一种基于拓展偏置张量隐特征分解的视频修复方法和装置
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及视频数据处理技术领域,特别涉及一种基于拓展偏置张量隐特征分解的视频修复方法和装置。
背景技术
随着机器视觉技术的不断发展,视频采集已经成为工业领域实现自动化生产的流行技术。在这种情况下,基于机器视觉技术采集到的视频数据能够代替人眼进行测量和判断,对工业中的各种应用场景提供辅助决策或自行决策。视频分析和视频管理功能可以为工业生产自动化提供有效的指导。端到端的视频数据是许多视频分析和视频管理的基本输入。此外,根据视频数据信息还能发现工业生产环节存在的异常和漏洞。由于复杂的工业环境导致采集到的视频存在遮挡或噪声,使得视频质量缺失以及不稳定。因此,如何对视频数据进行有效的修复是一个关键问题。
目前,许多研究人员提出了基于隐特征分解的模型修复未知的视频数据,其使用已知的历史视频数据修复未知的视频数据。然而,基于隐特征分解的视频数据修复方法将历史视频数据构造成静态的多维矩阵再进行未知视频数据的修复,但是视频是随时间变化所产生的一系列图像,基于隐特征分解的修复方法无法有效体现视频数据的时序性,因此造成修复精度低的问题。此外,由于视频数据在采集过程中随时间波动,导致视频数据不稳定。
发明内容
针对现有技术中视频数据修复精度较低的问题,本发明提出一种基于拓展偏置张量隐特征分解的视频修复方法和装置。
为了实现上述目的,本发明提供以下技术方案:
一种基于拓展偏置张量隐特征分解的视频修复方法,包括以下步骤:
S1:从服务器获取视频数据并进行存储;
S2:根据视频数据构造视频张量;
S3:根据视频数据构造视频数据拓展线性偏差矩阵;
S4:根据视频张量和视频数据拓展线性偏差矩阵构建视频数据修复预测模型的目标函数,并进行优化迭代;
S5:根据S4优化迭代得到的拓展线性偏差矩阵A、B和隐特征矩阵U、V、W,计算视频数据修复值。
优选地,所述S1中,视频数据以四元组的形式进行存储,四元组表示形式为T=(u,v,t,w),其中u表示视频中单帧图像的长,v表示视频中单帧图像的宽,t表示视频中产生单帧图像的长u和单帧图像的宽v的时间段,w表示视频中单帧图像的长u和单帧图像的宽v在时间段t产生的像素值。
优选地,所述S2中,视频张量的构造方法为:
将所有的四元组P=(u,v,t,w)按照时间段t划分成K个时间段;从中选择出t=1的四元组P
再从四元组P=(u,v,t,w)中依次选择出四元组P
最后用K个切片矩阵在三维空间中根据划分的K个时间段由小到大依次从前到后排列构造三维视频张量Z∈R
优选地,所述S3包括:
S3-1:根据视频数据创建视频中所有单帧图像的长对应的拓展线性偏差A,其中,α
S3-2:根据视频数据创建视频中所有单帧图像的宽对应的的拓展线性偏差B,b
优选地,所述S4包括:
S4-1:初始化视频数据修复预测的过程参数;
S4-2:对视频数据张量Z的已知数据集合Γ,构造目标损失函数;
S4-3:使用非负乘法更新规则对目标损失函数进行迭代优化;
S4-4:判断目标函数是否在已知数据集合Γ上收敛。
优选地,所述S4-1中,过程参数包括视频张量Z,单帧图像的长的隐特征矩阵U、单帧图像的宽的V、时间隐特征矩阵W;隐特征维数F;最大训练迭代轮数D;训练过程中迭代轮数控制变量d;收敛终止阈值τ;正则化因子η
隐特征维数F决定了隐特征矩阵U、V、W的隐特征空间维数;
隐特征矩阵U、V、W的大小由对应的视频张量Z的每个维度值和隐特征维数F确定,即U为I行F的隐特征矩阵、V为J行F列的隐特征矩阵、W为K行F列的隐特征矩阵;
最大训练迭代轮数D是控制迭代过程上限的变量;
迭代轮数控制变量d初始化为0;
收敛终止阈值τ是判断迭代过程是否已收敛的参数;
正则化因子η
优选地,所述S4-2中,目标损失函数ε为:
公式(1)中,A表示视频中单帧图像的长对应的拓展线性偏差矩阵;B表示视频中单帧图像的宽对应的拓展线性偏差矩阵;z
优选地,所述S4-3中,训练迭代的公式如下所示:
公式(2)中,z
优选地,所述S5中,视频数据修复值的计算公式为:
公式(3)中,
本发明还提供一种基于拓展偏置张量隐特征分解的视频修复装置,包括数据接收模块、数据存储模块、张量构造模块、拓展线性偏差矩阵构造模块和预测模块;
数据接收模块,用于从服务器采集视频数据;
数据存储模块,用于存储采集的视频数据和预测模块输出的视频数据修复值;
张量构造模块,用于根据视频数据构造视频张量;
拓展线性偏差矩阵构造模块,用于根据视频数据构造拓展线性偏差矩阵;
预测模块,用于根据视频张量、拓展线性偏差矩阵构建视频数据修复预测模型的目标函数并进行迭代优化,输出视频数据修复值。
综上所述,由于采用了上述技术方案,与现有技术相比,本发明至少具有以下有益效果:
本发明提供了一种基于拓展偏置张量隐特征分解的视频修复方法和装置,其专门作用于视频数据,并结合视频张量、拓展线性偏差矩阵构建视频数据修复预测模型,提高预测的稳定性和精度,能够进行符合统计规律的、准确度高的视频数据修复,以解决针对包含时序信息和动态性的视频数据修复问题。可广泛应用在机器视觉的视频修复、视频分析处理等领域。
附图说明:
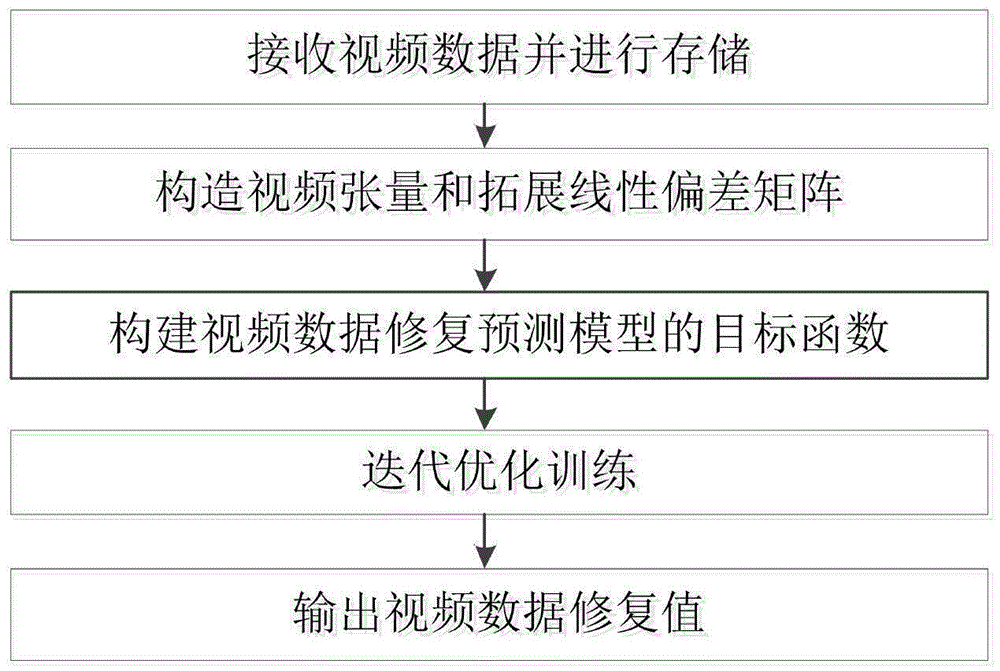
图1为根据本发明示例性实施例的一种基于拓展偏置张量隐特征分解的视频修复方法流程示意图。
图2为根据本发明示例性实施例的一种基于拓展偏置张量隐特征分解的视频修复装置示意图。
图3为根据本发明示例性实施例的数据存储模块示意图。
图4为根据本发明示例性实施例的预测模块示意图。
具体实施方式
下面结合实施例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
如图1所示,本发明提供一种基于拓展偏置张量隐特征分解的视频修复方法,具体包括以下步骤:
S1:从服务器获取视频数据并进行存储。
本实施例中,从服务器接收视频数据,接收的方式可以是:定期、或根据所述装置的通知、或根据某服务器的通知。
本实施例中,视频数据以四元组的形式进行存储,四元组表示形式为T=(u,v,t,w),其中u表示视频中单帧图像的长,v表示视频中单帧图像的宽,t表示视频中产生单帧图像的长u和单帧图像的宽v的时间段,w表示视频中单帧图像的长u和单帧图像的宽v在时间段t产生的像素值。
S2:根据视频数据构造视频张量。
将所有的四元组P=(u,v,t,w)按照时间段t划分成K个时间段;从中选择出t=1的四元组P
再从四元组P=(u,v,t,w)中依次选择出四元组P
最后用K个切片矩阵在三维空间中根据划分的K个时间段由小到大依次从前到后排列构造三维视频张量Z∈R
由于视频采集的过程中存在噪声,使得采集到的视频数据不完整,并且视频数据均为正值,因此构造的视频张量Z是一个非负稀疏张量,用已知数据集合Γ表示视频张量Z所有数据组成的集合,包括视频中单帧图像的长u、视频中单帧图像的宽v、时间段t、像素值w、视频中图像的总长度I、频中图像的总宽度J、时间段集合K等。
S3:根据视频数据创建初始的视频数据拓展线性偏差矩阵。
S3-1:根据视频数据创建视频中所有单帧图像的长对应的拓展线性偏差A,其中,α
S3-2:根据视频数据创建视频中所有单帧图像的宽对应的的拓展线性偏差B,b
本实施例中,拓展线性偏差A和B的加入能够有效增强修复模型的稳定性和表示能力。
S4:根据视频张量和视频数据拓展线性偏差矩阵构建视频数据修复预测模型的目标函数,并进行优化迭代。
S4-1:初始化视频数据修复预测的过程参数。
过程参数包括视频张量Z,单帧图像的长的隐特征矩阵U、单帧图像的宽的V、时间隐特征矩阵W;隐特征维数F;最大训练迭代轮数D;训练过程中迭代轮数控制变量d;收敛终止阈值τ;初始化正则化因子η
其中:
隐特征维数F决定了隐特征矩阵U、V、W的隐特征空间维数,初始化为正整数,例如2;
隐特征矩阵U、V、W的大小由对应的视频张量Z的每个维度值和隐特征维数F确定,即U为I行F的隐特征矩阵、V为J行F列的隐特征矩阵、W为K行F列的隐特征矩阵,对于三个隐特征矩阵分别用较小的随机正数(例如0.05)进行初始化;
最大训练迭代轮数D是控制迭代过程上限的变量,初始化为较大的正整数,例如100;
迭代轮数控制变量d初始化为0;
收敛终止阈值τ是判断迭代过程是否已收敛的参数,用极小的正数初始化,例如10
正则化因子η
S4-2:对视频数据张量Z的已知数据集合Γ,构造目标损失函数ε,以训练获取历史视频数据的隐特征矩阵U、V、W的值和两个拓展线性偏差矩阵A、B的实际拓展线性偏差值;
本实施例中,目标损失函数ε为:
公式(1)中,A表示视频中单帧图像的长对应的拓展线性偏差矩阵;B表示视频中单帧图像的宽对应的拓展线性偏差矩阵;z
并利用欧式距离度量上述的优化目标;使用Tikhonov正则化,对优化过程进行约束,防止优化过程中出现过拟合的问题。
S4-3:使用非负乘法更新规则对目标损失函数ε进行迭代优化,从而保证更新过程中的非负性。为了使目标损失函数ε的值最小,训练迭代的公式如下所示:
公式(2)中,z
S4-4:判断目标函数是否在已知数据集合Γ上收敛。
本实施例中,判断目标函数已收敛的条件为:
目标函数每迭代一轮,训练迭代轮数控制变量d的值加1,当d的值达到最大训练迭代轮数D时,停止训练;
或者本轮迭代结束后计算得到的目标损失函数的值与上一轮目标损失函数的值的差的绝对值小于收敛终止阈值τ,停止训练。
S5:根据S4优化迭代得到的拓展线性偏差矩阵A、B和隐特征矩阵U、V、W,计算精度最高的单帧图像的长和单帧图像的宽在时间段产生的视频数据修复值
公式(3)中,
基于上述方法,如图2所示,本发明还提供种基于拓展偏置张量分解的视频数据修复装置,包括数据接收模块、数据存储模块、张量构造模块、拓展线性偏差矩阵构造模块和预测模块。
数据接收模块的输出端与数据存储模块的第一输入端连接,数据存储模块的输出端分别与张量构造模块、拓展线性偏差矩阵构造模块的输入端连接,数据存储模块、拓展线性偏差矩阵构造模块的输出端分别与预测模块的输入端连接,预测模块的输出端与数据存储模块的第二输入端连接。
数据接收模块,用于从服务器采集视频数据;
数据存储模块,用于存储采集的视频数据和预测模块输出的视频数据修复值;
张量构造模块,用于根据视频数据构造视频张量;
拓展线性偏差矩阵构造模块,用于根据视频数据构造拓展线性偏差矩阵;
预测模块,用于根据视频张量、拓展线性偏差矩阵构建视频数据修复预测模型的目标函数并进行迭代优化,输出视频数据修复值。
本实施例中,如图3所示,数据存储模块包括第一存储单元和第二存储单元。
第一存储单元,用于将视频数据以四元组的形式进行存储,四元组表示形式为T=(u,v,t,w),其中u表示视频中单帧图像的长,v表示视频中单帧图像的宽,t表示视频中产生单帧图像的长u和单帧图像的宽v的时间段,w表示视频中单帧图像的长u和单帧图像的宽v在时间段t产生的像素值。
第二存储单元,用于存储预测模块输出的视频数据修复值,同时视频数据修复值也以四元组的形式进行存储。
本实施例中,如图4所示,预测模块包括初始化单元、训练单元和计算单元;
初始化单元,用于初始化视频数据修复预测过程中所涉及的过程参数;
训练单元,用于结合视频张量、拓展线性偏差矩阵构建视频数据修复预测模型的目标函数并进行迭代训练;
计算单元,用于根据目标函数的迭代参数计算视频数据修复值。
本领域的普通技术人员可以理解,上述各实施方式是实现本发明的具体实施例,而在实际应用中,可以在形式上和细节上对其作各种改变,而不偏离本发明的精神和范围。