一种用于精密运动控制的通信方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及精密运动控制领域,为对控制周期要求为50us及以上的控制算法提供一种用于精密运动控制的通信方法。
背景技术
运动控制通常是指在复杂条件下,将预定的控制方法、规划指令转变成期望的机械运动,实现机械运动精确的位置控制、速度控制、加速度控制、转矩或力的控制。随着技术发展,精密运动控制向着多领域多方向发展。在性能方面要求控制器控制精度越来越高,控制周期也越来越小;在规范化方面,将已有算法模型化封装,可以大大降低二次开发难度及成本。因此开发的统一化、规范化、模块化也成为日益迫切的需求。
Linux操作系统工具软件种类庞大,可以满足大部分模块化开发需求。但是Linux操作系统也存在一些不足。Linux操作系统分为内核层和用户层将导致系统内部通信延时增加。在通信架构方面,总线的延时及操作系统的抖动,都将成为通信系统的技术瓶颈。本发明旨在如何在保证控制精度及控制周期满足指标要求的前提下,解决这些不足。
发明内容
针对现有技术的不足,本发明提供一种用于精密运动控制的通信方法。
该通信方法基于Linux操作系统,使控制周期可达到50us,为模型化开发精密运动控制解决总线延时及系统抖动等瓶颈问题。
本发明为实现上述目的所采用的技术方案是:
一种用于精密运动控制的通信方法,包括以下步骤:
1)系统初始化;
2)通讯卡全局时钟触发本周期通信及计算,通讯卡将接收数据缓存中的被控对象的状态信息数据发送给内核驱动模块;同时,通讯卡将发送数据缓存中的前一个周期的被控对象控制参数数据发送给被控对象,并等待被控对象发送状态信息数据给接收数据缓存;
3)内核驱动模块接收到被控对象的状态信息数据后立即以阻塞方式发送给用户层的控制算法模型;
4)用户层的控制算法模型接收到被控对象状态信息数据后解开阻塞状态,使用该被控对象状态信息数据进行本周期的控制算法计算,得到被控对象的控制参数数据,并将被控对象的控制参数数据发回给内核驱动模块;
5)内核驱动模块将控制算法模块发送来的被控对象的控制参数数据发送给通讯卡;
6)通讯卡接收到来自内核驱动模块的被控对象的控制参数数据并将其保存在发送数据缓存中,同时,将来自被控对象的状态信息数据保存到接收数据缓存,结束本周期工作,等待下个周期时钟触发。
所述系统初始化包括以下步骤:
1)控制器加载内核驱动模块;
2)内核驱动模块初始化PCIE总线以及与控制算法模型通信功能,等待控制算法模型下发时钟配置指令及通信开始指令;
3)内核驱动模块将时钟周期配置指令及通信开始指令发送给通讯卡。
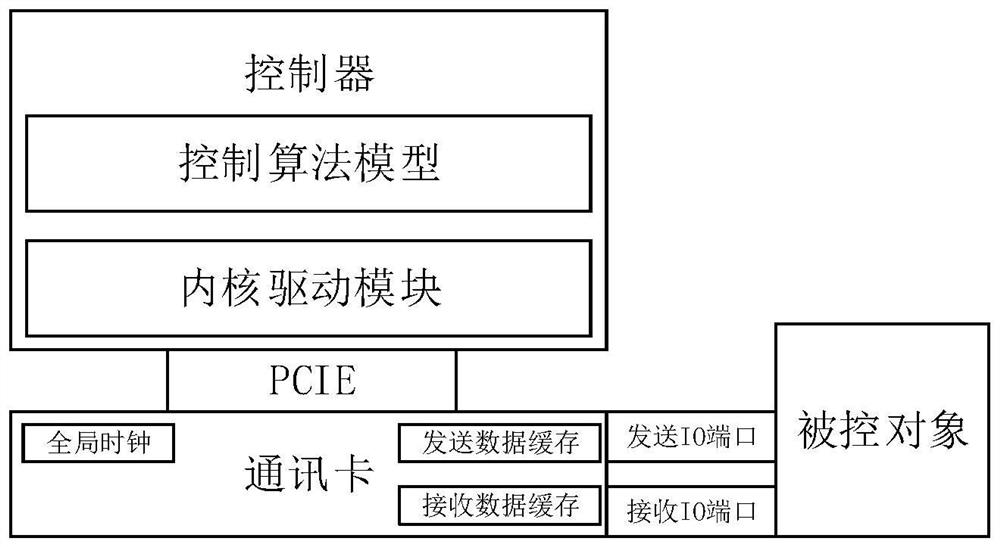
一种用于精密运动控制的通信系统,包括:控制器插有通讯卡,控制器和通讯卡采用PCIE通信协议,通讯卡与被控对象通过IO总线通信,控制器内部包含内核驱动模块及控制算法模型。
所述通讯卡包含发送数据缓存和接收数据缓存,并产生通信系统全局时钟。
所述通讯卡的工作流程为:
1)控制器中的内核驱动模块下发时钟周期配指令给通讯卡并对全局时钟进行配置;
2)控制器中的内核驱动模块下发通信开始指令通知通讯卡开始通讯工作;
3)通讯卡将接收数据缓存中的被控对象的状态信息数据发送给控制器并等待,同时将将发送数据缓存中的被控对象控制参数数据发送给被控对象并等待;
4)当通讯卡收到来自控制器的当前周期的控制算法模型计算结果即被控对象控制参数数据,将被控对象控制参数数据保存到发送缓存区中等待下个周期发送给被控对象;当收到来自被控对象的当前周期的状态信息数据后,将被控对象的状态信息数据保存到接收数据缓存中等待下个周期发送给控制器。
所述接收数据缓存区中保存的是上一个周期被控对象下发的被控对象状态信息数据;所述发送数据缓存区中保存的是上一个周期控制器下发的控制算法模型计算结果即被控对象控制参数数据。
所述内核驱动模块的工作流程为:
1)内核驱动模块对PCIE通讯功能、与控制算法模型通讯功能进行初始化;
2)接收到控制算法模型的时钟配置指令,并将时钟周期信息发送给通讯卡;
3)当接收到控制算法模型的通信开始指令后,向通讯卡发送一个通信开始信号表示开始通讯;
4)当接收到来自通讯卡的被控对象状态信息数据后,将被控对象状态信息数据通过阻塞方式发送给控制算法模型,并进入等待;
5)控制算法模型接收到被控对象状态信息数据后开始执行本周期计算,计算结束后会将结果即被控对象的控制参数数据发送给内核驱动模块;
6)内核驱动模块接收到被控对象的控制参数数据后,立即发送给通讯卡,结束本周期的工作。
所述控制算法模型的工作流程为:
1)对指定的CPU进行孤立化操作,并将控制算法模型运行在被孤立的CPU上;
2)初始化与内核驱动模块的通讯功能以及调整自身优先级到最高;
3)每个周期开始前,控制算法模型阻塞等待内核层发送来的被控对象状态信息数据;
4)接收到被控对象状态信息数据后解开阻塞状态并开始本周期控制计算;
5)将计算结果即被控对象的控制参数数据返回给内核驱动模块;
6)重新进入阻塞接收被控对象状态信息数据状态等待下一个计算周期开始。
本发明具有以下有益效果及优点:
1.现有的实时操作系统工具软件包少,通用性及可扩展性不强,不能满足精密运动控制规范化、便于重复开发等发展方向;Linux操作系统工具软件较多,扩展型较强,但存在系统抖动等不足。本发明基于精密运动控制的要求,针对Linux系统的不足做出改进,提出一种精密运动控制通信方法,使其对模块化开发提供支撑,且控制周期可以稳定达到50us。
2.稳定性好,本发明通过在通讯卡内部采用全局时钟使通信严格按照时钟沿周期触发,通过在通讯卡内部采用发送数据缓存和接收数据缓存使数据在控制器和被控对象之间从1个周期变为2个周期,减少了总线延时及抖动对通信造成的影响。
3.实时性高,本发明在控制器和通讯卡之间,控制算法模型和内核驱动模块之间全部采用阻塞通信的方式。并且通过将用户层的控制算法模型运行在被孤立核心中并且将其优先级调整到最高,来消除系统抖动对算法的影响。使本发明的实时性能得以保障。经实际测试,数据从通讯卡到控制算法模型不经过计算返回到发送数据缓存的时间平均仅为8us,最大不超过15us,也表明了本发明实时性能很高。
附图说明
图1是本发明的通信系统架构图;
图2是本发明的通讯卡工作逻辑图;
图3是本发明的内核驱动模块运行逻辑图;
图4是本发明的控制算法模型优化方法图;
具体实施方式
一种用于精密运动控制的通信方法,总共包含控制器,通讯卡和被控对象等。控制器包含控制算法模型和内核驱动模块,控制器与通讯卡通过PCIE总线互联。被控对象与通讯卡通过光纤、万兆以太网等IO方式互联;通讯卡包含系统全局时钟、发送缓存和接收缓存。
通信系统运行包括初始化及运行两个部分,其中初始化步骤为:
步骤1:控制器加载内核驱动模块;
步骤2:内核驱动模块初始化PCIE总线和与用户层通信功能,等待控制算法模型下发时钟配置指令及通信开始指令;
步骤3:控制算法模型初始化与内核通信功能,下发时钟周期配置指令及通信开始指令;
步骤4:内核驱动模块将时钟周期配置指令及通信开始指令以PCIE PIO的方式转发给通讯卡。
通信系统正常运行步骤为:
步骤1:通讯卡全局时钟触发本周期通信及计算。通讯卡将接收数据缓存中的数据通过PCIE DMA发送给内核驱动模块,接收数据缓存中的数据为前一个周期被控对象发送过来的数据;同时,将发送数据缓存中的数据发送给被控对象,发送数据缓存中的数据为前一个周期控制器发送过来的数据;
步骤2:内核驱动模块接收到PCIE DMA数据后立即以阻塞方式发送给用户层的控制算法模型;
步骤3:用户层的控制算法模型接收到内核驱动模块数据后解开阻塞状态,使用该数据进行本周期的控制算法计算,并将计算结果发回给内核驱动模块;
步骤4:内核驱动模块将控制算法模块发送来的数据通过PCIE DMA转发给通讯卡;
步骤5:通讯卡接收到来自内核驱动模块的数据并将其保存在发送数据缓存中,通过光纤等IO总线接收到来自被控对象的数据并将其保存在接收数据缓存中。结束本周期工作,等待下个周期时钟触发。
在本发明的通信方法下:控制器当前周期的控制算法数据固定在下一个时钟周期可以到达被控对象;同理被控对象当前周期的状态信息等数据也固定在下一个时钟周期抵达控制算法模型。
下面结合附图及实施例对本发明做进一步的详细说明。
如图1所示为本发明的通信系统架构图,系统整体分为控制器、通讯卡和被控对象三个部分。其中控制器包含控制算法模型和内核驱动模块;控制器与通讯卡通过PCIE总线互联;被控对象与通讯卡通过光纤、万兆以太网等IO方式互联;通讯卡包含系统全局时钟、发送缓存和接收缓存。
如图2所示为本发明的通讯卡工作逻辑图。控制器首先通过PCIE总线下发时钟周期配置指令,对通信系统全局时钟进行配置,时钟周期最小可配置为50us。随后通过PCIEPIO下发通信开始指令通知通讯卡开始通信工作。通讯卡作为系统全局时钟源,每个周期开始时,通过PCIE DMA的方式将接收数据缓存区中的数据发送给控制器并等待,该接收数据缓存区中保存的是上一个周期被控对象下发的数据;于此同时将发送数据缓存区中的数据通过光纤发送给被控对象并等待,该发送数据缓存区中保存的是上一个周期控制器下发的控制模型计算结果。当收到来自控制器的当前周期的控制模型计算结果后,将数据保存到发送缓存区中等待下个周期发送给被控对象;当收到来自被控对象的当前周期的状态数据后,将数据保存到接收数据缓存中等待下个周期发送给控制器。
如图3所示为本发明内核驱动模块运行逻辑图。挂载内核驱动模块后,驱动模块首先对PCIE通讯功能、与用户层通讯功能进行初始化。通信开始前,会接收来自用户层的时钟配置指令,并将时钟周期信息通过PIO发送给通讯卡。当收到用户层的通信开始指令后,向通讯卡发送一个PIO通信开始信号表示开始通讯。通讯开始后,当从PCIE DMA接收到来自通讯卡的数据后,理解将该数据通过阻塞方式发送给用户层,并进入等待。控制器的控制算法仿真算法运行在用户层,控制算法模型接收到数据后开始执行本周期计算,计算结束后会将结果发送给内核驱动模块。内核驱动模块接收到结果数据后,立即通过PCIE DMA发送给通讯卡,结束本周期的工作。
如图4所示为本发明控制算法模型优化方法图。控制器控制算法模型运行在用户层。运行时,采用将控制算法进程绑定到孤立核心及调整线程优先级等方法消除操作系统抖动带来的影响。在操作系统启动时,对指定CPU进行孤立化操作,并将控制算法模型运行在被孤立的CPU上。初始化阶段,初始化与内核的通讯功能以及调整自身优先级到最高,随后进入正常工作状态。每个周期开始前,控制算法模型阻塞等待内核层发送来的被控对象状态数据。接收到数据后解开阻塞状态并开始本周期控制计算,随后将计算结果返回给内核层,最后重新进入阻塞接收数据状态等待下一个计算周期开始。
本发明采用了全局时钟、周期触发控制以及采用缓存等方式,消除操作系统抖动对控制算法的影响,使单步控制周期可达到50us。全通信系统时钟源在主通讯板卡中,其余均为同步触发机制,降低数据通信延时。控制器的控制数据在计算当前周期可以抵达主通讯卡的发送缓存,在下一个周期可以抵达被控对象;同理被控对象的仿真数据在被仿真当前周期可以抵达通讯卡的接收缓存,在下一个周期可以抵达控制器算法。在控制领域,这种数据固定延时1个周期的通讯架构是可以被接收的。因此,本发明的通信方法,在保证控制算法可以正常使用的前提下,大大降低控制周期,满足精密运动控制需求。
本发明满足如下要求:
(一)控制器基于Linux操作系统;
(二)可实现控制器对被控对象以50us或大于50us为周期的精密运动控制。
控制器插有通讯板卡;控制器和通讯卡采用PCIE通信协议,通讯卡与被控对象采用光纤等IO总线通信;控制器内部包含内核驱动模块及控制算法模型。
通讯卡产生通信系统全局时钟;通讯卡内部包含用于消除总线传输延时对系统影响的发送数据缓存和接收数据缓存。
控制器内部的内核驱动模块,用于将来自通讯卡的PCIE数据和时钟信号传送到用户层,以及将用户层数据回传给通讯卡。
控制器控制算法模型运行在用户层。运行时,采用将控制算法进程绑定到孤立核心及调整线程优先级等方法消除操作系统抖动带来的影响。在操作系统启动时,对指定CPU进行孤立化操作,并将控制算法模型运行在被孤立的CPU上。控制算法模型在初始化阶段,及调整自身优先级到最高,以消除操作系统抖动对通讯架构带来的影响。
经实际测试,数据从通讯卡到控制算法模型不经过计算返回到发送数据缓存的时间平均仅为8us,最大不超过15us,也验证了本发明的实时性能。
- 一种用于精密运动控制的通信方法
- 一种用于全向移动机器人运动控制系统的CAN总线通信方法