一种基于空间交互关系的土壤重金属风险识别方法
文献发布时间:2023-06-19 09:43:16
技术领域
本发明属于土壤重金属风险识别领域,具体涉及一种基于空间交互关系的土壤重金属风险识别方法。
背景技术
我国政府非常重视土壤污染问题,开展了一系列土壤污染调查,包括重点排污单位名录、土壤环境重点企业监管名单和全口径涉重金属重点行业企业清单等,极大地提高了管理者和大众了解土壤环境污染相关企业,这同时也为技术和科研工作者提供了大量的污染企业信息来源。但是,这些数据均只有所在省市县和企业名称等信息,如何获取数据的经纬度信息和注册年份信息难度相对较大。
越来越多的学者开始研究土壤重金属与污染企业之间的空间关系,进而为土壤重金属污染溯源提供证据链。例如,Jiang等运用多元和地统计学方法确定了鄱阳湖地区土壤重金属的来源;Shao等运用正定矩阵分解和主成分分析方法定量计算了自然源和人为源对土壤重金属污染的贡献。然而,传统的源解析方法,如多元和地统计分析,主成分分析、正定矩阵分解等,在一定程度上都忽略了土壤重金属的空间污染特征,部分地区有可能得出相反的结果,难以有效和精准的指导土壤重金属管理。此外,土壤重金属污染往往与人为活动密切相关,尤其是污染企业,使用传统的源解析方法没有提供源汇之间可靠的空间耦合关系,对于污染的空间变异性也不能很好的解决,这使得目前由污染企业引起的土壤重金属污染防控治理工作变得相当艰难。
原农业部、国土部和环保部等相继出台了一些关于土壤重金属污染分区管理的技术规定或标准,但这些分区管理办法仅仅考虑到土壤重金属污染水平,而忽略了土壤重金属污染的风险,比如由于污染企业引起的土壤污染风险。幸运的是,一些研究开始考虑基于风险的污染土地管理。如Jiang等在综合考虑农业污染源、污染受体和社会经济的情境下,将农业污染区进一步分为高脆弱性区、高脆弱性高危害区和优先调查区。Jia等运用模糊K均值聚类方法将研究区土壤重金属污染划分为3个子区域,分别为高风险区、中度风险区和安全区。然而,这些研究仅基于土壤污染的确定性风险,而忽略了污染的空间交互关系。
因此,运用双变量局部莫兰指数建立土壤重金属与污染企业之间的空间交互关系,同时考虑土壤重金属污染水平和受体脆弱性水平,对于科学合理的土壤重金属风险识别和划分土壤重金属管理分区,以及指导政策制定者和利益相关者管控土壤重金属污染具有迫切的现实意义。
发明内容
本发明的目的在于解决现有技术中存在的问题,并提供一种基于空间交互关系的土壤重金属风险识别方法。
本发明所采用的具体技术方案如下:
一种基于空间交互关系的土壤重金属风险识别方法,其具体如下:
S1:基于http协议与公开网页端获得待研究区域的全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单、重点排污单位名录、企业POI数据、工商要素补充数据和遥感影像;其中,全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录均包括企业名称及其所属地市,企业POI数据包括企业名称及其经纬度信息;工商要素补充数据包括企业名称、经营范围、成立年份和注册地址;
S2:将S1中全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录的特征信息转换为结构化数据;根据工商要素补充数据和和企业POI数据,对两个数据中的企业名称分别进行分词处理,之后进行匹配,使得每个企业的基本信息与其地理位置信息相对应,得到含地理位置的企业基本信息关联数据;
S3:将S2中每个企业基本信息关联数据与遥感影像上的点位信息对应匹配,以获得每个污染企业及其周边场地的高分辨率遥感影像;然后使用基于深度学习的图像语义分割技术,对每个污染企业对应的遥感影像数据进行建筑物的特征提取,以判断该区域是否存在建筑或者企业工厂,实现污染企业分布情况与其企业基本信息关联数据的相似度匹配,得到污染企业点位数据;
S4:使用核密度法对S3中获取的污染企业点位数据进行核密度分析;运用反距离加权法预测研究区域内土壤重金属空间分布,并对土壤重金属风险级别进行划分;根据研究区域的研究边界生成特定规模的网格以及对应的网格点,基于网格点统计网格内土壤重金属风险级别与污染企业密度值;对土壤重金属风险级别与污染企业密度值进行双变量局部空间自相关分析,得到土壤重金属与污染企业的空间交互关系;
S5:根据所述土壤重金属风险、研究区域的受体脆弱性和空间交互关系,对研究区域进行风险识别。
作为优选,所述S1中,全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录均以PDF、word或图片格式存在。
进一步的,所述S2中,将全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录中以非结构化文档数据PDF、word或图片格式存在信息,使用OCR技术将其识别为基于Office Open XML标准的压缩文件格式,转换为结构化数据。
作为优选,所述S2中,特征信息包括企业名称、经营范围和地址。
作为优选,所述S2中,根据工商要素补充数据和企业POI数据,分别对两个数据中的企业名称使用分词引擎jieba分词处理,将其分词成“城市”+“企业名”+“行业名”+“后缀”四项;
若两个数据中的企业名称经分词处理后的四项完全匹配,则将该信息输出,并得到含地理位置的企业基本信息关联数据;
若两个数据中的企业名称经分词处理后的四项不完全匹配,提取工商要素补充数据中注册地址字段,使用高德API接口查询得到以GCJ-02坐标系表示的地理位置信息和位置范围,并与企业名称进行匹配,得到含地理位置的企业基本信息关联数据。
作为优选,所述S3的具体方法如下:
根据每个企业的基本信息关联数据及其对应遥感影像上的点位信息,对每个企业赋予经纬度信息,并获取该点位周边相应的遥感影像;通过获取的遥感影像进行数据的预处理,并生成相应的标注数据,对U-Net卷积神经网络模型进行训练建模;将训练好的U-Net卷积神经网络模型在研究区进行测试验证,模型对相应点位的影像进行图像分割,返还的结果图中的每个像元只有建筑与非建筑两类;若返还的结果图中存在建筑,则说明该点位的企业工厂真实存在;若返还的结果图中只存在非建筑,则说明该点位的企业工厂并不存在;
将该结果与企业基本信息关联数据进行比较,若两者相同,则自动筛选出有效企业基本信息关联数据的企业;若两者不同,则对该企业信息进行二次审查,通过企业的基本信息关联数据及其对应遥感影像判断该点位是否存在实际企业。
作为优选,所述S4的具体方法如下:
对所述土壤重金属风险级别进行划分后,根据研究区域的研究边界,得到其最小外接矩形所围成的范围;然后以该矩形的某个顶点开始,生成格网和对应的网格点;运用网格点提取污染企业核密度分析和土壤重金属空间分布插值结果在该网格内的数值,其数值分别代表研究边界中土壤重金属风险水平和污染企业的聚集程度;将带有土壤重金属风险级别与污染企业密度值的网格点进行双变量局部莫兰分析,具体公式如下:
其中
当I
作为优选,所述S5中,将所研究区域该年份的人口密度作为受体脆弱性指标,若人口密度高出当年我国平均人口密度1.5倍则认为是高脆弱性,否则,为低脆弱性。
本发明相对于现有技术而言,具有以下有益效果:
本发明基于政府调查并公开的污染企业数据进行后续建模,无需对数据进行分类以及污染状况以判别是否该企业是污染企业,后续研究可直接根据研究区所在省级政府公开的污染企业数据进行数据清洗与建模;此外,通过建立网格点数据,根据污染企业的建模结果得到密度值,并与土壤重金属风险级别进行双变量局部莫兰分析,分析二者在空间上的交互关系,从而使得离散的重金属污染点数据与污染企业点数据能够较为准确的探索空间交互关系,扩展了现有土壤重金属分区的方法和思路,对进一步管理与预防土壤重金属污染具有重要的理论与实际意义,并存在推广应用的价值。
本发明是通过一种基于模糊和相似度匹配的污染企业空间识别方法,主要采用U-Net模型建立污染企业识别的精度评价模型,通过一种基于特定的文本挖掘手段,主要采用了多项式朴素贝叶斯的方法建立分类模型,并通过得到的污染企业数据与当地的土壤重金属污染数据进行双变量局部莫兰指数分析来构建污染企业与土壤重金属含量分布之间的空间交互关系,进而对土壤重金属管理分区研究工作起到一个指向性的作用。
附图说明
图1是实施例中,(a)土壤重金属风险水平分区,(b)人口密度的分区,(c)污染企业密度分布,(d)土壤重金属Cd与污染企业的局部莫兰空间交互关系;
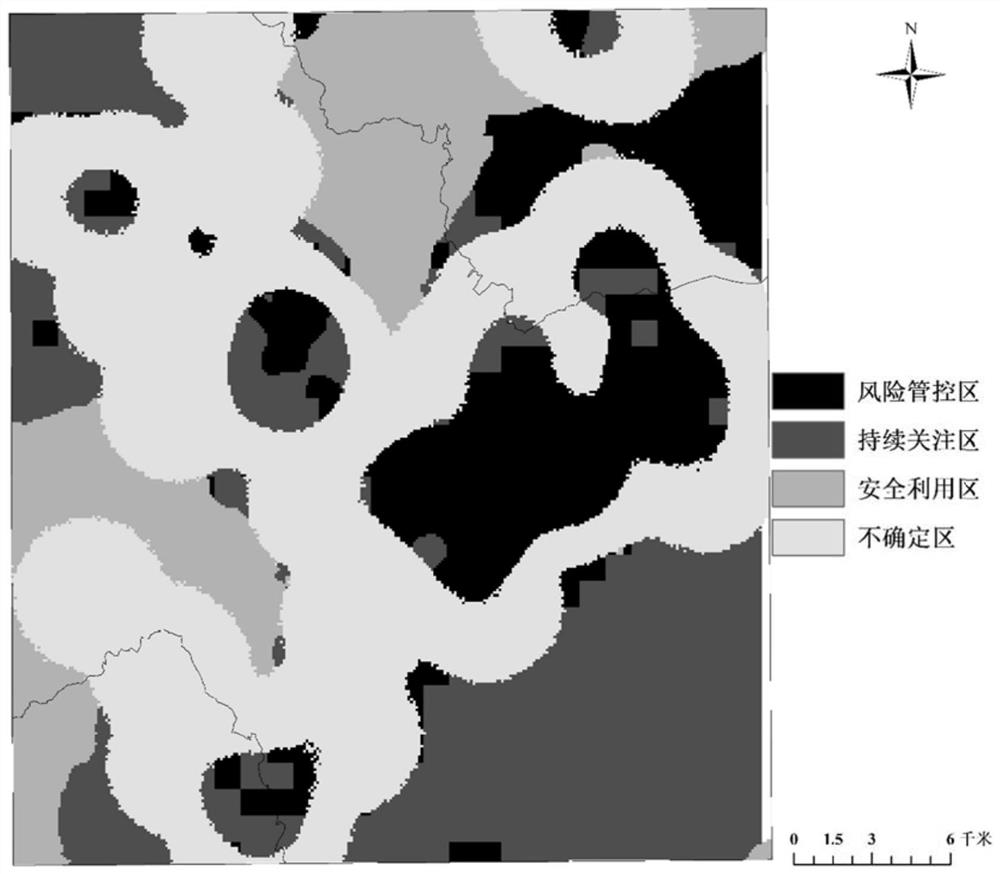
图2是实施例中,基于风险识别结果对研究区进行土壤重金属管理分区的示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。本发明中各个实施方式的技术特征在没有相互冲突的前提下,均可进行相应组合。
本发明提供了一种基于空间交互关系的土壤重金属风险识别方法,具体方法如下:
S1:数据获取,具体如下:
基于http协议与公开网页端获得待研究区域的全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单、重点排污单位名录、企业POI数据、工商要素补充数据和遥感影像。其中,全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录均包括企业名称及其所属地市,且均以PDF、word或图片格式存在。企业POI数据包括企业名称及其经纬度信息。工商要素补充数据包括企业名称、经营范围、成立年份和注册地址。
S2:数据预处理。将S1中全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录的特征信息(包括企业名称、经营范围和地址)转换为结构化数据。具体为:将全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录中以非结构化文档数据PDF、word或图片格式存在信息,使用OCR技术将其识别为基于Office Open XML标准的压缩文件格式,转换为结构化数据。
根据工商要素补充数据和和企业POI数据,对两个数据中的企业名称分别进行分词处理,之后进行匹配,使得每个企业的基本信息与其地理位置信息相对应,得到含地理位置的企业基本信息关联数据。同时,将POI数据的GCJ-02坐标系转换为WGS-84地理坐标系。
根据工商要素补充数据和企业POI数据,分别对两个数据中的企业名称使用分词引擎jieba分词处理,将其分词成“城市”+“企业名”+“行业名”+“后缀”四项。若两个数据中的企业名称经分词处理后的四项完全匹配,则将该信息输出,并得到含地理位置的企业基本信息关联数据。若两个数据中的企业名称经分词处理后的四项不完全匹配,提取工商要素补充数据中注册地址字段,使用高德API接口查询得到以GCJ-02坐标系表示的地理位置信息和位置范围,并与企业名称进行匹配,得到含地理位置的企业基本信息关联数据。
S3:相似度匹配。将S2中每个企业基本信息关联数据与遥感影像上的点位信息对应匹配,以获得每个污染企业及其周边场地的高分辨率遥感影像。然后使用基于深度学习的图像语义分割技术,对每个污染企业对应的遥感影像数据进行建筑物的特征提取,以判断该区域是否存在建筑或者企业工厂,实现污染企业分布情况与其企业基本信息关联数据的相似度匹配,得到污染企业点位数据。
S3的具体方法如下:
根据每个企业的基本信息关联数据及其对应遥感影像上的点位信息,对每个企业赋予经纬度信息,并获取该点位周边相应的遥感影像。通过获取的遥感影像进行数据的预处理,并生成相应的标注数据,对U-Net卷积神经网络模型进行训练建模。模型主要通过卷积与池化的步骤对图像进行特征提取,并通过反卷积的步骤将特征图恢复至原始图像的尺寸大小,卷积与池化的具体计算如公式(2)与(3)所示,具体如下:
其中假设k为模型的卷积层,
其中down()作为下采样的函数,在平均池化的步骤下,将固定大小的像素区域里的所有像素相加,最后得到的特征图的大小变为原来的1/n。
将训练好的U-Net卷积神经网络模型在研究区进行测试验证,模型对相应点位的影像进行图像分割,返还的结果图中的每个像元只有建筑与非建筑两类。若返还的结果图中存在建筑,则说明该点位的企业工厂真实存在。若返还的结果图中只存在非建筑,则说明该点位的企业工厂并不存在。
将该结果与企业基本信息关联数据进行比较,若两者相同,则自动筛选出有效企业基本信息关联数据的企业。若两者不同,则对该企业信息进行二次审查,通过企业的基本信息关联数据及其对应遥感影像判断该点位是否存在实际企业。
S4:使用核密度法对S3中获取的污染企业点位数据进行核密度分析。运用反距离加权法预测研究区域内土壤重金属空间分布,并运用全国农产品产地土壤重金属安全评估技术规定对土壤重金属风险级别进行划分。根据研究区域的研究边界生成特定规模的网格以及对应的网格点,基于网格点统计网格内土壤重金属风险级别与污染企业密度值。对土壤重金属风险级别与污染企业密度值进行双变量局部空间自相关分析,得到土壤重金属与污染企业的空间交互关系。
S4的具体方法如下:
对土壤重金属风险级别进行划分后,根据研究区域的研究边界,得到其最小外接矩形所围成的范围。然后以该矩形的某个顶点开始,生成格网和对应的网格点。运用网格点提取污染企业核密度分析和土壤重金属空间分布插值结果在该网格内的数值,其数值分别代表研究边界中土壤重金属风险水平和污染企业的聚集程度。将带有土壤重金属风险级别与污染企业密度值的网格点进行双变量局部莫兰分析,具体公式如下:
其中
当I
需要注意的是,将格网i和格网j进行变化,通过上述过程可得格网j处的a属性与格网i处b属性的局部莫兰指数。
S5:根据土壤重金属风险(以Cd为例)、研究区域的受体脆弱性(以人口密度为例)和空间交互关系,对研究区域进行风险识别。
其中,将所研究区域该年份的人口密度作为受体脆弱性指标,若人口密度高出当年我国平均人口密度1.5倍则认为是高脆弱性,否则,为低脆弱性。
根据表1将所研究区域进行管理分区,以便后续监测管理。
表1
实施例
选取中国东南沿海某区域作为研究区,使用本发明的方法进行分析,具体步骤如下:
S1:基于http协议与公开网页端获得待研究区域的全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单、重点排污单位名录、企业POI数据、工商要素补充数据和遥感影像。其中,工商要素补充数据的分类符合国民经济行业分类标准GB/T 4752-2011;企业POI数据需要有经纬度信息,属于WGS84地理坐标系,且是基于高德地图API下载而来。
S2:将S1中的数据使用分词引擎jieba,该引擎是经过隐马尔科夫链模型训练而来,具备很好的分词效果。首先,将工商要素补充数据的企业名字段,分词成“城市”+“企业名”+“行业名”+“后缀”四项;将企业POI数据的企业名字段,分词成“城市”+“企业名”+“行业名”+“后缀”四项。如工商与POI数据企业名字段的四项完全匹配,则得到含地理位置的企业基本信息关联数据;如后缀不符,例如“有限公司”和“有限责任公司”,仍认为是一家企业。对未能通过企业名关联到的工商企业数据,提取工商注册地址字段,使用高德API接口查询得到地理位置信息(GCJ-02)和位置范围(兴趣点、街道、乡镇、区、市、省),筛选位置范围为兴趣点的数据集,并与企业名称进行匹配,得到含地理位置的企业基本信息关联数据。
S3:根据每个企业的基本信息关联数据及其对应遥感影像上的点位信息,对每个企业赋予经纬度信息,并获取该点位周边相应的遥感影像。通过获取的遥感影像进行数据的预处理,并生成相应的标注数据,对U-Net卷积神经网络模型进行训练建模。具体如下:
将获得的相应点位的遥感影像与相应标注图进行切块处理,分成256*256大小的图像,并进行翻转与裁剪等数据增强的操作提高数据的多样性,以训练样本大小为10作为模型的训练输入,初始学习率为5e-5,损失函数选用二元交叉熵。在达到200K次的迭代后,模型基本达到局部最优点并收敛。在后续的模型验证过程中,对模型分割的结果以总体精度、召回率、F1-score作为模型性能的精度评价。
其中TP代表着是分类正确的并且类别为建筑的像元个数;TN表示分类正确的并且类别为背景的像元个数;FN表示本为建筑类别的像元被分为背景的像元个数;FP表示类别为背景的像元被分为建筑类别的像元个数。
将训练好的U-Net卷积神经网络模型在研究区进行测试验证,模型对相应点位的影像进行图像分割,返还的结果图中的每个像元只有建筑与非建筑两类。若返还的结果图中存在建筑,则说明该点位的企业工厂真实存在。若返还的结果图中只存在非建筑,则说明该点位的企业工厂并不存在。
将该结果与企业基本信息关联数据进行比较,若两者相同,则自动筛选出有效企业基本信息关联数据的企业。若两者不同,则对该企业信息进行二次审查,通过企业的基本信息关联数据及其对应遥感影像判断该点位是否存在实际企业。
S4:使用核密度法对S3中获取的污染企业点位数据进行空间插值,设定输出的分辨率为1km,得到研究区污染企业的空间分布密度图,即完成核密度分析。运用反距离加权法预测研究区域内土壤重金属空间分布,并运用全国农产品产地土壤重金属安全评估技术规定对土壤重金属风险级别进行划分。根据研究区域的研究边界生成特定l km分辨率的网格以及对应的网格点,基于网格点统计网格内土壤重金属风险级别(如图1a所示)与污染企业密度值(如图1c所示)。对土壤重金属风险级别与污染企业密度值进行双变量局部空间自相关分析,选取的空间相邻关系为K-Nearest neighbors,得到土壤重金属与污染企业的空间交互关系。
S5:如图2所示,根据土壤重金属风险(以Cd为例)、研究区域的受体脆弱性(以人口密度为例,如图1b所示)和空间交互关系(如图1d所示),对研究区域进行风险识别。并根据表1将所研究区域进行管理分区,以便后续监测管理。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 一种基于空间交互关系的土壤重金属风险识别方法
- 基于生物有效性和蒙特卡罗模拟的重金属污染土壤健康风险概率化识别方法