一种联邦学习场景中的数据选择方法
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及的联邦学习场景中的数据选择方法,属于数据分析与数据质量评估领域。
背景技术
如何获取大量的高质量数据集已成为许多机器学习模型和AI应用的常见瓶颈。这不仅是因为收集和标记大量样本非常昂贵,而且还因为隐私问题阻碍了许多领域(例如医学和经济学)的数据共享。联邦学习的出现使得终端用户利用本地数据联合训练网络模型成为可能。在联邦学习过程中,用户本地的数据质量影响全局模型的性能,低质量数据(例如,错误标签数据,非均匀分布的数据)将严重阻碍全局模型取得良好的效果。
本发明旨在一给定预算下,以一种隐私保护的方式为给定的联邦学习任务选择一组高质量的训练样本,从而提高模型的精度和加快模型收敛速度。
针对深度学习中的数据选择已有一系列工作:1)他们提出多种质量指标,例如任务相关性和内容多样性,并对数据样本进行质量指标检测,选择质量分数高的数据参与训练。2)动态选择对模型重要的训练样本,以在训练过程中组成数据batch,以加速模型收敛,通常,重要性分数通过梯度范数或损失值来量化。但他们不能直接用于联邦学习中:1)现有的方法需要直接访问所有训练样本,而在联邦系统中,数据不能被第三方直接访问到。2)直接计算每个样本的重要性对资源有限的参与者造成不可接受的开销。3)现有的方法没有考虑非IID或者错误样本对样本选择策略的影响,并且可能会给错误的样本赋予更高的重要性,从而降低模型性能。
发明内容
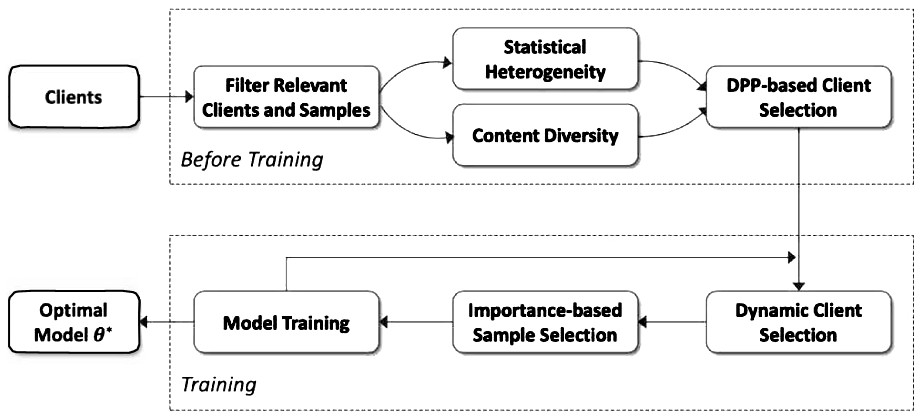
本发明的目的在于克服现有技术的不足,提供一种隐私保护的方式为给定的联邦学习任务选择一组高质量的训练样本,从而提高模型的精度和加快模型收敛速度。所述该方法包括过滤出和任务相关的用户和数据、训练前用户选择、训练过程中用户和数据选择、模型训练。
作为优选:任务相关用户和数据过滤为当一FL任务到达时,server首先通过计算每个用户C
作为优选:训练前用户选择:server使用基于点阵行列式(DPP)算法从相关用户集中进一步选择高质量用户集(用户下标集合Q),以在预算约束B下最大化同质性和内容多样性:max V(Q),s.t.,∑
a)基于同质性用户选择:server优先选择那些数据分布均匀且类别不缺失的用户。以同质性为选择用户的指标时,V
b)基于多样性用户选择:server选择那些数据内容多样的用户参与模型训练。以内容多样性为选择用户的指标时,V(Q)=ρ(D),D∪
为了计算数据集的内容多样性,首先需要提取数据的特征向量表达,我们使用深度学习模型提取特征,比如使用VGG-16网络提取图片的内容特征向量,然后去计算该用户所有数据的内容多样性。当该用户的数据量M较大,且特征向量维度l较高时,计算内容多样性开销很大O(M
i.构建数据集内容草图:用户C
ii.随机响应机制:为了进一步保护每个数据存在性的隐私,我们使用了随机响应机制来产生向量草图h(φ
C)基于点阵行列式用户选择:当同时考虑同质性和多样性时,用户选择问题被转化成DPP问题。用户C
作为优选:训练过程中用户和数据选择为给定选定的高质量用户集,其索引集为Q∈[N′],|Q|=K,为了进一步改善模型性能并减少训练开销,在每轮训练迭代中ζ比例的用户被选中,同时用户本地选择重要的数据样本参与模型训练。一个直观的量化用户C
作为优选:模型训练为在每轮迭代中,所有被选中的用户都会在被选中的样本上训练其本地模型,并且server汇总用户端的模型更新以更新全局模型。Server重复该过程,直到获得全局最佳模型θ
本发明设计了一个面向联邦学习的高效的数据选择方法,并提高模型的精度和加快了模型收敛速度。本发明提出的方法优势体现在,由于采用了向量草图和随机响应机制,用户选择策略高效且带有隐私保护;同时由于采用了server端日志信息来动态选择用户;基于梯度上界值选择数据,以及考虑到错误数据对梯度的影响,数据选择策略高效且准确。
附图说明
图1为联邦学习场景中高效的数据选择系统流程图。
具体实施方式
下面将结合附图对本发明作详细的介绍:如图1所示,本发明提出的联邦学习场景中的数据选择方法主要分为以下模块:过滤出和任务相关的用户和数据、训练前用户选择、训练过程中用户和数据选择、模型训练。
(1)任务相关用户和数据过滤:当一FL任务到达时,server首先通过计算每个用户C
(2)训练前用户选择:server使用基于点阵行列式(DPP)算法从相关用户集中进一步选择高质量用户集(用户下标集合Q),以在预算约束B下最大化同质性和内容多样性:maxV(Q),s.t.,∑
a)基于同质性用户选择:server优先选择那些数据分布均匀且类别不缺失的用户。以同质性为选择用户的指标时,V
b)基于多样性用户选择:server选择那些数据内容多样的用户参与模型训练。以内容多样性为选择用户的指标时,V(Q)=ρ(D),D∪
为了计算数据集的内容多样性,首先需要提取数据的特征向量表达,我们使用深度学习模型提取特征,比如使用VGG-16网络提取图片的内容特征向量,然后去计算该用户所有数据的内容多样性。当该用户的数据量M较大,且特征向量维度l较高时,计算内容多样性开销很大O(M
i.构建数据集内容草图:用户C
ii.随机响应机制:为了进一步保护每个数据存在性的隐私,我们使用了随机响应机制来产生向量草图h(φ
(3)基于点阵行列式用户选择:当同时考虑同质性和多样性时,用户选择问题被转化成DPP问题。用户C
(4)训练过程中用户和数据选择:给定选定的高质量用户集,其索引集为Q∈[N′],|Q|=K,为了进一步改善模型性能并减少训练开销,在每轮训练迭代中ζ比例的用户被选中,同时用户本地选择重要的数据样本参与模型训练。一个直观的量化用户C
(5)模型训练:在每轮迭代中,所有被选中的用户都会在被选中的样本上训练其本地模型,并且server汇总用户端的模型更新以更新全局模型。Server重复该过程,直到获得全局最佳模型θ
- 一种联邦学习场景中的数据选择方法
- 一种在联邦学习场景下的数据恢复攻击的方法