人类表型标准用语提取方法
文献发布时间:2023-06-19 11:27:38
技术领域
本发明属于生物信息领域,尤其涉及医学电子病历中人类表型标准用语的提取方法。
背景技术
本部分的陈述仅是提供了与本公开相关的背景技术,并不必然构成现有技术。
人类表型是临床数据和医学文献数据中重要的实体性信息,是医生诊断与治疗的主要依据。而电子病历中的表型信息往往都是非结构化数据,且以自然语言形式存在,给后续进行病历数据的应用带来困难。因此,对于病历数据的应用,需要根据具体情况进行文本的分析和信息抽取。
人类遗传性疾病的发病率和死亡率有逐年增高的趋势,人类的遗传性疾病已经成为威胁人类健康的一个重要因素,严重的遗传性疾病每年影响全世界700多万新生儿,而这些疾病往往又进展很快。因此,诊断这些疾病迫在眉睫,并且要求疾病诊断的时间要尽可能缩短。但是,手动诊断和评估病历会浪费大量时间及精力。一般来说,识别患者的致病基因一般需要花费一周左右的时间,而且还可能受到临床医生的主观影响,受限于临床医疗专家的医疗水平,无法针对相关性不明显的疾病做出诊断。如果能自动对患者的疾病进行识别,或者自动找出患者疾病和自身基因变异的对应关系,来辅助医生诊断,将大大减少医生做出诊断的时间,给患者赢得宝贵的治疗时间。但是,电子病历、医学文献等信息中对病人疾病表型的描述往往都是非结构化数据,且以自然语言形式存在,这严重阻碍了使用自动方法对疾病进行识别、或者对基因突变和疾病的对应关系识别。因此,临床数据中人类表型标准用语的自动提取非常重要。
传统方法中,基于规则的方法依赖于现有的医学词汇,如正则表达式的运用,但基于人工总结的规则和模板常常难以覆盖各种语言现象,且泛化能力较差,领域可移植性不佳,研究者们很难设计出完整的规则来覆盖各种情况。基于字典的方法因简单性被广泛使用,通过计算语义相似度,可以通过字典中已有的词来对目标概念进行标注;但是,该方法过分依赖外部数据的规模和质量,且搜集语料的过程耗费大量人力资源。
目前,自动提取人类表型标准用语的方法大多将自然语言的描述与标准用语库进行匹配,根据计算所得的相似度找出相对应的HPO标准词汇。Human Phenotype Ontology(HPO)是人类表型本体论,HPO目前包含13000多个术语和156000多个遗传病注释,提供了人类疾病中遇到的表型异常的标准化词汇。HPO的每个术语都描述一种表型异常,例如:HP:0001250是Seizures(癫痫发作)的ID。
发明内容
针对现有技术中存在的问题,本公开提供了一种从临床电子病历进行人类表型标准用语提取的方法。
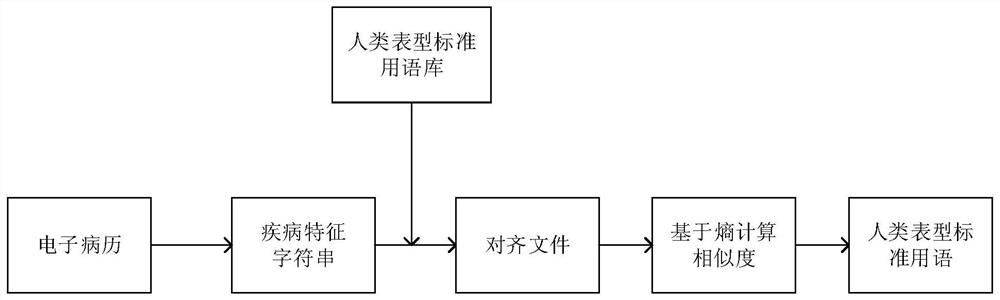
通常,对于非结构化的电子病历,需要先利用自然语言处理算法进行分词、词形还原以及去除停用词等预处理。在预处理完的电子病历中,再进行疾病特征字符串的识别与人类表型标准用语的转换。
本发明的实施例提供了一种基于熵的人类表型标准用语的提取方法,包括如下步骤:
(1)对电子病历数据进行分析提取,获得疾病特征字符串;
(2)将疾病特征字符串与人类表型标准用语库中的每个记录进行字符串匹配,标记出疾病特征字符串与人类表型标准用语库中每个记录的匹配关系,生成对齐文件;
(3)对生成的对齐文件进行块划分,得到块划分文件;
(4)根据块划分文件进行熵计算,获得疾病特征字符串与人类表型标准用语库中每个记录的相似度,根据最高相似度提取对应的人类表型标准用语。
步骤(1)中,对电子病历数据进行分析提取,根据自定义规则:由标点符号、否定词以及连接词(包括and,but等)进行电子病历数据的切分。首先按照第一类标点符号和否定词进行第一级切分,然后在第一级切分结果中,若出现否定词(比如not)则直接筛除,然后在这个基础上按照第二类标点符号以及连接词进行第二级拆分,从而得到疾病特征字符串;其中,第一类标点符号包括句号、感叹号和分号,第二类标点符号包括逗号和顿号。
本公开中,人类表型标准用语库包括:人类表型标准用语的名称及其定义,以及人类表型标准用语的同义词。其中,人类表型标准用语库中每一个标准用语及其对应的定义以及同义词,划分为一组,组内的每一项为一条记录。部分示例如图2所示。将提取出的疾病特征字符串与人类表型标准用语库中的记录进行对齐,在对齐之后进行块划分操作得到块划分文件,然后根据块划分文件进行熵计算获得疾病特征字符串与人类表型标准用语库中的记录的相似度,最后根据最高相似度提取出相对应的人类表型标准用语。本发明的方法摆脱了N-gram的限制,可以获得最大匹配长度的字符串,经过试验证实,可以显著提高提取的准确率。相较于ClinPhen方法,本发明在精确率上有明显提高。
附图说明
图1为本公开实施例中人类表型标准用语提取方法的流程图;
图2为人类表型标准用语库部分示意图;
图3为本公开的实施方式中对齐方法示意图;
图4为本公开的实施方式中块划分方法示意图。
具体实施方式
为了使本发明更加清楚,下面将结合附图和具体实例对本发明进行详细描述。
需要说明,以下实施例中采用的人类表型标准用语库是英文的,以英文电子病历进行验证,但本公开的方法同样适用于中文版本的人类表型标准用语库和病历。
本公开的实施例提供一种基于熵的人类表型标准用语提取方法,以提高人类表型标准用语提取的精确度。
香农将信息熵定义为离散随机事件出现的概率,假设X是一个离散型随机变量,取值空间为R,其概率分布为:
p(x)=P(X=x),x∈R (1.1)
X的熵H(X)定义为:
在公式(1.2)中,对数以2为底,公式定义的熵的单位为二进制位,即比特,通常将log2p(x)简写为logp(x)。
熵是一个变量不确定性度量,在本公开的方法中,熵可以用来反应提取出的疾病特征字符串和人类表型标准用语库中的记录所匹配上的片段的分布情况。熵越低,说明匹配上的片段的分布情况越集中,即匹配块越完整;反之,熵越高,说明匹配上的片段的分布情况越分散,匹配块越分散,流利性越差。
如图1所示,本实施例提供了一种人类表型标准用语的提取方法,包括如下步骤:
(1)对电子病历数据进行分析提取,获得疾病特征字符串;
根据自定义规则:由标点符号,否定词(not)以及连接词(包括and和but)进行电子病历数据的切分,首先按照第一类标点符号(包括句号、感叹号和分号)进行第一级切分,第一级切分结果中若出现否定词(比如not),直接筛除,然后在这个基础上,按照第二类标点符号(包括逗号、顿号)以及连接词进行第二级拆分,从而得到疾病特征字符串。
(2)将疾病特征字符串与人类表型标准用语库中的每个记录进行字符串匹配,标记出疾病特征字符串与人类表型标准用语库中每个记录的匹配关系,生成对齐文件;
首先,标记出在疾病特征字符串和人类表型标准用语库中每个记录的匹配情况,在标记出所有的匹配关系之后,在匹配关系的集合中,通过一定的规则找出每一个对齐,具体规则如下:每一个匹配都对应着疾病特征字符串与人类表型标准用语库中记录的一条连线,对于每个记录,选取交叉线最少的一组匹配关系,作为该记录与疾病特征字符串的对齐,对齐方式如图3所示。疾病特征字符串和人类表型标准用语库中每个记录的对齐为一一对应,即疾病特征字符串的一个词最多与人类表型标准用语库中一个记录的一个词相匹配,反之,人类表型标准用语库中一个记录的一个词也最多与疾病特征字符串中的一个词相匹配。
(3)对生成的对齐文件进行块划分,得到块划分文件;
块划分方式如图4所示,在做完对齐后,需要将对齐文件划分为块,要求每个块内的两个字符串中匹配上的词在疾病特征字符串内的位置是连续的,并且映射到人类表型标准用语库中的记录上的位置也是连续的,并且每个块应为最大连续的字符串匹配,从而得到块划分文件。
(4)根据块划分文件进行熵计算,获得疾病特征字符串与人类表型标准用语库中的每个记录的相似度,然后提取相似度最高的一条记录所对应的组中的人类表型标准用语。
在做好对齐文件与块划分后,对分块情况进行熵计算。所示熵计算包括:根据块划分文件的分块信息计算熵,对熵进行归一化,结合归一化的熵和F度量值得到疾病特征字符串与人类表型标准用语库中的每个记录的相似度。
根据分块信息计算熵的公式如下:其中,li代表第i个块的长度,即词的个数;c代表块的个数;L代表所有匹配上的词的个数。
为了把熵的值限定在(0,1)之间,需要对上述获得的熵进行归一化,采取的方法是对上述公式应用以e为底的指数函数。使用entropy来表示归一化后的熵。对分块信息的熵进行归一化,计算公式如下,
entropy=e
最后,结合归一化的熵和F度量值得到疾病特征字符串与人类表型标准用语库中的每个记录的相似度。具体如下:
步骤A:用F度量值来评价疾病特征字符串和人类表型标准用语库中每个记录的一致性。计算方式如(1.5)所示,其中β为精确率分配的权重,0﹤β﹤1,precision是精确率,recall是召回率。
步骤B:将F度量值引入entropy中,通过结合归一化的熵和F度量值得到疾病特征字符串与人类表型标准用语库中的每个记录的最终相似度,得到Sim即相似度,计算公式如(1.6)所示
Sim=e
通过相似度大小便可以提取出与疾病特征字符串相对应的相似度最高的人类表型标准用语。
步骤A中使用参数β,可以动态调整精确率和召回率的权重,从而得到更高的F度量值,进而得到更高的相似度Sim,使结果更加精确。
在本公开的一种实施方式中,β为1/2。
- 人类表型标准用语提取方法
- 一种人类表型标准用语确定方法及装置