分布式数据分片存储读取的方法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及数据的分片读取领域,具体涉及一种分布式数据分片存储读取的方法。
背景技术
在通信技术快速发展的今天,互联网不断探索着更高的速率和更低的延迟,各大主流厂商都在筹备5G、WIFI6相关的技术。而互联网种最常见的功能就是文件下载,无论是音乐、视频、网页其本质都是从服务器进行下载后在本机进行渲染。而下载这一最核心的功能,目前加速的方式主要有CDN加速和多线程加速,CDN加速是服务器端实现的加速,多线程加速则是客户端实现的加速。
CDN加速是根据地域在全国范围内部署CDN服务器,在用户访问网站时,分配到最近的可以访问的服务器,提高下载速度。多线程下载则是开启多个线程对文件分片后请求服务器,然后拼接为一个文件。CDN是通过减少数据在网络中转发次数、滞留时间提高速度,多线程则是依靠多个线程抢占带宽达到这一目的。但上述方式都是单方面的进行优化,如果客户端和服务器都同时支持一种方法,能够在客户端上支持多线程访问地域中多个服务器进行分片下载,将又是一种新的方式。
发明内容
本发明的目的是提供一种分布式数据分片存储读取的方法,用于提升用户在浏览互联网时的速率,减少用户在下载时的等待,让用户得到极佳的上网体验。
本发明解决其技术问题,采用的技术方案是:
分布式数据分片存储读取的方法,包括如下步骤:
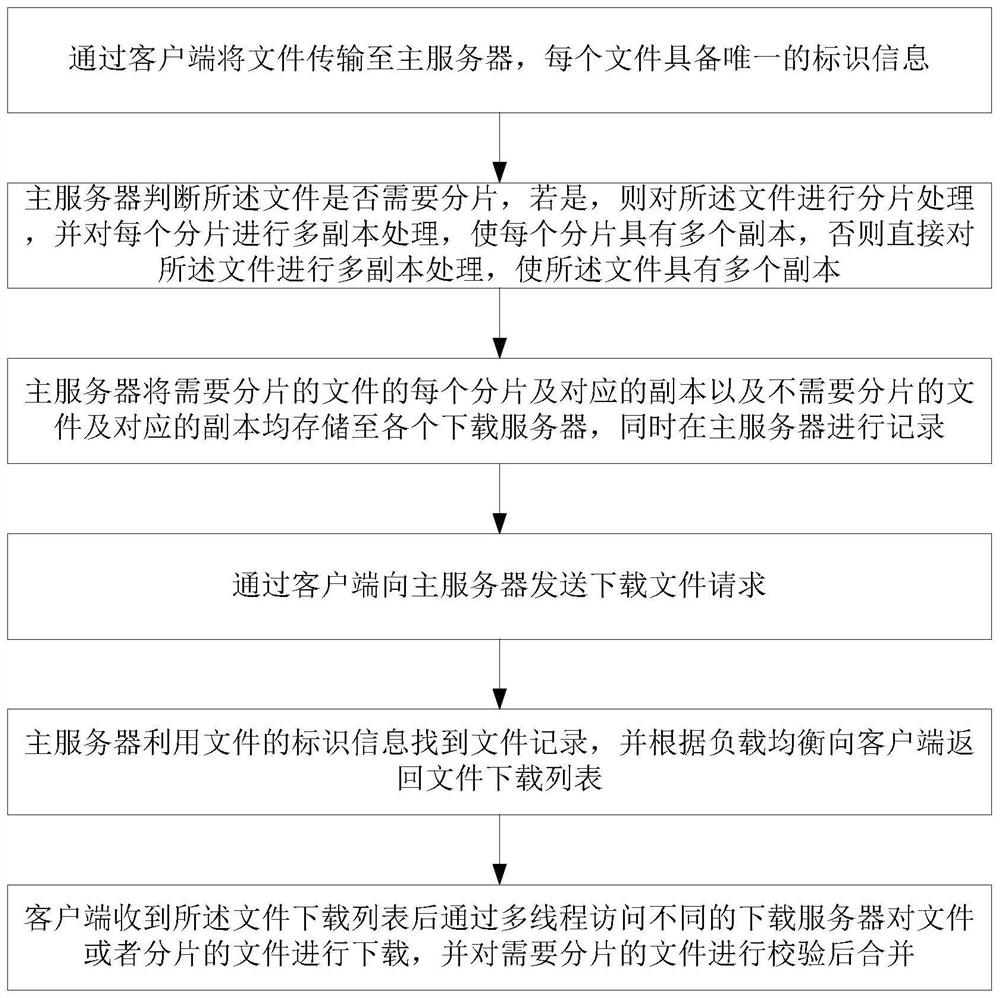
步骤1、通过客户端将文件传输至主服务器,每个文件具备唯一的标识信息;
步骤2、主服务器判断所述文件是否需要分片,若是,则对所述文件进行分片处理,并对每个分片进行多副本处理,使每个分片具有多个副本,否则直接对所述文件进行多副本处理,使所述文件具有多个副本;
步骤3、主服务器将需要分片的文件的每个分片及对应的副本以及不需要分片的文件及对应的副本均存储至各个下载服务器,同时在主服务器进行记录;
步骤4、通过客户端向主服务器发送下载文件请求;
步骤5、主服务器利用文件的标识信息找到文件记录,并根据负载均衡向客户端返回文件下载列表;
步骤6、客户端收到所述文件下载列表后通过多线程访问不同的下载服务器对文件或者分片的文件进行下载,并对需要分片的文件进行校验后合并。
进一步的是,步骤2中,在主服务器根据文件所占内存的大小判断所述文件是否需要分片,当文件所占内存大于等于规定值时,判定需要对该文件进行分片处理,否则判定不需要对该文件进行分片处理。
进一步的是,步骤3中,主服务器根据负载均衡和客户端IP将需要分片的文件的每个分片及对应的副本以及不需要分片的文件及对应的副本均存储至各个下载服务器。
进一步的是,步骤3中,主服务器还同时生成索引信息。
进一步的是,步骤5中,主服务器根据所述索引信息,并利用文件的标识信息找到文件记录。
进一步的是,步骤5中,所述文件记录包括文件的分片信息和下载服务器地址信息,所述文件记录以文件下载列表的方式返回至客户端。
进一步的是,步骤6中,下载完成后,对下载好的分片的文件进行md5校验后合并。
进一步的是,步骤6中,对下载好的分片的文件进行md5校验并合并完成后,校验md5。
本发明的有益效果是,通过上述分布式数据分片存储读取的方法,用户首先发起上传请求来上传文件,服务器根据文件大小进行分片和多副本,根据负载均衡和客户IP分配到下载服务器上,同时储存分片、副本信息到主服务器,用户发起下载请求时,返回文件分片信息和对应的下载服务器;客户端收到分片信息和下载地址后,通过多线程,分别访问不同的服务器,对文件片段进行下载,最大化下载速率,在下载完成后对文件进行合并。无论是上传还是下载,用户都不需要进行额外的操作,由算法自动进行下载合并,对于服务器运维人员,在搭建集群后也不用再进行额外的管理,数据自动分片存储。
附图说明
图1为本发明分布式数据分片存储读取的方法的流程图;
图2为本发明实施例中整体架构简图;
图3为本发明实施例中基本业务流程图;
具体实施方式
下面结合附图及实施例,详细描述本发明的技术方案。
本发明提出一种分布式数据分片存储读取的方法,其流程图见图1,其中,该方法包括如下步骤:
步骤1、通过客户端将文件传输至主服务器,每个文件具备唯一的标识信息,一般情况下,唯一的标识信息即为文件UID。
步骤2、主服务器判断所述文件是否需要分片,若是,则对文件进行分片处理,并对每个分片进行多副本处理,使每个分片具有多个副本,否则直接对文件进行多副本处理,使文件具有多个副本;
这里,在主服务器根据文件所占内存的大小判断所述文件是否需要分片,当文件所占内存大于等于规定值时,判定需要对该文件进行分片处理,否则判定不需要对该文件进行分片处理,其中的规定值根据系统需要进行设定。
步骤3、主服务器将需要分片的文件的每个分片及对应的副本以及不需要分片的文件及对应的副本均存储至各个下载服务器,同时在主服务器进行记录;
其中,主服务器可以根据负载均衡和客户端IP将需要分片的文件的每个分片及对应的副本以及不需要分片的文件及对应的副本均存储至各个下载服务器。
与此同时,主服务器还可以同时生成索引信息。
步骤4、通过客户端向主服务器发送下载文件请求。
步骤5、主服务器利用文件的标识信息找到文件记录,并根据负载均衡向客户端返回文件下载列表;
其中,主服务器可以根据索引信息,并利用文件的标识信息找到文件记录。
需要指出的是,文件记录可以包括文件的分片信息和下载服务器地址信息,这里,文件记录以文件下载列表的方式返回至客户端。
步骤6、客户端收到所述文件下载列表后通过多线程访问不同的下载服务器对文件或者分片的文件进行下载,并对需要分片的文件进行校验后合并;
其中,下载完成后,可以对下载好的分片的文件进行md5校验后合并,能够确保文件的完整性。
另外,对下载好的分片的文件进行md5校验并合并完成后,还可以校验md5,通过对md5本身的校验,进一步保证文件的完整性及准确性。
实施例
本实施例中,整体架构图见图2,其中,系统主要分为三个部分,一是下载服务器集群,用于提供真正的下载服务。二是主服务器,存储了所有文件的分片信息和下载地址。三是客户端,根据分片信息和下载地址去对应的服务器下载分片文件。
本实施例中,分布式数据分片存储读取的方法的基本业务流程图见图3,其中,基本业务具体为:
一、客户端上传文件到主服务器,主服务器接收完成后判断文件是否需要分片、副本。
二、主服务器对文件进行分片处理和多副本处理,根据负载均衡和其他信息下发到下载服务器,同时记录分片、副本和下载服务器信息。
三、用户向主服务器请求下载文件,主服务器根据文件的UID查询到分片信息和下载服务器信息,根据负载均衡,返回能够组合成一个完整文件的分片信息表返回给客户端。
四、客户端收到了文件信息,创建多个线程,访问对应的下载地址开始进行下载,在下载完成后对文件拼接,最后校验md5。
- 分布式数据分片存储读取的方法
- 一种基于分布式数据分片存储和模糊查找方法