一种基于深度语义对齐网络模型的图像匹配方法
文献发布时间:2023-06-19 12:22:51
技术领域
本发明属于计算机视觉和数字图像处理技术领域,涉及图像匹配技术,具体涉及一种基于图像深度语义对齐网络模型建立相似图像中主要目标物体的准确对应匹配关系的方法。
背景技术
图像语义对齐旨在图像间建立相似目标物体的准确对应关系,即,不同图像中相似目标物体间点对点的特征匹配关系。具体场景是指在图像内容信息相同或者相似的前提下,利用图像的特征信息,分析并量化特征之间的相似度,进而确定图像中相似物体上特征点的匹配关系。该问题是计算机视觉中的一个基本问题,在目标跟踪、图像语义分割、多视点三维重建等领域有着广泛的应用。
语义对齐近年来受到广泛关注。早期的研究包括通过定义和计算稀疏或密集描述子来寻找实例级匹配的方法[5]。然而,这些方法的实例级描述缺乏类别级对应的泛化能力。类别级对应的目的是在语义相似的图像之间找到密集的对应关系。一些方法使用局部描述子并最小化投入的匹配能量。而人工构建的描述子很难嵌入高级语义特征,并对图像变化很敏感。
受卷积神经网络(CNN)特征丰富的高级语义的启发,最近的解决方案(参考文献[2],[4],[6],[7],[8])采用训练CNN特征并将其结合,来估计稠密流场,从而对齐图像。此外参考文献[1],[3],[9],[10]中采用的方法是估计具有可训练CNN特征的几何变换,并将语义对应表述为几何对齐问题。得益于描述稠密对应的几何变换,其中一些方法的性能优于基于稠密流的方法,并产生了更平滑的匹配结果。
尽管现有方法取得了很大的进展,但语义对齐问题仍面临着一些挑战,如由物体变化(如外观、尺度、形状、位置)和复杂背景导致的对齐困难。具体地,首先,由于目标位置差异较大,很难直接建立图像间的密集对应关系,效果不佳(如图1所示)。由于处理此类情况的研究不够,以前的方法往往无法对齐此类图像。其次,是数据标注方面的困难,即很难收集到大量的具有地面真实稠密对应和显著外观变换的训练图像对。手工注释这样的训练数据是非常耗费人力并且带有一定的主观性。
参考文献:
[1]Ignacio Rocco,Relja Arandjelovic,and Josef Sivic,“Convolutionalneural network architecture for geometric matching,”inCVPR,2017.
[2]Kai Han,Rafael S Rezende,Bumsub Ham,Kwan-Yee K Wong,Minsu Cho,Cordelia Schmid,and Jean Ponce,“Scnet:Learning semantic correspondence,”inICCV,2017.
[3]Ignacio Rocco,Relja
[4]Junghyup Lee,Dohyung Kim,Jean Ponce,and Bumsub Ham,“Sfnet:Learningobject-aware semantic correspondence,”in CVPR,2019.
[5]David G Lowe,“Distinctive image features from scale-invariantkeypoints,”IJCV,vol.60,no.2,2004.
[6]Ce Liu,Jenny Yuen,and Antonio Torralba,“Sift flow:Densecorrespondence across scenes and its applications,”IEEE TPAMI,vol.33,no.5,2010.
[7]Bumsub Ham,Minsu Cho,Cordelia Schmid,and Jean Ponce,“Proposalflow:Semantic correspondences from object proposals,”IEEETPAMI,vol.40,no.7,2017.
[8]Seungryong Kim,Dongbo Min,Bumsub Ham,Sangryul Jeon,Stephen Lin,andKwanghoon Sohn,“Fcss:Fully convolutional self-similarity for dense semanticcorrespondence,”in CVPR,2017.
[9]Paul Hongsuck Seo,Jongmin Lee,Deunsol Jung,Bohyung Han,and MinsuCho,“Attentive semantic alignment with offset-aware correlation kernels,”inECCV,2018.
[10]Ignacio Rocco,Mircea Cimpoi,Relja
发明内容
为了克服上述现有技术的不足,本发明提供一种基于深度语义对齐网络模型的图像匹配方法,通过建立一个对象位置感知的语义对齐网络并采用三重采样策略训练该网络,以分层建立和优化图像之间的对齐关系,解决现有技术难以直接建立图像间的密集对应关系以及图像数据标注费时费力且准确度低的技术问题,提高图像匹配的准确度。
本发明中的图像语义对齐技术是图像匹配或图像特征匹配领域中的子问题,它主要针对的场景为:待匹配的两个图像虽不相同,但均包含了一个相似的前景目标,即,前景目标的外观、形状、姿态等高层语义信息是相似的,而且该目标基本属于同一类别,如不同品牌的轿车。
本发明提供的技术方案是:
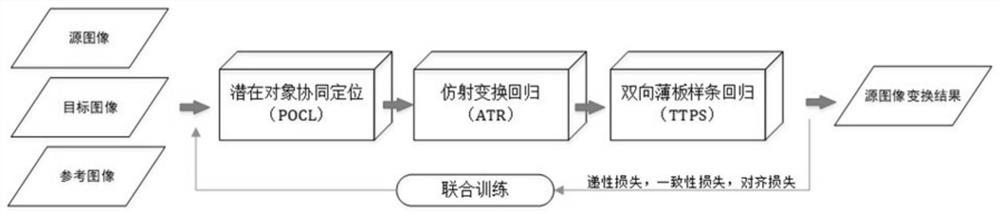
一种基于深度语义对齐网络模型的图像匹配方法,通过建立一个对象位置感知的语义对齐网络模型——OLASA,逐步、鲁棒地估计两个语义相似图像之间的对齐;同时,提出了一种三重采样策略训练该网络,通过三个子网络(潜在对象协同定位(POCL)、仿射变换回归(ATR)、双向薄板样条回归(TTPS))分别估计平移、仿射变换和样条变换,进而以分层建立和优化图像之间的对齐关系,得到图像匹配结果;包括如下步骤:
步骤1、提取图像语义特征;
本方法中,每个子网络的前端采用一个独立的卷积神经网络(CNN)用来提取图像的特征。具体实施时,本发明采用一个卷积神经网络(CNN)提取两个图像的特征,该网络可以是最基本的CNN网络,也可以是改进或增强后的CNN网络。
式(1)中,F为从图像中提取的特征,
将一对图像
本发明建立一个对象位置感知的语义对齐网络模型——OLASA,逐步、鲁棒地估计两个语义相似图像之间的对齐。OLASA的系统架构也是以POCL、ATR、TTPS三个子网络为主体,分别命名为N
步骤2、采用潜在对象协同定位子网络(N
针对图像间相似目标物体往往存在显著位移的问题,N
潜在对象协同定位子网络表示为
式中,
为了估计偏移变换模型
进一步定位I
将描述子{V
选取Z
最后,利用定位得到两个主要的潜在对象对应的边框的空间坐标,计算出位置偏移变换模型
步骤3、构建仿射变换回归子网络N
ATR子网络用于估计经过偏移调整后的图像与目标图像的仿射变换模型。ATR子网络需将图像特征构造成对,即特征对,并计算特征对的相关度,据此估计仿射变换模型的参数。
具体实施时,将经位置偏移变换的图像
其中,仿射变换模型
步骤4、构建双向薄板样条回归子网络N
TTPS子网络N
具体实施时,在图像
其中,
步骤5、联合训练包括三个子网络的整体OLASA网络模型;
在训练样本的选择方面,本发明通过引入参考图像提出了三元组方法,该方法可以更好地捕获训练数据中的几何变化和外观变化。
步骤51、本发明提出了三重抽样策略来生成训练数据。每个三元组包含源图像I
步骤52、设计三个损失函数来实现OLASA的优化,包括传递性损失、一致性损失和对齐损失。
传递损失函数
以检验某个仿射变换
其中,上述变换涉及了源图像、目标图像和参考图像三类对象,为此,我们将其组建成用于训练相关模型的三元组,即一条训练数据需由一副源图像、一副目标图像和一副参考图像构成。该方法亦可看成在传统的训练对(源图像、目标图像)基础上增加了一副相应参考图像。相关的损失计算有可能同时计算三种变换,每种变换会涉及三元组中的某个图对(两图属于不同图像类型),例如,仿射变换回归子网络
类似地,本方法中也将传递损失
一致性损失函数
给定一个图像I
其中,ε(I
在由源图像、目标图像和参考图像构成的三元样本中,还有其他图像对也包含了双向重投影误差,将其全部累计起来,就可以作为本方法的一致性损失函数
类似地,本方法中也将一致性损失
对齐损失函数
其中c
步骤6、获得图像匹配结果;
依据联合训练的整体网络,可针对给定待匹配图像对,给出源图像到目标图像的对齐结果。
具体通过包含三个子网络的整体网络进行学习训练,本方法可以根据训练数据样本得到图像对齐的变换模型,即得到训练好的对象位置感知的语义对齐网络模型OLASA。在测试阶段,即可针对给定的待匹配图像对,计算出源图像到目标图像的匹配图像结果。
与现有技术相比,本发明的有益效果:
本发明提供一种基于深度语义对齐网络模型的图像匹配方法,包括潜在对象协同定位(POCL)、仿射变换回归(ATR)、双向薄板样条回归(TTPS)三个子网络,其中POCL可有效地感知潜在对象的偏移,ATR可学到几何形变的参数,TTPS可提高变形的鲁棒性,三个子网络的联合学习不仅可以实现图像的语义对齐,而且能够获得更高准确率的图像匹配效果。利用本发明提供的技术方案,可以提高位置差异较大的图像对齐效果。同时,可以在标注数据缺乏的场景中,借助生成参考图像,更深入地挖掘和利用现有数据中的几何变化和外观变化,提高图像匹配的准确度。本发明可应用于计算机视觉领域的多种任务中,如目标跟踪、语义分割和多视点三维重建等。
附图说明
图1为图像匹配中图像中物体对象位置感知语义对齐的示意图;
其中,Is表示源图像;It表示目标图像。
图2为本发明建立的OLASA网络模型进行图像匹配的方法流程框图;
图3为本发明建立的2-2为OLASA网络模型的结构框图;
其中,I
图4为本发明中OLASA网络模型的训练三元组及相关变换模型示意图;
其中,(a)为源图像I
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明所提出基于深度语义对齐网络模型的图像匹配方法是一个基于语义对齐的深度神经网络模型OLASA,该模型方法的输入是源图像、目标图像和参考图像,OLASA通过对源图像和目标图像的深度语义分析,依据其内在对齐关系估计出对源图像的变形参数,经过变形的后源图像即为本方法的输出结果,其所含的目标物体可以匹配到目标图像中相应物体上。OLASA的内部实现是通过三个子网络的联合学习:三个子网络,潜在对象协同定位(POCL)、仿射变换回归(ATR)、双向薄板样条回归(TTPS)而达到有效进行图像匹配的目的。
图2所示为本发明建立的OLASA网络模型进行图像匹配的方法流程。本发明方法可用于任何给定的图像对(即源图像、目标图像),源图像和目标图像组成的图像对可以通过拍摄或网络下载等方式获取。采用图像数据集如PF-WILLOW[11],PF-PASCAL(文献[11]:Bumsub Ham,Minsu Cho,Cordelia Schmid,and Jean Ponce,“Proposal flow,”in CVPR,2016.)和Caltech-101(文献[12]:Li Fei-Fei,Rob Fergus,and Pietro Perona,“One-shot learning of object categories,”IEEE TPAMI,vol.28,no.4,2006.)等均可。参考图像采用本发明方法在执行过程中根据源图像计算得到。本发明方法的具体实现步骤如下。
步骤1、图像语义特征提取
OLASA接收源图像、目标图像和参考图像后,首先要提取其特征。即,将待匹配的一对图像(源图像和目标图像,可采用图像库中的图像或拍摄得到)
步骤2、采用潜在对象协同定位(POCL)子网络估计偏移
在实际情况中,源图像和目标图像中要做匹配的对象往往分别位于各自图像中的不同位置,即,待匹配对象之间往往存在较大的位置差异。现有方法往往只处理几乎处于同一位置的待匹配对象,而对上述存在较大位置差异的情况很少采取专门的处理方法,从而导致了很多方法的实际应用难以取得理想的匹配效果。本发明针对该问题,在实现图像匹配的第一阶段就采用一个预处理网络,潜在对象协同定位子网络(POCL)来消除待匹配对象的位置偏差。
该子网络定义为
其中,
为了估计偏移变换模型
为了进一步定位I
POCL仅用来捕获潜在对象位置偏差,并在位置偏差较大时,能够通过位置偏移变换实现相应的位置调整,但POCL还不能实现精准的语义对齐。
步骤3、利用仿射变换回归(ATR)子网络估计仿射变换模型
OLASA通过更为精准的仿射变换回归(ATR)子网络
其中,仿射变换模型
步骤4、使用双向薄板样条回归(TTPS)子网络优化对齐效果
利用控制点网络可以进一步改善或增强图像的语义对齐效果。具体地,通过使用双向薄板样条回归(TTPS)子网络进一步在图像
类似地,
步骤5、整体网络的联合训练
上述三个子网络的连续变换,实现了一种从粗到细的匹配原则,图像对I
传统方法在训练该网络时通常使用图像对作为训练样本,与之不同,对于OLASA的训练,我们通过引入参考图像,提出了三重抽样策略来生成训练数据。每个三元组包含源图像I
为实现整体模型的训练目标,我们设计了三个损失函数来实现OLASA的优化,包括传递性损失、一致性损失和对齐损失。
传递损失。在三重样本上,我们根据几何变换的传递性和网络MSE设计了传递损失
类似地,本方法中也将传递损失
一致性损失。几何变换中的一致性是从图像到图像变换中使用的循环一致性拓展得到的,可作为传递损失的补充。我们设计的一致性损失
在三元样本中,还有其他图像对也包含了双向重投影误差,将其全部累计起来,就可以作为本方法的一致性损失函数
类似地,本方法中也将一致性损失
对齐损失。对齐损失
其中c
步骤6、匹配结果的获得
通过包含三个子网络在内的整体网络学习,本方法可以根据训练数据样本得到图像对齐的变换模型,在测试阶段,即可针对给定的待匹配图像对,计算出源图像到目标图像的匹配结果。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 一种基于深度语义对齐网络模型的图像匹配方法
- 一种基于6W语义标识的语义网络模型构建方法