一种电子档案管理方法
文献发布时间:2023-06-19 09:49:27
技术领域
本发明涉及档案管理技术领域,具体为一种电子档案存储管理方法
背景技术
在现代企事业单位中,利用计算机办公已成为一种常态,而在计算机办公过程中会产生大量的电子档案,而电子档案的损坏或丢失可能会对企事业单位造成一定的损失,因此,对电子档案的妥善管理已成为企业管理中必不可少的部分。
现有企业可能会出现要将纸质档案的扫描件作为电子档案进行存储,一般的企业通常采用人工的方式对纸质档案的扫面件进行阅读后根据内容进行档案的分类,这种方式速度慢、效率低,并且准确性差。
发明内容
本发明的目的是:针对现有技术中采用人工的方式将纸质档案的扫面件进行存储的时候存在分类效率低、准确性差的问题,提出一种电子档案存储管理方法。
本发明为了解决上述技术问题采取的技术方案是:
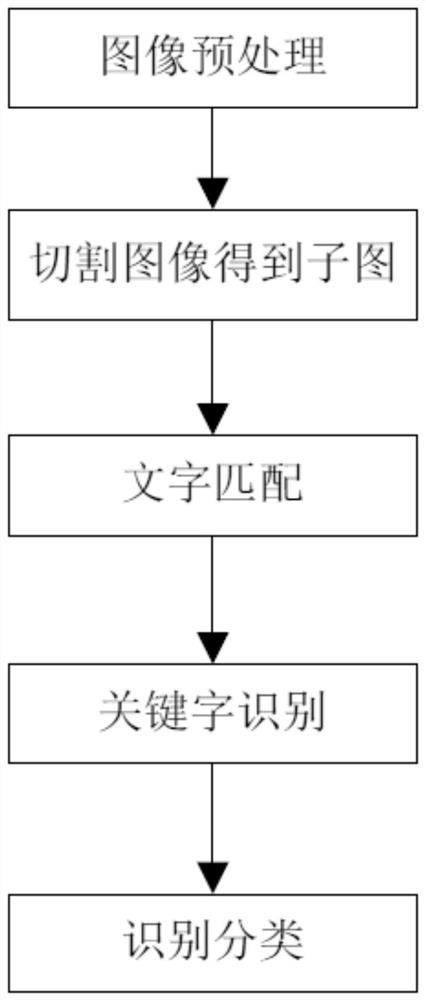
一种电子档案管理方法,包括以下步骤:
步骤一:将待识别文档图像进行预处理;
步骤二:对预处理后的待识别文档图像进行切割,得到包含文字的子图;
步骤三:将包含文字的子图与标准文字进行匹配,得到候选文本;
步骤四:将候选文本进行关键词识别,得到关键词;
步骤五:根据关键词得到待识别文档图像的分类,并在待识别文档图像上标记分类信息。
进一步的,所述预处理为:降噪及二值化处理。
进一步的,所述步骤四的具体步骤为:
步骤四一:将训练文本的关键词及训练文本中关键词所对应的有效特征进行标记,所述有效特征为关键词具有区分功能的特征,并将训练文本中关键词及有效特征作为训练集;
步骤四二:利用训练集训练神经网络;
步骤四三:将候选文本输入训练好的神经网络得到关键词。
进一步的,所述步骤四三的具体步骤为:
步骤四三一:若训练好的神经网络输出的关键词为单个,则直接输出该关键词,若训练好的神经网络输出的关键词为多个,则执行步骤四三二;
步骤四三二:建立共现特征集,所述共现特征集包括候选关键词及每个候选关键词对应的多个候选有效特征;
步骤四三三:将训练好的神经网络输出的多个关键词所对应的有效特征分别与共现特征集中的候选关键词所对应的多个候选有效特征进行匹配,若训练好的神经网络输出的多个关键词所对应的有效特征与同一个候选关键词所对应的多个候选有效特征匹配,则将该候选关键词最为最终关键词,若训练好的神经网络输出的多个关键词所对应的有效特征未与同一个候选关键词所对应的多个候选有效特征匹配,则选择有效特征对应次数最多的候选有效特征所对应的候选关键词作为最终关键词。
进一步的,所述步骤二对预处理后的待识别文档图像进行切割利用Cornernet网络进行。
进一步的,所述步骤二对预处理后的待识别文档图像进行切割的具体步骤为:
步骤二一:利用coco模型参数对Cornernet网络参数初始化;
步骤二二:利用初始化后的Cornernet网络,将预处理后的待识别文档图像输入到Hourglass中得到两张热力图,每张热力图的通道数为C,针对每张热力图中每个角点进行预测,并保留预测值大于0.7的角点;
步骤二三:对热力图上保留的每个角点进行编码,得到每个角点的编码向量,之后计算任意两个角点的编码向量间的距离,角点编码向量距离最小的两个角点即为相似度最大的两个角点,并将相似度最大的两个角点作为目标的左上和右下角点,然后根据目标的左上和右下角点生成目标框;
步骤二四:将目标框中内容与标准文字进行匹配,匹配值大于阈值的保留,匹配值小于阈值的删除;
步骤二五:将保留下的目标框进行拼接,得到包含文字的子图。
进一步的,所述Cornernet网络的损失函数为:
L=L
L
进一步的,所述对每张热力图中每个角点进行预测的损失函数为:
式中p
进一步的,所述编码的损失函数为:
e
本发明的有益效果是:采用本发明可以有效的将扫描的图像进行识别,并进行分类存储及管理,识别及存储效率高、准确率高。
附图说明
图1为本发明的整体流程图;
图2为本发明Cornernet网络结构图。
具体实施方式
具体实施方式一:参照图1具体说明本实施方式,本实施方式所述的一种电子档案管理方法,包括以下步骤:
步骤一:将待识别文档图像进行预处理;
步骤二:对预处理后的待识别文档图像进行切割,得到包含文字的子图;
步骤三:将包含文字的子图与标准文字进行匹配,得到候选文本;
步骤四:将候选文本进行关键词识别,得到关键词;
步骤五:根据关键词得到待识别文档图像的分类,并在待识别文档图像上标记分类信息。
本申请首先将扫描的电子文档文件进行预处理,预处理的作用是清除干扰,然后将包含文字的图像切割出来,减少工作量,之后对文本中的文字进行提取,提取其中的关键字,根据关键字与分类类别中的关键字进行匹配,从而进行电子文档的分类。
具体实施方式二:本实施方式是对具体实施方式一所述的作进一步说明,本实施方式与具体实施方式一的区别是所述预处理为:降噪及二值化处理。
具体实施方式三:本实施方式是对具体实施方式一所述的作进一步说明,本实施方式与具体实施方式一的区别是所述步骤四的具体步骤为:
步骤四一:将训练文本的关键词及训练文本中关键词所对应的有效特征进行标记,所述有效特征为关键词具有区分功能的特征,并将训练文本中关键词及有效特征作为训练集;
步骤四二:利用训练集训练神经网络;
步骤四三:将候选文本输入训练好的神经网络得到关键词。
具体实施方式四:本实施方式是对具体实施方式三所述的作进一步说明,本实施方式与具体实施方式三的区别是所述步骤四三的具体步骤为:
步骤四三一:若训练好的神经网络输出的关键词为单个,则直接输出该关键词,若训练好的神经网络输出的关键词为多个,则执行步骤四三二;
步骤四三二:建立共现特征集,所述共现特征集包括候选关键词及每个候选关键词对应的多个候选有效特征;
步骤四三三:将训练好的神经网络输出的多个关键词所对应的有效特征分别与共现特征集中的候选关键词所对应的多个候选有效特征进行匹配,若训练好的神经网络输出的多个关键词所对应的有效特征与同一个候选关键词所对应的多个候选有效特征匹配,则将该候选关键词最为最终关键词,若训练好的神经网络输出的多个关键词所对应的有效特征未与同一个候选关键词所对应的多个候选有效特征匹配,则选择有效特征对应次数最多的候选有效特征所对应的候选关键词作为最终关键词。
具体实施方式五:本实施方式是对具体实施方式一所述的作进一步说明,本实施方式与具体实施方式一的区别是所述步骤二对预处理后的待识别文档图像进行切割利用Cornernet网络进行。
具体实施方式六:本实施方式是对具体实施方式五所述的作进一步说明,本实施方式与具体实施方式五的区别是所述Cornernet网络的损失函数为:
L=L
L
具体实施方式七:本实施方式是对具体实施方式六所述的作进一步说明,本实施方式与具体实施方式六的区别是所述步骤二对预处理后的待识别文档图像进行切割的具体步骤为:
步骤二一:利用coco模型参数对Cornernet网络参数初始化(结构如图2所示);
步骤二二:利用初始化后的Cornernet网络,将预处理后的待识别文档图像输入到Hourglass中得到两张热力图,每张热力图的通道数为C,针对每张热力图中每个角点进行预测,并保留预测值大于0.7的角点;
步骤二三:对热力图上保留的每个角点进行编码,得到每个角点的编码向量,之后计算任意两个角点的编码向量间的距离,角点编码向量距离最小的两个角点即为相似度最大的两个角点,并将相似度最大的两个角点作为目标的左上和右下角点,然后根据目标的左上和右下角点生成目标框;
步骤二四:将目标框中内容与标准文字进行匹配,匹配值大于阈值的保留,匹配值小于阈值的删除;
步骤二五:将保留下的目标框进行拼接,得到包含文字的子图。
多目标检测
1)、利用coco模型参数对Cornernet网络参数初始化。
2)、将图像输入到Hourglass网络中得到两张heatmaps,一张用于左上角点的预测,一张用于右下角点预检测,每张heatmap的通道数为C,C是检测类别数,每个点的预测值为0到1,表示该点是角点的分数。
3)、对输入特征图上的每个点进行编码,得到的编码向量即为Embeddings,表示该点的位置信息,网络为每个检测到的角点预测一个Embedding vector,对于相同的物体左上角点和右下角点计算Embedding vector的距离很小,即同一物体的角点对应的Embeddings具有较高的相似度,对于不同物体的角点,对应的Embeddings具有较大的距离,较小的相似度。
4)、依据Embeddings计算的结果,同一个物体的角点组成文字的目标框。
具体实施方式八:本实施方式是对具体实施方式七所述的作进一步说明,本实施方式与具体实施方式七的区别是所述对每张热力图中每个角点进行预测的损失函数为:
式中p
角点预测的损失函数采用对focal loss损失函数进行改进,定义如下:
p
具体实施方式九:本实施方式是对具体实施方式七所述的作进一步说明,本实施方式与具体实施方式七的区别是所述编码的损失函数为:
e
需要注意的是,具体实施方式仅仅是对本发明技术方案的解释和说明,不能以此限定权利保护范围。凡根据本发明权利要求书和说明书所做的仅仅是局部改变的,仍应落入本发明的保护范围内。
- 一种基于二维码的溯源财务电子档案管理方法
- 一种基于企业链码的电子档案管理方法