人工智能对话方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明涉及人机交互领域,尤其涉及一种人工智能对话的方法。
背景技术
自动化客服已经深入了各行各业,能够进行简单的问题检索和显示,但仍然不够智能,为了能够进行相关的人工智能对话的更加智能化,需要提出一种新的人工智能对话方法。
发明内容
为此,需要提供一种进行相关的人工智能对话的更加智能化,以解决在现有技术中人机交互意思识别不够智能的问题;
为实现上述目的,发明人提供了一种人工智能对话方法,包括如下步骤,获取用户语音输入,将用户语音输入识别、转化为文本输入,
对所述文本输入执行意图理解,根据意图理解的结果选择将文本输入送入开域对话及问答流程、任务式对话流程;
其中,开域对话及问答流程如下,
对文本输入计算第一句子向量;
根据第一句子向量与答案库中的问题的句子向量比对结果,找出与第一句子向量相似度最高的答案库中的问题;
返回该问题的答案;
任务式对话流程的步骤如下:
对文本输入计算第二句子向量;
根据第二句子向量与任务式对话库中任务代表句子的句子向量比对结果,找出相似度最高的任务代表句子,获取任务代表句子对应的任务;
获取任务代表句子对应的任务所要获取的信息;
检测所述文本输入中是否包含所述要获取的信息;
如果没有,则提示用户补充信息,直至所有要获取的信息均被检测到。
具体地,还包括步骤,在任务式对话步骤开始时,首先对用户分配一个临时ID,并保存每个ID与要获取的信息的获取状态的对应表。
进一步地,还包括步骤还包括步骤,在意图理解的部分设置优先级,即当开域对话及自定义问答流程、或任务式对话流程均可被选择时,按预设的优先级处理。
具体地,开域对话及自定义问答流程具体分为开域对话流程、自定义问答流程;设置所述任务式对话流程的优先级高于自定义问答流程,设置所述自定义问答流程高于开域对话流程。
进一步地,还包括步骤,构建标注语料库,并用该语料库训练一个开域对话模型,在进入开域对话及问答流程时直接使用该开域对话模型返回结果。
具体地,所述开域对话及问答流程的答案库通过语料库训练获得,所述语料库通过如下方式标注:
切分步骤:
获取N个待标注音频文件F1,F2,F3...FN,对每个待标注音频文件Fi,计算Mi个切分点,并将Fi切分为Mi+1个音频片段,i取值为1,2,3……N,与所述待标注音频文件的数量一致,将所有待标注音频文件切分形成的音频片段乱序处理,生成乱序处理后的音频片段集合As;
记录所有待标注音频文件的切分点位置,以及所述切分点位置与所述切分位置对应的所述音频片段集合As中的元素的对应关系,形成切分记录Rs;
处理步骤:
获取乱序处理后的音频片段集合As,
对乱序后的音频片段进行标注处理,形成标注记录Ls;
合成步骤:
获取标注记录Ls,
获取切分记录Rs,
利用Rs将Ls中的标注内容重组排列,使得重组后的标注内容的顺序与所述待标注音频文件的内容一致,形成重组标注记录RLs;重组标注记录RLs作为语料库,所述切分记录Rs对所述处理步骤StepP隔离。
进一步地,所述乱序处理后的音频片段集合As中,每两个相邻的音频片段以大于等于P1的概率不属于同一个待标注音频文件,以大于或等于P2的概率不是同一个待标注音频文件的相邻两个音频片段。
进一步地,生成乱序处理后的音频片段集合As之后还包括如下步骤:
将音频片段集合As的内的音频片段随机重命名,记录重命名后的音频文件和原待标注音频文件的对应关系,将音频片段集合As的音频片段以文件名首字母顺序排序。
进一步地,还执行校验重排操作:
获取两个相邻的音频片段属于同一个待标注音频文件的音频片段集合S1,获取两个相邻的音频片段是同一个待标注音频文件的相邻两个切分的音频片段集合S2,如果N(S1)/N(As)>1-P1,则将属于S1的音频片段文件再次随机重命名;
如果N(S2)/N(As)>1-P2,则将属于S2的音频片段文件再次随机重命名,其中N(S1)表示音频片段集合S1中符合的音频文件总数,N(S2)表示音频片段集合S2中符合的音频文件总数;
执行所述校验重排操作,直到满足条件“每两个相邻的音频片段以大于或等于P1的概率不属于同一个待标注音频文件,以大于或等于P2的概率不是同一个待标注音频文件的相邻两个切分”为止。
通过上述方案我们实现了一种人工智能对话方法,能够分析人工输入的文本信息,并进行分析,并通过解析结果得到答案库中的回答结果输出。
附图说明
图1为本发明具体实施方式所述的人工智能对话方法流程图;
图2为本发明具体实施方式所述的人工智能对话装置模块图。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
请参阅图1,一种人工智能对话方法,包括如下步骤,获取用户语音输入,将用户语音输入识别、转化为文本输入,
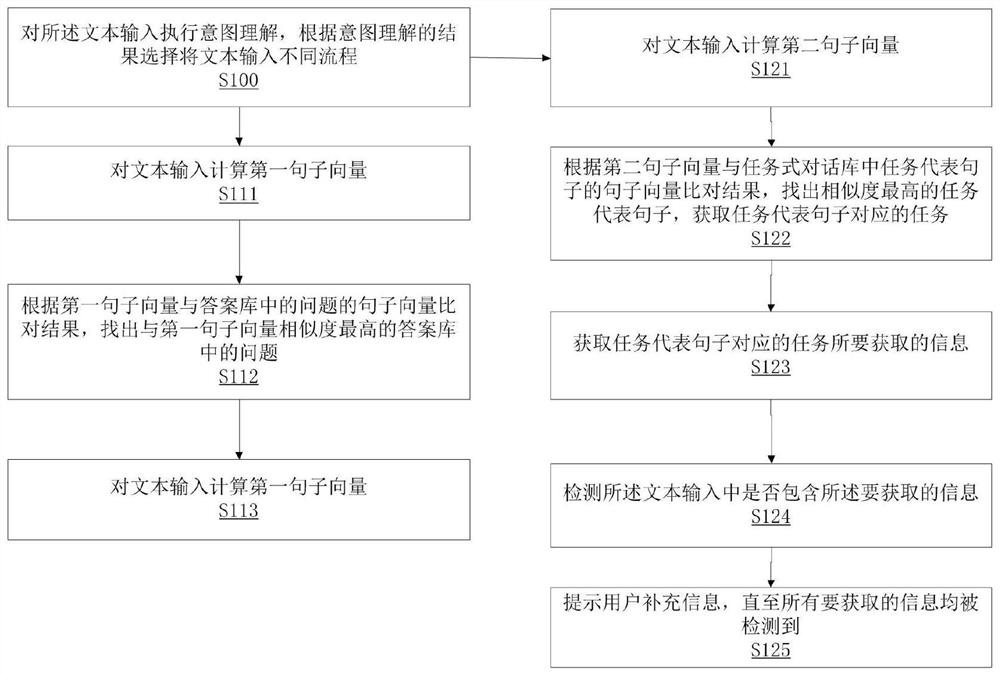
S100对所述文本输入执行意图理解,根据意图理解的结果选择将文本输入送入开域对话及问答流程S110、任务式对话流程S120;
其中,开域对话及问答流程如下,
S111对文本输入计算第一句子向量;
S112根据第一句子向量与答案库中的问题的句子向量比对结果,找出与第一句子向量相似度最高的答案库中的问题;
S113返回该问题的答案;这样就能够解决识别输入文本获得对应的答案输出的技术效果,解决人工智能对话的问题。
任务式对话流程的步骤如下:
S121对文本输入计算第二句子向量;
S122根据第二句子向量与任务式对话库中任务代表句子的句子向量比对结果,找出相似度最高的任务代表句子,获取任务代表句子对应的任务;
S123获取任务代表句子对应的任务所要获取的信息;
S124检测所述文本输入中是否包含所述要获取的信息;
如果没有,则S125提示用户补充信息,直至所有要获取的信息均被检测到。所述的句子向量为将句子文本进行向量化表达的结果,通过上述任务式对话步骤,能够通过句子向量比对的处理方式,获得文本输入中的信息最接近的任务代表句子,通过所述代表句子获取代表句子的任务,从而获取任务对应的信息,能够用于满足必要信息获取的需求。
在另一些具体的实施例中,还包括步骤,在任务式对话步骤开始时,首先对用户分配一个临时ID,并保存每个ID与要获取的信息的获取状态的对应表。通过对用户分配ID的做法,能够区分不同的对话任务进程,避免不同任务之间的影响。
其他一些进一步的实施例中,还包括步骤,在意图理解的部分设置优先级,即当开域对话及问答流程、或任务式对话流程均可被选择时,按任务式对话、开域对话及问答的优先级处理。通过设置优先级流程能够更好地处理文本信息输入进行人工智能对话的需求。
为了更好地进行人工智能的训练,还包括步骤,构建标注语料库,并用该语料库训练一个开域对话模型,在进入开域对话及问答流程时直接使用该开域对话模型返回结果。这里的标注可以是对语料的预处理,可以是赋予标签,如文件名、时长、情感倾向等等,还可以是对语料添加若干句子向量,即标注是对语料进行原文本外的信息附加,标注是可以由人工完成,也可以通过计算机程序自动完成。
在语音识别、对话系统等模型训练中,需要把音频人工转写为文本,或者先自动转写为文本,再由人工校验核对,完成后再进行模型训练,上述工作称为音频标注。本发明实施例提供的方案包括切分步骤StepS、处理步骤StepP和合成步骤StepC。在具体的实施例中,所述开域对话及问答流程的答案库通过语料库训练获得,所述语料库通过如下方式标注:
切分步骤:
获取N个待标注音频文件F1,F2,F3...FN,这些待标注音频文件的一个来源是电话录音,譬如银行客服电话、健康咨询电话等,每个音频文件通常是一整个电话的录音,因此包含了一定的隐私安全信息。
对每个待标注音频文件Fi,计算Mi个切分点,并将Fi切分为Mi+1个音频片段,i取值为1,2,3……N,与所述待标注音频文件的数量一致,与所述待标注音频文件的数量一致,切分方式可以是按固定时长切分,更优的方式是可以通过VAD语音端点检测,以每个VAD检测的开始端点为切分点,进一步的优化可以是将切分后的音频片段合并为时长大致相当的片段,譬如合并切分后的音频片段,使得合并后的音频片段的最大时长不超过最小时长的2倍。这样处理的技术效果包括容易计算切分人员的工作量。
将所有待标注音频文件切分形成的音频片段乱序处理,生成乱序处理后的音频片段集合As;注意集合As是可被排序的,包括通过文件名字母顺序、文件时长大小、文件修改时间等;
记录所有待标注音频文件的切分点位置,以及所述切分点位置与所述切分位置对应的所述音频片段集合As中的元素的对应关系,形成切分记录Rs;
处理步骤StepP:
获取乱序处理后的音频片段集合As,
对乱序后的音频片段进行标注处理,形成标注记录Ls;
合成步骤:
获取标注记录Ls,
获取切分记录Rs,
利用Rs将Ls中的标注内容重组排列,使得重组后的标注内容的顺序与所述待标注音频文件的内容一致,形成重组标注记录RLs;重组标注记录RLs作为语料库,所述切分记录Rs对所述处理步骤StepP隔离。通过上述设计的标注过程,能够使得音频文件的整体与音频片段的对应关系相对于标注步骤保密或隔离,在这一点上能够使得在标注时不会泄露整段的音频文件,也让自动标注的程序对音频片段的处理不会被音频文件影响。
在进一步的其他一些实施例中,所述乱序处理后的音频片段集合As中,每两个相邻的音频片段以大于等于P1的概率不属于同一个待标注音频文件,以大于或等于P2的概率不是同一个待标注音频文件的相邻两个音频片段。通过上述避免相邻的音频片段过于接近从而导致不必要的信息泄露。
为了让音频片段集合中的音频片段的文件名被用于音频片段的还原,生成乱序处理后的音频片段集合As之后还包括如下步骤:
将音频片段集合As的内的音频片段随机重命名,记录重命名后的音频文件和原待标注音频文件的对应关系,将音频片段集合As的音频片段以文件名首字母顺序排序。同样的,为了避免其他信息造成不必要的信息泄露,还可以将音频片段的时间戳也进行随机生成,按照新生成的时间戳进行随机排序。还可以对所述音频片段集合As中的每个音频片段的时长进行随机微调,或对所述音频片段集合As中的每个音频片段的文件创建修改时间进行修改混淆。
所述乱序处理后的音频片段集合As中,每两个相邻的音频片段以大于或等于P1的概率不属于同一个待标注音频文件,以大于或等于P2的概率不是同一个待标注音频文件的相邻两个切分。譬如,P1为0.8且P2为0.9,更优的,P1为0.99且P2为0.999。具体处理方式可以是先将音频片段集合As的音频文件随机重命名,并记录重命名后的文件和原文件的对应关系,该对应关系被设置为标注人员不可见,譬如可以保存至切分记录Rs中,然后将音频片段集合As的音频文件以文件名字母顺序排序,然后执行校验重排操作:获取两个相邻的音频片段属于同一个待标注音频文件的音频片段集合S1,获取两个相邻的音频片段是同一个待标注音频文件的相邻两个切分的音频片段集合2,如果N(S1)/N(As)>1-P1,则将属于S1的音频片段文件再次随机重命名,如果N(S2)/N(As)>1-P2,则将属于S2的音频片段文件再次随机重命名,其中N()表示音频片段集合中的音频文件总数。可以执行以上校验重排操作多次,直到满足条件“每两个相邻的音频片段以大于或等于P1的概率不属于同一个待标注音频文件,以大于或等于P2的概率不是同一个待标注音频文件的相邻两个切分”为止。这样处理的好处包括使得标注人员不容易找出具有关联性的音频片段,从而提高了安全保密性。
为进一步提高安全保密性,还可以进一步对每个音频片段的时长进行随机微调,包括通过添加静音段、重采样/改变采样率等方法。也可以进一步对文件创建修改的时间进行修改混淆。
在其他一些进一步的实施例中,还执行校验重排操作:
获取两个相邻的音频片段属于同一个待标注音频文件的音频片段集合S1,获取两个相邻的音频片段是同一个待标注音频文件的相邻两个切分的音频片段集合S2,如果N(S1)/N(As)>1-P1,则将属于S1的音频片段文件再次随机重命名;
如果N(S2)/N(As)>1-P2,则将属于S2的音频片段文件再次随机重命名,其中N(S1)表示音频片段集合S1中符合的音频文件总数,N(S2)表示音频片段集合S2中符合的音频文件总数;
执行所述校验重排操作,直到满足条件“每两个相邻的音频片段以大于或等于P1的概率不属于同一个待标注音频文件,以大于或等于P2的概率不是同一个待标注音频文件的相邻两个切分”为止。通过上述方案进行的校验重排,能够使得音频片段集合中的随机性能够得到保证,防止信息泄露的发生。
在一些实施例中,P1为0.8且P2为0.9。
另一个实施例中,P1为0.99且P2为0.999。
所述切分记录Rs对所述处理步骤StepP隔离,具体为,仅负责执行处理步骤的StepP的子设备,被设置为不获取所述切分记录Rs的相关内容。
又或,所述切分记录Rs对所述处理步骤StepP隔离,具体为,仅负责执行处理步骤的StepP的子设备,被设置为可以获得切分记录Rs的加密后的表现形式,如切分记录Rs相关的切分后的音频文件片段的数据包,但不获取可以用于解密的所述切分记录Rs的加密形式的密钥信息。
又或,所述切分记录Rs对所述处理步骤StepP隔离,具体为,仅负责执行处理步骤的StepP的子设备,被设置为不获取所述切分记录Rs的内容,但可以获取由Rs通过不可逆推原始内容的操作处理后获得指纹信息。
语料库的标注过程中,N个待标注音频文件的内容是语音录音。
在其他一些实施例中,请参阅图2,为一种人工智能对话装置,包括获取识别模块20、意图理解模块24、开域对话问答模块21、任务式对话模块22,所述获取识别模块用于获取用户语音输入,将用户语音输入识别、转化为文本输入,
所述意图理解模块24用于对所述文本输入执行意图理解,根据意图理解的结果选择将文本输入送入开域对话问答模块、任务式对话模块;
所述开域对话问答模块用于执行开域对话及自定义问答流程,开域对话及自定义问答流程如下,
对文本输入计算第一句子向量;
根据第一句子向量与答案库中的问题的句子向量比对结果,找出与第一句子向量相似度最高的答案库中的问题;
返回该问题的答案;
所述任务式对话模块用于执行任务式对话流程,任务式对话流程如下:
对文本输入计算第二句子向量;
根据第二句子向量与任务式对话库中任务代表句子的句子向量比对结果,找出相似度最高的任务代表句子,获取任务代表句子对应的任务;
获取任务代表句子对应的任务所要获取的信息;
检测所述文本输入中是否包含所述要获取的信息;
如果没有,则提示用户补充信息,直至所有要获取的信息均被检测到。
具体地,所述任务式对话模块还用于,在任务式对话步骤开始时,首先对用户分配一个临时ID,并保存每个ID与要获取的信息的获取状态的对应表。
具体地,对于分配了临时ID的用户,检测其是否与服务器保持连接,如果超过一定时长T未与服务器保持连接,则销毁所述临时ID。
进一步地,所述获取识别模块还用于在意图理解的部分设置优先级,即当开域对话及自定义问答流程、或任务式对话流程均可被选择时,按预设的优先级处理。
优选地,开域对话及自定义问答流程具体分为开域对话流程、自定义问答流程;设置所述任务式对话流程的优先级高于自定义问答流程,设置所述自定义问答流程高于开域对话流程。
进一步地,还包括模型标注训练模块23,所述模型标注训练模块用于构建标注语料库,并用该语料库训练一个开域对话模型,在进入开域对话流程时直接调用该开域对话模型返回结果。
具体地,所述开域对话流程的答案库通过语料库训练获得,所述语料库通过上述方式处理,此处不再赘述。
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 模型训练方法和装置及人工智能对话的识别方法和装置
- 一种人工智能对话的知识检索方法及知识库自动完善方法