基于自然语言描述的三维场景目标检测建模及检测方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明属于人工智能与计算机视觉领域,具体涉及一种基于自然语言描述的三维场景目标检测建模及检测方法。
背景技术
近年来,随着激光雷达和深度相机等的广泛应用,移动机器人可以更好地获得工作场景的三维信息,基于深度学习的三维点云场景理解引起了很多关注。人类通过自然语言的方式对移动机器人发出指令,移动机器人根据自然语言描述信息在所处的三维场景中定位出目标物体,将大幅度提升移动机器人的智能化水平。依据自然语言描述进行三维点云目标定位存在如何抽象出自由式语言描述关系特征、如何跨模态地对自然语言和三维点云信息进行融合处理等问题。
目前基于文本语言描述引导的三维点云目标检测方法只提取语言描述的全局特征,忽略了自由式语言描述中长距离名词的上下文关系,且没有深度融合跨语言和三维点云模态之间的抽象信息,限制了三维目标定位精度,制约了移动机器人以更智能的方式理解人类自然语言并执行相应的后续任务。
发明内容
本发明的目的在于提供一种基于自然语言描述的三维场景目标检测建模及检测方法,用以解决现有技术中的三维目标定位精度不足的问题。
为了实现上述任务,本发明采用以下技术方案:
一种基于自然语言描述的三维场景目标检测建模方法,包括如下步骤:
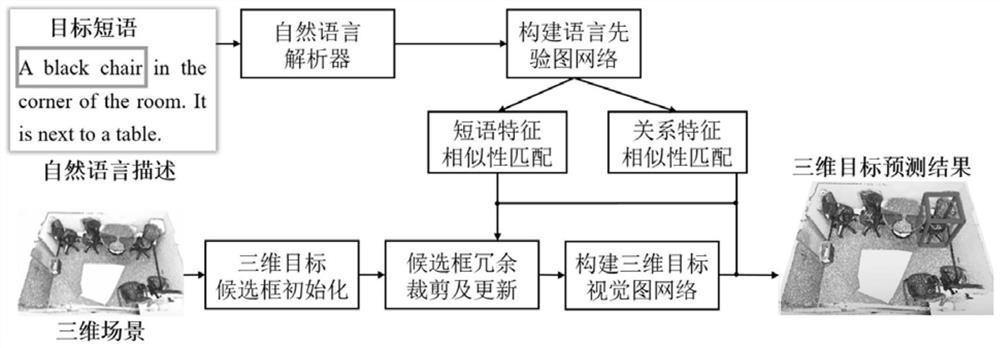
步骤一:获取自然语言描述集合和三维场景点云集合,所述的自然语言描述集合中每条自然语言描述包括名词短语集和关系短语集,每条自然语言描述对应三维场景点云集合中的一个三维场景点云,根据每条自然语言描述其对应的三维场景点云进行候选框标注,获得每个三维场景点云的真实目标候选框;
步骤二:根据图网络构建方法获得语言先验图网络和三维目标候选框视觉关系图网络;
步骤三:将自然语言描述集合和三维场景点云集合作为训练集,将所有三维场景点云的真实目标候选框作为标签集,训练语言先验图网络和三维目标候选框视觉关系图网络,将训练好的语言先验图网络和三维目标候选框视觉关系图网络作为基于自然语言描述的三维场景目标检测模型;
所述的图网络构建方法,包括如下步骤:
步骤1:获取自然语言描述,所述的自然语言描述包括名词短语集和关系短语集,对名词短语集和关系短集语进行编码得到名词短语特征集和关系短语特征集;以名词短语为节点,以关系短语为边,以名词短语特征为节点特征并以关系短语特征为边特征构建初始语言先验图网络;
步骤2:采用注意力机制对初始语言先验图网络中每个节点的临近节点的节点特征和边特征进行加权聚合,获得语言先验图网络;
步骤3:获取三维场景点云,所述的三维场景点云与步骤1的自然语言描述相关,采用PointNet++提取三维场景点云的点云特征,根据三维场景点云的点云特征采用VoteNet生成三维场景点云的初始化候选框集合,所述的初始化候选框集合包括多个候选框;
步骤4:通过多层感知机运算提取步骤3得到的初始化候选框集合中每个候选框的目标特征,根据每个候选框的目标特征和步骤2得到的语言先验图网络的每个节点特征计算每个候选框和每个名词短语节点的偏移量;
步骤5:计算每个名词短语和每个候选框的相似性匹配得分,将同一个名词短语的相似性匹配得分降序排列,获得同一个名词短语的前K个相似性匹配得分所对应的候选框,并对同一个名词短语的K个候选框分别依据步骤4得到的每个候选框和每个名词短语节点的偏移量进行更新,将更新后的同一个名词短语的K个候选框作为该名词短语的候选框集,其中,K为正整数;
步骤6:获取每个名词短语的候选框集中存在关系短语的所有对候选框,提取存在关系短语的每对候选框的视觉特征和存在关系短语的每对候选框的最小联合区域的几何特征,将存在关系短语的每对候选框的视觉特征和几何特征进行级联得到存在关系短语的每对候选框的级联关系特征;
以候选框为节点,以关系短语为边,以候选框的目标特征为节点特征,以存在关系短语的每对候选框的级联关系特征为边特征,构建初始三维目标候选框视觉关系图网络;
步骤7:采用注意力机制对初始三维目标候选框视觉关系图网络中每个节点的临近节点的节点特征和边特征进行加权聚合,获得三维目标候选框视觉关系图网络。
进一步的,步骤三进行训练时,每次迭代后对语言场景图和三维目标候选框视觉关系图进行图匹配,并根据图匹配结果计算损失函数并进行下次迭代,包括如下子步骤:
计算语言场景图中的每个名词短语节点和三维目标候选框视觉关系图中的每个目标候选框节点的节点图匹配得分,计算语言先验图中每条边和三维目标视觉关系图中每条边的边图匹配得分;
获取边图匹配得分值最高的三维目标视觉关系图中边作为目标候选框关系边,选取该目标候选框关系边连接的两个目标候选框节点中节点图匹配得分值最高的目标候选框作为本次迭代得到的最终目标候选框,根据目标候选框与真实目标候选框计算损失函数,更新模型参数并进行下次迭代。
更进一步的,所述的损失函数为:
其中
一种基于自然语言描述的三维场景目标检测方法,包括如下步骤:
步骤Ⅰ:获取待检测三维场景点云及待检测三维场景点云的一条自然语言描述;
步骤Ⅱ:将待检测三维场景点云及待检测三维场景点云的一条自然语言描述输入任一种基于自然语言描述的三维场景目标检测建模方法得到的基于自然语言描述的三维场景目标检测模型中得到目标候选框。
本发明与现有技术相比具有以下技术特点:
(1)本发明通过对自由式自然语言描述进行针对性的解析,利用解析得到的名词短语和关系短语构建自然语言先验图网络,通过基于注意力机制的特征更新策略,有效地提取自然语言描述中的目标信息及关系信息,克服了现有技术中对复杂语言描述无法提取长距离上下文信息的问题,使得本发明具有能够更好地理解自然语言描述,进而为目标的定位提供准确的引导先验信息的优点。
(2)本发明通过自然语言描述引导从复杂三维点云场景中定位出目标物体,利用自然语言先验图的节点特征作为先验进行目标候选框的冗余裁剪及更新,有效提升了初始化目标候选框的精度,客服了现有技术中视觉场景图构建中由于冗余造成的运算量大且候选框精度低的问题,使得本发明具有能够建立具有更强特征表示能力的三维目标视觉场景图的优点。
(3)本发明基于自然语言先验图的节点和边特征与三维目标视觉场景图进行相似性匹配,有效突破了自然语言和三维点云的跨模态特征域差异的瓶颈,克服了现有技术中无法深度融合自然语言和三维点云的多模态特征问题,使得本发明具有能够基于对自然语言的理解在三维点云场景中精准地定位到目标物体的优点。
附图说明
图1是基于自然语言描述引导的三维场景目标定位方法的整体框架;
图2是自然语言先验图的更新示意图;
图3是三维目标视觉场景图的更新示意图;
图4是三维场景目标定位结果示意图。
具体实施方式
首先对本发明中出现的技术词语进行解释:
临近节点:邻近节点是指与某一节点存在边的所有节点。
PointNet++:主干点云特征提取网络,在不同尺度提取点云局部特征,通过包含下采样和上采样的多层网络结构得到点云深层特征。该网络的出处为:Qi C R,Yi L,Su H,etal.PointNet++deep hierarchical feature learning on point sets in a metricspace[C]//Proceedings of the 31st International Conference on NeuralInformation Processing Systems.2017:5105-5114.
VoteNet:投票策略,该策略通过主干点云网络PointNet++传递输入点云之后,对一组种子点进行采样,并根据它们的特征生成投票,投票的目标是到达目标中心,投票集群出现在目标中心附近,然后可以通过一个学习模块进行聚合,生成初始化候选框集合。该策略的出处为:Qi C R,Litany O,He K,et al.Deep hough voting for 3d objectdetection in point clouds[C]//Proceedings of the IEEE/CVF InternationalConference on Computer Vision.2019:9277-9286.
相似性匹配:比较两个特征的相似性,将两个特征输入到卷积网络中运算,得到一个概率值,根据概率值的大小设定阈值判断二者相似性。
注意力机制:计算某一指定特征与其它所有特征的关系,这个关系是用归一化的权重值表示,然后将其它所有特征与它们对应权重值相乘后再相加,用来更新某一指定特征。注意力机制的出处为:Vaswani A,Shazeer N,Parmar N,et al.Attention is all youneed[C]//Proceedings of the 31st International Conference on NeuralInformation Processing Systems.2017:6000-6010.
最小联合区域:能够同时包含两个候选框最小外接框区域。
偏移量:候选框表示为中心坐标、长宽高和位姿角度,偏移量是指在中心坐标、长宽高和位姿角度上的偏移值,然后与原始值相加,得到更新后的候选框。
多层感知机:用[1,1]大小的卷积核去做多层卷积操作,用来做特征提取。
在本实施例中公开了一种图网络构建方法,包括如下步骤:
步骤1:获取自然语言描述,所述的自然语言描述包括名词短语集和关系短语集,对名词短语集和关系短集语进行编码得到名词短语特征集和关系短语特征集;以名词短语为节点,以关系短语为边,以名词短语特征为节点特征并以关系短语特征为边特征构建初始语言先验图网络;
步骤2:采用注意力机制对初始语言先验图网络中每个节点的临近节点的节点特征和边特征进行加权聚合,获得语言先验图网络;
步骤3:获取三维场景点云,所述的三维场景点云与步骤1的自然语言描述相关,采用PointNet++提取三维场景点云的点云特征,根据三维场景点云的点云特征采用VoteNet生成三维场景点云的初始化候选框集合,所述的初始化候选框集合包括多个候选框;
三维场景点云与步骤1的自然语言描述相关是指:一条自然语言描述所描述的对象在空间上处于一个三维场景中,称该条自然语言描述和该三维场景所对应的三维场景点云相关。
步骤4:通过多层感知机运算提取步骤3得到的初始化候选框集合中每个候选框的目标特征,根据每个候选框的目标特征和步骤2得到的语言先验图网络的每个节点特征计算每个候选框和每个名词短语节点的偏移量;
步骤5:计算每个名词短语和每个候选框的相似性匹配得分,将同一个名词短语的相似性匹配得分降序排列,获得同一个名词短语的前K个相似性匹配得分所对应的候选框,并对同一个名词短语的K个候选框分别依据步骤4得到的每个候选框和每个名词短语节点的偏移量进行更新,将更新后的同一个名词短语的K个候选框作为该名词短语的候选框集,其中,K为正整数;
步骤6:获取每个名词短语的候选框集中存在关系短语的所有对候选框,提取存在关系短语的每对候选框的视觉特征和存在关系短语的每对候选框的最小联合区域的几何特征,将存在关系短语的每对候选框的视觉特征和几何特征进行级联得到存在关系短语的每对候选框的级联关系特征;
以候选框为节点,以关系短语为边,以候选框的目标特征为节点特征,以存在关系短语的每对候选框的级联关系特征为边特征,构建初始三维目标候选框视觉关系图网络;
步骤7:采用注意力机制对初始三维目标候选框视觉关系图网络中每个节点的临近节点的节点特征和边特征进行加权聚合,获得三维目标候选框视觉关系图网络。
在本实施例中还公开了一种基于自然语言描述的三维场景目标检测建模方法,包括如下步骤:
步骤一:获取自然语言描述集合和三维场景点云集合,所述的自然语言描述集合中每条自然语言描述包括名词短语集和关系短语集,每条自然语言描述对应三维场景点云集合中的一个三维场景点云,根据每条自然语言描述其对应的三维场景点云进行候选框标注,获得每个三维场景点云的真实目标候选框;
步骤二:根据图网络构建方法获得语言先验图网络和三维目标候选框视觉关系图网络;
步骤三:将自然语言描述集合和三维场景点云集合作为训练集,将所有三维场景点云的真实目标候选框作为标签集,训练语言先验图网络和三维目标候选框视觉关系图网络,将训练好的语言先验图网络和三维目标候选框视觉关系图网络作为三维场景目标检测模型。
具体的,步骤三进行训练时,每次迭代后对语言场景图和三维目标候选框视觉关系图进行图匹配,并根据图匹配结果计算损失函数并进行下次迭代,包括如下子步骤:
计算语言场景图中的每个名词短语节点和三维目标候选框视觉关系图中的每个目标候选框节点的节点图匹配得分,计算语言先验图中每条边和三维目标视觉关系图中每条边的边图匹配得分;
获取边图匹配得分值最高的三维目标视觉关系图中边作为目标候选框关系边,选取该目标候选框关系边连接的两个目标候选框节点中节点图匹配得分值最高的目标候选框作为本次迭代得到的最终目标候选框,根据目标候选框与真实目标候选框计算损失函数,更新模型参数并进行下次迭代。
具体的,步骤三训练时网络的损失函数为:
其中
在本实施例中还公开了一种基于自然语言描述的三维场景目标检测方法,包括如下步骤:
步骤a:获取待检测三维场景点云及待检测三维场景点云的一条自然语言描述;
步骤b:将待检测三维场景点云及待检测三维场景点云的一条自然语言描述输入三维场景目标检测模型中得到目标候选框。
实施例1
在本实施例中公开了一种图网络构建方法,在上述实施例的基础上,还公开了如下技术特征,该方法包括如下子步骤:
步骤a:输入为三维场景的自然语言描述Q,通过离线语言解析器解析出名词短语
步骤b:以名词短语P为节点并以关系短语R为边建立语言场景图
步骤c:通过注意力机制聚合所有与指定名词短语节点存在边的邻近节点和边的特征来更新每个名词短语节点p
步骤d:输入随机采样后的三维点云场景
步骤e:采用PointNet++作为主干点云特征提取网络,并用VoteNet的投票策略生成初始化候选框集合
在本实施例中设置VoteNet的投票策略中的参数为256,则得到包含256个候选框的初始化候选框集合,候选框就类似一个只有骨架的长方体,它用来表示三维点云场景中物体的最小外接空间。候选框本身一般用中心点的坐标和长宽高来表示,而候选框内会包含有它所含空间内目标的三维点,这些所包含目标的三维点特征通常默认用来表示候选框的特征向量,同时用来表示候选框的坐标和长宽高可以提取得到候选框的空间特征向量。
步骤f:采用平均池化法为每个候选框提取特征向量
步骤g:级联特征向量
步骤h:对每个名词短语和候选框计算相似性匹配得分
具体的,所述的相似性匹配得分采用如下方法计算:
其中
步骤i:使用名词短语特征
步骤j:依据相似性匹配得分
步骤k:获取每个名词短语节点p
步骤l:如果一组候选框 步骤m:构建三维目标候选框视觉关系图 在本实施例中还公开了一种三维场景目标检测模型建立方法,在上述实施例的基础上还公开了如下特征: 步骤三进行训练时,每次迭代训练的过程中还包括如下操作: 步骤A:基于已经构建的语言先验图 分别计算的这两组图匹配得分,取边图匹配得分中值最高所对应的目标候选框关系边,该关系边连接有两个目标候选框节点,依据节点图匹配得分,选取这两个节点中值最高即目标候选框。根据目标候选框与真实目标候选框计算损失,更新模型参数; 具体的,图匹配得分采用如下式结构化预测方法计算得到:
其中β为平衡名词短语和关系得分的权重系数,优选的,在本实施例中β=0.7。 步骤B:分配给每一个名词短语和候选框目标组一个二进制变量λ 具体的,在本实施例中τ 实施例2 如图3所示,构建三维目标候选框视觉关系图 如图3所示,为语言先验图2中的每个名词节点对应选取得分排名前25的候选框,作为三维目标候选框视觉关系图的节点,分别为o
- 基于自然语言描述的三维场景目标检测建模及检测方法
- 基于自然语言描述的三维场景目标检测建模及检测方法