基于文本相似度的信息匹配系统
文献发布时间:2023-06-19 09:44:49
技术领域
本发明涉及信息处理技术领域,尤其涉及一种基于文本相似度的信息匹配系统。
背景技术
随着大数据技术的不断发展,多个数据中存储有同一对象的不同数据信息,为了便于获取同一对象的多个数据信息,很多场景下,需要将同一对象在不同数据源中的不同数据信息关联起来。但是,由于数据量庞大,若将不同数据源中的数据直接一一对比进行匹配,匹配效率极低,且会花费大量的时间成本和人力成本。因此,如何快速准确地将同一对象在不同数据源中的不同数据信息关联起来成为亟待解决的技术问题。
发明内容
本发明目的在于,提供一种基于文本相似度的信息匹配系统,能够基于文本相似度,快速、准确地将同一对象在不同数据源中的不同数据信息匹配起来。
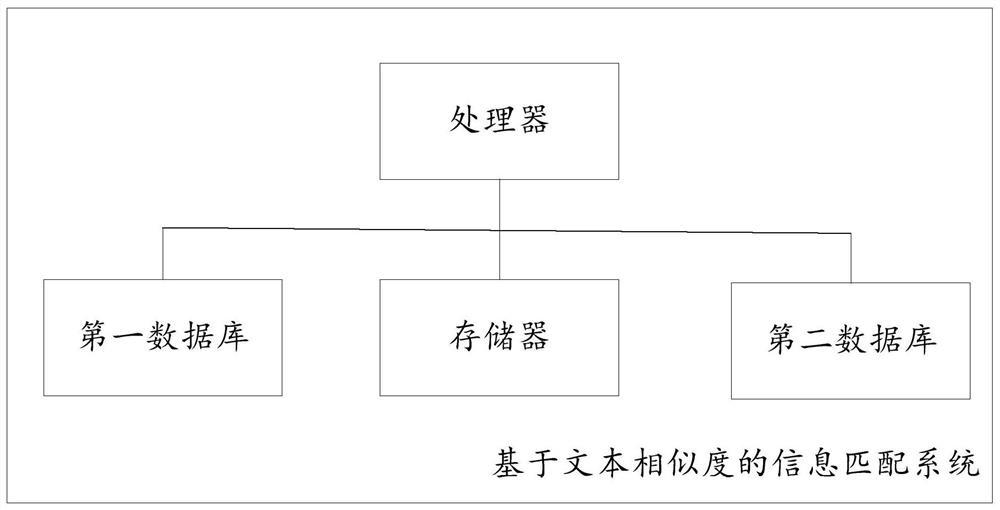
根据本发明第一方面,提供了一种基于文本相似度的信息匹配系统,其特征在于,包括第一数据库和第二数据库,处理器和存储有计算机程序的存储器,所述第一数据库用于存储第一文本信息以及所述第一文本信息对应的第一地址信息,所述第二数据库用于存储第二文本信息以及所述第二文本信息对应的第二地址信息,当所述计算机程序被处理器执行时,实现以下步骤:
步骤S1、从所述第一数据库中获取第一文本信息C,以及与所述第一文本信息对应的第一地址信息D;
步骤S2、从所述第二数据库中获取以D为中心的预设距离范围内的所有的第二地址信息所对应的第二文本信息列表E=(E
步骤S3、基于所述第一文本信息C构建基准词库,并根据所述基准词库确定X类词库,X为正整数;
步骤S4、基于所述基准词库以及X类词库构建特征词库,所述特征词库中包括多个特征词文本信息,即F=(F
步骤S5、逐个获取每一所述特征词文本信息F
本发明与现有技术相比具有明显的优点和有益效果。借由上述技术方案,本发明提供的一种基于文本相似度的信息匹配系统可达到相当的技术进步性及实用性,并具有产业上的广泛利用价值,其至少具有下列优点:
本发明所述系统能够基于文本相似度,快速、准确地将同一对象在不同数据源中的不同数据信息匹配起来。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1为本发明实施例提供的基于文本相似度的信息匹配系统示意图。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种基于文本相似度的信息匹配系统的具体实施方式及其功效,详细说明如后。
本发明实施例提供了一种基于文本相似度的信息匹配系统,如图1所示,包括第一数据库和第二数据库,处理器和存储有计算机程序的存储器,所述第一数据库用于存储第一文本信息以及所述第一文本信息对应的第一地址信息,所述第二数据库用于存储第二文本信息以及所述第二文本信息对应的第二地址信息,当所述计算机程序被处理器执行时,实现以下步骤:
步骤S1、从所述第一数据库中获取第一文本信息C,以及与所述第一文本信息对应的第一地址信息D;
步骤S2、从所述第二数据库中获取以D为中心的预设距离范围内的所有的第二地址信息所对应的第二文本信息列表E=(E
步骤S3、基于所述第一文本信息C构建基准词库,并根据所述基准词库确定X类词库,X为正整数;
步骤S4、基于所述基准词库以及X类词库构建特征词库,所述特征词库中包括多个特征词文本信息,即F=(F
步骤S5、逐个获取每一所述特征词文本信息F
本发明实施例所述系统能够基于文本相似度快速、准确地将同一对象在不同数据源中的不同数据信息匹配起来。
作为一种示例,第二数据库可以为个推数据库,所述第二文本信息为wifi信息,具体可为wifimac文本信息,第一数据库可以为其他第三方数据库,所述第一文本信息可为兴趣点(Point of Interest,简称POI)信息,POI信息具体可为公司名称信息,通过本发明实施例所述系统可以将属于同一对象的公司名称信息和其对应的wifi信息对应关联起来,进而可以把第二数据库中wifi信息对应的信息以及第一数据库中POI信息对应的信息关联起来,从而将同一对象在第一数据库和第二数据库中的不同的数据信息关联起来。
作为一种示例,所述步骤S3进一步包括:
步骤S31、将所述第一文本信息C进行分词处理,得到多个分词文本,将每一所述分词文本与预设的第一词库进行匹配,若所述第一词库中包含与该分词文本相同的文本信息,则将该分词文本剔除,将剩余的分词文本基于在所述第一文本信息C中的顺序重新组成基准词存储至基准词库中,构建所述基准词库;
其中,具体可直接调用基于Python的jieba分词包来进行分词处理。
步骤S32、将所述基准词与预设的第x词库进行匹配,x=2,3,...X+1,将所述基础词中包含在所述第x词库中的文本切除,将所述基础词剩余的文本信息存储至第x-1类词库中,构建所述第x-1类词库。
需要说明的是,步骤S31中所述第一词库基于预设的通用词词典构建,步骤S32中的所述第x词库基于预设的专业词典构建。进一步的,基于预设的专业词典构建不同的第x词库,以增加基准词所构建出的第x-1类词库,从而增加了所述特征词库中所包括的特征词数量,进一步提高匹配成功的概率。
需要说明的是,基于基准词构建的X类词库并没有必然的优先级关系,设置的第x词库越多,所构建的第x-1类词库类别越多,对应的特征词库中的特征词也越多,匹配成功的概率越大,匹配准确度也越高。但具体设置第x词库的数量以及每一第x词库中设置的文本信息,可以综合匹配成本、匹配精确度需求等信息综合设定。
以下以一具体示例对本实施例步骤S31-步骤S32进行说明,第一词库中包括省份名称、市名称和区名称对应的文本信息,第二词库中包括“公司”、“有限公司”“中心”、“直营店”、“股份”,第三词库中包括第三词库中包括“有限公司”、“中心”、“股份”“科技”,第四词库中包括“有限公司”、“中心”、“股份”、“网络”,第五词库中包括“有限公司”、“中心”、“股份”“科技”、“网络”第一文本信息C为“浙江每日互动网络科技股份有限公司”,则通过步骤S31获得的基准词为“每日互动网络科技股份有限公司”,通过步骤S32,基于第二词库获取的第一类词库为{每日互动网络科技},通过第三词库获取的第二类词库为{每日互动网络},通过第四词库获取的第三类词库为{每日互动科技},通过第五词库获取的第四类词库为{每日互动}。
作为一种示例,所述步骤S4进一步包括:
步骤S41、将所述基准词以及所有第x-1类词库中的文本信息的原始文本信息分别根据预设的转译规则进行转译,得到所述基准词以及所有第x-1类词库中的文本信息对应的转译文本信息;
步骤S42、将所述基准词以及所有第x-1类词库中的文本信息对应的转译文本信息,以及所述基准词以及所有第x-1类词库中的文本信息的原始文本信息共同组成所述特征词库。
所述步骤S41中,所述预设的转译规则为:
将所述基准词以及所有第x-1类词库中的文本信息对应的原始文本信息转换为对应的汉语拼音信息,得到第一转译文本信息,以及,将所述原始文本信息中每一汉语汉字转换为该汉语汉字对应的拼音信息的首字母,得到第二转译文本信息,所述第一转译文本信息和所述第二转译文本信息共同组成所述转译文本信息。
需要说明的是,基于计算机对大量的wifi信息进行统计分析,有大量的wifi信息对应的wifimac的核心词均为以该对象的名称、名称全拼、名称首字母缩写、名称简称、名称简称全拼或名称简称缩写,且有些对象会对应多个wifimac,但也均遵循以上设定规则,因此本发明实施例通过基准词和多个第x词库去构建覆盖范围更广的特征词库,将设定上述转译规则,提高了信息关联的成功概率和准确度。
需要说明的是,wifimac文本信息中通常包括很多无用的信息,例如“TP-LINK”、“5g”等,但通过计算机对大量的wifimac文本信息进行统计可知,这样无用信息的存在具有一定的规律,例如大多以特定字符与核心信息分隔开,因此可以根据所统计的规律基于正则匹配来去除无用信息,以提高计算效率和准确率,从而提高匹配成功的概率和准确率,具体的,可在步骤S5之前这只步骤S50、采用正则匹配去除所述wifi信息中的预设的无用信息。例如wifimac文本信息为“TP-LINK_mrhd-5g”,其中mrhd为核心词,“_”,“-”为特定字符,“TP-LINK”、“5g”为无用信息,通过步骤S5可以从中提取出核心词“mrhd”。这样,在文本相似度计算过程中,只需基于核心词去计算即可,大大减少了计算量,提高了匹配效率。
作为一种示例,所述步骤S5中,获取每一所述特征词文本信息F
其中,a为F
为了避免仅依赖上式进行文本相似度计算,以及设置的相似度阈值可靠度低等,进一步提高第一文本信息与第二文本信息匹配成功的概率和匹配的准确性,在所述步骤S4执行完之后,所述步骤S5开始执行前,还包括:
步骤S30、逐个遍历所述特征词库的每一个特征词文本信息F
基于所述系统大量的匹配结果,可以对预设的相似度阈值进行动态调整,以进一步提高匹配成功的概率和准确度,具体地,步骤S5之后,还包括步骤S6、获取第一文本信息与第二文本信息匹配的召回率P和精确率Q:
其中,R为进行信息匹配的第一文本信息的总数量,S为匹配上第二文本信息的第一文本信息的数量,T为正确匹配上第二文本信息的第一文本信息的数量;
基于所述召回率P和精确率Q动态调整所述相似度阈值H
若所述召回率P大于预设的召回率上限且精确率Q大于预设的精确率上限,则将当前相似度阈值增加预设相似度步长;
若所述召回率P小于预设的召回率下限和精确率Q小于预设的精确率下限,则将当前相似度阈值减少预设相似度步长;
其他情况下保持当前相似度阈值不变。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 基于文本相似度的信息匹配系统
- 一种基于同义词典的短文本相似度匹配方法及系统