一种融合句法和实体关系图卷积网络的事件联合抽取方法
文献发布时间:2023-06-19 09:24:30
技术领域
本发明涉及一种融合句法和实体关系图卷积网络的事件联合抽取方法,属于大数据挖掘和社会信息处理技术领域。
背景技术
事件信息抽取是社会信息处理、自然语言处理,以及大数据挖掘等领域的重要研究课题。事件信息抽取任务包含两个子任务:候选触发词识别和分类、候选论元识别和分类。它旨在于面向非结构化文本,研制对事件的结构化信息的抽取方法。通过候选触发词识别和分类子任务抽取文本中包含的事件类型,通过候选论元识别和分类子任务抽取时间、地点、参与者和目标等论元或事件要素。事件信息抽取在问答系统、舆情监控、意见挖掘和突发事件检测等领域具有广泛的应用前景。
事件信息抽取方法包括基于模式匹配的方法、基于机器学习的方法,以及基于深度学习的方法。基于模式匹配的事件信息抽取方法是指首先构建不同事件类型的抽取模式或规则,然后根据文本所匹配的模式或规则抽取事件信息。基于机器学习的事件信息抽取方法是指将事件信息抽取任务转化为候选触发词分类问题和候选论元分类问题,然后通过训练的支持向量机、条件随机场或最大熵等分类器实现事件信息抽取。基于深度学习的方法主要包括基于双向长短时记忆网络、动态记忆网络、图卷积网络、生成式对抗网络等深度神经网络模型来抽取事件信息。另外,从候选触发词识别和分类与候选论元识别和分类两个子任务处理方式来看,事件信息抽取方法分为基于流水线模型和基于联合模型的方法。基于流水线模型的事件信息抽取方法是指首先进行候选触发词识别和分类,然后进行论元识别和分类。基于联合模型的事件信息抽取方法是指,对于候选触发词识别和分类子任务与候选论元识别和分类子任务,将这两个子任务集成在同一深度学习模型下训练,降低基于流水线模型的事件信息抽取方法产生的误差传播。
图神经网络(Graph Neural Network)是指面向图数据的深度学习或深度神经网络学习方法,广泛应用于语音识别、机器翻译、目标检测,以及自然语言处理等众多领域。图神经网络可以分为图卷积网络、图注意力网络、图自编码器、图生成网络,以及图时空网络。图卷积网络(Graph Convolutional Network,简称GCN)是通过将问题建模为图数据,在图数据上进行卷积运算的深度神经网络,其目的是学习目标结点的低维嵌入表示。
事件信息抽取是信息抽取领域的重要研究内容。目前,事件信息抽取面临的主要挑战包括文本语义复杂和模型泛化能力弱等问题。
发明内容
本发明的目的在于针对现有基于机器学习和深度学习的事件信息抽取方法存在误差传播和模型泛化能力弱的技术缺陷,提出了一种融合句法和实体关系图卷积网络的事件联合抽取方法,该方法提出了一种事件信息抽取的联合框架,挖掘“候选触发词识别和分类”子任务与“候选论元识别和分类”子任务之间信息的依赖关系;并基于两个子任务进行候选触发词分类和候选论元分类,建立联合模型,提取测试集中句子的事件信息。
其中,候选触发词识别和分类是识别出句子中的事件候选触发词,并对候选触发词所表示的事件类型进行分类,采用一种基于句法图卷积网络和位置自注意力机制;句法图卷积网络是指将句法关系引入到图卷积网络中,为句子中每个词语的分类特征引入句法依存关系;
候选论元识别和分类是在识别句子的事件类型的基础上,识别事件论元即事件要素,并对论元所承担的事件角色进行分类,事件角色包括时间、地点、攻击者和受害者等,基于实体关系图卷积网络,利用图卷积网络提取实体之间的关系作为论元分类的特征。
为达到上述的目的,本发明采取如下技术方案。
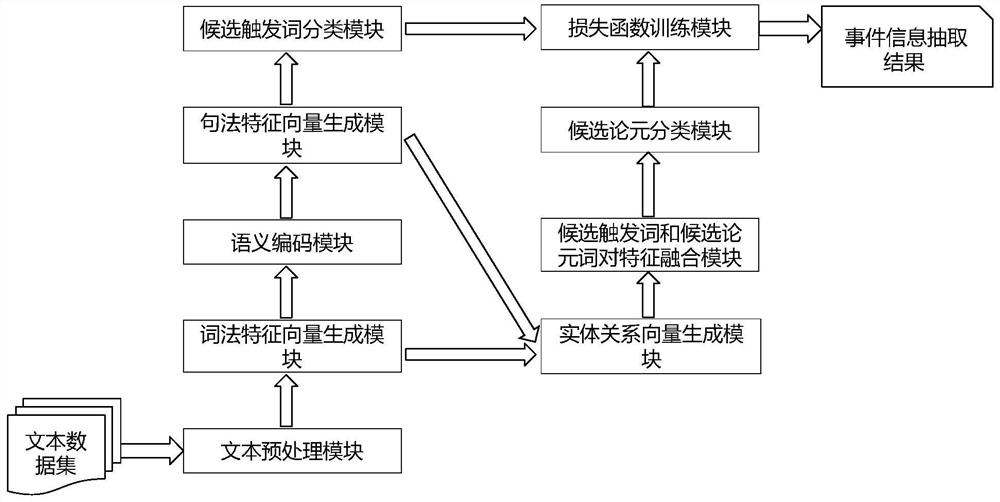
所述事件联合抽取方法依托的联合模型,包括文本预处理模块、词法特征向量生成模块、语义编码模块、句法特征向量生成模块、候选触发词分类模块、实体关系向量生成模块、候选触发词和候选论元词对特征融合模块、候选论元分类模块以及损失函数训练模块;
所述联合模型中各模块的连接关系如下:
文本预处理模块与词法特征向量生成模块相连,词法特征向量生成模块语义编码模块相连,语义编码模块与句法特征向量生成模块相连;句法特征向量生成模块与候选触发词分类模块相连;候选触发词分类模块与损失函数训练模块相连;
词法特征向量生成模块、句法特征向量生成模块与实体关系向量生成模块相连;实体关系向量生成模块与候选触发词和候选论元词对特征融合模块相连,候选触发词和候选论元词对特征融合模块与候选论元分类模块相连,候选论元分类模块与损失函数训练模块相连。
所述事件联合抽取方法,包括以下步骤:
步骤1:文本预处理模块对训练集中的句子进行文本预处理,获得预处理后的训练集;
其中,文本预处理包括:实体标注、词性标注以及获取句法依存关系树;
其中,实体标注的类型包括设施、人名、地名、机构名、地缘政治实体、工具和武器七大类;
其中,预处理训练集中包括若干句子,记为句子S=w
步骤2:词法特征向量生成模块基于词向量模型对步骤1预处理后的训练集中的句子词语生成词语嵌入、词性标注嵌入、实体类型嵌入和位置嵌入,这四种嵌入拼接构建为词语的词法特征向量,再对句子中所有词语的词法特征向量进行堆叠,构建句子词法矩阵;
步骤3:语义编码模块利用双向长短时记忆网络LSTM对步骤2构建的句子词法矩阵进行语义编码,获取词语之间的长短期依赖关系;
其中,LSTM,即Long-short term memory network;
步骤4:句法特征向量生成模块根据句法依存关系树信息通过句法图卷积网络生成词语的句法特征向量,并与步骤2构建的词语的词法特征向量进行拼接;进一步句法特征向量生成模块对句子中所有词语的句法特征向量和词法特征向量进行堆叠,获得句子的词法和句法矩阵M;
为了对每层图卷积网络GCN传播之后的结点信息能够尽可能最大化保留上一层结点信息,分别对上一层结点的原始信息和非线性转换后信息的保留程度进行学习。
步骤5:识别步骤1文本预处理后的训练集中句子的候选触发词、计算重要性得分、生成上下文向量并堆叠,候选触发词分类模块再基于堆叠产生的上下文矩阵对候选触发词进行分类,具体为:
步骤5.1:将经过步骤1文本预处理得到的句子S的任意词语作为候选触发词,即,将w
步骤5.2:对于句子S=w
score
其中,score
位置嵌入是候选触发词和其他词语之间相对距离的向量表征,具体为:候选触发词w
步骤5.3:对于候选触发词w
其中,M
进一步,对句子S中所有词语的上下文向量进行堆叠,构建为句子S的上下文矩阵表示M
步骤5.4:将句子S的上下文矩阵M
步骤6:实体关系向量生成模块构建实体关系图卷积网络,获取实体结点的聚合特征向量,生成实体关系向量,具体为:
步骤6.1:提取步骤1预处理后的训练集中所有句子的实体,由这些实体作为结点构建实体关系图卷积网络;
步骤6.2:设置实体关系图卷积网络的实体结点和关联边的初始特征向量;利用图卷积网络聚合函数AGGREGATE,对实体关系图卷积网络中每一个实体结点的所有邻居结点的特征进行聚合,生成该实体结点的聚合特征向量;
步骤6.3:将每一个实体结点的初始特征向量与聚合特征向量进行拼接,经过非线性函数转换生成实体关系向量;
步骤7:候选触发词和候选论元词对特征向量构建模块提取句子中的候选论元,构建(候选触发词,候选论元)词对的特征向量,具体为:
步骤7.1:将句子S中的所有实体,提取为候选论元;
步骤7.2:对于句子S中的每个候选触发词和每个候选轮元,构建(候选触发词,候选论元)词对的特征向量;
其中,候选触发词和候选论元两者不同;特征向量是对候选触发词的词法特征向量和句法特征向量,与候选论元的词法特征向量和句法特征向量进行拼接获取;
步骤8:候选论元分类模块对(候选触发词,候选论元)词对特征向量,以及候选论元的实体关系向量进行拼接,并将其输入到全连接层和Softmax层;将(候选触发词,候选论元)词对进行分类,识别候选论元在候选触发词所属的事件中承担的事件角色;
步骤9:损失函数训练模块训练候选触发词分类模型和候选论元分类模型,具体为:
对于候选触发词识别和分类阶段与候选论元识别和分类阶段,
步骤9.1采用交叉熵损失函数计算“候选触发词识别和分类”与“候选论元识别和分类”两个阶段的损失函数;
其中,“候选触发词识别和分类”阶段的损失函数为交叉熵损失函数,记为l
步骤9.2根据重要性系数构造事件抽取联合框架损失函数l;
其中,事件抽取包含两个多分类任务:候选触发词识别和分类、候选论元识别和分类;
其中,损失函数l为交叉熵损失函数,具体体现在公式(3):
l=αl
其中,l为事件抽取联合框架的损失函数,α为“候选触发词识别和分类”的重要性系数,β为“候选论元识别和分类”的重要性系数;
步骤10:提取测试集中句子的事件信息,具体为:
基于测试集依次进行:步骤1的文本预处理,步骤2生成句子词语的词法特征向量,步骤3基于长短时记忆网络对句子词法矩阵进行语义编码,步骤4生成句子词语的句法特征向量,步骤5的候选触发词分类,步骤6基于实体关系图卷积网络生成实体关系向量,步骤7构建(候选触发词,候选论元)词对的特征向量,步骤8的候选论元分类,利用步骤9训练的候选触发词分类模型和候选论元分类模型提取测试集句子的事件信息,完成事件触发词识别和分类与论元识别和分类。
有益效果
本发明一种融合句法和实体关系图卷积网络的事件联合抽取方法,与现有事件信息抽取方法:基于模式匹配的方法、基于机器学习的方法、基于深度学习的方法相比,具有如下有益效果:
1.所述事件联合抽取方法具有灵活性,一方面,不仅能够提供候选触发词识别和分类的独立功能与候选论元识别和分类的独立功能,而且能够提供候选触发词识别和分类、候选论元识别和分类的联合功能,另一方面,能够处理英语、汉语等多种自然语言文本的事件信息抽取;
2.所述事件联合抽取方法提高了候选触发词以及候选论元分类的性能,具体为:
2.a)融合句法图卷积网络和实体关系图卷积网络,句法图卷积网络利用图卷积网络对句法依存关系建模,获取句子中词语之间的句法关系,生成词语的句法依存特征;引入句法图卷积网络到候选触发词识别和分类子任务中,增强了候选触发词的分类特征,有助于解决文本语义信息复杂,难以获取词语的句法结构特征的问题;引入的位置自注意力机制区分了候选触发词和句子其他词语的关联程度,挖掘了多事件语句中候选触发词的关联关系,提高了候选触发词分类的性能;
2.b)实体关系图卷积网络是通过图卷积网络提取实体之间的关系作为候选论元分类的特征;在实体关系图卷积网络中,将每对实体视为一级邻居,提取候选论元和句子中所有其他实体之间的关联特征,挖掘实体关系作为论元分类特征,增强了论元的分类特征,提高了论元分类的性能;
3.所述事件联合抽取方法具有鲁棒性,具体为:通过设置联合损失函数使得候选触发词识别和分类、候选论元识别和分类两个子任务在神经网络的反向传播过程中获得训练来拟合模型,不仅提高了事件抽取的性能,而且能够提取一个句子中包含多个事件的事件类型和论元角色;
4.所述事件联合抽取方法能够提取结构化的事件信息,在舆情监控、突发事件检测、意见挖掘等领域具有广阔的应用前景。
附图说明
图1为本发明及实施例一种融合句法和实体关系图卷积网络的事件联合抽取方法的流程示意图。
具体实施方式
下面结合实施例对本发明的融合句法和实体关系图卷积网络的事件联合抽取方法的优选实施方式进行详细说明。
实施例1
基于本发明所述事件联合抽取方法的事件信息抽取系统以PyCharm为开发工具,Python为开发语言。
本实施例叙述了采用本发明所述的一种融合句法和实体关系图卷积网络的事件联合抽取方法的流程,如图1所示。
从图1可以看出,具体包括如下步骤:
步骤1:文本预处理模块对训练集中的句子进行文本预处理,获得预处理后的训练集;
其中,文本预处理包括:实体标注、词性标注以及获取句法依存关系树;
其中,实体标注的类型包括设施、人名、地名、机构名、地缘政治实体、工具和武器七大类;
其中,预处理训练集中包括若干句子,记为句子S=w
例如,文本预处理工具为Stanford CoreNLP工具;
例如,对于句子“I used to work there.”,实体标注结果为:“[('I','PER'),('used','O'),('to','O'),('work','O'),('there','ORG'),('.','O')]”;词性标注结果为“[('I','PRP'),('used','VBD'),('to','TO'),('work','VB'),('there','RB'),('.','.')]”;句法依存关系树识别结果为“[('ROOT',0,2),('nsubj',2,1),('mark',4,3),('xcomp',2,4),('advmod',4,5),('punct',2,6)]”。
步骤2:词法特征向量生成模块基于词向量模型对步骤1预处理后的训练集中的句子词语构建词语嵌入、词性标注嵌入、实体类型嵌入和位置嵌入,拼接这四种嵌入构建为词语的词法特征向量,再对句子中所有词语的词法特征向量进行堆叠,构建句子词法矩阵;
例如,词向量模型为Glove。对于句子“I used to work there.”中的词语“work”,该词语的词语嵌入为(-0.1256,0.0136,0.1031,-0.1012,0.0981,0.1363,-0.1072,0.2370,0.3287,-1.6785]),词性标注嵌入为([0.1156,-0.1296,0.1270,-0.1310,0.0217,-0.1159,-0.1182,-0.1105,-0.0051,0.1477]),实体类型嵌入为([-0.1430,0.7867,0.5322,0.0754,-0.2166,0.4625,0.2722,0.5974,-0.5920,-0.9014]),位置嵌入为([0.0136,-0.1259,0.1227,0.1230,0.0968,0.0116,-0.1423,-0.1137,-0.0486,0.1252])。
步骤3:语义编码模块利用长短时记忆网络LSTM对步骤2构建的句子词法矩阵进行语义编码,获取词语之间的长短期依赖关系,输出句子的隐藏状态;
其中,LSTM,即Long-short term memory network;
步骤4:句法特征向量生成模块根据句法依存关系树信息通过句法图卷积网络构建词语的句法特征向量,并与步骤2构建的词语的词法特征向量进行拼接;进一步句法特征向量生成模块对句子中所有词语的句法特征向量和词法特征向量进行堆叠,获得句子的词法和句法矩阵M,具体为:
步骤4.1:将步骤3输出的句子隐藏状态输入到句法图卷积网络。基于句法图卷积网络,句法特征向量生成模块生成句子的任意词语的句法特征向量;
句法图卷积网络是指将句法依存关系引入到图卷积网络中。句法依存关系是表示句子中两个词语的句法依赖关系。例如,“dobj(left,airport)”表示词语left和airport之间的句法依存关系为dobj,即直接宾语关系。
句法图卷积网络中边的类型共有三种:正向边、反向边和自回路。在句法图卷积网络中,对于词语结点u
例如,对于句子“I used to work there.”中的词语“work”,该词语的句法特征向量为([0.3503,1.0601,0.2506,0.4199,0.1480,0.8078,0.1819,1.3246,1.3067,0.4503])。
步骤4.2:将步骤4.1生成的词语的句法特征向量,与步骤2构建的词语的词法特征向量进行拼接;然后句法特征向量生成模块对句子中所有词语的句法特征向量和词法特征向量进行堆叠,获得句子的词法和句法矩阵M;
为了对每层图卷积网络GCN传播之后的结点信息能够尽可能最大化保留上一层结点信息,分别对上一层结点的原始信息和非线性转换后信息的保留程度进行学习。
步骤5:识别步骤1文本预处理后的训练集中句子的候选触发词、计算重要性得分、生成上下文向量并堆叠,候选触发词分类模块再基于堆叠产生的上下文矩阵对候选触发词进行分类,具体为:
步骤5.1:将经过步骤1文本预处理得到的句子S的任意词语作为候选触发词,即,将w
步骤5.2:对于句子S=w
score
其中,score
位置嵌入是候选触发词和其他词语之间相对距离的向量表征,具体为:候选触发词w
步骤5.3:对于候选触发词w
其中,M
进一步,对句子S中所有词语的上下文向量进行堆叠,构建为句子S的上下文矩阵表示M
步骤5.4:将句子S的上下文矩阵M
例如,对于句子:“I used to work there”,其候选触发词分类结果:[‘O’,‘O’,‘O’,’Personnel:End-Positio’,’O’,’O’]。
步骤6:实体关系向量生成模块构建实体关系图卷积网络,获取候选论元之间的关系,生成实体关系向量;
其中,候选论元为句子中的任意实体;
步骤6.1:提取步骤1预处理后的训练集中所有句子的实体,由这些实体作为结点构建实体关系图卷积网络;
步骤6.2:设置实体关系图卷积网络的实体结点的初始特征向量和和关联边的初始值;
首先,初始时,假设任意一对实体之间都具有关联关系,也就是,图卷积网络是全连接图。任意一对实体之间的边权重初始值设为1。对于结点p,其初始向量
其中,v
然后,利用图卷积网络聚合函数AGGREGATE,对实体关系图卷积网络中每一个实体结点的所有邻居结点的特征进行聚合,生成该实体结点的聚合特征向量;
对于结点p,生成结点p的聚合特征向量
其中,N(p)表示结点p的邻居结点集合,q为结点p的邻居结点,
步骤6.3:将每一个实体结点的初始特征向量与聚合特征向量进行拼接,经过非线性函数转换生成实体关系向量;
对于结点p,对其初始特征向量
其中,f为非线性函数,X为权重矩阵,CONCAT表示拼接操作。
步骤7:候选触发词和候选论元词对特征向量构建模块提取句子中候选论元,构建(候选触发词,候选论元)词对的特征向量,具体为:
步骤7.1:对于句子S中的所有实体,提取为候选论元;
步骤7.2:对于句子S中的每个候选触发词和每个候选轮元,构建(候选触发词,候选论元)词对的特征向量;
其中,候选触发词和候选论元两者不同;特征向量是对候选触发词的词法特征向量和句法特征向量,与候选论元的词法特征向量和句法特征向量进行拼接获取;
例如,对于句子S中的候选触发词w
步骤8:候选论元分类模块对(候选触发词,候选论元)词对特征向量,以及候选论元的实体关系向量进行拼接,并将其输入到全连接层和Softmax层;将(候选触发词,候选论元)词对进行分类,识别候选论元在候选触发词所属的事件中承担的事件角色;
例如,对于“I used to work there.”,其事件类型为:"Personnel:End-Position",候选触发词为:{"text":"work","start":3,"end":4},候选论元为:["I","there"],论文角色为:"arguments":[{"role":"Person","entity-type":"PER:Individual","text":"I","start":0,"end":1},{"role":"Entity","entity-type":"ORG:Media","text":"there","start":4,"end":5}]。
步骤9:损失函数训练模块训练候选触发词分类模型和候选论元分类模型,具体为:
对于候选触发词识别和分类阶段与候选论元识别和分类阶段,
步骤9.1采用交叉熵损失函数计算“候选触发词识别和分类”与“候选论元识别和分类”两个阶段的损失函数,
其中,“候选触发词识别和分类”阶段的损失函数为交叉熵损失函数,记为l
步骤9.2根据重要性系数构造事件抽取联合框架损失函数l;
其中,事件抽取包含两个多分类任务:候选触发词识别和分类、候选论元识别和分类;
其中,损失函数l为交叉熵损失函数,具体体现在公式(6):
l=αl
其中,l为事件抽取联合框架的损失函数,α为“候选触发词识别和分类”的重要性系数,β为“候选论元识别和分类”的重要性系数:
步骤10:提取测试集中句子的事件信息,具体为:
基于测试集依次进行:步骤1的文本预处理,步骤2生成句子词语的词法特征向量,步骤3基于长短时记忆网络对句子词法矩阵进行语义编码,步骤4生成句子词语的句法特征向量,步骤5的候选触发词分类,步骤6基于实体关系图卷积网络生成实体关系向量,步骤7构建(候选触发词,候选论元)词对的特征向量,步骤8的候选论元分类,利用步骤9训练的候选触发词分类模型和候选论元分类模型提取测试集句子的事件信息,完成事件触发词识别和分类与论元识别和分类。
为说明本发明的事件信息抽取效果,本实验是在同等条件下,以相同的训练集和测试集分别采用两种方法进行比较。第一种方法是基于双向循环神经网络的事件信息联合抽取方法,第二种是本发明的事件信息抽取方法。
事件信息抽取采用的评测指标为:准确率、召回率和F1值。事件信息抽取的结果为:对于已有技术的基于双向循环神经网络的事件信息联合抽取方法,其触发词分类的准确率约为66.0%,召回率约为73.0%,F1值约为69.3%;论元分类的准确率约为54.1%,召回率约为56.7%,F1值约为55.4%;采用本发明方法的触发词分类的准确率约为73.2%,召回率约为76.3%,F1值约为74.5%;论元分类的准确率约为66.5%,召回率约为55.8%,F1值约为60.9%。通过实验表明了本发明提出的一种融合句法和和实体关系图卷积网络的事件联合抽取方法的有效性。
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 一种融合句法和实体关系图卷积网络的事件联合抽取方法
- 一种融合句法和实体关系图卷积网络的事件联合抽取方法