一种基于深度学习的物流包裹自主检测方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及物流领域,其中涉及一种基于深度学习的物流包裹自主检测方法。
背景技术
当今,我国的物流市场已经位居世界之首,但成本所占比例仍然过高。特别是物流中转站,当包裹在传送带或其他自动化设备上传输时,由于包裹的大量堆积,难免会出现不慎掉落或卡住等异常情况。物流中转站使用监控录像等人为的方法使位置异常的包裹归位,但这对于庞大的包裹数量来说,无论是效率还是成本都不尽如人意。目标检测技术已经广泛应用于工业、医疗、航空等领域,计算机可以帮助甚至取代人类进行物体的检测工作,在提升效率的同时降低了成本和出错率。
当今的物流中转站虽然已经在很多方面提升了自动化水平,但上述问题仍然依靠人力解决,通过工作人员去监控视频中寻找丢失的包裹,不仅费时费力,而且看的时间一长,还会产生疲劳,导致容易遗漏掉一些包裹,提高出错的概率。因此需要提出一种能够提高包裹检测效率的同时兼顾成本和出错率的包裹智能检测方法。考虑到物流包裹大量堆积对检测造成的影响,对模型进行改进。此外,对位置纠正后的包裹进行进一步分类处理,有利于提高物流中转站的运作效率。因此,提出一种与多机器人协同路径规划技术相结合的包裹分类处理方法。
发明内容
鉴于现有技术的不足,本发明旨在于提供一种基于深度学习的物流包裹自主检测方法,通过本发明能够更好的进行物流包裹异常位置检测并降低检测成本和出错率以及对位置纠正后的包裹进行分类处理。
为了实现上述目的,本发明采用的技术方案如下:
一种基于深度学习的物流包裹自主检测方法,所述方法包括:
S1物流包裹数据采集:基于深度学习模型建立物流包裹图片数据集,数据集从多个场景采集,并且具备不同的角度、光线,也包含一些密集包裹和小包裹;
S2建立物流包裹数据集:根据监督学习要求,使用数据标注工具对数据集中的所有图片进行手动标注;
S3使用改进后的基于深度学习的目标检测模型进行训练:获得包裹位置异常识别模型;
S4使用包裹位置异常识别模型对物流包裹数据进行识别:对识别结果进行评价。
需要说明的是,所述深度学习模型,以YOLOv3作为基础。
需要说明的是,使用焦点损失函数代替交叉熵损失函数,解决模型出现的类别不平衡;焦点损失函数公式为:
FL(p
其中,a
需要说明的是,引入Deep-SORT算法,解决物流包裹传送过程中包裹堆积导致的包裹和包裹间存在遮挡,包裹错误检测;
其中,将物流包裹的运动和表面特征信息结合,将基于深度特征向量最小余弦距离的表观信息和基于马式距离的运动信息进行加权融合,得到一个新的度量匹配信息,改善遮挡对于检测性能的影响。
需要说明的是,使用剪枝方法,改善引入Deep-SORT算法导致的计算量加大;
通过对模型进行剪枝,减少卷积层中特征性较弱的神经元,加快训练速度;基于模型进行稀疏化训练,得到稀疏化后的BN权重;
使用随机梯度下降更新BN层参数γ,公式为:
排列得到的γ值,选定临界值s,小于s的γ全部剪掉,得到剪枝后的模型;对剪枝后的模型进行通道调整,减少特征通道数量,简化模型。
本发明有益效果在于,能够提高包裹检测效率的同时兼顾成本和出错率的包裹智能检测方法,改善包裹大量堆积情况下的检测性能,同时验证了YOLOv3算法应用于包裹检测的可行性。
附图说明
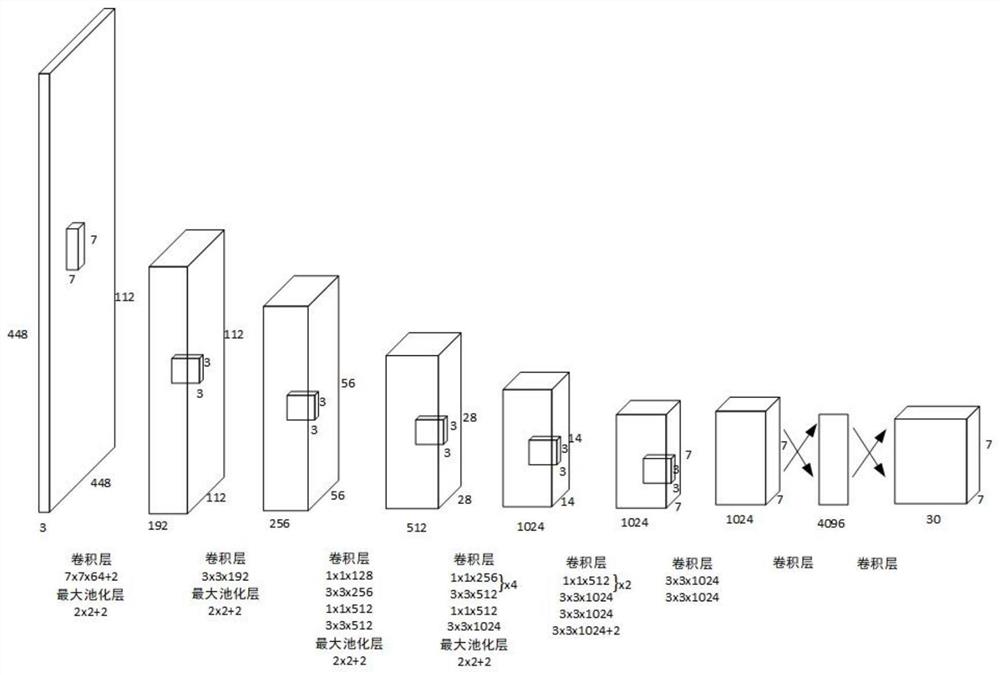
图1是本发明中基于深度学习的物流包裹自主检测方法的一具体实施例的YOLOv1结构图;
图2是本发明中基于深度学习的物流包裹自主检测方法的一具体实施例的YOLOv3结构图;
图3是本发明中基于深度学习的物流包裹自主检测方法的一具体实施例的包裹检测系统流程图;
图4是本发明中多机器人协同分类搬运系统一具体实施例的多机器人检测搬运图;
图5是本发明中基于深度学习的物流包裹自主检测方法及多机器人协同分类搬运系统的实施流程图;
图6为本发明中基于深度学习的物流包裹自主检测方法及多机器人协同分类搬运系统屋顶相机、包裹、物流机器人位置示意图。
具体实施方式
下将结合附图对本发明作进一步的描述,需要说明的是,本实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
本发明为一种基于深度学习的物流包裹自主检测方法,所述方法包括:
S1物流包裹数据采集:基于深度学习模型建立物流包裹图片数据集,数据集从多个场景采集,并且具备不同的角度、光线,也包含一些密集包裹和小包裹;
S2建立物流包裹数据集:根据监督学习要求,使用数据标注工具对数据集中的所有图片进行手动标注;
S3使用改进后的基于深度学习的目标检测模型进行训练:获得包裹位置异常识别模型;
S4使用包裹位置异常识别模型对物流包裹数据进行识别:对识别结果进行评价。
需要说明的是,所述深度学习模型,以YOLOv3作为基础。
需要说明的是,使用焦点损失函数代替交叉熵损失函数,解决模型出现的类别不平衡;焦点损失函数公式为:
FL(p
其中,a
需要说明的是,引入Deep-SORT算法,解决物流包裹传送过程中包裹堆积导致的包裹和包裹间存在遮挡,包裹错误检测;
其中,将物流包裹的运动和表面特征信息结合,将基于深度特征向量最小余弦距离的表观信息和基于马式距离的运动信息进行加权融合,得到一个新的度量匹配信息,改善遮挡对于检测性能的影响。
需要说明的是,使用剪枝方法,改善引入Deep-SORT算法导致的计算量加大;
通过对模型进行剪枝,减少卷积层中特征性较弱的神经元,加快训练速度;基于模型进行稀疏化训练,得到稀疏化后的BN权重;
使用随机梯度下降更新BN层参数γ,公式为:
排列得到的γ值,选定临界值s,小于s的γ全部剪掉,得到剪枝后的模型;对剪枝后的模型进行通道调整,减少特征通道数量,简化模型。
实施例一
本实例提供了一种深度学习物体检测模型,模型结构如图1,将输入图像划分为7*7的网格,如果某目标的中心坐标位于某个小格子中,则该小格子负责检测这个目标物体。
使用每个小格子预测2个边界框,并且使用PASCAL VOC数据集进行训练,小格子能够预测20类物体属于某一类的概率。每个边界框有x,y,w,h,confidence这5个信息。x,y是小格子预测某物体的边界框中心点的x和y坐标;w,h分别指边界框的宽、高;confidence是置信度,表明边界框是否包含对象和对象位置的准确性,置信度的计算公式为:
confidence=P(object)*IOU (1)
其中,P(object)反映边界框是否包含物体。若边界框包含物体,P(object)值为1;反之P(object)值为0。IOU是指边界框和真实区域的交并比。并且,输入图像的一个小格子会对应一个输出的向量,即本模型输出维度为:7*7*(2*5+20)=7*7*30=1470。并且由于本实例模型的网络最后有两个全连接层,输入图片的尺寸必须缩放到448*448。
另外,对于每个小格子,只有交并比最高的边界框会被输出。这也是本实例介绍模型的一个缺陷,假如图片的某小格子中有几个密集的小物体,然而该小格子只能输出一个边界框,也就是只能检测一个物体,导致准确率低下。可以通过增加网格的数量来改善这个问题。
损失函数使用均方和误差损失函数,网络输出的1470维向量和标注图像对应的1470维图像求误差,均方和误差损失函数公式为:
其中,coordError表示坐标误差,iouError表示置信度误差,classError为类别误差。由于三者对总误差的贡献应该是不同的,因此用λ
此外,YOLOv1计算误差的时候还把w和h求平方根,因为对同样的误差值,小目标的误差对检测的影响大于大目标的误差。损失函数形式为:
其中,第一行表示中心点误差,第二行表示宽、高误差,两者都属于坐标误差;第三、四行分别表示边界框内有、无物体的置信度误差;第五行为类别误差。
实施例二:
本发明实例二提供一种基于深度学习的物流包裹自主检测方法,基于发明实例一的模型进行改进,目的是保证检测速度不降的前提下改进实例一中的定位不准确、召回率低等缺陷。主要步骤如下:
S1:加入批归一化处理:对数据做一个批归一化预处理,使模型在不必要使用其他正则化形式的前提下,显著地加快了模型的收敛速度。
S2:网络使用Darknet-53:使用Darknet-53作为Backbone替换实例一模型中的GoogLeNet,后者有24个卷积层和2个全连接层,而前者则是53个卷积层,舍弃了池化层和全连接层,改变卷积层中过滤器的步长进行图像的下采样使得模型计算量减少,提升了检测速度。
S3:使用更高分辨率的分类器:实例一模型的分类器是基于ImageNet预训练出来的,图片尺寸为224*224。但是模型输入尺寸是448*448,如果分辨率直接切换会使模型难以快速适应,所以先使用448*448的尺寸在ImageNet上将网络进行微调,使模型适应这个分辨率。
S4:引入先验框:实例一的模型用全连接层预测边界框的坐标,引入先验框机制,每个小格子设定一定数量的先验框来预测边界框坐标,取代实例一的方法。取消全连接层,并且为了提高特征地图的分辨率,减少一个池化层。输入尺寸采用416*416而不是448*448,使得最后的特征地图大小为13*13,这样的话特征地图的中心只有一个小格子,有利于预测大物体。每个小格子有5个先验框,那么总共有13*13*5=845个先验框,比实例一模型的边界框数量7*7*2=98要多得多,这样大幅提高了召回率的值。
S5:聚类提取先验框尺寸:为了使最后先验框位置精修的时候更简单,舍弃手动选定先验框的方式,通过对训练集的标注框进行k均值聚类分析,提前设定好较合适的先验框。由于先验框大小不同甚至可能差异很大,这里采用的距离度量不同于一般k均值的计算方法,而是采用以下公式:
d(box,centroid)=1-IOU(box,centroid) (4)
其中,centroid表示聚类中心的先验框,其数量k由人为设定;box表示标注框。一开始给定的centroid只有w和h,没有x和y,计算时每个box的中心都与centroid重合,结合距离公式计算出每个box与每个centroid的“距离”,将box分配给“距离”最近的centroid,更新centroid为簇里面所有box的均值。按上述步骤反复调整centroid,最终得到合适的先验框尺寸。此外,对先验框的位置进行约束、使用穿越层检测细粒度特征等改进,均值平均准确率有很大提高。
S6:引入多尺度训练:无全连接层,使得输入的图片尺寸可以不同。为了使得模型更具鲁棒性,引入多尺度训练,使模型在面对不同的分辨率时,依然有良好的预测效果。设置多尺度特征图进行检测,是穿越层的升级版,对检测小目标有很大作用。如果直接按照Darknet-53输出特征图的话,那么特征图相对于输入图像有多达32倍的下采样,这样会使特征图的感受野偏大,不利于检测小物体。为此,使用上采样来缩小特征图下采样的倍数。以图2为例,图像的输入尺寸为416*416,再结合YOLOv3的网络结构,可以判断出图2中第一个concat处拼接的张量尺寸均为26*26,即16倍下采样,最后得到的特征图为16倍下采样,可以检测中等大小的物体。同理,图2的第三行对应的就是52*52的张量拼接,得到的特征图为8倍下采样,感受野已经很小了,可以检测小尺寸的物体。
S7:聚类生成合适大小的先验框:使用K均值聚类生成先验框尺寸的方法和原理,在自制的包裹数据集上得到合适大小的先验框。这里的聚类方法采用的距离并不是标准的欧几里得距离,因为它会受先验框框的大小影响,小尺寸的先验框框产生的误差更小。
S8:改进模型损失函数:坐标和置信度的损失沿用了均方和误差损失函数,分类损失则改成了焦点损失函数。焦点损失函数是对交叉熵损失函数的一种改进,旨在解决上述类别不平衡问题。交叉熵损失函数的表达式可简化为:
CE(p
其中p
焦点损失函数的思想就是,降低易负样本对误差的影响,那么易样本、负样本的误差都应赋予一个衰减。对正负样本的控制通过在前面添加一个系数来权衡,交叉熵损失函数公式为:
CE(p
其中,a的范围也是0到1。
本次实验负样本占多数,即y=0的样本更多,所以的值应大于0.5且小于1,本文设置的值为0.75,此时性能最优。
对难易样本的控制则是通过添加调制系数(1-p
FL(p
当样本分错时,不论样本是正还是负,p
把对正负样本的权衡与难易样本的权衡合并起来,就得到了焦点损失函数,公式为:
FL(p
这既解决了正负不平衡,又解决了难易不平衡。
实施例三:
本发明实例三提供一种基于深度学习的物流包裹自主检测方法,基于发明实例二的模型进行改进,目的在于提高对于物流包裹传送过程中包裹堆积导致的包裹和包裹间存在遮挡,包裹错误分类问题的处理能力。
改进后的YOLOv3模型在遮挡条件下对目标不够敏感,从而导致误检和漏检情况的发生。引入Deep-SORT算法,将物流包裹的运动和表面特征信息结合,将基于深度特征向量最小余弦距离的表观信息和基于马式距离的运动信息进行加权融合,得到一个新的度量匹配信息,改善遮挡对于检测性能的影响。
卡尔曼滤波器利用检测方法所得的前一帧目标信息来预测对应目标的后一帧的跟踪信息。卡尔曼滤波算法主要分为预测和更新两步。
设置状态向量X为(x,y,w,h,vx,vy,vw,vh)初始化卡尔曼滤波。
其中,x,y为框的中心点横、纵坐标,w,h为框的宽度和高度,vx,vy,vw,vh分别为x,y,w,h对应的速度分量。系统状态方程和观测方程为:
X
Z
其中,X
在预测下一时刻状态时,预测方程和协方差预测方程为:
X
P
其中,X
t时刻最优状态估计值计算公式为:
X
K
其中,K
使用卡尔曼增益矩阵修正状态变量和协方差矩阵,更新t时刻的协方差:
P
改进后的YOLOv3模型和Deep-SORT算法同时使用可能存在重复标记同一目标区域的问题。在Deep-SORT算法中引入匈牙利算法,通过马氏距离和基于特征向量的最小余弦距离加权融合的量值来关联匹配检测框与跟踪框的信息,得出检测结果。
马氏距离用于评价检测框和跟踪框之间的相似度,公式为:
其中,A和B为样本向量,S为协方差矩阵。
其中,
为增强匹配准确度,使用最小余弦距离评价表征相似度距离。表征相似度距离和马氏距离加权融合得到最终匹配度量值。公式为:
其中,G
通过实施例三,增强了检测性能,但是增加了计算量,检测速度有所降低。
实施例四:
本发明实例四提供一种基于深度学习的物流包裹自主检测方法,基于发明实例三的模型进行改进,目的在于降低模型大小,加快训练速度。
模型剪枝可以减少卷积层中特征性较弱的神经元,加快训练速度。批标准化层对通道进行归一化处理,使用批标准化层的参数γ作为通道剪枝因子。
首先,基于模型进行稀疏化训练,得到稀疏化后的批标准化层的权重。在损失函数中添加γ的正则项进行稀疏训练,公式为:
其中,L(W)是模型损失函数。R
当前向传播结束之后,γ参数为:
使用随机梯度下降更新γ,公式为:
排列得到的γ值,选定临界值s,小于s的γ全部剪掉,得到剪枝后的模型。对剪枝后的模型进行通道调整,减少特征通道数量,简化模型。
图3为包裹异常位置检测系统流程图。
实施例五:
本发明的实施例五还提供一种多机器人协同分类搬运系统,适用于物流中转站传送带等需要对目标物体位置进行检测的装置,目的是实现物流包裹的高准确率检测并将包裹归位。按功能分类,可以分成以下模块:
图像数据获取模块:用于获取传送带等包裹传送装置的包裹图像信息。
图像数据处理模块:用于对得到的图像数据应用基于深度学习的方法进行物体识别等处理,得到包裹位置信息,并检查包裹是否位于正确位置范围内。
位置纠正模块:用于对位于错误位置的包裹进行位置纠正。使用机械臂对位置异常的包裹进行位置纠正。图4展示了包裹的相对位置,纠正后的包裹在传送带有序排列。图6展示了相机位置的示意图,位置纠正后的包裹的物流信息可被屋顶相机检测到。
分类处理模块:用于对位置纠正后的包裹进行分类处理。使用物流机器人将发往同一区域的包裹运送到相应区域。图4为多机器人检测搬运系统。位置纠正后的物流包裹在传送带上有序排列,传送带两侧为物流机器人,发往同一区域的物流机器人位于同一队列。通过位于屋顶的摄像机,对传送带上包裹的物流信息进行识别。通过无线通信,将控制信息发送到相应的物流机器人。物流机器人接收到信息后,拾取目标包裹,将目标包裹运送至目标区域。考虑到同一时刻,同一区域范围内,有多台物流机器人同时运行,物流机器人间可使用已有的多机器人协同路径规划方法,实现物流机器人个体的寻径以及物流机器人间的避障等功能。
基于本发明的方法与多机器人协同分类搬运系统的结合。首先,本文根据自制的包裹数据集,通过聚类方法生成了更合适的先验框尺寸,将均值平均准确率提升了2.7%。接着,针对模型出现的类别不平衡问题,改进了损失函数,用焦点损失函数取代了交叉熵损失函数,将均值平均准确率又提升了1%。接着,针对物流包裹传送过程中包裹堆积导致的包裹和包裹间存在遮挡,包裹错误分类问题,引入Deep-SORT算法,改善遮挡对于检测性能的影响。接着,针对引入Deep-SORT算法增加计算量,降低模型速度的问题,使用剪枝的方法,简化模型,提高模型效率。
对于本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及变形,而所有的这些改变以及变形都应该属于本发明权利要求的保护范围之内。