一种单模板工作流优化方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及深度学习和图像文字识别领域,具体提供一种单模板工作流优化方法。
背景技术
单模板工作流能够自主构建文字识别模板,识别模板图片中的文字,提供高精度的文字识别模型,保证结构化信息提取精度,其中图像OCR文本识别的可用性是单模板工作流在框选参照字段、框选识别区和评估应用阶段的关键指标,如图4所示。
图片进行文本信息提取主要基于光学字符识别(Optical CharacterRecognition,OCR)技术实现,优化较好的OCR技术已可以正确识别大部分的文本内容,但是仍存在部分形似文本的识别错误。
文本纠错问题伴随计算机技术发展,目前国内外有大量科研工作者在做相关领域的研究。文本纠错主要分为两部分,第一步是错误检测,第二步是错误纠正。目前比较主流的做法是在错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误,整合这两种粒度的疑似错误结果,形成疑似错误位置候选集。
错误纠正部分是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
对此,如何提高图像经过OCR转换后文本的可用性成为单模板工作流的瓶颈之一。
发明内容
本发明是针对上述现有技术的不足,提供一种实用性强的单模板工作流优化方法。
本发明解决其技术问题所采用的技术方案是:
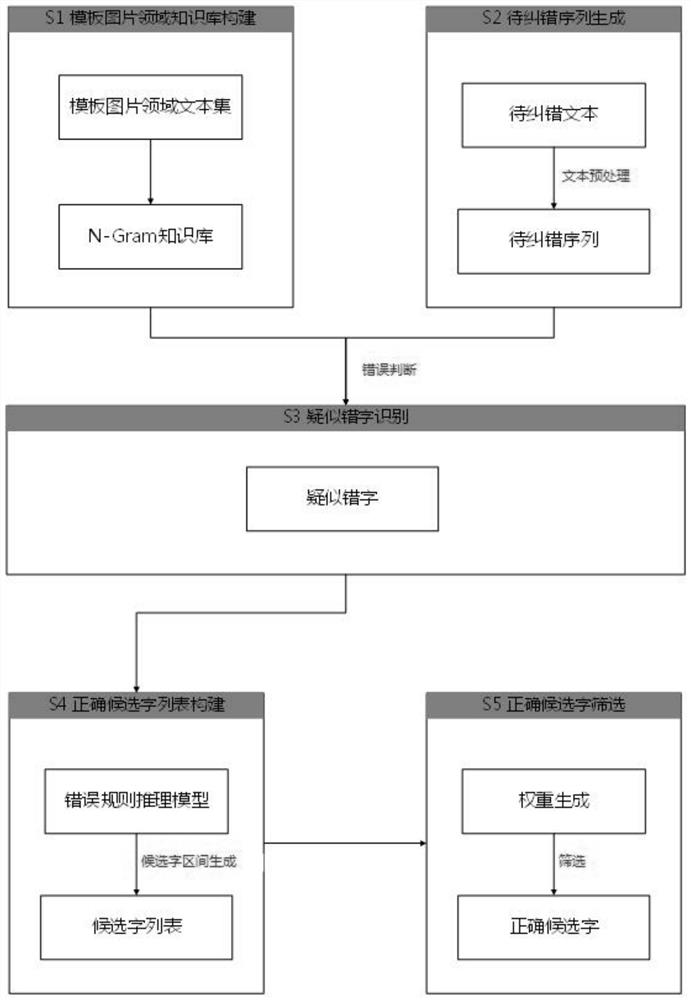
一种单模板工作流优化方法,具有如下步骤:
S1、构建模板图片领域的N-Gram知识库;
S2、预处理OCR纠错文本为待纠错序列;
S3、将识别疑似错字;
S4、基于错误规则推理模型,构建正确候选字列表;
S5、利用候选字筛选算法进行综合权重生成,对权重进行排序,权重最高的字则为当前待纠错文本中错误字的正确字。
进一步的,在步骤S1中,对收集的模板图片领域文本集进行BiGram切分,分析和统计领域文本集中的字词搭配,生成模板图片领域字词搭配概率矩阵,构建模板图片领域文集N-Gram知识库,作为对带纠错文本进行错误位置判断的文本错误判断机制背景知识库。
作为优选,在步骤S2中,对待纠错文本进行文本预处理,包括去除句中数字、符号及英语字母,利用N-Gram机制对句子进行BiGram切分,得到带纠错文本序列。
进一步的,在步骤S3中,待纠错文本经过文本预处理后得到待错文本BiGram切分字词序列,通过与模板图片领域文本集N-Gram知识库进行比对参照领域字词搭配概率矩阵,概率低于阈值部分则视为BiGram组内存在文本错误。
进一步的,在步骤S4中,确定待纠错文本中的字词错误位置后使用错误规则推理模型对该字进行OCR转换错误规则推理。
进一步的,在步骤S4中,汉字构造属性知识图谱主要由汉字本身、汉字对应表形码、汉字笔及汉字与汉字之间在OCR转换时出现的错误规则构成,图谱中为每个汉字赋予独有的编号,以汉字编号作为所有关系的主节点,组成完整的汉字构造属性知识图谱。
进一步的,在步骤S4中,根据该字在OCR转换中出现错误的预测结果,生成该错误字的正确字候选区间,供后续候选词筛选算法提取,根据错误字在OCR转换错误规则推理模型中的推理结果,生成候选字列表。
进一步的,在步骤S5中,针对候选字列表的筛选分为两部分进行,
根据BiGram领域字词搭配模板图片知识库对候选字列表中每一个候选字在疑似错字所处待纠错文本中对应上下文BiGram切分的字词搭配组合进行遍历排查,候选字中如果与疑似错字在待纠错文本中所处上下文位置的前后文构不成合理句子的字会被直接排除,不被保留在供筛选算法进行权重推算的候选字列表中。
进一步的,在步骤S5中,针对候选字列表的筛选算法利用TF-IDF算法和余弦相似度对每个候选字与疑似错字所处上下文位置进行计算,表示候选字与待纠错文本中错误位置上下文构成句子的合理程度,比较经过BiGram模板图片知识库比对后的候选字列表中的候选字与错误字本身在待纠错文本中的相似程度,挑选出最为合理的候选字。
本发明的一种单模板工作流优化方法和现有技术相比,具有以下突出的有益效果:
本发明的单模板工作流优化方法提高图像在单模板工作流中经过OCR转换后文本的可用性,应用于框选参照字段、框选识别区和评估应用阶段,从而提高单模板工作流文字识别模型的精度,保证结构化信息的提取效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
附图1是一种单模板工作流优化方法中文本纠错框架图;
附图2是一种单模板工作流优化方法中错误判断机制流程图;
附图3是一种单模板工作流优化方法中错误规则推理模型图;
附图4是现有技术中单模板的工作流程图。
具体实施方式
为了使本技术领域的人员更好的理解本发明的方案,下面结合具体的实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
下面给出一个最佳实施例:
如图1所示,本实施例中一种单模板工作流优化方法,具有如下步骤:
S1、构建模板图片领域的N-Gram知识库:
首先,首先对收集的模板图片领域文本集进行BiGram切分,分析和统计领域文本集中的字词搭配,生成模板图片领域字词搭配概率矩阵,构建模板图片领域文集N-Gram知识库,作为对带纠错文本进行错误位置判断的文本错误判断机制背景知识库。
BiGram(二间隔)是N-Gram技术中广泛使用的一种细化标准,BiGram相比Tri Gram或5-Gram等在文本字词搭配统计分析上更为细粒度,可以获得更为准确的领域字词搭配概率矩阵,在文本错误位置判断上可以提供更高的精度。
S2、预处理OCR纠错文本为待纠错序列:
对待纠错文本进行文本预处理,包括去除句中数字、符号及英文字母等,利用N-Gram机制对句子进行BiGram切分,得到带纠错文本序列。
S3、将识别疑似错字:
待纠错文本经过文本预处理后得到待错文本BiGram切分字词序列,通过与模板图片领域文本集N-Gram知识库进行比对参照领域字词搭配概率矩阵,概率低于阈值部分则视为BiGram组内存在文本错误。
如图3所示,W1、W2、W3、W4分别表示待纠错文本N-Gram序列中的四个字,经过BiGram切分后,分别有W1W2、W2W3、W3W4三组BiGram序列,通过对每组BiGram进行字词搭配概率分析,当W2W3的字词搭配概率低于阈值时,判定W2W3组合中存在文本错误。然后对W2、W3所在的BiGram组合W1W2、W3W4分别进行字词搭配概率分析,概率较高的组合视为正确,概率较低的组合视为错误,从而确认W2W3组合中错误字的具体位置。
S4、基于错误规则推理模型,构建正确候选字列表:
如图4所示,确定待纠错文本中的字词错误位置后使用错误规则推理模型对该字进行OCR转换错误规则推理。
汉字构造属性知识图谱主要由汉字本身、汉字对应表形码、汉字笔及汉字与汉字之间在OCR转换时出现的错误规则构成,图谱中为每个汉字赋予独有的编号,以汉字编号作为所有关系的主节点,组成完整的汉字构造属性知识图谱。
根据该字在OCR转换中出现错误的预测结果,生成该错误字的正确字候选区间,供后续候选词筛选算法提取。根据错误字在OCR转换错误规则推理模型中的推理结果,生成候选字列表。
S5、利用候选字筛选算法进行综合权重生成,对权重进行排序,权重最高的字则为当前待纠错文本中错误字的正确字:
针对候选字列表的筛选分为两部分进行。
首先,根据BiGram领域字词搭配模板图片知识库对候选字列表中每一个候选字在疑似错字所处待纠错文本中对应上下文BiGram切分的字词搭配组合进行遍历排查,候选字中如果与疑似错字在待纠错文本中所处上下文位置的前后文构不成合理句子的字会被直接排除,不被保留在供筛选算法进行权重推算的候选字列表中。
然后,针对候选字列表的筛选算法利用TF-IDF算法和余弦相似度对每个候选字与疑似错字所处上下文位置进行计算,表示候选字与待纠错文本中错误位置上下文构成句子的合理程度,比较经过BiGram模板图片知识库比对后的候选字列表中的候选字与错误字本身在待纠错文本中的相似程度,挑选出最为合理的候选字。
上述具体的实施方式仅是本发明具体的个案,本发明的专利保护范围包括但不限于上述具体的实施方式,任何符合本发明的一种单模板工作流优化方法权利要求书的且任何所述技术领域普通技术人员对其做出的适当变化或者替换,皆应落入本发明的专利保护范围。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于KMP算法的单模板工作流优化方法
- 一种单模板工作流预处理优化方法