基于语音存在概率和听觉掩蔽效应的语音增强算法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及语音信号增强技术,具体涉及一种基于语音存在概率和听觉掩蔽效应的语音增强算法。
背景技术
随着语音识别等技术的发展,其前端预处理中的语音增强领域也变得越来越重要。目前语音增强算法主要有谱减法、小波变换法、维纳滤波法等。谱减法在输入信号信噪比较高时能较好的抑制噪声,但在信噪比较低时,噪声残留较多。谱减法简单、复杂度低,但对于噪声的估计偏差较大,且对于谱减后得到的负值使用半波整流处理,导致“音乐噪声”的出现,严重影响语音的可懂度。目前有许多研究者在噪声估计方面进行了改进以解决“音乐噪声”问题。例如在平稳噪声环境下,有最小值控制的递归平均(MCRA)算法,该算法基于噪声对语音频谱的影响在频率上分布不均匀的特性,即只要某频带语音不存在的概率很高就可以对噪声功率谱进行估计更新。
在非平稳环境下,许多噪声估计算法依旧会有跟踪延迟、误差较大等问题。部分研究人员尝试在非平稳环境下,利用人耳的听觉特性进行语音增强。掩蔽效应即两个声音同时作用于人耳时,会存在相互干扰,使得另一个声音不易被察觉。包括纯音对纯音的掩蔽、噪声对纯音的掩蔽。在语音增强中,语音信号的存在使得噪声的听阈值上升,且语音信号的能量越大,噪声的掩蔽阈值就越高,越难被察觉。
发明内容
本发明目的在于克服现有谱减法中的噪声估计偏差较大导致谱减后语音失真的问题,提出一种基于语音存在概率和听觉掩蔽效应的语音增强算法,该算法在谱减时不需要完全减去噪声,而是使得残留的噪声强度在掩蔽阈值之下,使人耳无法感受到这些噪声,这样在消除噪声的同时可以减少语音失真。
本发明的目的是通过以下技术方案来实现的:一种基于语音存在概率和听觉掩蔽效应的语音增强算法,其步骤如下:
S1.对输入的时域语音信号进行预处理,得到频域语音信号,并保留相角于后续步骤使用;
S2.对S1步骤得到的频域信号进行基于谱熵比的语音存在概率计算,并得到估计的噪声功率谱;
S3.对S1步骤得到的频域信号进行噪声掩蔽阈值计算,得到各个频点的谱减系数值;
S4.结合S2的估计噪声功率谱和S3得到的谱减系数进行谱减,得到纯净语音谱,然后结合保留的相角进行逆傅立叶变换,得到纯净时域语音信号。
其中,步骤S1中输入的时域语音信号由纯净语音信号和噪声信号叠加而成,纯净语音信号和噪声信号来自THCHS30语料库。
进一步地,步骤S1包括以下子步骤:
S1-1.对长度为T的时域语音信号进行预加重处理,得到预加重后的信号
其中μ为预加重系数,y(t)为原始语音信号,t=1,2,…,T;
S1-2.对预加重后的信号进行加窗分帧处理,得到分帧后帧长为W的语音信号y(t);
y(t)=[y
其中,y
S1-3.对每帧语音信号进行傅立叶变换,将语音信号从时域变换到频域,得到长度为W的频域语音信号Y(k):
Y(k)=[Y
其中,Y
进一步地,步骤S2包括以下子步骤:
S2-1.根据能熵比计算第l帧第k个语音频点的语音存在概率p(k,l):
其中,a为控制参数;W(k,l)为能熵比,能熵比常用来区分有无语音片段,能熵比越大,语音存在的概率也就越大;能熵比由短时谱熵H(k,l)和短时能量E(l)决定:
S2-2.将计算得到的语音存在概率在时间上进行平滑,得到平滑后的语音存在概率
其中,α
S2-3.由平滑后的语音存在概率计算平滑因子
其中,α
S2-4.本发明在基于时间递归的噪声功率谱估计的基础上由上述语音存在概率进行改进;噪声功率谱估计分语音存在和不存在两种情况,两种情况都考虑时,由平滑因子计算估计噪声功率谱
其中,|Y(k,l)|为第l帧第k个频点的带噪语音幅度谱。
进一步地,掩蔽效应为两个声音同时作用于人耳时,会存在相互干扰,使得另一个声音不易被察觉;语音信号的存在使得噪声的听阈值上升,且语音信号的能量越大,噪声的掩蔽阈值就越高,越难被察觉;本发明根据这个特性,在谱减法中并不完全抑制噪声,而是使得残留的噪声强度在掩蔽阈值之下,使人耳无法感受到这些噪声,这样在消除噪声的同时可以减少语音失真。
进一步地,将人耳听觉频率范围划分为若干个Bark尺度的关键子频带,并计算每个子频带中的噪声掩蔽阈值。
进一步地,步骤S3包括以下子步骤:
S3-1.采用Bark刻度来实现将线性频率映射到人的听觉感知域,在这种映射中,频率f和线性Bark刻度b的函数关系为:
其中,b为临界Bark频带序号。
S3-2.根据Bark刻度的划分,求得每个Bark带内的语音信号能量,得到临界带的能量:
其中,B
S3-3.将临界带能量和扩展函数SF
其中,扩展函数SF
其中,Δ=i-j表示两个临界频带号的差值,且Δ≤i
S3-4.考虑到有两种掩蔽情况:一种为纯音掩蔽噪声;另一种为噪声掩蔽纯音;所以需判断语音信号偏噪声特性还是偏语音特性,本发明根据语音谱平坦度SFM
根据语音平坦度计算音调系数∈:
音调系数∈∈[0,1],其值为0时,说明频带的信号完全为噪声特性,为1时,表示频带的信号完全为纯语音特性;
S3-5.根据得到的扩展Bark域功率谱C和音调系数∈计算扩展掩蔽阈值T′:
S3-6.根据扩展掩蔽阈值T′和绝对听阈阈值计算得到最终噪声掩蔽阈值T:
T
其中,T
S3-7.根据最终掩蔽阈值计算谱减参数增益因子α和过减因子β:
其中,α
进一步地,步骤S4包括以下子步骤:
S4-1.根据S3得到的谱减参数以及S2得到的估计噪声谱,进行谱减,计算增强后的纯净语音功率谱
其中,Y(m,k)为带噪语音信号的功率谱;
S4-2.根据S1保留的相角和S4-1得到的纯净语音功率谱进行逆傅立叶变换得到增强后的时域纯净语音信号
一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述基于语音存在概率和听觉掩蔽效应的语音增强算法。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述基于语音存在概率和听觉掩蔽效应的语音增强算法。
与现有技术相比,本发明的有益效果为:本发明根据改进的语音存在概率计算方法,即使在非平稳环境下也能有效跟踪噪声;利用人耳的听觉掩蔽效应,对进入人耳的噪声信号计算其掩蔽阈值,并结合噪声估计,能在消除噪声的同时,尽可能保证语音的感知质量,使得语音信号中不易出现较多突变的峰值。
附图说明
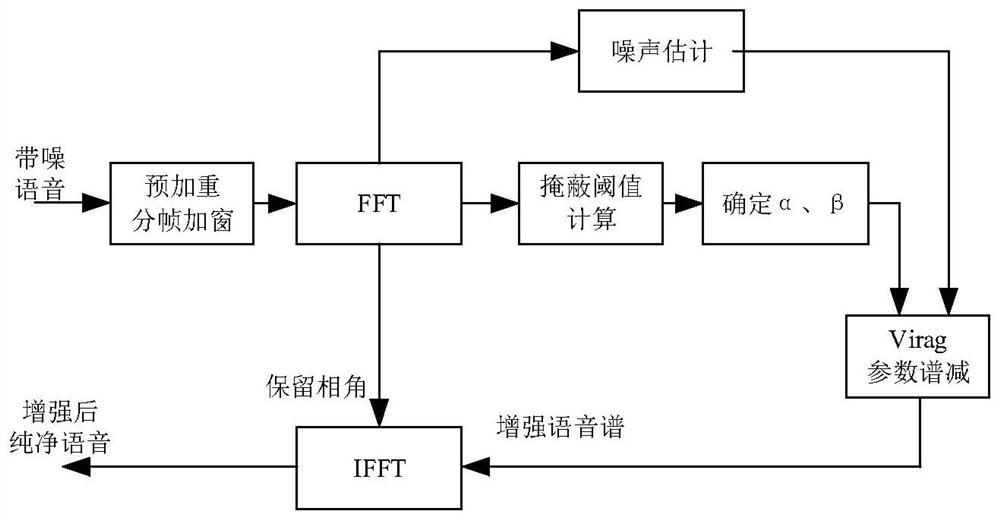
图1为本发明的方法流程图。
图2为一个计算噪声掩蔽阈值的流程图。
图3中(a)为原始语音信号、(b)为带噪语音信号、(c)为本发明算法降噪后的语音信号示意图。
具体实施方式
下面结合附图对本发明的具体实施方法做进一步详细描述。以下实施例或者附图用于说明本发明,但不用来限制本发明的范围,被描述的说明性施例仅仅是例证本发明的各个步骤。
本发明利用人耳的听觉掩蔽特性以及改进的噪声功率谱估计方法设计了一种新的语音增强算法。在听觉特性下,语音信号的存在使得噪声的听阈值上升,且语音信号的能量越大,噪声的掩蔽阈值就越高,越难被察觉。本发明根据这个特性,在谱减法中并不完全抑制噪声,而是使得残留的噪声强度在人耳的听觉掩蔽阈值之下,那么人耳便不会感受到该噪声,这样在消除噪声的同时可以减少语音失真。
传统的谱减法在进行噪声估计时通常先判断语音的有无语音片段,再估计噪声。但这种方法在非平稳环境下时,难以做到有效跟踪噪声。本发明基于时间递归的噪声谱估计方法,对其中的语音存在概率进行改进,利用能熵比进行语音存在概率值计算,并进行平滑处理。最终利用语音存在概率估计带噪信号中的噪声功率谱。本发明改进的算法能即使在非平稳环境下也能有效跟踪噪声。
如图1所示,该方法包括:
S1.对输入的时域语音信号进行预处理,得到频域语音信号,并保留相角于后续步骤使用;
S2.对S1步骤得到的频域信号进行基于谱熵比的语音存在概率计算,并得到估计的噪声功率谱;
S3.对S1步骤得到的频域信号进行噪声掩蔽阈值计算,得到各个频点的谱减系数值;
S4.结合S2的估计噪声功率谱和S3得到的谱减系数进行谱减,得到纯净语音谱,然后结合保留的相角进行逆傅立叶变换,得到纯净时域语音信号。
具体的,在本实施例中,所述的时域语音信号由纯净语音信号和噪声信号叠加而成。所述纯净语音信号和噪声信号来自THCHS30语料库。
在本实施例中,所述步骤S1包括以下子步骤:
S1-1.对长度为T的时域语音信号进行预加重处理,在本实施例中,语音信号长度为7.375s,采样率为16000Hz,即T=118000,最终得到预加重后的信号
其中μ为预加重系数,本实施例中取μ=0.97;y(t)为原始语音信号,t=1,2,…,T。
S1-2.对预加重后的信号进行加窗分帧处理,本实施例取帧长为W=320点,得到分帧后的语音信号y(t);
y(t)=[y
其中,y
S1-3.对每帧语音信号进行傅立叶变换,将语音信号从时域变换到频域,得到长度为W的频域语音信号Y(k):
Y(k)=[Y
其中,Y
在本实施例中,步骤S2:对步骤S1得到的频域信号进行基于谱熵比的语音存在概率计算,并得到估计的噪声功率谱,主要包括以下子步骤:
S2-1.在本实施例中,取控制参数α=0.01,再根据能熵比计算第帧第个语音频点的语音存在概率p(k,l):
W(k,l)为能熵比,能熵比常用来区分有无语音片段,能熵比越大,语音存在的概率也就越大。能熵比由短时谱熵H(k,l)和短时能量E(l)决定:
S2-2.在本实施例中,取平滑常数α
S2-3.在本实施例中,取递归平滑系数α
S2-4.本发明在基于时间递归的噪声功率谱估计的基础上由上述语音存在概率进行改进。噪声功率谱估计分语音存在和不存在两种情况,两种情况都考虑时,由平滑因子计算估计噪声功率谱
其中,|Y(k,l)|为第l帧第k个频点的带噪语音幅度谱。
在本实施例中,步骤S3:对S1步骤得到的频域信号进行噪声掩蔽阈值计算,如图2所示,得到各个频点的谱减系数值,主要包括以下子步骤:
S3-1.采用Bark刻度来实现将线性频率映射到人的听觉感知域,在这种映射中,频率f和线性Bark刻度b的函数关系为:
在本实施例中,将0-16000Hz范围内的频率可分为22个频带。因此,临界Bark频带序号b=1,2…,22。
S3-2.根据Bark刻度的划分,求得每个Bark带内的语音信号能量,得到第i个临界带的能量:
在本实施例中,每一帧的临界带能量为22维向量;
S3-3.将临界带能量和扩展函数SF
其中,扩展函数SF
其中,Δ=i-j表示两个临界频带号的差值,且Δ≤i
S3-4.在本实施例中,根据语音谱平坦度SFM
根据语音平坦度计算音调系数∈:
音调系数∈∈[0,1],其值为0时,说明频带的信号完全为噪声特性,为1时,表示频带的信号完全为纯语音特性。
S3-5.根据得到的扩展Bark域功率谱C和音调系数∈计算扩展掩蔽阈值T′:
S3-6.根据扩展掩蔽阈值T′和绝对听阈阈值计算得到最终噪声掩蔽阈值T:
T
其中,T
S3-7.根据最终掩蔽阈值计算谱减参数增益因子α和过减因子β:
在本实施例中,α
在本实施例中,步骤S4:结合S2的估计噪声功率谱和S3得到的谱减系数进行谱减,得到纯净语音谱,然后结合保留的相角进行逆傅立叶变换,得到纯净时域语音信号,包括以下子步骤:
S4-1.根据S3得到的谱减参数以及步骤S2得到的估计噪声谱,进行谱减,计算增强后的纯净语音功率谱
其中,Y(m,k)为带噪语音信号的功率谱;
S4-2.根据S1保留的相角和S4-1得到的纯净语音功率谱进行逆傅立叶变换得到增强后的时域纯净语音信号
图3为本实施例仿真图,其中(a)为原始语音信号、(b)为带噪语音信号、(c)为本发明算法降噪后的语音信号示意图。可以看出,本发明改进的算法能即使在非平稳环境下也能有效跟踪噪声。
本发明还提供一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的基于语音存在概率和听觉掩蔽效应的语音增强算法。
进一步的,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的基于语音存在概率和听觉掩蔽效应的语音增强算法。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 基于语音存在概率和听觉掩蔽效应的语音增强算法
- 基于语音存在概率和相位估计的语音增强方法