一种基于PSO-CSA的煤与瓦斯突出风险识别方法
文献发布时间:2023-06-19 18:46:07
技术领域
本发明涉及智慧煤矿瓦斯序列预测领域,具体为一种基于PSO-CSA的煤与瓦斯突出风险识别方法。
背景技术
我国是煤炭能源消耗大国,并且浅部煤炭资源消耗严重,深部煤矿的开采在应对煤炭供给中有序推进,随着开采深度的增加,地应力及瓦斯压力越来越大,当前对地应力等煤岩力学因素对煤与瓦斯突出的影响现在还未明确,并且对煤与瓦斯突出的机理的研究目前还处于假说阶段,煤与瓦斯突出以其突发性和极高的伤害性,依旧是煤矿生产面临首要威胁因素,以及煤矿安全研究人员亟需解决的灾害问题。
在煤与瓦斯突出防治过程中,监测与预测是最重要的环节,及时的感知、及时的识别预测,才能及时的采取预防措施,将煤与瓦斯突出消灭在萌发阶段,克隆选择算法(CSA)以其只关注抗体和抗原的亲和度对B淋巴细胞分化的影响,不受抗体间亲和度的影响,算法只针对受刺激最强的个体的选择和克隆,以及自主学习、识别和记忆的优点,符合煤与瓦斯突出危险性异常检测和识别的需求,但其也存在震荡、收敛不足,易陷入局部最优等问题。粒子群优化算法(PSO)具有收敛速度快,无需反复编码和解码的优点,来对CSA的变异过程优化,改善CSA克隆变异过程存在的不足。从而建立一种基于PSO-CSA的煤与瓦斯突出风险识别方法,来对煤与瓦斯突出风险进行识别。
发明内容
本发明的目的在于提供一种基于PSO-CSA的煤与瓦斯突出风险识别方法,针对CSA的变异收敛方向不确定,计算速度慢等不足,实现煤与瓦斯突出风险识别问题的全局寻优,进一步提高计算效率和准确度,为解决煤与瓦斯突出的风险识别提供了新的思路和方法。
本发明的目的可以通过以下技术方案实现:一种基于PSO-CSA的煤与瓦斯突出风险识别方法,所述该基于PSO-CSA的煤与瓦斯突出风险识别方法的具体步骤如下:
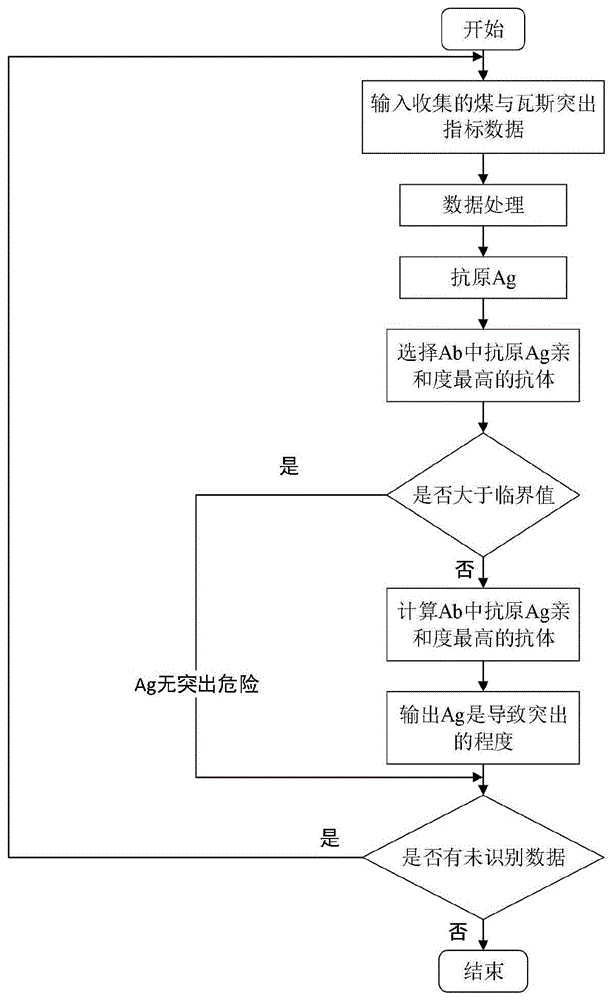
步骤1:采集煤矿井下局部煤与瓦斯突出的指标数据,包括钻屑量S、钻屑瓦斯解吸K
步骤2:使用粒子群优化算法对克隆选择算法进行优化,建立基于PSO-CSA煤与瓦斯突出风险识别模型;
步骤3:在步骤1基础上,将训练集输入到PSO-CSA中,对算法进行训练,刺激算法产生抗体,匹配亲和度高的抗体作为记忆细胞,并对记忆细胞集合更新;
步骤4:将识别集数据输入算法中,计算抗体中与抗原亲和度最高的抗体,判断是否大于临界值λ,输出所输入抗原导致突出的程度的识别结果;
步骤5:若有未识别数据,重新进行步骤4,输出煤与瓦斯突出危险性识别结果。
进一步的,所述步骤1的具体步骤为:
步骤1.1:采取煤的瓦斯放散初速度Δp,钻屑量S、钻屑瓦斯解吸K
步骤1.2:对收集到的瓦斯放散初速度Δp,钻屑量S、钻屑瓦斯解吸K
依据归一化原则,模型对现场的突出危险性识别则按照如下规则进行:
当识别结果小于0.35时,则视为无突出危险性;当识别结果在[0.35,0.8]之间时,则输出突出危险性一般的结果;当识别结果大于0.8时,则判定具有严重的突出危险性。
步骤1.3:将均一化处理后数据,分为训练集和识别集。
进一步的,所述步骤2的具体步骤为:
步骤2.1、CSA的具体步骤为:
在算法的预测空间内,表示抗体和抗原基因型的字符串长度为L,S表示免疫空间的合适坐标轴,首先定义CSA中所需变量:
·Ag:抗原;
·Ab:可用抗体表(Ab∈S
·Ab
·Ab
·Ag
·f
·Ab
·C
·C
·Ab
·Ab
CSA算法的具体步骤如下:
步骤2.1.1:随机选择一个抗原Ag
步骤2.1.2:计算Ab中N个抗体的亲和度向量f
步骤2.1.3:选择Ab中和抗原Ag
步骤2.1.4:Ab
步骤2.1.5:集合C
步骤2.1.6:计算成熟克隆集合C
步骤2.1.7:重新选择集合C
(1)设定n=N,即Ab中所有抗体在步骤2.1.3中都被选择克隆;
(2)确定Ab
式中N
步骤2.1.8:C
当所有的M个抗原均执行过一次上述步骤2.1.1到步骤2.1.8的过程后,则算法执行了一代,在步骤2.1.3后,n个亲和度最高的抗体将依据亲和度从高到低排序,通过下列计算式计算出它们具体的克隆体数量:
步骤2.2:由于CSA对数据集中数据的识别和输出以及计算都采用二进制的算法,所以算法在每次对抗原与抗体的亲和度计算时均需重新解码,则计算量随之增加,计算时间随之增多;同时,算法的变异实现是通过随机改变原有克隆抗体的特征向量,增加抗体多样性的作用,产生破坏亲和度高抗体的副作用,且随变异过程增加计算量,在原有克隆选择算法基础上,其自身进行优化,具体步骤为:
对算法的收敛优化,使算法对高概率的变异自适应,即随着迭代次数的增加,算法中的β随之减少,其递减公式为:
式中:i表示排列中抗体的排次,k表示迭代次数,且参数μ满足0<μ<1;
同时,对克隆的新抗体的亲和度进行计算,限制抗体克隆更新,新产生的抗体替换掉原有的低亲和度的抗体,使算法在克隆过程中向上收敛,新产生的抗体的亲和度要在目前种群的亲和度平均值以上;若低于平均值则对克隆的抗体舍弃,随机生成新的抗体;
当生成的抗体符合式(16)的抗体,则进行保存,若连续循环生成的抗体都不符合要求,或者迭代次数超过设定阈值,则停止克隆,使用原有亲和度抗体;
为防止算法在运行过程中出现“早熟”突变,使用y指数来进行检测,并设置值λ=1作为临界值,当y≤λ,判断算法进入“早熟”状态,暂停使用β赋值的抗体的克隆,同时使用将变异概率突然放大为原先概率k倍的方法,引入新的群体来增加算法跳出局部最优,并且收敛;当y重新回至y>λ时,则算法继续按照β赋值进行。
式中:f
步骤2.3、PSO对CSA进行优化,具体步骤为:
在优化过程中,将每一个亲和度高的抗体集合C
v
Ab
其中,
进一步的,所述步骤4的具体步骤为:
设置算法的无突出危险性和有突出危险性的阈值,迭代次数,以及记忆细胞的替换阈值,从无突出开始,若集合Ab
识别成功率计算如下:
其中,T
本发明的有益效果:
本发明通过对CSA针对煤与瓦斯突出识别的需求进行改进,加快其收敛速度,提高其全局搜索能力,消除其运行后期震荡,提高识别的成功率,进而有效的识别突出异常,PSO具有收敛速度快,无需反复编码和解码的优点,来对CSA的变异过程优化,改善CSA克隆变异过程存在的不足,从而在两者结合的基础上,建立一种基于PSO-CSA的煤与瓦斯突出危险性识别的方法,将PSO引入到CSA的变异过程,使得变异不再依赖于大量计算的二进制编码和解码,又能够达到变异过程产生的抗体表现出高亲和度的目的。
附图说明
下面结合附图对本发明作进一步的说明。
图1CSA流程;
图2PSO-CSA模型训练流程;
图3基于PSO-CSA的煤与瓦斯突出风险识别方法应用流程;
图4克隆率u与识别率关系;
图5迭代次数d与识别率关系;
图6记忆细胞替换阈值e与识别率关系;
图7有无突出危险性阈值Φ与识别率关系。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1所示,本发明为一种基于PSO-CSA的煤与瓦斯突出风险识别方法,所述该基于PSO-CSA的煤与瓦斯突出风险识别方法的具体步骤如下:
步骤1:采集煤矿井下局部煤与瓦斯突出的指标数据,包括钻屑量S、钻屑瓦斯解吸K
步骤1.1:采取煤的瓦斯放散初速度Δp,钻屑量S、钻屑瓦斯解吸K
步骤1.2:对收集到的瓦斯放散初速度Δp,钻屑量S、钻屑瓦斯解吸K
依据归一化原则,模型对现场的突出危险性识别则按照如下规则进行:
当识别结果小于0.35时,则视为无突出危险性;当识别结果在[0.35,0.8]之间时,则输出突出危险性一般的结果;当识别结果大于0.8时,则判定具有严重的突出危险性。
步骤1.3:将均一化处理后数据,分为训练集和识别集;
具体参照例中验证所需数据来自选定煤矿3
表1 3
对表1中收集到的原始数据进行均一化处理,得到表2中的隶属度值,其区间均处于[0,1]之间,按照均一化处理标准,对于没有突出危险性的数据用0.1表示;具有一般的突出危险性的用0.6来表示;突出危险性较为严重或者表现出明显突出危险性,所收集的数据超过临界值的则用1来表示,而针对这一归一化原则,模型对现场的突出危险性识别则按照如下规则进行:对于识别结果小于0.35的情况,视为无突出危险性;识别结果在[0.35,0.8]之间的情况,输出突出危险性一般的结果;而结果大于0.8的情况则认为具有严重的突出危险性;
表2 3
依据对此煤矿的不同指标数据的计算分析,同时对所使用的三个指标采用不同的权重,和识别关联度,以提高对于突出危险性识别的成功率;
步骤2:使用粒子群优化算法对克隆选择算法进行优化,建立基于PSO-CSA煤与瓦斯突出风险识别模型,具体步骤为:
步骤2.1、CSA的具体步骤为:
在算法的预测空间内,表示抗体和抗原基因型的字符串长度为L,S表示免疫空间的合适坐标轴,首先定义CSA中所需变量:
·Ag:抗原;
·Ab:可用抗体表(Ab∈S
·Ab
·Ab
·Ag
·f
·Ab
·C
·C
·Ab
·Ab
CSA算法的具体步骤如下:
步骤2.1.1:随机选择一个抗原Ag
步骤2.1.2:计算Ab中N个抗体的亲和度向量f
步骤2.1.3:选择Ab中和抗原Ag
步骤2.1.4:Ab
步骤2.1.5:集合C
步骤2.1.6:计算成熟克隆集合C
步骤2.1.7:重新选择集合C
(1)设定n=N,即Ab中所有抗体在步骤2.1.3中都被选择克隆;
(2)确定Ab
式中N
步骤2.1.8:C
当所有的M个抗原均执行过一次上述步骤2.1.1至步骤2.1.8的过程后,则算法执行了一代,在步骤2.1.3后,n个亲和度最高的抗体将依据亲和度从高到低排序,通过下列计算式计算出它们具体的克隆体数量:
步骤2.2:由于CSA对数据集中数据的识别和输出以及计算都采用二进制的算法,所以算法在每次对抗原与抗体的亲和度计算时均需重新解码,则计算量随之增加,计算时间随之增多;同时,算法的变异实现是通过随机改变原有克隆抗体的特征向量,增加抗体多样性的作用,产生破坏亲和度高抗体的副作用,且随变异过程增加计算量,在原有克隆选择算法基础上,其自身进行优化,具体步骤为:
对算法的收敛优化,使算法对高概率的变异自适应,即随着迭代次数的增加,算法中的β随之减少,其递减公式为:
式中:i表示排列中抗体的排次,k表示迭代次数,且参数μ满足0<μ<1;
同时,对克隆的新抗体的亲和度进行计算,限制抗体克隆更新,新产生的抗体替换掉原有的低亲和度的抗体,使算法在克隆过程中向上收敛,新产生的抗体的亲和度要在目前种群的亲和度平均值以上;若低于平均值则对克隆的抗体舍弃,随机生成新的抗体;
当生成的抗体符合式(27)的抗体,则进行保存,若连续循环生成的抗体都不符合要求,或者迭代次数超过设定阈值,则停止克隆,使用原有亲和度抗体;
为防止算法在运行过程中出现“早熟”突变,使用y指数来进行检测,并设置值λ=1作为临界值,当y≤λ,判断算法进入“早熟”状态,暂停使用β赋值的抗体的克隆,同时使用将变异概率突然放大为原先概率k倍的方法,引入新的群体来增加算法跳出局部最优,并且收敛;当y重新回至y>λ时,则算法继续按照β赋值进行。
式中:f
步骤2.3、PSO对CSA进行优化,具体步骤为:
在优化过程中,将每一个亲和度高的抗体集合C
v
Ab
其中,
步骤3:在步骤1基础上,将训练集输入到PSO-CSA中,对算法进行训练,刺激算法产生抗体,匹配亲和度高的抗体作为记忆细胞,并对记忆细胞集合更新;
步骤4:将识别集数据输入算法中,计算抗体中与抗原亲和度最高的抗体,判断是否大于临界值λ,输出所输入抗原导致突出的程度的识别结果,具体步骤为:
设置算法的无突出危险性和有突出危险性的阈值,迭代次数,以及记忆细胞的替换阈值,从无突出开始,若集合Ab
表3各指标关联权重
该实例中,分别使用CSA和PSO-CSA方法对煤与瓦斯突出危险性的指标数据进行识别,并且比较两种算法的识别结果,分析优化前后PSO对CSA算法识别结果的提高效果。
对所选数据进行归一化处理,并且将前300的数据作为训练集对模型训练,随后使用后100个数据作为识别集,使用CSA进行识别,识别出其中超出突出指标临界值的数据,作为有导致突出的异常数据处理。设置算法的无突出危险性的识别阈值分为0.35和0.80,迭代次数d为100,记忆细胞替换阈值e为0.99,对不同的克隆率、迭代次数,以及不同阈值记忆细胞替换条件下的异常数据识别成功率计算,结果如图4-图7方格点线图所示;
在同样的数据及设置条件下,使用PSO对CSA算法优化,结果如图5-图7圆点线所示,其中识别成功率计算如下:
其中,T
为了对比优化前后PSO对CSA算法识别结果的提高效果,分别使用克隆率u、迭代次数d、记忆细胞替换阈值e、有无突出危险性阈值Φ与识别率的关系,如图4-图7所示,PSO对CSA的优化效果显著,识别准确率明显高于优化前;
步骤5:若有未识别数据,重新进行步骤4,输出煤与瓦斯突出危险性识别结果。
以上内容仅仅是对本发明结构所作的举例和说明,所属本技术领域的技术人员对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离发明的结构或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。