基于深度时空推理网络的人体行为识别方法及电子设备
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及行为识别技术领域,具体涉及一种基于深度时空推理网络的人体行为识别方法及电子设备。
背景技术
随着计算机视频监控技术的发展,智能监控系统广泛应用于诸如交通路口、机场、商场、停车场和商业办公大楼等公共场所。其中,人体行为识别已经成为智能监控领域中最具有挑战性的问题之一,其目标是使计算机能够根据人体信息尤其是运动信息识别出人体行为。
按照识别方法的不同,目前研究行为识别的方法可以分为两大类:传统方法与深度学习方法。传统方法主要包括基于模板匹配的方法、基于状态空间的方法与基于语义描述的方法等。传统方法需要根据特定领域和特定应用的算法以及特征工程构建识别模型,且需要复杂的特征工程来提取人的行为特征。近些年基于深度学习的人体行为识别方法受到越来越多研究者与业界的关注,但现有基于深度学习的人体行为识别方法只能对静止图片进行识别,无法对视频数据中的人体行为进行识别。
因此,现有技术还有待于改进和发展。
发明内容
针对现有技术的上述缺陷,本发明提供一种基于深度时空推理网络的人体行为识别方法及电子设备,旨在解决现有基于深度学习的人体行为识别方法只能对静止图片进行识别,无法对视频数据中的人体行为进行识别的问题。
本发明解决技术问题所采用的技术方案如下:
第一方面,本发明实施例提供一种基于深度时空推理网络的人体行为识别方法,其中,包括:
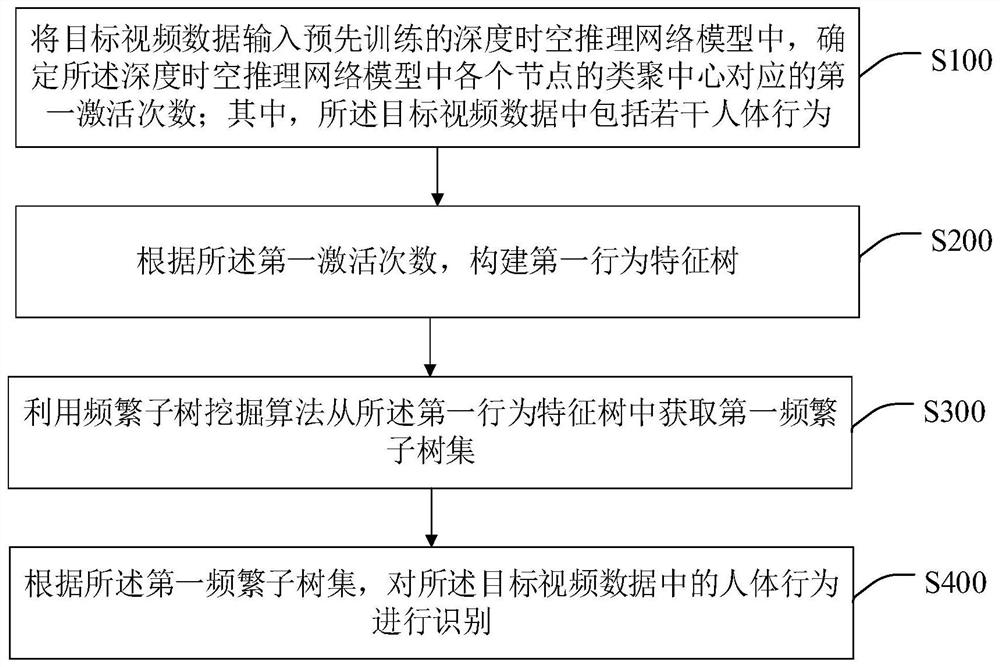
将目标视频数据输入预先训练的深度时空推理网络模型中,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数;其中,所述目标视频数据中包括若干人体行为;
根据所述第一激活次数,构建第一行为特征树;
利用频繁子树挖掘算法从所述第一行为特征树中获取第一频繁子树集;
根据所述第一频繁子树集,对所述目标视频数据中的人体行为进行识别。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述将目标视频数据输入预先训练的深度时空推理网络模型中,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数的步骤包括:
将目标视频数据输入预先训练的深度时空推理网络模型中,获取所述深度时空推理网络模型中各个节点对应的第一观测值;
根据所述第一观测值,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述根据所述第一观测值,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数的步骤包括:
根据所述各个节点对应的第一观测值和所述各个节点的类聚中心,确定所述第一观测值所属类簇;
根据所述第一观测值所属类簇,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述根据所述第一激活次数,构建第一行为特征树的步骤包括:
根据所述第一激活次数,确定所述各个节点的目标类聚中心;
根据所述目标类聚中心,构建第一行为特征树。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述利用频繁子树挖掘算法从所述第一行为特征树中获取第一频繁子树集的步骤包括:
基于最右扩展策略从所述第一行为特征树中生成若干第一候选子树,并确定所述若干第一候选子树的支持数;
根据所述若干第一候选子树的支持数和预设的支持数阈值,确定第一频繁子树集。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述根据所述第一频繁子树集,对所述目标视频数据中的人体行为进行识别的步骤包括:
根据所述第一频繁子树集,确定目标第一频繁子树;其中,所述目标第一频繁子树为所述第一频繁子树集中频繁性最高的第一频繁子树;
根据所述目标第一频繁子树和预先确定的频繁子树与人体行为的对应关系,对所述目标视频数据中的人体行为进行识别。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述将目标视频数据输入预先训练的深度时空推理网络模型中,的步骤之前包括:
利用训练视频数据集对预先构建的深度时空推理网络模型进行训练,获得预先训练的深度时空推理网络模型;其中,所述训练视频数据集中包括若干训练视频数据,所述若干训练视频数据中包括若干人体行为;
将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络,确定所述训练视频数据集中若干人体行为对应的频繁子树;
根据所述训练视频数据集中若干人体行为对应的频繁子树,确定频繁子树与人体行为的对应关系。
在一种实现方式中,所述的基于深度时空推理网络的人体行为识别方法,其中,所述将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络模型,确定所述训练视频数据集中若干人体行为对应的频繁子树的步骤包括:
将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络模型,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第二激活次数;
根据所述第二激活次数,构建第二行为特征树;
利用频繁子树挖掘算法从所述第二行为特征树中获取第二频繁子树集;
根据所述第二频繁子树集,确定所述训练视频数据集中若干人体行为对应的频繁子树。
第二方面,本发明实施例还提供一种智能终端,其中,包括:处理器、与处理器通信连接的存储介质,所述存储介质适于存储多条指令;所述处理器适于调用所述存储介质中的指令,以执行实现上述所述的基于深度时空推理网络的人体行为识别方法的步骤。
第三方面,本发明实施例还提供一种计算机可读存储介质,其上存储有多条指令,其中,所述指令适于由处理器加载并执行,以执行实现上述所述的基于深度时空推理网络的人体行为识别方法的步骤。
有益效果:本发明对目标视频数据的人体行为进行识别时,利用深度时空推理网络模型提取的人体动态行为时空特征和频繁子树反映的不同层次特征关系进行行为识别,既关注行为中人体部位的自身特征,也关注部位之间的关联与协调,从而提高网络中的特征利用率,提升了网络的识别率,实现对视频数据中人体行为快速准确识别。
附图说明
图1是本发明实施例提供的一种基于深度时空推理网络的人体行为识别方法的一个实施例的流程图;
图2是本发明实施例提供的一种深度时空推理网络的结构示意图;
图3是本发明实施例中人体行为为挥手时对应的频繁子树图;
图4是本发明实施例中人体行为为跳跃时对应的频繁子树图;
图5是本发明实施例提供的一种智能终端的内部结构原理框图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供的一种基于深度时空推理网络的人体行为识别方法,可以应用于智能终端中。其中,智能终端可以但不限于是各种个人计算机、笔记本电脑、手机、平板电脑、车载电脑和便携式可穿戴设备。本发明的终端采用多核处理器。其中,智能终端的处理器可以为中央处理器(Central Processing Unit,CPU),图形处理器(Graphics ProcessingUnit,GPU)、视频处理单元(Video Processing Unit,VPU)等中的至少一种。
为了解决现有基于深度学习的人体行为识别方法只能对静止图片进行识别,无法对视频数据中的人体行为进行识别的问题,本发明提供了一种基于深度时空推理网络的人体行为识别方法。
请参照图1,图1是本发明提供的一种基于深度时空推理网络的人体行为识别方法的一个实施例的流程图。
在本发明的一个实施例中,所述基于深度时空推理网络的人体行为识别方法有四个步骤:
S100、将目标视频数据输入预先训练的深度时空推理网络模型中,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数;其中,所述目标视频数据中包括若干人体行为。
具体地,本实施例中所述目标视频数据为需要进行人体行为识别的视频数据,所述目标视频数据中包括若干人体行为,例如挥手、跳跃等。所述目标视频数据可通过现有具有捕捉人体行为深度数据的设备,如体感器(Kinect)等进行采集。
本实施例中为了对目标视频数据中的人体行为进行识别,预先构建一个深度时空推理网络(DeSTIN网络)模型,该深度时空推理网络模型的结构如图2所示,该深度时空推理网络模型是一个多层金字塔型的深度网络模型,每层都被分为若干个2*2的区域,且第N-1层的一个2*2的区域连接着第N层的一个节点,而第N层的四个节点再与第N+1层的一个节点相连。在深度时空推理网络模型的隐含层(中间层)中,每一层的节点都包含着一定数量的类聚中心。
在对目标视频数据的人体行为进行识别之前,需要预先对深度时空推理网络模型进行训练,深度时空推理网络模型中的节点可以通过无监督学习产生与学习到本层的观测值的特征,并初始化类聚中心的更新步长,以得到预先训练的深度时空推理网络模型。
将目标视频数据输入预先训练的深度时空推理网络模型之前,需要首先对目标视频数据进行预处理,对目标视频数据中的图像大小进行归一化,例如图像大小归一化为320*320。然后将预处理后的目标视频数据输入预先训练的深度时空推理网络模型中,确定所述深度时空推理网络模型的各个节点中类聚中心对应的第一激活次数,所述深度时空推理网络模型的各个节点中类聚中心的激活次数反映了人体动态行为时空特征,本实施例中通过获取第一激活次数,能够对目标视频数据中的人体行为进行识别。
在一具体实施方式中,步骤S100包括如下步骤:
S110、将目标视频数据输入预先训练的深度时空推理网络模型中,获取所述深度时空推理网络模型中各个节点对应的第一观测值;
S120、根据所述第一观测值,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数。
对于深度时空推理网络模型的每一层(除最底层外),都会获得一组从子层传递过来的信念值作为观测值。将目标视频数据输入预先训练的深度时空推理网络模型后,在深度时空推理网络模型的最底层,目标视频数据直接作为观测值输入,深度时空推理网络模型的每一层可以看作目标视频数据在一定层次上的抽象,对于深度时空推理网络模型的每一层(除最底层外),获得一组从子层传递过来的信念值作为观测值,即获得所述深度时空推理网络模型的每一层的各个节点对应的第一观测值。
考虑到不同类簇的观测值对应的类聚中心的激活次数不同,本实施例中获取到深度时空推理网络模型的每一层的各个节点对应的第一观测值后,计算深度时空推理网络模型的每一层的各个节点对应的第一观测值到该节点中所有类聚中心的欧式距离,根据计算出的欧式距离,确定第一观测值所属的类簇(被激活的类簇),然后根据第一观测值所属的类簇,确定深度时空推理网络模型的各个节点中类聚中心的第一激活次数,即根据第一观测值所属的类簇更新第i层第j个节点第k个类簇被激活的次数N
S200、根据所述第一激活次数,构建第一行为特征树。
考虑到频繁子树能够反映人体行为不同层次特征关系,本实施例中获取到深度时空推理网络模型的各个节点中类聚中心对应的第一激活次数后,根据第一激活次数构建第一行为特征树。其中,所述第一行为特征树的高度为深度时空推理网络模型的层数,第一行为特征树的节点为深度时空推理网络模型的节点,第一行为特征树中各节点的值根据各个节点中类聚中心对应的第一激活次数确定。
在一具体实施方式中,步骤S200包括如下步骤:
S210、根据所述第一激活次数,确定所述各个节点的目标类聚中心;
S220、根据所述目标类聚中心,构建第一行为特征树。
考虑到深度时空推理网络模型的各个节点中会包含多个类聚中心,而每个类聚中心都有其对应的第一激活次数。本实施例中获取到深度时空推理网络模型的各个节点中类聚中心对应的第一激活次数后,首先根据第一激活次数,确定各个节点中最常被激活即第一激活次数最大的类聚中心作为各个节点的目标聚类中心。然后计算各个节点的目标类聚中心的第一激活频率。其中,第一激活频率=max
S300、利用频繁子树挖掘算法从所述第一行为特征树中获取第一频繁子树集。
由于频繁子树挖掘算法(TreeMiner算法)的数据结构简单,易于实现,又能唯一表示一颗树,能够提高算法的设计效果,本实施例中构建第一行为特征树后,利用频繁子树挖掘算法从所述第一行为特征树中获取第一频繁子树集,以便后续步骤中根据第一频繁子树集对目标视频数据中的人体行为进行识别。本实施例中对目标视频数据的人体行为进行识别时,利用深度时空推理网络提取的人体动态行为时空特征和频繁子树反映的不同层次特征关系进行行为识别,既关注行为中人体部位的自身特征,也关注部位之间的关联与协调,从而提高网络模型中的特征利用率,提升了网络模型的识别率,实现对视频数据中人体行为的快速准确识别。
在一具体实施方式中,步骤S300具体包括:
S310、基于最右扩展策略从所述第一行为特征树中生成若干第一候选子树,并确定所述若干第一候选子树的支持数;
S320、根据所述若干第一候选子树的支持数和预设的支持数阈值,确定第一频繁子树集。
具体地,本实施例中利用频繁子树挖掘算法获取第一频繁子树集时,首先基于最右扩展策略从所述第一行为特征树中生成若干第一候选子树,并确定所述若干第一候选子树的支持数。然后将确定的若干第一候选子树的支持数与预先设置的支持数阈值进行比较,从若干第一候选子树筛选出支持数大于预设支持数阈值的若干第一候选子树作为第一频繁子树集,以便后续步骤中根据第一频繁子树集,确定所述目标视频数据中的人体行为。
S400、根据所述第一频繁子树集,对所述目标视频数据中的人体行为进行识别。
具体地,本实施例中预先确定了频繁子树与人体行为的对应关系,当获取到目标视频数据对应的第一频繁子树集后,根据所述第一频繁子树集和预先确定的频繁子树与人体行为的对应关系,确定所述人体行为视频数据中的人体行为。
在一具体实施方式中,所述步骤S400包括如下步骤:
S410、根据所述第一频繁子树集,确定目标第一频繁子树;其中,所述目标第一频繁子树为所述第一频繁子树集中频繁性最高的第一频繁子树;
S420、根据所述目标第一频繁子树和预先确定的频繁子树与人体行为的对应关系,对所述目标视频数据中的人体行为进行识别。
由前述步骤可知,第一频繁子树集中包括支持数大于预设支持数阈值的若干第一频繁子树,本实施例中根据第一频繁子树集对人体行为进行识别时,首先对第一频繁子树集中各频繁子树进行计数,确定第一频繁子树集中频繁性最高即计数值最大的第一频繁子树,并将该第一频繁子树作为目标第一频繁子树。然后将目标第一频繁子树和预先确定的频繁子树与人体行为的对应关系进行比较,确定频繁子树与人体行为的对应关系中目标第一频繁子树对应的人体行为即为所述目标视频数据中的人体行为,从而实现了对目标视频数据中的人体行为进行识别。例如,预先确定的频繁子树与人体行为的对应关系中,第一频繁子树对应挥手,第二频繁子树对应跳跃,当获取到第一频繁子树后,即可确定第一频繁子树对应的目标人体行为为挥手,即识别出人体行为视频数据中的人体行为为挥手。
在一具体实施方式中,步骤S100之前包括如下步骤:
S01、利用训练视频数据集对预先构建的深度时空推理网络模型进行训练,获得预先训练的深度时空推理网络模型;其中,所述训练视频数据集中包括若干训练视频数据,所述若干训练视频数据中包括若干人体行为;
S02、将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络,确定所述训练视频数据集中若干人体行为对应的频繁子树;
S03、根据所述训练视频数据集中若干人体行为对应的频繁子树,确定频繁子树与人体行为的对应关系。
具体地,本实施例对目标视频数据中的人体行为进行识别之前,需要预先对深度时空推理网络模型进行训练。对深度时空推理网络模型进行训练时,首先利用设备如Kinect捕捉人体行为的深度数据并采集人体行为的视频数据,并对采集的视频数据进行预处理,如对采集的视频数据分别进行变暗、加入高斯噪声和椒盐噪声等处理来增强样本数据集,使训练的深度时空推理网络模型具有泛化能力和较强的鲁棒性。在一具体实施例中,参数为0.9的变暗,加入30%的高斯噪声,加入30%的椒盐噪声等处理来增强样本数据。然后对采集的视频数据的图像大小进行归一化,例如将采集的视频数据的图像大小归一化为320*320,并按照比例将采集到的视频数据分为训练视频数据集和测试视频数据集,以便后续步骤中对深度时空推理网络模型进行训练和测试。
在对深度时空推理网络模型进行训练时,将处理后的训练视频数据集中的训练视频数据逐帧输入预先构建的深度时空推理网络模型中,在深度时空推理网络模型的最底层,训练视频数据直接作为观测值输入,对于深度时空推理网络模型的每一层(除最底层外),获得一组从子层传递过来的信念值作为观测值,并通过无监督学习方法更新类聚中心,然后依据更新后的类聚中心进行在线类聚。在进行在线类聚的同时,深度时空推理网络模型将父层类聚的获胜节点信息(PSSA)反馈至本层,对本层的类聚中心进行更新后重新计算信念值,并将此信念值作为输出,向上层传输到父层作为父层的观测值,直至达到预设的迭代次数或者类聚中心的变化满足预设阈值,获得预先训练的深度时空推理网络模型。
本实施例中对深度时空推理网络模型进行训练时,采用无监督学习方法来对每一层的观测值进行聚类,无监督学习方法为一种在线无监督类聚方法-竞争学习(winnertake all,WTA),WTA只对与新到样本最相似(距离最近)的类聚中心进行调整,与样本无关的其它类性质(类聚中心的位置)得以保存,从而提高了深度时空推理网络模型的训练效率和鲁棒性。聚类中心的更新步长可以根据用户需要进行设置,在一具体实施例中,设置聚类中心的更新步长为0.1。
深度时空推理网络模型训练完成后,关闭网络每层类聚中心的更新与父层对本层的信息反馈,并初始化第i层第j个节点第k个类聚中心的被激活的次数N
在一具体实施例中,步骤S02包括如下步骤:
S021、将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络模型,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第二激活次数;
S022、根据所述第二激活次数,构建第二行为特征树;
S023、利用频繁子树挖掘算法从所述第二行为特征树中获取第二频繁子树集;
S024、根据所述第二频繁子树集,确定所述训练视频数据集中若干人体行为对应的频繁子树。
具体地,本实施例中在确定训练视频数据集中若干人体行为对应的频繁子树时,首先将训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络模型,确定深度时空推理网络模型的各个节点中类聚中心对应的第二激活次数,然后根据第二激活次数确定各节点中最常被激活的类聚中心对应的第二激活频率,并以深度时空推理网络模型的层数为树高度,以深度时空推理网络模型的节点为树节点,以第二激活频率为节点值,构建第二行为特征树。
与前述第一行为特征树的挖掘步骤类似,构建第二行为特征树后,利用频繁子树挖掘算法从所述第二行为特征树中获取第二频繁子树集,并从第二频繁子树集中获取频繁性最高的若干第二频繁子树作为训练视频数据集中若干人体行为对应的频繁子树,以便后续步骤中确定训练视频数据集中若干人体行为对应的频繁子树。
在一具体实施例中,发明人利用Kinect采集人体行为视频数据集,该视频数据集中包括挥手和跳跃2种常见人体行为,其中,每种行为有20段视频,每段视频长约10s,共80段视频,并将采集到的视频数据集进行数据增强和归一化处理后,按照80%:20%的比例分为训练视频数据集和测试视频数据集。然后构建如图2所示的一个8层的深度时空推理网络模型,网络模型中每一层的节点从底到顶依次为128×128,64×64,32×32,16×16,8×8,4×4,2×2,1,相应的每一层类聚中心的个数为2,2,4,8,32,16,8,3。利用上述基于深度时空推理网络的人体行为识别方法,将训练视频数据集中的训练视频数据输入深度时空推理网络模型中,对深度时空推理网络模型进行训练,并将测试视频数据集中的测试视频数据输入训练好的深度时空推理网络模型中,利用训练好的深度时空推理网络模型对测试视频数据集中的人体行为进行识别,得到如图3和图4所示的挥手和跳跃两种人体行为对应的频繁子树,且本发明基于深度时空推理网络的人体行为识别方法对测试数据集中人体行为的识别准确率达到85%以上。
基于上述实施例,本发明还提供了一种智能终端,其原理框图可以如图5所示。该智能终端包括通过系统总线连接的处理器、存储器、网络接口、显示屏和温度传感器。其中,该智能终端的处理器用于提供计算和控制能力。该智能终端的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该智能终端的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于深度时空推理网络的人体行为识别方法。该智能终端的显示屏可以是液晶显示屏或者电子墨水显示屏,该终端的温度传感器是预先在装置内部设置,用于检测内部设备的当前运行温度。
本领域技术人员可以理解,图5中示出的原理框图,仅仅是与本发明方案相关的部分结构的框图,并不构成对本发明方案所应用于其上的终端的限定,具体的终端可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,提供了一种智能终端,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时至少可以实现以下步骤:
将目标视频数据输入预先训练的深度时空推理网络模型中,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数;其中,所述目标视频数据中包括若干人体行为;
根据所述第一激活次数,构建第一行为特征树;
利用频繁子树挖掘算法从所述第一行为特征树中获取第一频繁子树集;
根据所述第一频繁子树集,对所述目标视频数据中的人体行为进行识别。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:将目标视频数据输入预先训练的深度时空推理网络模型中,获取所述深度时空推理网络模型中各个节点对应的第一观测值;根据所述第一观测值,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:根据所述各个节点对应的第一观测值和所述各个节点的类聚中心,确定所述第一观测值所属类簇;根据所述第一观测值所属类簇,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:根据所述第一激活次数,确定所述各个节点的目标类聚中心;根据所述目标类聚中心,构建第一行为特征树。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:基于最右扩展策略从所述第一行为特征树中生成若干第一候选子树,并确定所述若干第一候选子树的支持数;根据所述若干第一候选子树的支持数和预设的支持数阈值,确定第一频繁子树集。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:根据所述第一频繁子树集,确定目标第一频繁子树;其中,所述目标第一频繁子树为所述第一频繁子树集中频繁性最高的第一频繁子树;根据所述目标第一频繁子树和预先确定的频繁子树与人体行为的对应关系,对所述目标视频数据中的人体行为进行识别。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:利用训练视频数据集对预先构建的深度时空推理网络模型进行训练,获得预先训练的深度时空推理网络模型;其中,所述训练视频数据集中包括若干训练视频数据,所述若干训练视频数据中包括若干人体行为;将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络,确定所述训练视频数据集中若干人体行为对应的频繁子树;根据所述训练视频数据集中若干人体行为对应的频繁子树,确定频繁子树与人体行为的对应关系。
在其中的一个实施例中,该处理器执行计算机程序时还可以实现:将所述训练视频数据集中的训练视频数据输入预先训练的深度时空推理网络模型,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第二激活次数;根据所述第二激活次数,构建第二行为特征树;利用频繁子树挖掘算法从所述第二行为特征树中获取第二频繁子树集;根据所述第二频繁子树集,确定所述训练视频数据集中若干人体行为对应的频繁子树。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
综上所述,本发明公开了一种基于深度时空推理网络的人体行为识别方法及电子设备,方法包括:将目标视频数据输入预先训练的深度时空推理网络模型中,确定所述深度时空推理网络模型中各个节点的类聚中心对应的第一激活次数;根据所述第一激活次数,构建第一行为特征树;利用频繁子树挖掘算法从所述第一行为特征树中获取第一频繁子树集;根据所述第一频繁子树集,对所述目标视频数据中的人体行为进行识别。本发明通过深度时空推理网络提取的人体动态行为时空特征和频繁子树反映的不同层次特征关系进行行为识别,既关注行为中人体部位的自身特征,也关注部位之间的关联与协调,从而提高网络中的特征利用率,提升了网络的识别率,实现对视频数据中人体行为快速准确地识别。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 基于深度时空推理网络的人体行为识别方法及电子设备
- 一种基于深度时空图的人体行为识别方法及系统