一种6D姿态估计方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及姿态估计领域,尤其涉及一种6D姿态估计方法。
背景技术
6D姿态估计的目的是在场景中检测出目标,并估计目标相对参考坐标系(canonical frame)的旋转和平移。高效精确的6D姿态估计是实时交互应用的关键技术,比如增强现实、自动驾驶、机器人应用等。由于现实场景存在光照变化、数据噪声、遮挡残缺等情况,所以设计鲁棒的姿态估计算法是很具有挑战性的。近几年得益于深度学习强大的特征提取和拟合能力,基于数据驱动的姿态估计算法表现出极好的性能。这些基于深度学习的姿态估计算法按照使用的输入数据,可以分为基于2D图像的方法、基于3D点云的方法和基于2D图像-3D点云的方法。早期基于2D图像的6D位姿估计方法通过CNN提取2D纹理特征来进行姿态回归,因为2D图像缺少深度信息,所以这类算法很难获得精确的估计结果,也很难处理弱纹理或者无纹理物体。基于3D点云的方法,特征提取一般使用PointNet,PointNet++等网络,相比基于2D图像的算法有了较大的性能提升。近年来出现了以DenseFusion为代表的结合2D图像特征和3D点云特征来进行姿态估计的算法,并获得进一步性能提升,并且其提出的Point-wise特征聚合方式在面对点云残缺,目标遮挡等情况时,表现出了优异的鲁棒性。但目前的2D-3D特征聚合框架是异构的架构,一个分支在图像上进2D特征提取,另一个分支在点云空间中进行3D特征提取,再根据点云在图像上的索引进行聚合,这种方式耗时长,结构也不够优雅。通过总结存在以下缺点:1、特征提取阶段,目前最高水平的算法都是Point-based的提取方式,这些算法利用PointNet++提取3D特征。PointNet++需要频繁进行点云分组,是比较耗时的特征提取网络。同时为了获得Point-wise的2D-3D特征,Densefusion、PVN3D等算法需要通过点云与像素的关联索引进行特征聚合,这种异构结构不够高效也不易实现;2、过去的深度学习算法都不能很好的处理对称物体,因为对称物体存在旋转多义性,所以在训练阶段,会使得网络在面对同一个输入时,接收到不同的惩罚,最终导致网络学习不到正确的解。本专利提出了一个面向现实场景,既高效又鲁棒的姿态估计算法,以及新的代价函数,使姿态估计算法可以应用于对称物体上。
发明内容
为了克服现有技术的缺陷,本发明所要解决的技术问题在于提出一种6D姿态估计方法,通过此方法,解决了密集2D-3D特征提取不高效及对称物体的旋转多义性的问题。
为达此目的,本发明采用以下技术方案:
本发明提供的一种6D姿态估计方法,一种6D姿态估计方法,包括以下步骤:
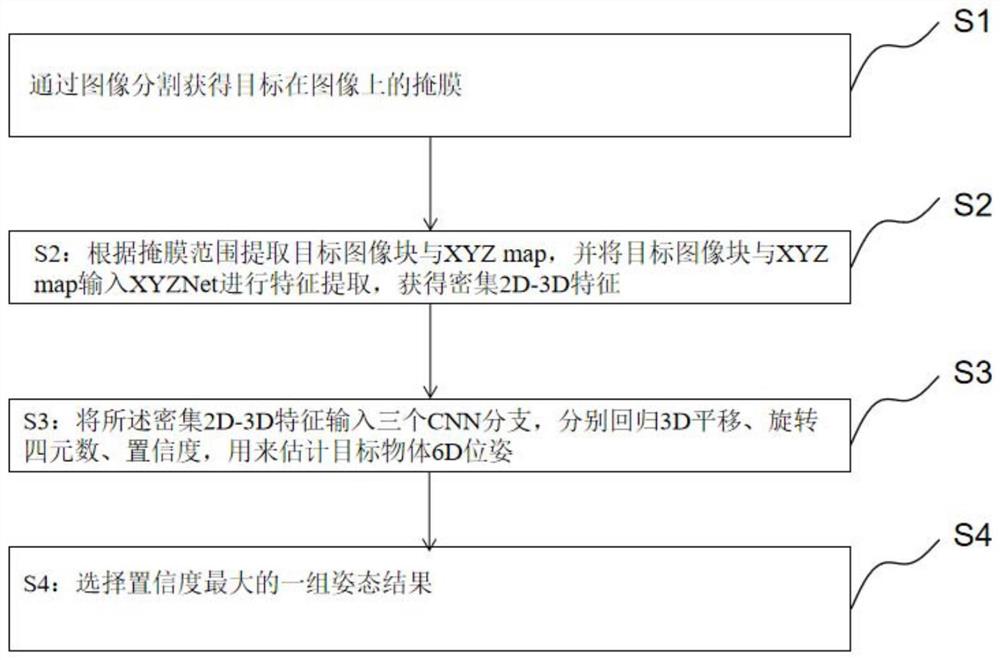
S1:通过图像分割获得目标在图像上的掩膜;
S2:根据掩膜范围提取目标图像块与XYZ map,并将目标图像块与XYZ map输入XYZNet进行特征提取,获得密集2D-3D特征;
S3:将密集2D-3D特征输入三个CNN分支,分别回归3D平移、旋转四元数、置信度,用来估计目标物体6D位姿;
S4:选择置信度最大的一组姿态结果。
本发明优选地技术方案在于,通过图像分割获得目标在图像上的掩膜具体步骤为:
通过图像分割把图像分成若干个特定的、具有独特性质的区域并提取感兴趣目标,并对感兴趣目标做掩膜处理。
本发明优选地技术方案在于,XYZNet包括:
多层级局部特征提取模块,用于对目标的图像块以及对应的XYZ map经过多层卷积进行局部特征提取;
全局几何信息编码模块,用于将局部特征和坐标串联,并使用多层1x1卷积进行特征编码,并使用max pooling提取代表目标的全局特征;
密集2D-3D特征聚合模块,用于将局部特征与全局特征串联,全局特征提供感受野更大的上下文信息,局部特征提供细致且具有差异的信息。
本发明优选地技术方案在于,所述S4具体为:将S3得到的置信度值经过argmax函数筛选,得到置信度最大的一组姿态结果。
本发明优选地技术方案在于,根据掩膜范围提取目标图像块与XYZ map,并将目标图像块与XYZ map输入XYZNet进行特征提取具体为:
将点云保存为XYZ map数据格式,与目标图像块一起输入XYZNet全卷积网络进行密集2D-3D特征提取,获取特征结果。
本发明优选地技术方案在于,在所述S1之前包括:
对卷积神经网络进行训练;
所述对卷积神经网络进行训练具体为,随机初始化网络参数,根据数据集及其对应的真值,卷积神经网络对数据进行处理,输出预测值;
使用预测值和真值计算loss,将loss进行反向传导以修改卷积神经网络的参数。
本发明优选地技术方案在于,根据预测值和真值计算loss,提出PrimADD(S)loss用于处理对称物体旋转多义性;
所述PrimADD(S)包括ADD(S)和primitive error;
所述ADD(S)由ADD和ADD-S组成;
所述ADD用于计算非对称物体目标,所述ADD-S用于计算对称物体目标,具体公式如下:
其中[R,t]是网络估计的姿态,
本发明优选地技术方案在于,通过坐标基元及无多义性坐标基元计算primitiveerror;
所述坐标基元具体为一组和物体自身坐标轴相平行的单位向量,所述无多义性坐标基元具体为在旋转变换中,物体的外观与该坐标基元的状态一一对应,不存在一对多的关系的向量。
本发明优选地技术方案在于,在姿态估计任务中,坐标基元和估计的旋转矩阵之间的关系如下:
[px,py,pz]=R
借助无多义性坐标基元,primitive error计算公式定义如下:
a为非对称物体,b为只有一个无多义性坐标基元,c为不存在无多义性坐标基元,up是指估计的无多义性坐标基元,
本发明优选地技术方案在于,PrimADD(S)loss的形式如下:
PrimADD(S)
λ
本发明的有益效果为:
本发明提供的一种6D姿态估计方法,具有如下优势:
第一个是特征提取模块XYZNet的优势,XYZNet是一个在RGBD数据上提取密集2D-3D特征的架构。这种全卷积的架构相比于DenseFusion等异构架构更加高效而简洁,非常适用于实时性要求高,计算力低的应用场景,比如手机端和嵌入式端的应用,同时所提取的特征具有强大的表征能力,可以用于检测、分割、高精度的姿态估计,密集特征对于遮挡残缺等情况也更鲁棒。
第二个优势在于本发明大大拓宽了姿态估计的应用范围,过去的方法没法正确估计对称物体的姿态,这限制了该项技术的应用,现实生活中,对称物体比比皆是,生活场景的瓶瓶罐罐,圆木家具,工业场景的各种对称工件等,提出的primitve error则有效消除了局部最优的情况,使得网络学习到正确的参数,解决了传统算法用ADD(S)尝试去解决对称物体的旋转多义性问题,但ADD(S)本身的设计就含有缺陷,因ADD(S)在高维空间中存在很多局部最优情况,引导网络进入这些错误的局部最优的问题。
附图说明
图1是本发明具体实施方式中提供的6D姿态估计方法的算法示例图;
图2是本发明具体实施方式中提供的6D姿态估计方法的算法示例图;
图3是本发明具体实施方式中提供的6D姿态估计方法的XYZNet的网络结构;
图4是本发明具体实施方式中提供的6D姿态估计方法的坐标基元示意图;
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。RGBD=RGB+Depth Map,其中RGB色彩模式是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是目前运用最广的颜色系统之一。在3D计算机图形中,Depth Map(深度图)是包含与视点的场景对象的表面的距离有关的信息的图像或图像通道。其中,Depth Map类似于灰度图像,其每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。基于RGBD数据特点,设计了一个高效且简洁的密集2D-3D特征提取网络——XYZNet。不同于DenseFusion的聚合方式,XYZNet将点云数据以XYZ map的格式保存,使点云与图像严格对齐(alignment),并使用2D卷积在RGB图像和XYZ map上进行2D-3D特征提取,这样的设计利用了卷积的窗口结构对原本在3D空间的点进行聚合,能高效提取点云局部几何特征。也区别于Range-based的算法,XYZNet为了避免卷积后丢失空间结构信息,在卷积后仍将XYZ map传递到下一层,并且包含一个CNN实现的PointNet模块以获取点云的全局几何特征,解决了密集2D-3D特征提取不高效的问题,我们基于XYZNet分别实现了DenseFusion和PVN3D,并在YCB-Video数据集上与原算法进行了对比,详细数据见表1,其中ADD-S、ADD(S)用来评价算法的性能,数值越高,性能越好,Inference time(ms)表示模型推理时间,时间越少,效率越高,FLOPs(G)表示模型运算量,Parameters(million)表示模型参数量,数值越小,参数量越低,时间和空间效率越好。可以看到,在ADD(S)精度上,XYZNet实现的DenseFusion提升了2%。基于XYZNet实现的算法在推理时间上几乎是原算法的一半,并且参数量更少。
表1
设计了PrimADD(S)Loss,引入目标的primitives error作为额外的惩罚,不仅解决了网络训练中多义性,相比于ADD(S),PrimADD(S)有效减少的局部最优的情况,解决了对称物体的旋转多义性问题,我们使用同样的特征提取网络与回归方式,但loss分别使用了ADD(S)和PrimADD(S),这两种loss在YCB-Video数据集上的性能对比,见于表2,bowl、wood_block、large_clamp、extra_large_clamp、foam_brick均为对称物体,ALL所在行,表示在YCB-Video数据集上的在不同λ
表2
如图1、图2所示,本实施例中提供的一种6D姿态估计方法,包括以下步骤:
S1:通过图像分割获得目标在图像上的掩膜;
S2:根据掩膜范围提取目标图像块与XYZ map,并将目标图像块与XYZ map输入XYZNet进行特征提取,获得密集2D-3D特征;
S3:将密集2D-3D特征输入三个CNN分支,分别回归3D平移、旋转四元数、置信度,用来估计目标物体6D位姿;
S4:选择置信度最大的一组姿态结果,通过上述方法,XYZNet将点云数据以XYZmap的格式保存,使点云与图像严格对齐(alignment),并使用2D卷积在RGB图像和XYZ map上进行2D-3D特征提取,这样的设计利用了卷积的窗口结构对原本在3D空间的点进行聚合,能高效提取点云局部几何特征,另,提取的特征通过S3、S4可以估计目标的6D姿态。
优选地,通过图像分割获得目标在图像上的掩膜具体步骤为:
通过图像分割把图像分成若干个特定的、具有独特性质的区域并提取感兴趣目标,并对感兴趣目标做掩膜处理,掩模是由0和1组成的一个二进制图像。当在某一功能中应用掩模时,1值区域被处理,被屏蔽的0值区域不被包括在计算中。通过指定的数据值、数据范围、有限或无限值、感兴趣区和注释文件来定义图像掩模,也可以应用上述选项的任意组合作为输入来建立掩模,①提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0;②屏蔽作用,用掩模对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计;③结构特征提取,用相似性变量或图像匹配方法检测和提取图像中与掩模相似的结构特征;④特殊形状图像的制作。用选定的图像、图形或物体,对待处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程,用于覆盖的特定图像或物体称为掩模或模板。
如图2所示,优选地,XYZNet包括:
多层级局部特征提取模块,用于对目标的图像块以及对应的XYZ map经过多层卷积进行局部特征提取,多层卷积采用ResNet18,并对做ResNet18以下修改,
(a)第一个卷积的卷积核大小改为3;
(b)layer 4中不进行下采样;
(c)将layer 4的特征图和最后的pooling特征缩放至layer2的特征图大小;
(d)串联layer2的特征图,layer4的特征图和最后pooling的特征,使用1x1卷积将特征通道调整为512,并作为最后的局部特征输入下个模块;
全局几何信息编码模块,用于将局部特征和坐标串联,并使用多层1x1卷积进行特征编码,并使用max pooling提取代表目标的全局特征。max pooling的含义是对某个Filter抽取到若干特征值,只取得其中最大的那个Pooling层作为保留值,其他特征值全部抛弃,值最大代表只保留这些特征中最强的,抛弃其他弱的此类特征,保证特征的位置与旋转不变性;
密集2D-3D特征聚合模块,用于将局部特征与全局特征串联,全局特征提供感受野更大的上下文信息,局部特征提供细致且具有差异的信息。
优选地,所述S4具体为:将S3得到的置信度值经过argmax函数筛选,得到置信度最大的一组姿态结果,argmax是一种函数,是对函数求参数(集合)的函数。当我们有另一个函数y=f(x)时,若有结果x0=argmax(f(x)),则表示当函数f(x)取x=x0的时候,得到f(x)取值范围的最大值;若有多个点使得f(x)取得相同的最大值,那么argmax(f(x))的结果就是一个点集。换句话说,argmax(f(x))是使得f(x)取得最大值所对应的变量点x(或x的集合)。arg即argument,此处意为“自变量”。
优选地,根据掩膜范围提取目标图像块与XYZ map,并将目标图像块与XYZ map输入XYZNet进行特征提取具体为:
将点云保存为XYZ map数据格式,与目标图像块一起输入XYZNet全卷积网络进行密集2D-3D特征提取,获取特征结果。
优选地,在所述S1之前包括:对卷积神经网络进行训练:
所述对卷积神经网络进行训练具体为,随机初始化网络参数,根据数据集及其对应的真值,卷积神经网络对数据进行处理,输出预测值;
使用预测值和真值计算loss,将loss进行反向传导以修改卷积神经网络的参数,通过上述方法,具体方式如下,1、网络进行权值的初始化;
2、输入数据经过卷积层、下采样层、全连接层的向前传播得到输出值;
3、使用网络的输出值与目标值计算loss;4、在训练结束前,将loss反向传导,计算梯度,并修改网络参数;当误差等于或小于期望值时,结束训练。
优选地,根据预测值和真值计算loss,提出PrimADD(S)loss用于处理对称物体旋转多义性;
所述PrimADD(S)包括ADD(S)和primitive error;
所述ADD(S)由ADD和ADD-S组成;
所述ADD用于计算非对称物体目标,所述ADD-S用于计算对称物体目标,具体公式如下:
其中[R,t]是网络估计的姿态,
优选地,通过坐标基元及无多义性坐标基元计算primitive error;所述坐标基元具体为一组和物体自身坐标轴相平行的单位向量,所述无多义性坐标基元具体为在旋转变换中,物体的外观与该坐标基元的状态一一对应,不存在一对多的关系的向量,如图3所示,长方体饮料盒的三个坐标基元[px,py,pz]都是无多义性坐标基元,碗1、碗2只有pz是无多义性坐标基元。
优选地,在姿态估计任务中,坐标基元和估计的旋转矩阵之间的关系如下:
[px,py,pz]=R
借助无多义性坐标基元,primitive error计算公式定义如下:
a为非对称物体,b为只有一个无多义性坐标基元,c为不存在无多义性坐标基元,up是指估计的无多义性坐标基元,
优选地,PrimADD(S)loss的形式如下:
PrimADD(S)
λ
提供的一种6D姿态估计方法,具有如下优势:
第一个是特征提取模块XYZNet的优势,XYZNet是一个在RGBD数据上提取密集2D-3D特征的架构。这种全卷积的架构相比于DenseFusion等异构架构更加高效而简洁,非常适用于实时性要求高,计算力低的应用场景,比如手机端和嵌入式端的应用,同时所提取的特征具有强大的表征能力,可以用于检测、分割、高精度的姿态估计,密集特征对于遮挡残缺等情况也更鲁棒。
第二个优势在于本发明大大拓宽了姿态估计的应用范围,过去的方法没法正确估计对称物体的姿态,这限制了该项技术的应用,现实生活中,对称物体比比皆是,生活场景的瓶瓶罐罐,圆木家具,工业场景的各种对称工件等,提出的primitve error则有效消除了局部最优的情况,使得网络学习到正确的参数,解决了传统算法用ADD(S)尝试去解决对称物体的旋转多义性问题,但ADD(S)本身的设计就含有缺陷,因ADD(S)在高维空间中存在很多局部最优情况,引导网络进入这些错误的局部最优的问题。
本发明是通过优选实施例进行描述的,本领域技术人员知悉,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。本发明不受此处所公开的具体实施例的限制,其他落入本申请的权利要求内的实施例都属于本发明保护的范围。
- 一种实时高效的6D姿态估计网络、构建方法及估计方法
- 一种基于增强自编码器的室内目标物体6D姿态估计方法