一种基于“层次分析-神经网络”的食用油安全预警方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及食品安全技术领域,尤其涉及一种基于“层次分析-神经网络”的食用油安全预警方法。
背景技术
食用油作为人体所需的重要营养物质之一,是我们日常生活不可缺少的必需品,对人体的健康发挥着重要的作用。但是目前仍然存在质量安全问题,引起广大消费者和政府部门的广泛关注。食用油的质量安全问题主要来自种植过程中带来的重金属污染、加工过程中带来的苯并芘、反式脂肪酸以及浸出毛油中的溶剂超标问题、储藏过程中油脂出现氧化、酸败,导致酸价和过氧化值升高等。为此各国食品质量安全监管部门都会定期对市场上食用油进行抽检,检测其中的危害物是否超标,营养物质是否达标。然而如何根据食用油的检查结果数据,对其进行安全评价和预警,形成一道安全防线,是一个亟待解决的问题。
层次分析法(Analytic Hierarchy Process,AHP)是一种定性和定量相结合、系统化和层次化的分析方法。主要解决多目标的复杂问题。由于不同食品安全风险评价指标之间没有明确的定量关系,因此可以采用AHP算法确定各个风险评价指标的权重。但是传统的层次分析法需要研究人员通过经验构造判断矩阵,人为主观性太强,过于强调经验的作用。熵权法仅依赖于数据本身的离散性,是一种客观赋权法。将熵权法引入指标权重的判断过程。相对于传统的层次分析法,层次分析法和熵权法相结合兼顾了主观与客观因素,更具有合理性。
长短期记忆(Long Short-Term Memory,LSTM)神经网络,通过设计控制门结构弥补了循环神经网络(Recurrent Neural Network,RNN)的梯度消失和梯度爆炸、长期记忆能力不足等问题,使得RNN能够真正有效地利用长距离的时序信息。LSTM神经网络在挖掘序列数据长期依赖关系中极具优势。LSTM神经网络主要解决了数据分类问题,并且由于可以完美地模拟多个输入变量的问题,也可以用于时间序列预测。食用油安全检测数据具有多变量以及时序的特点,因此可以用LSTM模型对食用油安全检测数据进行预测。
发明内容
本申请的目的在于提供一种基于AHP-LSTM的食用油安全预警方法,以预测食用油潜在的风险,为食用油安全监管提供支持。
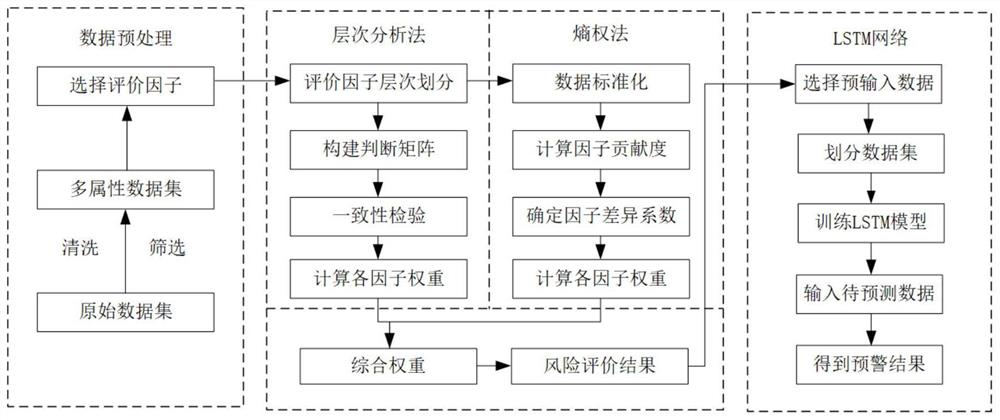
为实现上述目的,本发明提供了一种基于AHP-LSTM的食用油安全预警方法。首先对食用油检测结果数据进行预处理,从中选择能够反映食用油安全性的评价因子;其次分别利用层次分析法和熵权法,通过结合以上所选取的多个评价因子,对食用油安全性进行综合评价,并将两种方法的评价结果进行融合,得到风险指数,进而划分为3个风险等级(而不只是“合格”、“不合格”2个风险等级)。通过这种方法可以更精准有效的发现具有安全风险的食用油样品;最后利用LSTM神经网络模型,对已有的食用油检测数据集进行学习,确定模型参数并生成预警模型。后期应用该预警模型,通过输入新的食用油样品的检测结果,就可以在输出端得到预测结果,即该样品的风险等级。此方法能够发现食用油潜在的安全风险,从而为食用油安全监管提供决策支持。具体步骤如下:
A.对食用油原始检测结果数据集进行预处理。对数据集进行清洗和筛选,删除数据值缺失的无效数据,得到多属性数据集,再从多属性数据集中选择能够反映食用油安全性的评价因子(指标),将每一个样品中检出的多项指标合并为一条记录,得到评价因子数据集。
B.对步骤A中得到的评价因子数据集根据因子的分类进行层次划分,并使用层次分析法计算各评价因子的权重,最终得到各个评价因子的权重Θ=(θ
C.对步骤A中得到的评价因子数据集进行数据标准化,并使用熵权法计算各评价因子的权重,最终得到各个评价因子的权重W=(w
D.将步骤B中运用层次分析法获得的主观权重Θ与步骤C中运用熵权法获得的客观权重W 进行综合,运用公式
E.通过步骤A中的评价因子数据集中各评价因子数值运用公式
F.将已有的食用油的检测结果以及步骤E中得到的风险等级作为LSTM神经网络的输入进行训练,确定LSTM模型的各参数,得到预警模型。后面就可以应用此模型,将未来食用油样品的检测结果作为模型输入,模型输出即为该样品风险等级的预测结果。
下面对上述步骤B、C、F做进一步说明。
上述步骤B是使用层次分析法计算各评价因子的权重,其具体计算过程如下:
B1.根据评价因子的分类进行层次划分,如图3所示,包括了目标层、准则层和方案层。其中目标层为对食用油进行综合评价,方案层为食用油中各评价因子(如铅、总砷、过氧化值等),准测层为各评价因子的分类(如重金属、品质指标等)。
B2.构造判断矩阵确定各评价因子权重。为定量地评价各因子重要性,采用矩阵标度(1~ 9标度法)确定因子的重要性之比,构建每一层的判断矩阵H,
计算最大特征向量。将判断矩阵的每一列进行归一化,即归一化后的元素值=每个元素值 /该列元素值之和,得到矩阵
表1:矩阵标度表
B3.对判断矩阵进行一致性检验,使其在一个可允许的范围里,检验过程所需公式如公式 (1.1)(1.2):
式中:CI为一致性指数;CR为一致性比率,用于确定判断矩阵的不一致性的容许范围;k是该层的评价因子个数,λ
表2:RI与k对照表
当CR<0.1时,表明矩阵的不一致程度在可允许范围内,则λ
B4.特征向量Θ为层次分析法得到的各评价指标权重。
上述步骤C是使用熵权法计算各评价因子的权重,其具体计算过程如下:
C1.对步骤A中得到的评价因子数据集进行数据标准化,评价因子数据集表示为矩阵
C2.计算因子贡献度,熵值法根据评价因子提供信息量的重要性确定其对最终评价结果的权重,若某评价因子在不同样品中的检测结果相差很大,则该类检测项目在比较时具有更大的影响,应该具有更高的权重。因此需要利用公式(1.3)进行贡献度的计算:
其中p
C3.根据因子贡献度,利用公式(1.4)(1.5)(1.6)计算因子间的差异系数:
q=1/lnm (1.5)
d
式中:e
C4.根据因子差异系数,计算各评价因子权重如公式(1.7):
其中w
上述步骤F是对LSTM神经网络的输入进行训练,得到AHP-LSTM预警模型,其具体计算过程如下:
F1.将步骤E中得到的各评价因子数据与各指标限量标准之比数据集Z,与每个样品对应的风险等级按样品采样时间进行排序,得到食用油的时序数据集,其中数据集中一行为一个样品,行数为样品数,列数为变量总数。
F2.将步骤F1中得到的食用油的时序数据集输入到LSTM网络中进行训练,得到预测模型。其中评价因子为输入变量,风险等级为输出变量。
LSTM网络模型训练过程如下:
S1.首先前向计算每个LSTM神经元的输出值,具体为:
i
f
o
h
其中,t为时间步,x
输出的激活函数为tanh函数,其中tanh函数为:
长短期记忆网络输入门的输入为当前时间步输入x
长短期记忆需要计算候选记忆细胞
通过元素值域在[0,1]的输入门、遗忘门和输出门来控制隐藏状态中信息的流动。当前时间步记忆细胞c
有了记忆细胞以后,可以通过输出门来控制从记忆细胞到隐藏状态h
S2.再反向计算LSTM每个神经元的误差项δ的值,并将误差项向上一层传播。
在t时刻,LSTM的输出值为h
其中E为全局误差,
计算出t-1时刻的误差项δ
其中
权重矩阵W
S3.根据相应的误差项,计算每个权重的梯度。
用公式(1.21)-公式(1.32)分别计算W
训练集中的样品数据作为LSTM网络的输入,每个时间步输入一个带有风险等级标签的样品数据,LSTM网络进行一次前向计算和反向计算,前向计算更新t时刻记忆细胞c
F3.将最新的食用油样品检测数据x
本发明有益成果:
本发明的技术方案,给出了一种基于AHP-LSTM的食用油安全风险预警的方法。该方法首先用层次分析法从主观上对食用油各评价指标进行主观评价,用熵权法从客观上对食用油各评价指标进行客观评价,再用基于AHP-E方法对食用油安全性进行综合评价,得到每一个样品的风险等级,更精准的发现具有安全风险的食用油样品,同时也可以达到自动给食用油样品打标签(定风险等级)的效果;进而利用LSTM网络,对已打标签的食用油检测数据集进行学习,并生成预警模型。以后就可以直接应用此模型,将未来食用油样品的检测数据作为模型输入,模型输出即为该样品风险等级的预测结果。所述方法通过AHP-E的方法兼顾了主观与客观因素,避免了风险评价过程中可能因为过于依赖研究者的判断从而导致的误判,并能够有效发现具有潜在风险的食用油;所述方法通过基于LSTM的预警模型,可以实现对食用油检测结果进行快速污染等级判定。本申请所述方法可用于对食用油安全潜在的风险进行预警,帮助监管人员及时发现可能存在的高风险食用油食品,并设置应对的保障方案,以保障食用油的安全性以及可靠性。
附图说明
图1为基于AHP-LSTM方法的食用油安全预警方法流程图;
图2为层次分析法的层次划分结构图;
图3为食用油样品的层次划分结构图;
图4为层次分析法得到的各评价因子权重图;
图5为熵权法得到的各评价因子权重图;
图6为层次分析法以及熵权法得到的综合权重图;
图7为LSTM网络隐藏状态图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于AHP-LSTM模型的食用油预警方法。其步骤如图1所示,具体如下。
A.数据预处理
本实验数据为2016年1月至2016年8月某海关进口食用油检测结果数据集,共有来自 54个国家或地区的7516条检测结果,其中含有1031个样品,102个检测指标,对原始数据进行预处理,得到食用油的多属性数据集,如表3所示。
表3:数据预处理后食用油检测结果数据集(部分)
其中,数据预处理包括但不限于:删去异常值;令检测结果为“未检出”的数据取值为 0.001;将检测结果为空的数据用“0.001”填充。
选择可以直接影响食用油安全性的检测项目作为评价因子。其中,本次实验选择了检测次数大于全部样品数量50%以上(515次)的检测项目作为评价因子,在食用油检测数据集中选择酸价、苯并(a)芘、溶剂残留、过氧化值、总砷等7个指标作为评价因子,评价因子取值表如表4所示。
表4:食用油检测数据集中评价因子取值表(部分)
B.使用层次分析法计算步骤A中得到的7个评价因子的权重。
B1.进行评价因子的划分。根据评价因子的分类将评价因子分为重金属、品质指标和污染物与微生物三类。其中铅和总砷为重金属,过氧化值和酸价为品质指标,苯并(a)芘、溶剂残留和黄曲霉素B1为污染物与微生物。如图3所示。
B2.构造判断矩阵确定评价因子权重。为定量评价因子重要性,采用矩阵标度(1~9标度法)确定因子重要性之比,构建由k个因子两两对比得到的判断矩阵。通过专家的经验判断,分别得到如下四个判断矩阵(不同专家可能给出不同的判断矩阵):
判断矩阵A:
其中A
判断矩阵B:
其中B
判断矩阵C:
其中C
判断矩阵D:
其中D
对矩阵A每一列进行归一化得到矩阵
用同样的方法可以得到判断矩阵B、C、D的各因子权重
B3.对步骤B2中四个判断矩阵进行一致性检验,使其在一个可允许的范围里,检验过程所需公式(2.1)、(2.2)如下:
式中:CI为一致性指数;CR为一致性比率,用于确定判断矩阵的不一致性的容许范围; k是该层的评价因子个数,λ
经过计算得到判断矩阵A的CI=0.019,CR=0.037<0.1,满足一致性检验;由于判断矩阵 B、C只有两个因子,所以无需做一致性检验;判断矩阵D的CI=0,CR=0,满足一致性检验。
B4.得到层次分析法的评价因子权重值
结果如表5、图4所示。
表5:基于层次分析法(AHP)的评价因子权重值
C.使用熵权法计算步骤A中得到的7个评价因子的权重。
C1.对步骤A中的7个评价因子利用公式
表6:标准化后数据(部分)
C2.计算因子贡献度。利用以下公式(2.3)对步骤C1中标准化后的数据进行贡献度计算:
其中y
C3.根据步骤C2中计算出的因子贡献度计算因子间的差异系数,公式(2.4)(2.5)(2.6) 如下:
k=1/lnm (2.5)
d
其中:e
C4.通过步骤C3中得到的差异系数d
其中w
C5.得到熵权法的评价因子权重值
结果如表7、图5所示。
表7:基于熵权法(E)的评价因子权重值
D.计算综合权重。
将步骤B中运用层次分析法获得的主观权重Θ与步骤C中运用熵权法获得的客观权重W进行综合,运用公式
表8:基于AHP-E得到的综合权重
E.计算步骤A中表4的各评价因子值与食用油中各评价因子限量标准之比,如表9所示。将步骤D中计算出的综合权重值与各评价因子值与食用油中各评价因子限量标准之比进行加权求和,得到各个样品的风险指数,如表10所示。
表9:各评价因子值与食用油中各评价因子限量标准之比(部分)
表10:各样品风险指数和风险等级(部分)
并对风险指数进行分级,由大到小排列,风险指数大于0.8为高风险等级(3级),风险指数在0.4-0.8为中风险等级(2级),小于0.4为低风险等级(1级)。
计算结果为:在1031个样品中,高风险样品7个,中风险样品16个,低风险样品1008个。
F.将步骤E中得到的各评价因子值与食用油中各评价因子限量标准之比数据集与各样品风险等级数据集,并根据采样时间将样品进行排序,得到LSTM网络预输入数据集,结果如表 11所示。
表11 LSTM网络预输入数据集(部分)
将数据集的前80%作为训练集(共825条样品数据),后20%为测试集(共206条样品数据)。
将训练集作为LSTM网络的输入,借助Python中的keras库建立LSTM预测模型。其中总砷、过氧化值、酸价、苯并(a)芘、溶剂残留、黄曲毒素R1、铅7个风险因子作为模型输入,风险等级作为模型预测输出。
如图7所示,t时刻输入样品数据x
i
f
o
h
其中,t为时间步,x
输出的激活函数为tanh函数,其中tanh函数为:
从训练集中的第一条数据开始输入样品数据进入LSTM网络中进行训练,直到训练集最后一个样品数据输入完,通过借助Python中的keras库可以确定此刻LSTM网络中的权重矩阵W
测试数据集将样品的风险等级删去,仅保留采样时间和7个评价因子的检测值,如表12 所示。
表12:测试数据集(部分)
将测试集中数据输入到生成的LSTM模型中,得到预测出的风险等级结果,与样品真实的风险等级进行对比,为了减少随机性,重复建立五次模型,取五次预测出的样品风险等级的平均值作为预测结果。测试集中的206条样品数据,共有198条预测正确,有8条预测错误,得到的平均预测正确率为198/206=96.1%,证明了模型的有效性。测试数据集输入中,预测出有3个高风险样品和5个中风险样品,如表13所示。
表13:测试数据集中预测出的中高风险等级样品
监管人员可以通过将最新食用油样品的检测项目结果放入训练好的AHP-LSTM模型中,得到该样品的风险等级,从而能够及时发现潜在的高风险食用油,并设置应对的保障方案,以保障食用油的安全性以及可靠性。
以上所述实施例仅表达了本申请的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。
- 一种基于“层次分析-神经网络”的食用油安全预警方法
- 一种基于层次分析法及灰色理论的企业安全风险预警方法