一种基于自然语言处理挖掘风险信号的方法
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及互联网+监管应用领域领域,尤其涉及一种基于自然语言处理(NLP)挖掘风险信号的方法。
背景技术
目前,各监管部门的监管资源有限,任务来源方式主要包括随机匹配、计划任务。针对海量监管对象,结合紧张的监管资源现状,监管任务来源方式盲区大、精准度低。同时,空有海量数据,却无法从中提炼出有效的风险线索凸显出当前资源浪费的现状。如何合理利用紧张资源,如何有效利用大数据资源是当前各监管部门急需解决的问题。
风险预警引擎系统属于互联网+监管领域风险预警范畴,利用已经构建好的数据分析模型,基于海量数据分析出潜在的风险预警信号,并驱动监管主体进行针对性监管,从而缩小监管盲区、提高监管的精准度。但是,目前最具备前瞻性的数据遍是大文本格式,存在无结构、不抽象、无特征等低质量特点。由此导致引擎无法精准分析该类数据,从而需要对该类数据进行信息提炼、格式化等预处理。
目前,经由系统汇入的数据普遍是大文本格式,存在无结构、不抽象、无特征等低质量特点,导致风险预警引擎和其他系统不宜对此类信息进行业务分析。由此,导致业务系统无法对此类海量数据进行深度利用,从而造成浪费。
发明内容
为了解决以上技术问题,本发明提供了一种基于自然语言处理(NLP)挖掘风险信号的方法。
本发明通过对大文本内容进行分析,提炼出对象、时间、地点、情感等关键信息并做格式化存储,进而对预处理之后的数据进行分析挖掘出风险预警信号
本发明的技术方案是:
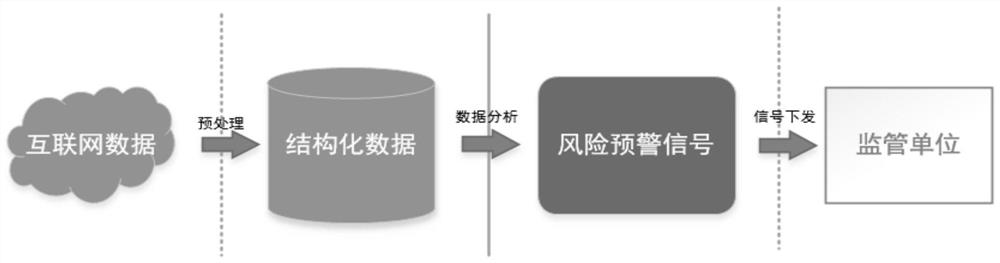
一种基于自然语言处理挖掘风险信号的方法,风险预警引擎系统基于人工智能自然语言处理技术预先处理投诉举报、网络舆情数据,并将提炼出的关键信息格式化存储。然后基于已经构建的风险预警分析模型对预处理之后的格式化内容进行分析产生风险预警信号,并将该信号精准下发至相关部门。
进一步的,
将文本信息经过语义分析、分词处理成词条向量,以互联网监管领域的关键词语料库为训练对象,通过深度学习算法迭代学习,找出可以代表此条文本信息的关键指令。
提取的信息包括投诉举报对象、时间、地点、情感信息。
再进一步的,
自然语言处理和语义分析:
风险预警引擎初步分析文本数据时,依托自然语言处理技术、协同众包技术、机器学习技术、神经网络技术,提供自然语言分析和理解服务,利用NLP的分词词性标注、人名识别、地名识别、机构名识别、时间名词识别、句法依存分析、自动摘要、文本相似、文本分类、情感分析、关键词提取的处理技术,为文本信息提供分析服务。
所涉及的算法包括K-short分词算法、HMM隐马尔科夫算法模型、Dijkstra 最短距离算法、TF-IDF词频-逆向文本频率算法、TextRank算法、W2V词向量模型、 CRF条件随机场算法模型、基于神经网络的FastText文本分类算法模型。
分析风险预警信号:
进一步分析风险预警信号的模型存放至关系型数据库中;同时,支持用户自定义添加分析模型,扩展模型库,以适应自身预警焦点的动态变化。
风险预警引擎根据已经创建的分析模型分析预处理之后的格式化数据,针对可疑数据产生风险预警信号,信号存放至关系型数据库表中。
推送风险预警信号
根据风险预警信号问题类型、该类型所属监管单位以及此类信号问题的分发历史经验,将产生的风险预警信号以http post接口或库表交换的方式推送至相应的平台。
本发明的有益效果是
根据海量数据所产生的风险预警信号能够反应出潜在风险点,以此作为线索展开监管工作的方式更精准。同时合理利用有限资源,将产生的风险预警信号自动推送至相关监管单位的方式更加高效。
附图说明
图1是本发明的工作流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明应用于互联网+监管领域风险预警引擎系统,专门用来从大文本内容中提取对象、时间、地点、情感等有价值的信息,进而分析出风险预警信号。
对大文本内容进行预处理,挖掘出对象、时间、地点、情感等信息,并将该信息回写数据库,从而将内容结构化、抽象化。经过此环节分析处理,风险预警引擎可以直接利用挖掘出的结构化结果数据进行业务分析计算。由此,不但能够提高业务数据的检索速度,还可以大幅提升数据的利用率。
本发明应用于风险预警引擎系统,属于互联网+监管应用领域范畴。风险预警引擎系统基于人工智能自然语言处理技术预先处理数据,并将提炼出的关键信息格式化存储。然后基于已经构建的风险预警分析模型对预处理之后的格式化内容进行分析产生风险预警信号,并将该信号精准下发至相关部门。本发明实现技术方案如下:
1、自然语言处理和语义分析:
风险预警引擎初步分析大文本数据时,依托自然语言处理技术、协同众包技术、机器学习技术、神经网络技术等,提供个性化、一体化、智能化、多样化的自然语言分析和理解服务,利用NLP的分词词性标注、人名识别、地名识别、机构名识别、时间名词识别、句法依存分析、自动摘要、文本相似、文本分类、情感分析、关键词提取等处理技术,为文本信息提供高效、精准的分析服务,所涉及的核心算法包括K-short分词算法、HMM隐马尔科夫算法模型、Dijkstra最短距离算法、TF-IDF词频-逆向文本频率算法、TextRank算法、 W2V词向量模型、CRF条件随机场算法模型、基于神经网络的FastText文本分类算法模型等。
2、分析风险预警信号:
进一步分析风险预警信号的模型存放至关系型数据库中,用户可以横向扩展数据分析模型的数量,丰富模型库。风险预警引擎根据已经创建的分析模型分析预处理之后的格式化数据,针对可疑数据产生风险预警信号,信号存放至关系型数据库表中。
3、推送风险预警信号
根据风险预警信号问题类型、该类型所属监管单位以及此类信号问题的分发历史经验,将产生的风险预警信号以http post接口或库表交换的方式推送至相应的平台。
1)基于深度学习技术,提高语音到文本的识别率;
2)基于互联网监管领域的场景特定语料库提高文本处理的准确率;
3)通过自然语言处理和语义分析实现关键词的提取;
将文本信息经过语义分析、分词等处理成词条向量,以互联网监管领域特定的关键词语料库为训练对象通过深度学习算法迭代学习,可以更加准确的找出可以代表此条文本信息的关键指令,提高算法识别准确率。
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 一种基于自然语言处理挖掘风险信号的方法
- 一种基于自然语言处理的舆情风险监测方法及系统