基于多维度的威胁情报源可信性评估方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及网络安全技术领域,具体涉及一种基于多维度的威胁情报源可信性评估方法。
背景技术
尽管学术界和工业界当前已经在网络威胁情报理论和实践方面开展了大量工作,但是威胁情报来源广、种类多、数量大、更新快、价值高的特点,给威胁情报的可信感知带来了一系列新的问题与挑战。
威胁情报源可信性评估中信任因子考虑不足、信任因子权重分配具有主观性的问题。威胁情报共享社区是威胁情报共享的主流形式之一,但由于情报社区的开放性,不可信的情报源大量存在,研究威胁情报共享社区中情报源的可信度显得尤为重要。信任作为情报社区中最复杂的概念之一,评估威胁情报源可信性的信任因子有很多,但现有的工作往往关注少量的信任因子,没有很好地考虑社会计算中信任关系的复杂性。如何实现威胁情报源的可信性评估是大数据环境中威胁情报可信感知亟待解决的关键问题之一。
发明内容
鉴于上述问题,本发明提供了一种基于多维度的威胁情报源可信性评估方法。
本发明提供的基于多维度的威胁情报源可信性评估方法,包括:步骤S1,从威胁情报共享社区中获取待评估的任一情报源;步骤S2,分别从身份信任因子、行为信任因子、关系信任因子和反馈信任因子这四个信任因子对所述情报源进行评估,得到所述情报源在每个所述信任因子的信任度;步骤S3,通过有序加权平均和加权移动平均的组合算法,为所述情报源的每个所述信任因子分配对应的权重值;步骤S4,将所述情报源在每个所述信任因子的信任度与所述对应的权重值进行融合,计算所述情报源的总体信任度。
通过本发明的实施例提供的基于多维度的威胁情报源可信性评估方法,首先从身份信任因子、行为信任因子、关系信任因子和反馈信任因子四个方面对情报源的可信度进行了多维度的评估,然后通过有序加权平均和加权移动平均组合算法为四个信任因子动态分配权重。本发明提出的方法,超越了现有方法信任因子考虑不足、信任因子权重分配主观性等限制。基于真实数据集的实验结果表明,所提出的方法具有较高的准确性和自适应性。
附图说明
通过以下参照附图对本发明实施例的描述,本发明的上述内容以及其他目的、特征和优点将更为清楚,在附图中:
图1示意性示出了根据本发明实施例的基于多维度的威胁情报源可信性评估方法的流程图;
图2示意性示出了根据本发明实施例的情报源可信性评估模型Info-Trust系统架构;
图3示意性示出了根据本发明实施例的评估情报源在各信任因子的信任度的流程图;
图4示意性示出了根据本发明实施例的情报源的多维度信任因子的融合过程的流程图;
图5A示意性示出了根据本发明实施例的评估情报源在各信任因子的信任度的流程图;
图5B示意性示出了根据本发明实施例的评估情报源在各信任因子的信任度的算法原理;
图6示意性示出了根据本发明实施例的情报源的虚假情报的总体影响力的计算过程的流程图;
图7示意性示出了根据本发明实施例的评估情报源在关系信任因子的信任度的流程图;
图8示意性示出了根据本发明实施例的可信情报源和不可信情报源的局部集聚系数的差异解释,其中(a)为可信情报源,(b)为不可信情报源;
图9示意性示出了根据本发明实施例的可信情报源和不可信情报源的中介中心度的差异解释,其中(a)为可信情报源,(b)为不可信情报源;
图10A示意性示出了根据本发明实施例为各信任因子动态分配权重值的流程图;
图10B示意性示出了根据本发明实施例为各信任因子动态分配权重值的算法原理;
图11示意性示出了根据本发明实施例的情报源的总体信任度的算法原理。
具体实施方式
以下,将参照附图来描述本发明的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本发明的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本发明实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本发明。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
在使用类似于“A、B和C等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有A、B和C中至少一个的系统”应包括但不限于单独具有A、单独具有B、单独具有C、具有A和B、具有A和C、具有B和C、和/或具有A、B、C的系统等)。
附图中示出了一些方框图和/或流程图。应理解,方框图和/或流程图中的一些方框或其组合可以由计算机程序指令来实现。这些计算机程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,从而这些指令在由该处理器执行时可以创建用于实现这些方框图和/或流程图中所说明的功能/操作的装置。本发明的技术可以硬件和/或软件(包括固件、微代码等)的形式来实现。另外,本发明的技术可以采取存储有指令的计算机可读存储介质上的计算机程序产品的形式,该计算机程序产品可供指令执行系统使用或者结合指令执行系统使用。
在本发明的技术方案中,所涉及的用户信息(包括但不限于用户个人信息、用户图像信息、用户设备信息,例如位置信息等)和数据(包括但不限于用于分析的数据、存储的数据、展示的数据等),均为经用户授权或者经过各方充分授权的信息和数据,并且相关数据的收集、存储、使用、加工、传输、提供、公开和应用等处理,均遵守相关国家和地区的相关法律法规和标准,采取了必要保密措施,不违背公序良俗,并提供有相应的操作入口,供用户选择授权或者拒绝。
面对日益复杂化、持续化、组织化、武器化的网络攻击,世界各地越来越多的组织和个人开始利用和共享网络威胁情报以全面了解快速演变的网络威胁形势,防范网络攻击。随着威胁情报技术的快速推进,威胁情报来源广、种类多、数量大、更新快、价值高的特点给威胁情报的可信感知带来了一系列新的问题与挑战。
具体而言,随着移动终端和移动互联网的发展,很多安全公司和组织机构在情报共享社区/社交媒体上发布威胁情报。威胁情报共享社区因其用户多、传播速度快、成本低等特点,在分享和传播用户生成内容方面越来越受欢迎,成为威胁情报共享的主流形式之一。然而,情报共享社区的开放性以及情报源的匿名性使得情报社区中充斥着大量的虚假情报源,不可信的情报源甚至是恶意的情报源散布虚假情报、没有经过验证的声明、欺诈性或者虚假的评论,发起地下非法活动,这严重影响了社区中威胁情报源之间的情报共享和利用。因此,如何对情报共享社区中的情报源进行可信感知成为当前威胁情报发展中迫切需要解决的问题之一。信任计算机制是各种应用中促进决策制定的有效工具。由于情报社区以及信任概念本身的复杂性,量化情报共享中的信任是一个复杂而重要的问题。社会计算、网络安全、数据挖掘等领域研究者对信息源的信任评估问题已展开了广泛的研究,提出了一系列的新方法和新模。其中一些很具有创新性和有效性,但它们中的大多数仍面临以下两个问题需要解决:
首先,现有研究对情报源的信任评估因子考虑不足。信任作为共享社区中最复杂的概念之一,具有多标准属性。但是,现有的工作大多关注较少的信任属性,没有很好地考虑社会计算中信任关系的复杂性。从情报消费者的角度来看,信任是对情报质量保证的完整度量,信任管理系统应包含多维度的信任因子。正如现实生活中,人们对某个情报源总会从多个不同的角度考察它的可信度。通常人们会考察情报源的基本特征--情报源是谁(whois he/she?),发布的历史情报--情报源发布了什么(what did he/she post?),情报源的社会关系/网络结构--情报源的网络关系如何(how about his/her network relation?),以及用户反馈--用户对情报源的反馈如何(how about user feedback?),从而对情报源的信任度进行多角度的评估。现有研究常常忽略了基于反馈的信任因子或者基于身份的信任因子,这将导致信任评估的不准确。
其次,现有的许多机制在信任融合中使用了主观方法或者加权平均方法对信任因子赋予权重,然而这种缺乏自适应性的权重分配方法会影响信任评估的准确性。定义信任值为R(D)=λ
针对威胁情报源可信性评估中信任因子考虑不足的问题,本发明提出一种基于多维度的威胁情报源可信性评估方法。图1示意性示出了根据本发明实施例的基于多维度的威胁情报源可信性评估方法的流程图。
如图1所示,该实施例的基于多维度的威胁情报源可信性评估方法可以包括步骤S1~步骤S4。
步骤S1,从威胁情报共享社区中获取待评估的任一情报源。
步骤S2,分别从身份信任因子、行为信任因子、关系信任因子和反馈信任因子这四个信任因子对情报源进行评估,得到情报源在每个信任因子的信任度。
步骤S3,通过有序加权平均和加权移动平均的组合算法,为情报源的每个信任因子分配对应的权重值。
步骤S4,将情报源在每个信任因子的信任度与对应的权重值进行融合,计算情报源的总体信任度。
通过本发明的实施例,首先从身份信任因子、行为信任因子、关系信任因子和反馈信任因子四个方面对情报源的可信度进行了多维度的评估,然后通过有序加权平均和加权移动平均组合算法为四个信任因子动态分配权重。本发明提出的基于多维度的威胁情报源可信性评估方法,超越了现有方法信任因子考虑不足、信任因子权重分配主观性等限制。基于真实数据集的实验结果表明,所提出的方法具有较高的准确性和自适应性。
在详细描述本发明的具体实施例之前,首先对技术术语进行阐释,以便于更好地理解本发明。
系统模型与问题描述:
问题定义:情报源可信度的评估问题。定义一个有向图G∈{S|E},其中
定义1(情报源的信任度)一个情报源s
定义2(信任度的值域)一个情报源的信任度被表示为0到1之间的一个实数,1表示完全信任,0表示完全不信任,即信任度的值域为[0,1]。
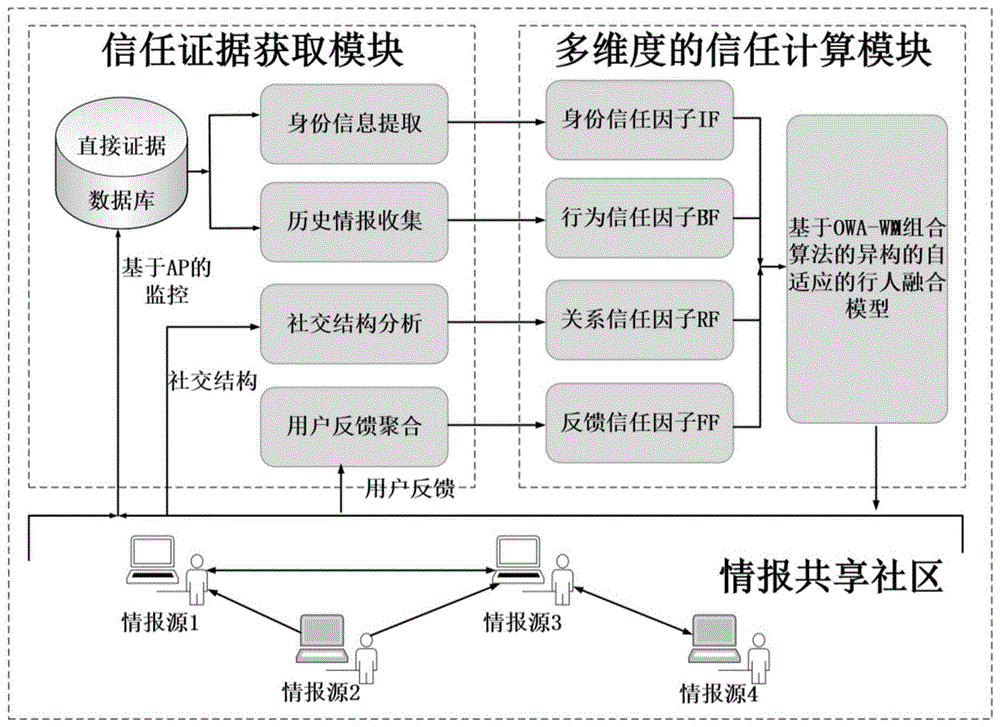
在详细介绍本发明所提出的情报源可信性评估模型Info-Trust之前,首先给出它的系统架构。图2示意性示出了根据本发明实施例的情报源可信性评估模型Info-Trust系统架构。如图2所示,Info-Trust包含两个主要模块:信任证据获取模块和多维度的信任计算模块。首先,情报源的身份信息,例如注册时长等,被提取用于计算基于身份的信任因子;通过基于API的实时监控,情报源发布的历史情报数据被收集起来,作为直接信任的重要证据,用于计算基于行为的信任因子;情报源的社交网络结构被用于评估基于关系的信任因子;用户反馈信息,例如情报的评论消息以及共享社区反馈系统收集的反馈信息等,被用于计算基于反馈的信任因子。
图3示意性示出了根据本发明实施例的评估情报源在各信任因子的信任度的流程图。
如图2和图3所示,本实施例中,上述步骤S2可以包括步骤S21~步骤S22。
步骤S21,获取情报源的身份信息、发布的历史情报数据、社交网络结构和用户反馈信息。
例如,身份信息包括注册时长。发布的历史情报数据通过基于API的实时监控来获得,包括历史发帖行为。社交网络结构包括社会关系。用户反馈信息包括情报源的评论消息以及共享社区反馈系统收集的反馈信息。
步骤S22,分别根据身份信息、发布的历史情报数据、社交网络结构和用户反馈信息,评估情报源在身份信任因子、行为信任因子、关系信任因子和反馈信任因子的信任度。
例如,情报源s
其中,
定义3(总体信任度)情报源的总体信任度(Overall Trust Degree,OTD)由以下公式计算得出:
其中,Ti表示任一情报源s
在现有研究中,分配信任权重一般有三种主观方法,即随机分配法、平均权重法和专家评定法。然而,这些方法存在一个共同的缺陷--缺乏动态适应性。一旦权重值设定好后,信任因子的权重值不能动态地自适应调整。因此,自适应地给信任因子分配权重是本发明的重要工作之一。OWA-WMA组合算法,整合了有序加权平均OWA算子和加权移动平均WMA算子,不仅考虑了各个信任因子的影响力的变化,也考虑了动态加权问题,提供了详细而准确的信任计算过程。
图4示意性示出了根据本发明实施例的情报源的多维度信任因子的融合过程的流程图。
如图4所示,本发明提出的情报源可信性评估模型Info-Trust,同时考虑了直接证据和间接证据,融合了四个维度的信任因子:基于身份的信任因子、基于行为的信任因子、基于关系的信任因子和基于反馈的信任因子,考虑了情报源的基本特征--情报源是谁(whois he/she?)、发布的历史情报--情报源发布了什么(what did he/she post?)、情报源的社会关系/网络结构--情报源的网络关系如何(how about his/her network relation?),以及用户反馈--用户对情报源的反馈如何(how about user feed back?),从而给出了情报源信任评估的全方位视图。
通过上述的实施例,本发明提供的方法,融合了多个信任因子来反映信任的复杂性和不确定性,包括情报源身份信息、情报源发布的历史情报数据、情报源的社交网络结构和用户反馈信息。这些信任因子的权重值由有序加权平均--加权移动平均(OrderedWeighted Averaging-Weighted Moving Average,OWA-WMA)组合算法动态分配,它超越了现有方法人为指定权重的主观性。基于真实数据集的仿真实验结果验证了所提机制在信任评估中的准确性和自适应性。
接下来,分别针对上述步骤S22详细说明如何评估情报源在身份信任因子、行为信任因子、关系信任因子和反馈信任因子的信任度。
基于身份信任因子的信任度
图5A示意性示出了根据本发明实施例的评估情报源在各信任因子的信任度的流程图。图5B示意性示出了根据本发明实施例的评估情报源在各信任因子的信任度的算法原理。
如图5A和图5B所示,本实施例中,在上述步骤S22,可以根据身份信息,通过以下步骤S2211~步骤S2214评估情报源在身份信任因子的信任度。
步骤S2211,针对威胁情报共享社区的任一情报源s
研究表明,社交媒体中信源的信任度与信源的身份信息相关,虚假信息很可能由网络机器人产生并传播。通常,通过认证的信息源比匿名信息源更值得信任。因此,本发明根据情报源s
步骤S2212,根据以下公式计算情报源s
其中,R(s
在情报共享社区网络中,一些有目的的专为传播虚假情报的账号被创建,例如网络机器人。传播真实情报的情报源的注册时长通常比那些传播虚假情报的情报源的注册时长要长。情报源s
步骤S2213,根据以下公式计算情报源s
其中,NoFlw(s
通常,情报源的关注者数量体现它的受欢迎程度和可信度。情报源的关注者数量越大,即该节点在网络中的入度越大,通常预示着越多的用户信任这个情报源并且乐于接受其发布的信息。因此,本发明将情报源s
步骤S2214,根据以下公式计算情报源s
其中,Follower(i)表示情报源s
PageRank算法根据全网网页拓扑关系计算了网页节点的权威度。受PageRank算法的启发,本发明定义了情报源s
步骤S2215,计算情报源s
因此,情报源s
基于行为信任因子的信任度
在情报共享社区网络中,情报源的历史发布行为是情报源可信度评估的一个重要依据。尽管不可信情报源和可信情报源在“每个情报帖子的点赞(like)数量”、“每个情报帖子的分享(share)数量”等特征上没有显著差异,但是其发布的虚假情报和可信情报在这两个特征维度上是有显著差异的。
定义4(行为信任因子的信任度)本实施例中,在上述步骤S22,根据发布的历史情报数据,根据以下公式评估情报源在行为信任因子的信任度
其中,Q
可以看出,在本发明所提模型Info-Trust中,情报源的行为信任因子记作
图6示意性示出了根据本发明实施例的情报源的虚假情报的总体影响力的计算过程的流程图。
如图6所示,特别地,针对情报源s
步骤S601,提取情报源s
例如,将虚假情报f的likes、shares、mentions数作为评估I
步骤S602,分别使用喜爱数NoLik(f)、分享数NoShr(f)和提及数NoMet(f),根据以下公式计算情报源s
首先,使用likes数NoLik(f)来计算情报源的第一发帖影响力LK
步骤S603,计算第一发帖影响力LK
最后,得到情报源s
I
基于关系信任因子的信任度
图7示意性示出了根据本发明实施例的评估情报源在关系信任因子的信任度的流程图。
如图7所示,本实施例中,在上述步骤S22,根据社交网络结构,通过以下步骤S2221~步骤S2223评估情报源在关系信任因子的信任度。
步骤S2221,应用图理论,根据以下公式计算情报源s
其中,
在情报共享社区网络中,可信的情报源通常与其他情报源有较强的网络结构关联关系。相反,不可信的情报源通常盲目地关注其他情报源,与其他情报源有着较弱的网络结构关联关系。将情报共享社交网络中的每个情报源视为一个节点,则所有情报源构成一个图。为了量化一个情报源的邻居节点形成一个团(完全图)的紧密程度,本发明应用图理论中的一种度量--局部集聚系数(local clustering cofficient)。一个节点的局部集聚系数,是它的相邻节点之间的连接数与它们所有可能存在连接的数量的比值。
图8示意性示出了根据本发明实施例的可信情报源和不可信情报源的局部集聚系数的差异解释,其中(a)为可信情报源,(b)为不可信情报源。
如图8中(a)所示,三个不同的虚线三角形表示“可信源”节点的邻居之间的三种关系,并且该“可信源”节点的局部集聚系数为LC(s
步骤S2222,在有向图中,根据以下公式计算情报源s
其中,δ
相比可信的情报源,恶意的情报源通常随机关注大量无关的情报源来获取丰富的社会关系,从而在其关注的情报源之间形成了大量的最短路径。为了量化这个特征,本发明采用中介中心度BC(s
图9示意性示出了根据本发明实施例的可信情报源和不可信情报源的中介中心度的差异解释,其中(a)为可信情报源,(b)为不可信情报源。
如图9中(a)所示,较细粒度点线和较粗粒度点线表示经过“可信源”节点s
定义5(关系信任因子的信任度)步骤S2223,使用局部集聚系数LC(s
需要说明的是,恶意情报源或许会认真地筛选它所要关注的情报源,从而使它的局部集聚系数和中介中心度更接近可信的情报源的值。然而,该操作的实现需要耗费恶意情报源大量的时间、金钱和精力,同时也大量减少了其关注的情报源的数量。另外,考虑到在大型图(例如整个Twitter社交网络图)上精准地计算这两个评估指标较为耗时,邻居采样技术能允许分块计算这两个评估指标,从而以一种近似的轻量级的方式计算出这两个评估指标。
基于反馈信任因子的信任度
大多数情报共享平台为平台用户提供了反馈功能,用户可以将其发现的恶意情报源或恶意情报向平台举报。用户的反馈数据对情报源的可信评估非常重要,然而该反馈数据却没有被给予足够的重视甚至被忽视。考虑到恶意反馈,本发明所提模型只利用可信用户提供的反馈。也就是说,只有总体信任度不低于预先设定的阀值(根据经验,设定为0.6)的用户提供的反馈信息才能被采纳。
对于一个大型情报共享社交网络环境--拥有百万级的情报源且每秒处理数以千计的信息发布,由信任系统引发的延迟将是一个具有挑战性的重要问题。因此,反馈聚合机制的高效计算性是本发明所提模型的基本需求。由此,本发明提出了一种轻量级的反馈聚合机制。
定义6(反馈信任因子的信任度)本实施例中,在上述步骤S22,根据用户反馈信息,根据以下公式评估情报源在反馈信任因子的信任度
其中,ρ
在公式(1-14)中,当ρ
至此,根据前述公式(1-2),在计算出情报源s
OWA-WMA算法,是OWA算子和WMA模型的组合,综合考虑了不同因子的影响程度以及动态加权问题。决策制定者仅仅需要根据聚合场景调整参数,系统将能够给出融合计算后的结果。因此,在Info-Trust信任机制中,OWA-WMA算法给各个信任因子赋权重。其中,OWA算子给不同的信任因子赋予不同的权重,WMA模型以移动平均的方式对最新的历史信任度进行累加求和。
定义7(OWA算子)形式上地,一个n维的OWA算子是一个映射F:R
其中,P
为了确定所有信任因子的权重向量W的值,可以利用不同的聚合算子。OWA算子提供了一个平均类型的聚合算子。OWA算子是一个非线性算子,其结果来自确定w
基于此,图10A示意性示出了根据本发明实施例为各信任因子动态分配权重值的流程图。图10B示意性示出了根据本发明实施例为各信任因子动态分配权重值的算法原理。
如图10A和图10B所示,本实施例中,上述步骤S3包括以下步骤S31~步骤S36。
步骤S31,预先设置参数n=4,参数λ∈[0,1]。
例如,可以将参数n记为第一参数,参数λ记为第二参数。
步骤S32,判断参数λ是否小于0.5,如果是,则以1-λ作为更新后的参数λ。
步骤S33,根据以下公式计算所有信任因子的权重向量中的权重值w
w
(1-16)
步骤S34,基于权重值w
步骤S35,根据以下公式计算所有信任因子的权重向量中的其他权重值w
步骤S36,根据权重值w
在上述公式中,参数λ的值域为[0,1],被视为信任机制中确定集合{p
定义8(WMA模型)WMA模型具有算术变化的权重,其计算方式如下:
其中,F(U)是序列U的融合函数,i是用于计算加权平均的数据项的编号,U
图11示意性示出了根据本发明实施例的情报源的总体信任度的算法原理。
综上,情报源的总体信任度OTD的计算过程可以表示为图11中的算法1-3。另外,为使情报用户能对情报源s
表1总体信任度和信任级别之间的映射关系
附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或流程图中的每个方框、以及框图或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
本领域技术人员可以理解,本发明的各个实施例和/或权利要求中记载的特征可以进行多种组合或/或结合,即使这样的组合或结合没有明确记载于本发明中。特别地,在不脱离本发明精神和教导的情况下,本发明的各个实施例和/或权利要求中记载的特征可以进行多种组合和/或结合。所有这些组合和/或结合均落入本发明的范围。
以上对本发明的实施例进行了描述。但是,这些实施例仅仅是为了说明的目的,而并非为了限制本发明的范围。尽管在以上分别描述了各实施例,但是这并不意味着各个实施例中的措施不能有利地结合使用。本发明的范围由所附权利要求及其等同物限定。不脱离本发明的范围,本领域技术人员可以做出多种替代和修改,这些替代和修改都应落在本发明的范围之内。