一种基于引导表示的雷达一维距离像自维持增量识别方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于目标识别技术领域,具体涉及一种基于引导表示的雷达一维距离像自维持增量识别方法。
背景技术
雷达一维距离像(HRRP)是雷达通过发射窄脉冲或宽带信号(如线性调频信号和步进频率信号等),目标回波信号沿距离方向上占据多个距离单元的散射特征分布。因其具有实时性强、运算量小、容易获取与存储等优点而受到了广泛的研究,是现代战争环境目标识别的一种主要方法。目前,深度学习方法在HRRP分类识别中都取得不错的效果,但并没有考虑未来阶段数据的增长学习。当新目标出现时,模型识别旧目标的参数被掩盖,不能识别出旧目标,即灾难性遗忘。常见方法通过回放少量旧目标样本与新目标一起训练,但少量的旧目标样本只能获得少量的信息,遗忘仍然存在。在此背景下,本发明针对雷达一维像目标的识别问题,展开新目标的增量识别研究,力求在识别新目标的同时不遗忘旧目标,实现雷达自动目标识别。
发明内容
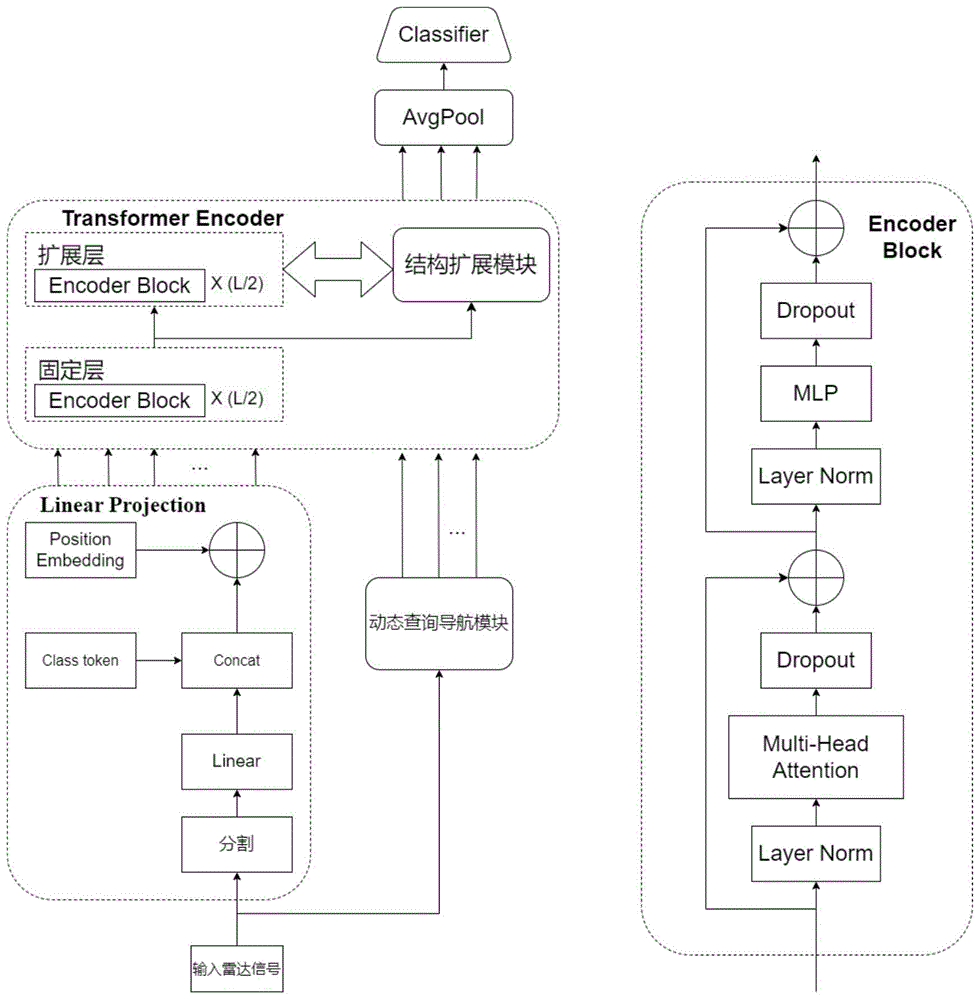
本发明以雷达一维距离像目标识别为背景,针对现有基于回放的增量识别方法无法解决遗忘问题,提出了一种自维持的引导表示方法。该方法在不同的学习阶段,通过扩展输入维度和模型结构防止遗忘。具体来说,以vision transformer中的token形式保留目标类别特定信息,再使用保留的任务信息扩展输入辅助模型识别。此外,使用旧类信息扩展模型结构,使模型在新旧信息的共同指导下学习,保留对旧类目标的记忆。
本发明的模型采用vision transformer(ViT)作为基础框架。当前任务的新类别样本Dt和所有旧类别的少量抽样样本构成当前任务的训练数据集。当前任务的训练数据集经过vision transformer进行特征提取后输入分类器得到识别结果。网络的核心思想是:一方面,在transformer encoder之前构建动态查询引导,用于得到当前样本的额外信息,与patch token一起输入transformer encoder中提取特征。另一方面,在transformerencoder部分,通过结构扩展与携带旧类信息的结构整合,共同学习当前任务数据,以实现对旧类信息的保留。利用新旧类别的数据进行测试,统计平均准确率、平均遗忘率等指标。
本发明的技术方案为:
一种基于引导表示的雷达一维距离像自维持增量识别方法,包括以下步骤:
S1、构建数据集:
将学习过程划分为基础任务和增量任务两个阶段,基础任务只有一个任务T
S2、数据预处理:
对S1中的所有样本进行归一化处理,将信号强度映射到(-1,1)上,获得任务t的训练集:
其中t代表第t个任务,T代表任务的数量;N代表总类别数;B代表采样点数;K
式中y
S3、构建自维持的引导表示网络:网络基础框架是vision transformer,在这个基础上,增加动态查询导航模块扩张vision transformer编码层的输入维度;增加结构扩展模块扩张编码层中后几层的网络结构;具体的:
S31、构建预训练好的基础vision transformer网络为
线性投影模块将雷达一维距离像拆分为多个一维块,输入x∈R
在x
编码层共有L层,每一层包含:两个归一化LN、多头注意力MSA、两个dropout以及MLP块,模型的整体输出为最后一层x
z
z
S32、构建动态查询导航模块,动态查询导航模块的输入为S2中预处理后的结果X
构建导航池,池中包含两个部分:键值K和导航A,键值和导航一一对应表示为{(k
查询得到导航,输入X
/>
扩充输入,由于键值和导航一一对应,根据键值的索引找到M个navigation,表示为A
S33、构建结构扩展模块,将vision transformer的编码层划分为
构建扩展结构,设计扩展结构g与扩展层相同:
扩展模型结构,扩展层和扩展结构的输入都是固定层的输出
p
对于扩展层,每一层的输入是上一层模型的输出与扩展结构输出的元素级求和:
其中,q
S4、采用基础数据集的训练样本对S3构建的网络进行训练,模型的损失函数为:
L=L
其中,λ为超参数;具体包括:
S41、L
上式中L
其含义是:S32中取出的导航对应位置的输出的平均值在分类器上的输出结果;
S42、L
上式中q(x)表示S32中计算出的x
S5、每个任务学习结束之后,为任务中的每个类别选择H个样本保留在样本数据库中;
S6、将待识别的雷达目标一维像数据与之前保留的所有样本共同输入到训练好的模型中进行分类识别。
本发明的有益效果为,本发明针对雷达一维像新目标识别中存在的灾难性遗忘问题,根据vision transformer的结构特点提出自维持的引导表示方法。一方面,使用可学习的导航,以一维块的形式保留类别特定信息,通过在训练过程中查询得到相似度最高的导航扩展编码层的输入,使得模型获得更多附加信息,提升识别准确率。另一方面,构建结构扩展模块保留所有旧类信息,在每次训练时通过元素级求和扩张模型的结构,使得模型能够在新旧类别信息的共同指导下学习。同时,为了防止模型在记忆时失去对新类别的学习能力,使用不被冻结的模型,让模型能够充分学习到新类别。
附图说明
图1网络整体结构示意图。
图2动态查询导航模块设计示意图。
图3结构扩展设计示意图。
具体实施方式
下面结合附图,详细描述本发明的技术方案:
本发明具体包括以下步骤:
S1、构建数据集:
将整个学习过程划分为基础任务和增量任务两个阶段,基础任务只有一个任务T
S2、数据预处理:
对S1中的所有样本进行归一化处理,将信号强度映射到(-1,1)上,获得任务t的训练集:
其中t代表第t个任务。训练集的样本标签集表示为:
Y
式中y
同理得到任务t的测试集
S3、构建预训练的基础vision transformer网络为
线性投影模块将雷达一维距离像拆分为多个一维块。输入x∈R
x
在x
z
编码层共有12层,每一层包含:两个归一化LN、多头注意力MSA(12个头部)、两个dropout以及MLP块,具体结构见示例图1。模型的整体输出为最后一层x
z
z
设计动态查询导航模块,见示例图2。它的输入为S2中预处理后的结果X
构建导航池。池中包含两个部分:键值K和导航A,键值和导航一一对应表示为{(k
查询得到导航。输入X
扩充输入。由于键值和导航一一对应,根据键值的索引找到5个navigation,表示为A
p
使用导航扩充输入后,每一层的维度变化表格如下:
设计结构扩展模块,见示例图3。将vision transformer的编码层划分为6层固定层
构建扩展结构。设计扩展结构g与扩展层相同:6个MSA层,每一层包含两个归一化LN、多头注意力MSA、两个dropout以及MLP块。扩展结构在每个任务训练结束后,使用内存数据库中的旧类数据更新.
扩展模型结构。扩展层和扩展结构的输入都是固定层的输出z
p
对于扩展层,每一层的输入是上一层模型的输出与扩展结构输出的元素级求和:
/>
其中,q
S4、采用基础数据集的训练样本对S3构建的网络进行训练,模型的损失函数为:
L=L
L
上式中L
其含义是:S3中取出的导航对应位置的输出的平均值在分类器上的输出结果。
L
上式中q(x)表示S3中计算出的x
S5、每个任务学习结束之后,为任务中的每个类别选择20个样本保留在样本数据库中。
S6、将待识别的雷达目标一维像数据与之前保留的所有样本共同输入到训练好的模型中进行分类识别。