针对工商登记信息中跨企业人员重名实现消歧处理方法、系统、装置、处理器及其存储介质
文献发布时间:2023-06-19 12:14:58
技术领域
本发明涉及数据分析技术领域,尤其涉及企业人名消歧分析领域,具体是指一种针对工商登记信息中跨企业人员重名现象实现消歧处理方法、系统、装置、处理器及其计算机可读存储介质。
背景技术
随着企业注册门槛越来越低,在企业在合作方面越发重视合作企业风险管控。风险管控包括自身风险、关联风险,企业高管人员的风险是关联风险的重要一部分。
在实际生活中,不同企业之间的存在高管人员重名问题。虽然这些信息在有关部门依法等级,但是大量的企业数据来自网络爬虫,这些隐私信息(身份证号码等)并不会在网络公开。因此,通用的身份证识别的方式在企业高管人员识别中无法实施。另外,通过人工调查方法去标记识别重名问题,在小规模的数据中可以使用,在2亿企业数据中人工做重名消歧,几乎是不可能完成的任务。因此,需要实现一种高效准确的重名消歧方法,为企业风险管控做支撑。
发明内容
本发明的目的是克服了上述现有技术的缺点,提供了一种高效准确的针对工商登记信息中跨企业人员重名现象实现消歧处理方法、系统、装置、处理器及其计算机可读存储介质。
为了实现上述目的,本发明的针对工商登记信息中跨企业人员重名现象实现消歧处理方法、系统、装置、处理器及其计算机可读存储介质如下:
该针对工商登记信息中跨企业人员重名现象实现消歧处理方法,其主要特点是,所述的方法包括以下步骤:
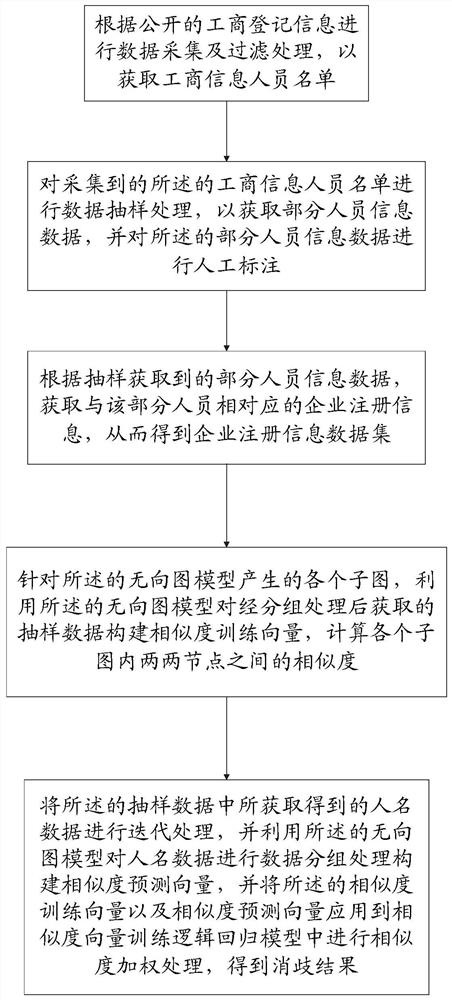
(1)根据公开的工商登记信息进行数据采集及过滤处理,以获取工商信息人员名单;
(2)对采集到的所述的工商信息人员名单进行数据抽样处理,以获取部分人员信息数据,并对所述的部分人员信息数据进行人工标注;
(3)根据抽样获取到的部分人员信息数据,获取与该部分人员相对应的企业注册信息,从而得到企业注册信息数据集;
(4)根据所述的企业注册信息数据集创建无向图模型,对各个数据进行分组处理;
(5)针对所述的无向图模型产生的各个子图,利用所述的无向图模型对经分组处理后获取的抽样数据构建相似度训练向量,计算各个子图内两两节点之间的相似度;
(6)将所述的抽样数据中所获取得到的人名数据进行迭代处理,并利用所述的无向图模型对人名数据进行数据分组处理构建相似度预测向量,并将所述的相似度训练向量以及相似度预测向量应用到相似度向量训练逻辑回归模型中进行相似度加权处理,得到消歧结果。
较佳地,所述的步骤(1)具体为:
将采集获取到的所述的公开的工商登记信息进行数据过滤,并根据过滤后的所述的工商登记信息中的各个工商人员与其所对应的公司名称之间是否存在投资参股的行为来收集所述的工商信息人员名单。
较佳地,所述的步骤(2)具体包括以下步骤:
(2.1)标记人员对所述的工商信息人员名单进行去重处理,并对去重处理后的数据进行数据抽样处理,获取部分人员的待消歧数据集;
(2.2)获取所述的待消歧数据集中的人名信息得到待消歧人名信息数据集;
(2.3)所述的标记人员对所述的待消歧人名信息数据集进行人工标注,并根据获取的工商登记信息与搜索引擎得到信息判断该企业人员是否为同一个人。
较佳地,所述的工商信息包括:公司名称、联系电话、邮箱、官网、公司地址以及实时计算的企业字号。
较佳地,所述的工商信息通过统计模型,过滤噪音数据后获得,所述的统计模型为TF-IDF模型,具体通过以下步骤获取所述的工商信息:
(a)将所有工商信息数据中的官网、联系电话、邮箱构建倒排索引并统计词频;
(b)将上述步骤(a)中获取的每一个数据q,使用以下公式计算其权重:
w(q)=TF(q)×log(N/(df+1));
其中,w(q)为每一个特征数据q的权重,df值为倒排索引中包含每一个特征数据q的公司数量,TF(q)恒为1,N为公司总数量。
较佳地,所述的工商信息人员名单具体包括各个公司的法定代表人,股东以及高级管理人员。
较佳地,所述的步骤(4)具体:
根据所述的企业注册信息数据集,以所述的工商信息中的公司名称为点,以其他工商信息为边,构建无向图模型,并对该企业注册信息数据集中的各个数据进行分组处理。
较佳地,所述的步骤(5)具体包括以下步骤:
(5.1)找出所述的无向图模型中所有节点数大于2的连通子图;
(5.2)将所述的节点数大于2的连通子图中的预设维度的数据进行分组处理,计算每一个维度下各个数据之间的相似度从而构建相似度训练向量,并根据人工标注结果作为训练标注,以计算各个节点之间的相似度权重。
较佳地,所述的预设维度包括企业全称、企业字号以及地址,其中,所述的企业全称具体包括区号、字号、行业特征以及组织形式。
尤佳地,所述的相似度向量训练逻辑回归模型具体包括编辑距离算法以及拆分算法,其中,编辑距离算法通过以下公式进行计算:
其中,
所述的拆分算法具体为:将所述的企业全称使用Transformer神经网络+CRF拆分算法进行序列标注学习。
更佳地,将所述的无向图模型中获取的所有工商登记信息的特征数据进行逻辑回归学习,通过损失代价函数的最小化结果,从而预测各个企业之间是否存在相似性,其中,所述的损失代价函数具体根据以下公式进行计算:
cost(h
其中,cost为损失函数处理,log为计算对数函数,x为输入特征数据的离散样本,y为输入特征数据的离散样本标签,0或1,yi为第i个样本的真值,θ为待求特征数据,h
该针对工商登记信息中跨企业人员重名现象进行消歧处理的系统,其主要特点是,所述的系统包括:
数据采集模块,用于根据所有公开的工商信息获取工商信息人员名单;
数据过滤模块,与所述的数据采集模块相连接,用于根据统计模型过滤所述的工商信息中为噪音的数据,得到对应的企业注册信息;
数据集获取模块,与所述的数据过滤模块相连接,用于根据所述的工商信息人员名单获取对应的企业信息数据集;
数据处理模块,与所述的数据集获取模块相连接,用于针对获取的企业信息数据集创建无向图模型,进行相似度分析处理。
该用于实现针对工商登记信息中跨企业人员重名现象进行消歧处理的装置,其主要特点是,所述的装置包括:
处理器,被配置成执行计算机可执行指令;
存储器,存储一个或多个计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述针对工商登记信息中跨企业人员重名现象进行消歧处理的方法的各个步骤。
该用于实现针对工商登记信息中跨企业人员重名现象进行消歧处理的处理器,其主要特点是,所述的处理器被配置成执行计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述针对工商登记信息中跨企业人员重名现象进行消歧处理的方法的各个步骤。
该计算机可读存储介质,其主要特点是,其上存储有计算机程序,所述的计算机程序可被处理器执行以实现上述针对工商登记信息中跨企业人员重名现象进行消歧处理的方法的各个步骤。
采用了本发明的该针对工商登记信息中跨企业人员重名现象实现消歧处理方法、系统、装置、处理器及其计算机可读存储介质,通过构建相似度向量训练逻辑回归模型,对各相关人员名称进行消歧,用于判断不同企业之间是否存在一定的相似度。同时,本发明可以自动对企业人名进行消歧,有较高的召回率,对于实现细节可根据数据状况选择计算公式,并设置阈值;同时本发明在可在大规模数据集中快速计算,可为企业关联关系分析提供一定的支撑。
附图说明
图1为本发明的针对工商登记信息中跨企业人员重名现象实现消歧处理方法的流程图。
图2为本发明的实际处理结果示意图。
具体实施方式
为了能够更清楚地描述本发明的技术内容,下面结合具体实施例来进行进一步的描述。
在详细说明根据本发明的实施例前,应该注意到的是,在下文中,术语“包括”、“包含”或任何其他变体旨在涵盖非排他性的包含,由此使得包括一系列要素的过程、方法、物品或者设备不仅包含这些要素,而且还包含没有明确列出的其他要素,或者为这种过程、方法、物品或者设备所固有的要素。
请参阅图1所示,该针对工商登记信息中跨企业人员重名现象实现消歧处理方法,其中,所述的方法包括以下步骤:
(1)根据公开的工商登记信息进行数据采集及过滤处理,以获取工商信息人员名单;
(2)对采集到的所述的工商信息人员名单进行数据抽样处理,以获取部分人员信息数据,并对所述的部分人员信息数据进行人工标注;
(3)根据抽样获取到的部分人员信息数据,获取与该部分人员相对应的企业注册信息,从而得到企业注册信息数据集;
(4)根据所述的企业注册信息数据集创建无向图模型,对各个数据进行分组处理;
(5)针对所述的无向图模型产生的各个子图,利用所述的无向图模型对经分组处理后获取的抽样数据构建相似度训练向量,计算各个子图内两两节点之间的相似度;
(6)将所述的抽样数据中所获取得到的人名数据进行迭代处理,并利用所述的无向图模型对人名数据进行数据分组处理构建相似度预测向量,并将所述的相似度训练向量以及相似度预测向量应用到相似度向量训练逻辑回归模型中进行相似度加权处理,得到消歧结果。
作为本发明的优选实施方式,所述的步骤(1)具体为:
将采集获取到的所述的公开的工商登记信息进行数据过滤,并根据过滤后的所述的工商登记信息中的各个工商人员与其所对应的公司名称之间是否存在投资参股的行为来收集所述的工商信息人员名单。
作为本发明的优选实施方式,所述的步骤(2)具体包括以下步骤:
(2.1)标记人员对所述的工商信息人员名单进行去重处理,并对去重处理后的数据进行数据抽样处理,获取部分人员的待消歧数据集;
(2.2)获取所述的待消歧数据集中的人名信息得到待消歧人名信息数据集;
(2.3)所述的标记人员对所述的待消歧人名信息数据集进行人工标注,并根据获取的工商登记信息与搜索引擎得到信息判断该企业人员是否为同一个人。
作为本发明的优选实施方式,所述的工商信息包括:公司名称、联系电话、邮箱、官网、公司地址以及实时计算的企业字号。
作为本发明的优选实施方式,所述的工商信息通过统计模型,过滤噪音数据后获得,所述的统计模型为TF-IDF模型,具体通过以下步骤获取所述的工商信息:
(a)将所有工商信息数据中的官网、联系电话、邮箱构建倒排索引并统计词频;
(b)将上述步骤(a)中获取的每一个数据q,使用以下公式计算其权重:
w(q)=TF(q)×log(N/(df+1));
其中,w(q)为每一个特征数据q的权重,df值为倒排索引中包含每一个特征数据q的公司数量,TF(q)恒为1,N为公司总数量。
作为本发明的优选实施方式,所述的工商信息人员名单具体包括各个公司的法定代表人,股东以及高级管理人员。
作为本发明的优选实施方式,所述的步骤(4)具体:
根据所述的企业注册信息数据集,以所述的工商信息中的公司名称为点,以其他工商信息为边,构建无向图模型,并对该企业注册信息数据集中的各个数据进行分组处理。
作为本发明的优选实施方式,所述的步骤(5)具体包括以下步骤:
(5.1)找出所述的无向图模型中所有节点数大于2的连通子图;
(5.2)将所述的节点数大于2的连通子图中的预设维度的数据进行分组处理,计算每一个维度下各个数据之间的相似度从而构建相似度训练向量,并根据人工标注结果作为训练标注,以计算各个节点之间的相似度权重。
作为本发明的优选实施方式,所述的预设维度包括企业全称、企业字号以及地址,其中,所述的企业全称具体包括区号、字号、行业特征以及组织形式。
作为本发明的优选实施方式,所述的相似度向量训练逻辑回归模型具体包括编辑距离算法以及拆分算法,其中,编辑距离算法通过以下公式进行计算:
其中,
所述的拆分算法具体为:将所述的企业全称使用Transformer神经网络+CRF拆分算法进行序列标注学习。
作为本发明的优选实施方式,将所述的无向图模型中获取的所有工商登记信息的特征数据进行逻辑回归学习,通过损失代价函数计算最小化结果,从而预测各个企业之间是否存在相似性,其中,所述的损失代价函数具体根据以下公式进行计算:
cost(h
其中,cost为损失函数处理,log为计算对数函数,x为输入特征数据的离散样本,y为输入特征数据的离散样本标签,0或1,yi为第i个样本的真值,θ为待求特征数据,h
该针对工商登记信息中跨企业人员重名现象进行消歧处理的系统,其中,所述的系统包括:
数据采集模块,用于根据所有公开的工商信息获取工商信息人员名单;
数据过滤模块,与所述的数据采集模块相连接,用于根据统计模型过滤所述的工商信息中为噪音的数据,得到对应的企业注册信息;
数据集获取模块,与所述的数据过滤模块相连接,用于根据所述的工商信息人员名单获取对应的企业信息数据集;
数据处理模块,与所述的数据集获取模块相连接,用于针对获取的企业信息数据集创建无向图模型,进行相似度分析处理。
该用于实现针对工商登记信息中跨企业人员重名现象进行消歧处理的装置,其中,所述的装置包括:
处理器,被配置成执行计算机可执行指令;
存储器,存储一个或多个计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述针对工商登记信息中跨企业人员重名现象进行消歧处理的方法的各个步骤。
该用于实现针对工商登记信息中跨企业人员重名现象进行消歧处理的处理器,其中,所述的处理器被配置成执行计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述针对工商登记信息中跨企业人员重名现象进行消歧处理的方法的各个步骤。
该计算机可读存储介质,其中,其上存储有计算机程序,所述的计算机程序可被处理器执行以实现针对工商登记信息中跨企业人员重名现象进行消歧处理的方法的各个步骤。
在本发明的一具体实施方式中,本发明的该针对工商登记信息中跨企业人员重名现象实现消歧处理方法的主要如下:
将所有工商数据中的人名信息去重后得到待消歧数据集C,随机抽取C中的人名信息获取所有包含改人名的训练集T,对T进行人工标注是否未同一人;对步骤1中的每个待消歧人名N
在本发明的一具体实施方式中,本发明的该针对工商登记信息中跨企业人员重名现象实现消歧处理方法的具体实施步骤如下:
(1)工商信息人员的筛选包括:法定代表人,股东,高级管理人员。
判断依据:工商信息人员和公司名称之间根据是否存在投资参股来收集。
(2)根据人员重名的条件抽取工商信息,工商信息具体指:公司名称,联系电话,邮箱,官网,公司地址,以及实时计算的字号。对于联系电话、邮箱、网址等信息,均由企业自主上报,存在代理公司上报与企业人员误上报的情形。为解决此问题,我们针对以上信息使用统计模型,过滤噪音数据。
(3)企业名称相似与否的判断是从两个角度出发①是公司的全称②是企业字号。其中①,②可以使用两种方式计算其相似度。1.编辑距离;2.单词分布式表示。考虑在大规模应用的效率,本专利使用编辑距离方式计算。因为公司全称是由区号,字号,行业特征和组织形式构成。企业名称拆分算法,使用Transformer神经网络+CRF进行序列标注学习。(区别与专利3,使用的是注意力机制,训练准确且快速)
(4)创建无向图,以公司为节点,企业工商信息为边(将当前被计算人名信息去除)。考虑到联系电话,邮箱可能来自第三方代理公司,导致整个图出现大量噪音数据影响预测结果,步骤2中的统计模型解决了此问题。
(5)对于整个无向图,找出其中所有节点数大于2的连通子图,单一节点的子图无需计算,减小计算量。两个公司之间的路径数越多,两个公司的关联性在一定程度上就会增强,考虑到后续训练效率,路径数需要归一化处理,提升模型的收敛速度。
(6)使用编辑距离计算公司名称,企业字号和地址的相似度相关公式。
字符串A和B表示两个不同的公司名称,或企业字号,或地址。
函数edis(A,B)表示字符串A和B的编辑距离,A转换为B的最少编辑次数,函数strlen表示字符串的长度。
(7)步骤(2)中统计模型为TF-IDF模型处理官网网址,联系电话,邮箱合理性与权重的计算过程。
①将所有企业信息的数据中网址、电话、邮箱构建倒排索引并统计词频;
②对于每一个数据q,计算其权重,使用公式如下
w(q)=TF(q)×log(N/(df+1)),其中df值为倒排索引中包含q的公司数量,TF(q)恒为1。
(8)将所有特征进行逻辑回归学习,通过损失代价函数的最小化结果,预测为有关联或无关联,根据整体效果,将损失代价函数中的sigmod函数中阈值取0.5进行逻辑回归学习,其中损失函数如下:
cost(h
请参阅图2所示,在本发明的另一具体实施方式中,首先,利用公开的工商登记信息进行数据采集及过滤处理以获取工商信息人员名单;训练人员通过随机抽样获取部分人员信息数据并进行人工标注,再根据获取到的部分人员信息数据,匹配获取对应的企业注册信息,从而得到企业注册信息数据集;根据获取得到的企业注册信息数据集创建无向图模型,对各个数据进行分组处理;利用经过人工标注后得到的抽样数据计算组内每个维度的相似度以构建训练向量,并根据人工标注结果作为训练标注,将与经过迭代处理的人名数据利用无向图模型进行数据分类,计算每个人名数据之间的相似度构建的预测向量应用到进行相似度向量训练逻辑回归模型中进行相似度加权处理,从而得到最终的跨企业人员重名现象消歧的结果。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行装置执行的软件或固件来实现。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成的,程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一实施例”、“一些实施例”、“示例”、“具体示例”、“实施方式”或“实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
采用了本发明的该针对工商登记信息中跨企业人员重名现象实现消歧处理方法、系统、装置、处理器及其计算机可读存储介质,通过构建相似度向量训练逻辑回归模型,对各相关人员名称进行消歧,用于判断不同企业之间是否存在一定的相似度。同时,本发明可以自动对企业人名进行消歧,有较高的召回率,对于实现细节可根据数据状况选择计算公式,并设置阈值;同时本发明在可在大规模数据集中快速计算,可为企业关联关系分析提供一定的支撑。
在此说明书中,本发明已参照其特定的实施例作了描述。但是,很显然仍可以作出各种修改和变换而不背离本发明的精神和范围。因此,说明书和附图应被认为是说明性的而非限制性的。
- 针对工商登记信息中跨企业人员重名实现消歧处理方法、系统、装置、处理器及其存储介质
- 提升逐篇归档的效率的人物重名消歧方法、系统、设备