一种基于深度学习和帧差法的传统数字水表读数识别方法
文献发布时间:2023-06-19 09:40:06
技术领域
本发明属于图像处理技术领域,涉及一种基于深度学习和帧差法的传统数字水表读数识别方法。
背景技术
随着水资源日益消耗严重,水表读数精确记录具有重要意义;另一方面,水表用户数量庞大,分布范围广,人工抄表的难度越来越大,已经不再适应于当前时代发展的需求,因此智能抄表系统成为水务企业目前及未来的发展重点。采用图像识别的方式记录水表读数,成为近几年的发展趋势。
水表读数识别的一般步骤主要有以下几个方面:(1)图像预处理,主要包括去噪和二值化;(2)字符区域的定位。传统的定位方法有:基于纹理特征、基于边缘梯度的窗口收缩以及支持向量机的方法。其存在背景复杂,难以准确定位的缺点;(3)水表字符分割。主要方法有聚类法、行程标记法以及投影法。这些方法在计算时,效果缓慢且分割效果容易受到背景的干扰。(4)水表字符识别。主要有模板匹配法、神经网络法以及小波识别算法。这些算法往往存在识别率不高以及占用大量内存的缺点。
可见,无论采用哪种方法,尽可能提高水表读数识别的准确率以及降低内存是研究水表读数识别的主要目的。
发明内容
发明的目的是提供一种基于深度学习和帧差法的水表读数识别方法,解决了不同类型水表数据少、无用数据冗余以及读数识别准确率低的问题。
本发明所采用的技术方案是,
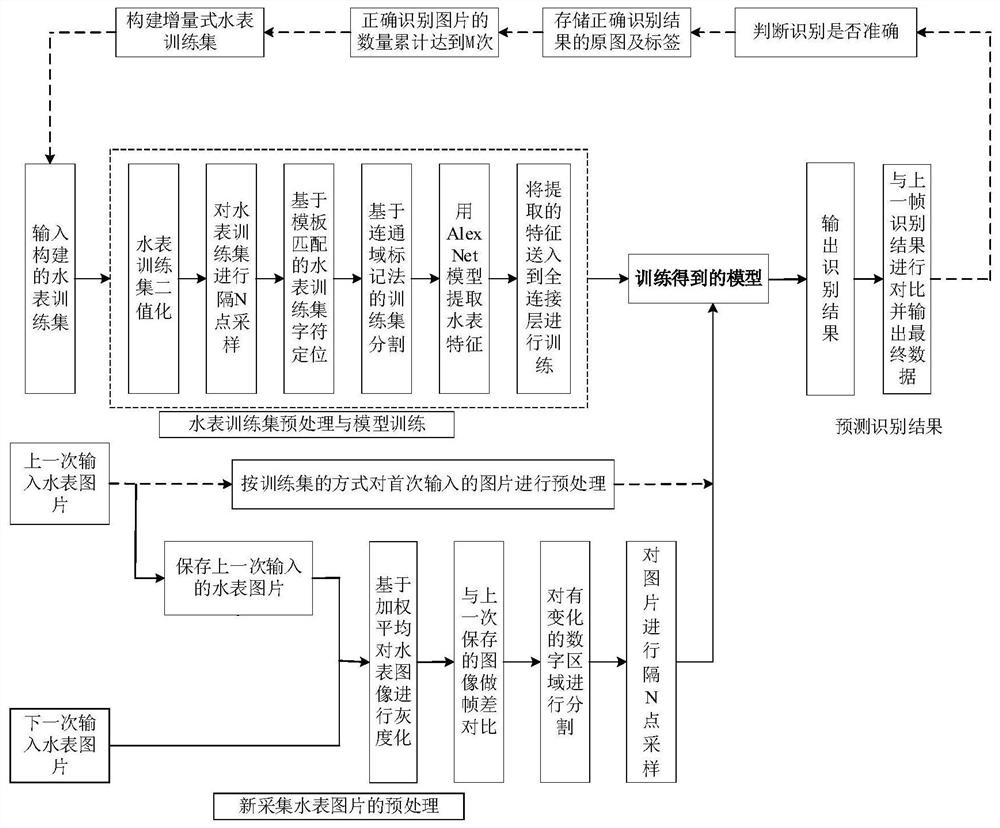
一种基于深度学习和帧差法的水表读数识别方法步骤为:
步骤1:采集大量水表图片;
步骤2:对每张水表图片进行预处理,构建水表训练集;
步骤3:对水表训练集中水表字符区域位置进行定位;
步骤4:对定位后的水表训练集进行字符分割;
步骤5:用AlexNet模型提取分割后水表训练集的水表字符特征;
步骤6:将水表字符特征送入到全连接网络进行训练,得到训练模型;
步骤7:将新采集的水表图像送入到训练模型中进行识别,得到识别结果;
步骤8:将识别结果正确的水表原图以及标签进行保存,加入到训练集中再次训练模型。
本发明的特点还在于,
其中步骤1的过程为:固定水表与摄像头的距离,距离为5cm,通过改变水表的读数,获取到大量的水表图片,对所述水表图片分类做标签作为水表训练集。
其中步骤2的过程为:
步骤2.1,对水表图片进行二值化;
步骤2.2,对二值化后的水表图片进行隔N点采样,剔除无用像素,得到水表训练集;其中设原图的大小为W*H,宽度和长度的缩小因子分别为K
其中步骤3的过程为:将字符“M”设置为搜索模板T对水表字符区域进行定位,T通过遍历整幅被搜索图S的像素点,模板覆盖被搜索图的那块区域叫子图S
其中模板T的大小为m×n个像素,搜索图S的大小为W×H个像素通过比较T和S
其中步骤4的过程为:对定位后的图像进行开运算之后采用8邻域方式连接的连通域进行标记,通过计算定位后水表图片的坐标信息,将5个连在一起的水表字符分割成单一的字符。
其中步骤5包括:
步骤5.1,在Tensorflow框架下利用Keras来搭建AlexNet模型,将输入图像的尺寸改为32*32*3以适应水表训练集,并将原始的AlexNet模型中的11*11、7*7、5*5等大尺寸卷积核均替换成3*3的小卷积核;
步骤5.2,对分割后的水表训练集做两次卷积,第一次是96个3*3的卷积核,第二次是256个3*3的卷积核,不进行全零填充,为了解决梯度消失的问题,进行批标准化操作,激活函数为Relu进行最大池化,池化核尺寸为3*3,步长为2:
f(x)是Relu取最大值的函数;为了提高模型的泛化能力,在第二次做卷积时,采用局部归一化响应:
步骤5.3,继续做两次卷积,进行全零填充,激活函数为Relu,不进行批标准化操作以及最大池化;
步骤5.4,最后一次做卷积,进行全零填充,激活函数为Relu,不进行批标准化操作,进行最大池化,池化核尺寸为3*3,步长为2,最终得到水表字符特征。
其中步骤6中全连接层共有3层:第一二层共有2048个神经元,激活函数为Relu,为了缓解过拟合的现象,对20%的神经元进行舍弃,第三全连接层共10个神经元,迭代训练次数设置为5。
其中步骤7的步骤包括:
步骤7.1,输入新采集的先后两帧水表图像,对上一帧水表图像保存后按步骤2的方式进行预处理,最后送入到训练好的模型中进行识别,得到首次识别结果;
步骤7.2,将下一帧水表图像作为当前图像,将先后两帧水表图像分别进行灰度化;
步骤7.3,对步骤7.2得到的两个灰度化图像做帧差法操作,得到差分水表图像;做完帧差操作后,将当前图像记为上一帧图片进行保存,循环更新保存的上一帧水表图片;
步骤7.4,设定阈值T,对差分图像D
步骤7.5,对二值化图像R
步骤7.6,对不同的差异性区域图像进行分割,得到多个分割后的字符图像;
步骤7.7,对多个分割后的字符图像进行隔N点采样。
步骤7.8,将步骤7.7采样后字符图像进行下标标记后,送入到模型中进行识别,得到二次识别结果,将首次识别结果与二次识别结果下标作比较,将二次识别结果下标相同的字符替换掉首次识别结果的水表读数,最终整合输出完整的水表读数。
其中步骤8的步骤包括:将模型识别正确的水表图像以及它的标签进行保存,当正确识别的水表图片数量达到50时将保存的新数据添加到原有的训练集中重新进行训练。
本发明的有益效果是:
与现有方法相比,本发明采用隔N点采样以及帧差法思想对水表图片进行预处理,减少背景无用信息干扰、降低数据冗余的同时节省了大量内存;采用模板匹配的方法通过定位“M”标志的坐标信息,能够快速的定位出水表字符区域;采用连通域标记法能够准确的分割出单一字符;通过负反馈扩充训练集的方式增强AlexNet训练模型的鲁棒性,提高水表识别的准确度。
附图说明
图1是本发明一种基于深度学习和帧差法的水表读数识别方法一种基于深度学习和帧差法的水表读数识别方法的流程图;
图2是本发明一种基于深度学习和帧差法的水表读数识别方法整个水表读数区域的隔N点采样结果图,其中(a)为整个电表区域的二值图,(b)为对(a)进行隔6点采样后的结果;
图3是本发明一种基于深度学习和帧差法的水表读数识别方法单个字符隔N点采样的结果图,其中(a)为整个字符区域的二值图,(b)为对(a)进行隔6点采样后的结果;
图4是本发明一种基于深度学习和帧差法的水表读数识别方法水表字符识别的准确率图;
图5是本发明一种基于深度学习和帧差法的水表读数识别方法水表字符识别的Loss值图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于深度学习和帧差法的水表读数识别方法,如图1,步骤包括:
步骤1:采集大量水表图片;
步骤2:对每张水表图片进行预处理,构建水表训练集;
步骤3:对水表训练集中水表字符区域位置进行定位;
步骤4:对定位后的水表训练集进行字符分割;
步骤5:用AlexNet模型提取分割后水表训练集的水表字符特征;
步骤6:将水表字符特征送入到全连接网络进行训练,得到训练模型;
步骤7:将新采集的水表图像送入到训练模型中进行识别,得到识别结果;
步骤8:将识别结果正确的水表原图以及标签进行保存,加入到训练集中再次训练模型。
本发明的特点还在于,
其中步骤1的过程为:首先测量好水表与摄像头的大致距离,经过试验,发现摄像头与水表表盘的距离为5CM时,拍摄的照片效果比较理想,因此将两者固定在具体的距离上,通过改变水表的读数,获取到大量的水表图片,对所述水表图片分类做标签作为水表训练集。
其中步骤2的过程为:
步骤2.1,对水表图片进行二值化,设原图像为f(i,j),设定阈值T
步骤2.2,对二值化后的水表图片进行隔N点采样,剔除无用像素,得到水表训练集;其中设原图的大小为W*H,宽度和长度的缩小因子分别为K
其中步骤3的过程为:将字符“M”设置为搜索模板T对水表字符区域进行定位,T通过遍历整幅被搜索图S的像素点,模板覆盖被搜索图的那块区域叫子图S
其中模板T的大小为m×n个像素,搜索图S的大小为W×H个像素通过比较T和S
其中步骤4的过程为:对定位后的图像进行开运算之后采用8邻域方式连接的连通域进行标记,通过计算定位后水表图片的坐标信息,将5个连在一起的水表字符分割成单一的字符。
其中步骤5包括:
步骤5.1,在Tensorflow框架下利用Keras来搭建AlexNet模型,将输入图像的尺寸改为32*32*3以适应水表训练集,并将原始的AlexNet模型中的11*11、7*7、5*5等大尺寸卷积核均替换成3*3的小卷积核;
步骤5.2,对分割后的水表训练集做两次卷积,第一次是96个3*3的卷积核,第二次是256个3*3的卷积核,不进行全零填充,为了解决梯度消失的问题,进行批标准化操作,激活函数为Relu进行最大池化,池化核尺寸为3*3,步长为2:
f(x)是Relu取最大值的函数;在输入是负值的情况下,它会输出0,则神经元不会被激活,这意味着同一时间只有部分神经元会被激活,使得网络很稀疏,进而提高了计算的效率;
为了提高模型的泛化能力,在第二次做卷积时,采用局部归一化响应:
步骤5.3,继续做两次卷积,进行全零填充,激活函数为Relu,不进行批标准化操作以及最大池化;
步骤5.4,最后一次做卷积,进行全零填充,激活函数为Relu,不进行批标准化操作,进行最大池化,池化核尺寸为3*3,步长为2,最终得到水表字符特征。
其中步骤6中全连接层共有3层:第一二层共有2048个神经元,激活函数为Relu,为了缓解过拟合的现象,对20%的神经元进行舍弃,第三全连接层共10个神经元,进行10分类,迭代训练次数设置为5,最终得到水表训练模型。
其中步骤7的步骤包括:
步骤7.1,输入新采集的先后两帧水表图像,对上一帧水表图像保存后按步骤2的方式进行预处理,最后送入到训练好的模型中进行识别,得到首次识别结果;
步骤7.2,将下一帧水表图像作为当前水表图像,将先后两帧水表图像分别进行灰度化,根据水表图像重要性以及它的指标,将RGB三个分量分别为R(i,j),G(i,j),B(i,j)通过不同的权值进行加权平均,G(i,j)为灰度分量;通过实验证明,当三分量参数取值为如下公式时,灰度化效果比较好:
Gray(i,j)=0.299*R(i,j)+0.578*G(i,j)+0.114B(i,j) (5)
步骤7.3,对步骤7.2得到的两个灰度化图像做帧差法操作,得到差分水表图像;差分水表图像为当前水表图像与上一帧水表图像存在差异的部分;帧差法公式为:
D
其中N帧水表图像和第N-1帧水表图像为f
做完帧差操作后,将当前图像记为上一帧图片进行保存,循环更新保存的上一帧水表图片;
步骤7.4,设定阈值T,对差分图像D
步骤7.5,对二值化图像R
步骤7.6,对不同的差异性区域图像进行分割,得到多个分割后的字符图像;
步骤7.7,对多个分割后的字符图像进行隔N点采样。
步骤7.8,将步骤7.7采样后字符图像进行下标标记后,送入到模型中进行识别,得到二次识别结果,将首次识别结果与二次识别结果下标作比较,将二次识别结果下标相同的字符替换掉首次识别结果的水表读数,最终整合输出完整的水表读数。
其中步骤8的步骤包括:将模型识别正确的水表图像以及它的标签进行保存,当正确识别的水表图片数量达到一定数量时将保存的新数据添加到原有的训练集中重新进行训练,本发明图片数量设置为50。
为此,本发明实验如下:
如图2以及图3通过对定位后的水表图像进行隔点采样,由于拍摄的图片背景颜色比较深,二值化不能完全使得字符的区域为黑色。通过试验,发现每当隔6个点进行采样的时候,能够去除一部分多余的无用信息,使得字符区域得到细化,压缩像素点的同时节省了内存容量。
图4和图5为通过AlexNet网络对水表图像进行训练后的可视化结果图。蓝色线代表模型在训练时的Loss值以及准确率,橙色线代表测试图片的Loss值以及准确率。Loss值越低,说明训练的模型效果越好;准确率越高,说明水表识别的效果比较好。通过图4可以看出,随着迭代次数的增加,训练模型的Loss值大约为0.06,准确率大约为0.98;测试结果的Loss值大约在0.075左右,而准确率可以达到0.975以上,说明水表读数识别的效果更加精准。
- 一种基于深度学习和帧差法的传统数字水表读数识别方法
- 基于深度学习的直读水表读数识别方法