或之后执行或执行特定操作在本公开的方面的范围内。当介绍本公开或其示例的方面的要素时,冠词“a”、“an”、“the”和“said”旨在表示存在一个或多个要素。术语“包括(comprising)”、“包括(including)”和“具有(having)”旨在是包括性的,并且意味着除了所列元素之外可能还有其他元素。术语“示例性”旨在表示“示例的”。短语“以下一项或多项:A、B和C”是指“A中的至少一个和/或B中的至少一个和/或C中的至少一个”。
已经详细描述了本公开的多个方面,显而易见的是,在不脱离如所附权利要求中限定的本公开的方面的范围的情况下,修改和变化是可能的。由于在不脱离本公开的方面的范围的情况下可以对上述构造、产品和方法进行各种改变,因此上述描述中包含的所有内容和附图中所示的所有内容都应被解释为说明性的,而不是限制性的。