一种基于姿态引导、风格和形状特征约束的人体图像生成方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于人体图像生成技术领域,尤其是涉及一种基于姿态引导、风格和形状特征约束的人体图像生成方法。
背景技术
人体图像生成是计算机视觉领域中一个重要的分支,可以被广泛地应用于行人重识别的数据增强、电影角色制作、虚拟试衣、增强现实等领域。基于姿态引导的人体图像生成是指给定一个目标姿态、和一张(组)源图像,在目标姿态的引导下,生成目标姿态下的具有源图像风格特征的目标人体图像。
如公开号为CN112116673A的中国专利文献公开了一种姿态引导下的基于结构相似性的虚拟人体图像生成方法;公开号为CN109191366A的中国专利文献公开了一种基于人体姿态的多视角人体图像合成方法及装置。
目前的人体图像生成存在两方面的问题:(1)在风格特征提取中,往往以源图像整体为输入提取一个全局的风格特征,而无法单独提取特定语义区域的特征。(2)控制方式单一,只能改变源图像的姿态,而无法控制特定的语义区域的风格和形状。
因此,亟需一种能够提供多样化的图像合成控制方式的人体图像生成方法。
发明内容
本发明提供了一种基于姿态引导、风格和形状特征约束的人体图像生成方法,可以按语义区域提取风格特征,控制人体图像的姿态和形状。
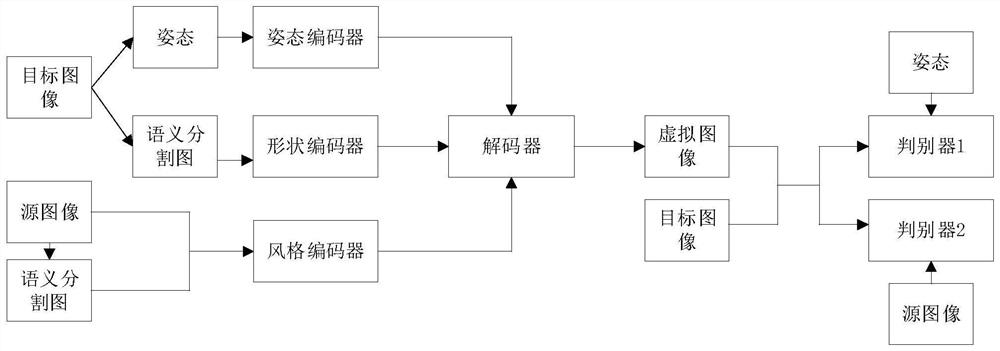
一种基于姿态引导、风格和形状特征约束的人体图像生成方法,包括以下步骤:
(1)采集获取源人体图像I
(2)构建生成器G和判别器D
(3)将步骤(1)中得到的源人体图像I
把依次提取得到的风格特征、姿态特征和形状特征输入解码器Decoder中,获得虚拟目标人体图像I
(4)把(I
(5)循环步骤(3)和步骤(4),达到预设的迭代次数后,获得训练好的生成器G,并用于现实场景中虚拟目标图像的生成。
步骤(1)中,姿态图像的关键点个数N=18,人体语义分割图像的类别个数C=8。
步骤(2)的具体步骤为:
(2-1)构建风格编码器Encoder
Encoder
使用时,首先使用语义分割图像分割出8个独立的图像
Encoder
(2-3)构建解码器Decoder
以姿态特征作为输入,使用风格特征和形状特征计算归一化参数;先经过4个ResBlock,保持通道不变;接着经过3组上采样层和ResBlock层;除了最后一层激活层为tanh,其余激活层皆为ReLU层。
(2-4)构建判别器D
使用PatchGAN作为判别器,包括4个3×3卷积层和3个残差块,判别器的Dropout设置为0.5。
步骤(4)中,所述的对抗损失函数的定义为:
式中,E表示期望。
步骤(4)中,图像重建损失L
L
图像感知损失定义为:
其中,
语义损失L
式中,
与现有技术相比,本发明具有以下有益效果:
1、本发明所提供的基于姿态引导、风格和形状特征约束的人体图像生成方法中,基于语义分割图像的风格编码器可以独立提取各个语义区域的特征,并按照预设顺序组合为风格特征,使得不同语义区域之间的特征具有独立性,在一组源图像情况下,可以实现风格特征重组,在实际应用中更加灵活。
2、本发明所提供的基于姿态引导、风格和形状特征约束的人体图像生成方法中,解码器使用目标语义分割图像的形状特征进行归一化,能够输出符合目标语义分割的图像,与现有基于姿态引导的人体图像生成方法相比,本发明提供了通过修改语义分割图像来修改生成图像的控制方式。
附图说明
图1为本发明方法的流程示意图;
图2为本发明人体图像姿态示意图;
图3为本发明人体图像语义分割示意图;
图4为本方法风格编码器示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,一种基于姿态引导、风格和形状特征约束的人体图像生成方法,包括以下步骤:
步骤1,采集获取源人体图像I
具体的,如图2所示,姿态图像关键点个数N=18;如图3所示,人体语义分割图像类别个数C=8。
步骤2,构建生成器G和判别器D
具体步骤如下:
步骤2.1,构建Encoder
Encoder
使用时,首先使用语义分割图像分割出8个独立的图像
步骤2.2,构建Encoder
Encoder
步骤2.3,构建Decoder
以姿态特征作为输入,使用风格特征和形状特征计算归一化参数。
先经过4个ResBlock,保持通道不变;接着经过3组上采样层和ResBlock层,除了最后一层激活层为tanh,其余激活层皆为ReLU层。
步骤3.4,构建判别器D
使用PatchGAN作为判别器,包括4个3×3卷积层和3个残差块,判别器的Dropout设置为0.5。
步骤3,把步骤1中得到的源人体图像I
步骤4,把(I
具体的,对抗损失函数定义为:
其中E表示期望。
图像重建损是虚拟目标图像和真实目标图像之间的L
L
图像感知损失定义为:
其中
语义损失L
步骤5,循环步骤3和步骤4,达到预设的迭代次数后,获得训练好的生成器G,用于现实场景中虚拟目标图像的生成。
具体的,训练过程中,学习率初始为0.0001,在1000次迭代中,线性衰减至0。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 一种基于姿态引导、风格和形状特征约束的人体图像生成方法
- 基于姿态引导重识别特征的并行人体姿态检测跟踪方法