基于DPSO-ANFIS的弃渣坝变形预测方法
文献发布时间:2023-06-19 12:18:04
技术领域
本发明属于弃渣坝变形预测技术领域,具体涉及基于DPSO-ANFIS的弃渣坝变形预测方法。
背景技术
随着社会经济发展,现代水利工程技术不断革新,修建水库大坝成为当前水利工程内容的主体。利用大坝实际监测数据建立变形预测模型是对大坝进行有效安全监控的手段,对监控大坝安全运行具有重要意义。针对具有复杂非线性特征的大坝变形监测数据,自适应模糊神经网络系统(Adaptive Network-basedFuzzy Inference System,ANFIS)具有结构和参数辨识的特点,自适应生成模糊规则,优化隶属和输出函数。依据输入影响因素,可自动设计系统参数,实现模糊系统自学习,对非线性系统有较好的适用性,在大坝安全监控方面有良好应用前景。目前自适应模糊神经网络在大坝变形预测领域应用较多,但是仍存在着自适应模糊神经网络适应度参数寻优困难、大坝变形预测方法预测精度较低、泛化性能差的问题。
发明内容
本发明的目的是提供基于DPSO-ANFIS的弃渣坝变形预测方法,解决了现有弃渣坝变形预测方法在精确度低、泛化性能差的问题。
本发明所采用的技术方案是,基于DPSO-ANFIS的弃渣坝变形预测方法,具体包括以下步骤:
步骤1、监测弃渣坝原始数据,对原始数据进行预处理;
步骤2、搭建自适应模糊神经网络系统,对系统中的网络参数进行赋值;
步骤3、对步骤2中自适应模糊神经网络的参数进行寻优;
步骤4、将步骤1预处理后的弃渣坝数据代入自适应模糊神经网络中进行训练和预测,此时,自适应模糊神经网络中参数经过步骤3得到最优,计算预测精度值,对比不同位置测点的预测效果。
本发明的特点还在于,
步骤2具体为:
步骤2.1、首先搭建自适应模糊神经网络,然后将步骤1预处理后的弃渣坝数据作为数据样本输入到自适应模糊神经网络的第一层输入层,进行模糊化处理,输出对应的隶属度;
式中,
其中,μA
步骤2.2、通过步骤2.1得到的隶属度,计算出每条规则的适应度,把第一层得到的隶属度作为第二层模糊规则层的输入信号,然后将输入信号进行累乘得到第二层的输出结果即适应度值;
式中,
步骤2.3、选择ANFIS初始参数,通过聚类方法对自适应模糊神经网络的参数进行赋值。
步骤3具体步骤,通过提取步骤2中自适应模糊神经网络中第二层模糊规则层的适应度值,作为粒子群初始化待优化参数,求解空间初始化标准粒子群,采用动态权重粒子群算法,将动态更新惯性权重及算法迭代寻优,生成最优的模糊规则层适应度值。
所述步骤3中粒子群算法具体步骤为:
步骤3.1、初始化标准粒子群算法参数,对种群大小、粒子初始位置与速度、迭代次数、误差精度和惯性权重进行赋值;
步骤3.2、计算粒子适应度值,根据设定的目标函数,计算出每个粒子在不同位置是所对应的适应度值,设定的目标函数取模型预测输出值与实测值的均方误差(MSE),其目标函数形式为:
式中:n为粒子群训练样本个数,y
步骤3.3、通过判断更新迭代满足精度要求或者达到最大迭代次数,输出最优的模糊规则层适应度值;
在一个N维搜索空间中,一个种群由m个粒子组成,Z表示矩阵,Z
V
Z
式中,V
随着每次迭代的运行,粒子通过个体和全局最优值来更新自身的速度与位置,更新公式为:
式中,
更新个体局部与所有粒子全局最优值后,更新惯性权重,惯性权重改变全局和局部搜索,采用自适应权重的方式对惯性权重ω进行改进,改进后的惯性权重计算公式如下:
式中,ω为惯性权重,ω
步骤4.1、对步骤3中经过动态权重粒子群算法寻优后的每条规则的适应度进行归一化计算,得到对应的归一化适应度值,即自适应模糊神经网络的第三层归一化层;
其中,
步骤4.2、计算自适应模糊神经网络每条规则的输出结果,即自适应模糊神经网络的第四层计算输出层;
其中,
步骤4.3、计算整个模糊系统的总输出,即自适应模糊神经网络的第五层总输出层;
其中,O
步骤4.4、将步骤1预处理后的弃渣坝数据与自适应模糊神经网络系统输出数据作对比,以输出不同组数的数据,达到不同天数的预测效果。
步骤2.3中,赋值包括影响半径、初始步数、最大迭代次数、目标误差、步长变化率。
步骤3.3中为了避免粒子盲目搜索,将粒子在第
步骤3.3中粒子群算法中的ω取值在0.4~0.9之间。
步骤1具体为:对原始监测数据按时间顺序进行整理,剔除每天其他时段测值,只保留一个时段测值,将整理好的数据序列进行绘图,剔除明显的跳跃点粗差,得到按时间顺序排列的实际监测数据。
本发明的有益效果是,本发明基于DPSO-ANFIS的弃渣坝变形预测方法,将自适应模糊神经网络引入到弃渣坝变形预测模型中,利用动态权重粒子群算法对自适应模糊神经网络中模糊规则层的适应度值进行参数寻优,得到最优适应度值的自适应模糊神经网络,本发明的预测方法具有较高的精确度、良好的泛化性与可靠的稳定性,工程实用综合性能较优。
附图说明
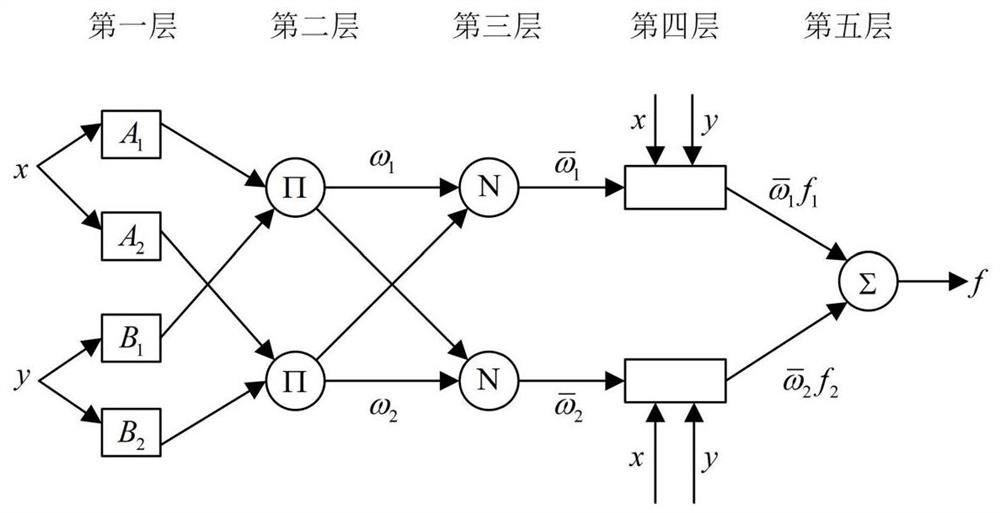
图1是本发明基于DPSO-ANFIS的弃渣坝变形预测方法的示意图;
图2是本发明基于DPSO-ANFIS的弃渣坝变形预测方法中粒子群算法的流程图;
图3是本实施例中的弃渣坝设计图;
图4是本实施例中EL1095马道测点不同模型预测结果对比图;
图5是本实施例中EL1070马道测点不同模型预测结果对比图;
图6是本实施例中EL1016马道测点不同模型预测结果对比图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于DPSO-ANFIS的弃渣坝变形预测方法,如图1所示,具体包括以下步骤:
步骤1、监测弃渣坝原始数据,对原始数据进行预处理。
步骤1具体为:对原始监测数据按时间顺序进行整理,剔除每天其他时段测值,只保留一个时段测值,将整理好的数据序列进行绘图,剔除明显的跳跃点粗差,得到按时间顺序排列的实际监测数据。
步骤2、搭建自适应模糊神经网络系统,对系统中的网络参数进行赋值。
步骤2.1、首先搭建自适应模糊神经网络,然后将步骤1预处理后的弃渣坝数据作为数据样本输入到自适应模糊神经网络的第一层输入层,进行模糊化处理,输出对应的隶属度;
式中,
其中,μA
步骤2.2、通过步骤2.1得到的隶属度,计算出每条规则的适应度,把第一层得到的隶属度作为第二层模糊规则层的输入信号,然后将输入信号进行累乘得到第二层的输出结果即适应度值。
式中,
步骤2.3、选择ANFIS初始参数,通过聚类方法对自适应模糊神经网络的参数进行赋值,赋值包括影响半径、初始步数、最大迭代次数、目标误差、步长变化率。
步骤3、对步骤2中自适应模糊神经网络的参数进行寻优;
步骤3具体步骤,通过提取步骤2中自适应模糊神经网络中第二层模糊规则层的适应度值,作为粒子群初始化待优化参数,求解空间初始化标准粒子群,采用动态权重粒子群算法,将动态更新惯性权重及算法迭代寻优,生成最优的模糊规则层适应度值。
粒子群算法,DPSO,算法的优化效率较高,从优化后的DPSO不会出现局部最优的现象,使算法继续保持寻优能力,提升了算法的效率。
步骤3中粒子群算法具体步骤,流程如图2所示:
步骤3.1、初始化标准粒子群算法参数,对种群大小、粒子初始位置与速度、迭代次数、误差精度和惯性权重进行赋值;
步骤3.2、计算粒子适应度值,根据设定的目标函数,计算出每个粒子在不同位置是所对应的适应度值,设定的目标函数取模型预测输出值与实测值的均方误差(MSE),其目标函数形式为:
式中:n为粒子群训练样本个数,y
步骤3.3、通过判断更新迭代满足精度要求或者达到最大迭代次数,输出最优的模糊规则层适应度值;
在一个N维搜索空间中,一个种群由m个粒子组成,Z表示矩阵,Z
V
Z
式中,V
随着每次迭代的运行,粒子通过个体和全局最优值来更新自身的速度与位置,更新公式为:
式中,
为了避免粒子盲目搜索,将粒子在第
更新个体局部与所有粒子全局最优值后,更新惯性权重,惯性权重改变全局和局部搜索,采用自适应权重的方式对惯性权重ω进行改进,改进后的惯性权重计算公式如下:
式中,ω为惯性权重,ω
步骤4、将步骤1预处理后的弃渣坝数据代入自适应模糊神经网络中进行训练和预测,此时,自适应模糊神经网络中参数经过步骤3得到最优,计算预测精度值,对比不同位置测点的预测效果。
步骤4.1、对步骤3中经过动态权重粒子群算法寻优后的每条规则的适应度进行归一化计算,得到对应的归一化适应度值,即自适应模糊神经网络的第三层归一化层;
其中,
步骤4.2、计算自适应模糊神经网络每条规则的输出结果,即自适应模糊神经网络的第四层计算输出层。
其中,
步骤4.3、计算整个模糊系统的总输出,即自适应模糊神经网络的第五层总输出层。
其中,O
步骤4.4、将步骤1预处理后的弃渣坝数据与自适应模糊神经网络系统输出数据作对比,以输出不同组数的数据,达到不同天数的预测效果。
实施例
本实施例中某弃渣坝位于商洛市镇安县西磨沟内,弃渣坝主要用于上下库连接道路、对外交通路及水工隧道的开挖弃渣堆放,并作为后期中转料场。弃渣坝占地面积8.12万m2,弃渣总量为475.41万m
步骤1、对坝顶水平位移监测数据进行分析,对原始数据进行预处理;
选取弃渣坝1#施工平台EL1095、EL1070、EL1016马道顺冲沟方向靠近左侧部位布设监测点的监测数据作为数据样本,监测频率为一天一次。这个时间序列包含2016年6月2日~2017年9月13日共计470组数据。
步骤2、搭建自适应模糊神经网络系统,对系统中的网络参数进行赋值;
本实施例中选择ANFIS初始参数时,通过减法聚类方法对自适应模糊神经网络的参数进行赋值,赋值包括影响半径、初始步数、最大迭代次数、目标误差、步长变化率,减法聚类参数具体取值,如表1所示。
表1减法聚类参数选取表
步骤3、对步骤2中自适应模糊神经网络的参数进行寻优;通过提取步骤2中自适应模糊神经网络中第二层模糊规则层的适应度值,作为粒子群初始化待优化参数,求解空间初始化标准粒子群,采用动态权重粒子群算法,将动态更新惯性权重及算法迭代寻优,生成最优的模糊规则层适应度值。粒子群算法参数取值具体数值,如表2所示。
表2粒子群算法参数取值表
步骤4、将步骤1预处理后的弃渣坝数据代入自适应模糊神经网络中进行训练和预测,此时,自适应模糊神经网络中参数经过步骤3得到最优,计算预测精度值,对比不同位置测点的预测效果。对前380组数据进行模糊化训练,这里以预测30组结果为例,将不同测点不同模型的预测结果进行整理,如图4、图5和图6所示,本实施例通过计算实际值与本发明预测值之间的差值,采用相关系数R、均方根误差(Root Mean Squared Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)来说明预测精度的高低。
为了准确评价模型精度,体现出自适应模糊神经网络在弃渣坝变形预测方法方面的适用性,对比传统BP神经网络及标准粒子群算法优化方法,说明动态权重粒子群算法优化方法在预测精度、泛化性方面的优越性。对比ANFIS模型、PSO-ANFIS模型以及BP神经网络模型,每个测点的性能评价指标,如表3所示。
表3不同模型下各测点性能评价表
由图4、图5和图6中预测趋势和表3中数值可知,在预测精度值方面,有关ANFIS模型的相关系数都在0.88以上,表明共线性程度较好,而BP模型的相关系数最差的为0.80,共线程度一般。在均方根误差和平均绝对误差值方面,DPSO-ANFIS预测数值小于其他模型,反映出本发明的预测精度较高。在不同位置测点,DPSO-ANFIS的预测效果好,预测趋势符合实际数据走向,精度也优于其他模型,表现出良好的泛化性。在预测时间序列方面,随着预测天数的增加,在EL1095测点中,DPSO-ANFIS模型预测效果好,整体预测性能稳定,其余三种模型表现为预测精度提高。在EL1070、EL1016这两个测点中,所有方法表现出随着预测天数增加而预测精度降低的趋势。DPSO-ANFIS模型在3个测点的预测效果中表现最好,而且预测精度在合理范围内,并优于其他方法。
本发明采用动态权重粒子群算法优化自适应模糊神经网络中模糊层的适应度值,形成寻找最优适应度值的自适应模糊神经网络,结合实际工程监测数据,通过将自适应模糊神经网络引入到弃渣坝变形预测方法中,采用动态权重粒子群算法对自适应模糊神经网络进行优化,提高预测精度、具有良好的泛化性与可靠的稳定性;对比传统BP神经网络和ANFIS两种方法,动态权重粒子群算法优化后的自适应模糊神经网络模型弥补了标准粒子群算法优化程度不够,预测精度不高的缺点,同时本发明的方法在不同位置测点、预测时间序列中性能表现较好,整体稳定性与预测效果优于其他方法,适用于弃渣坝的变形预测。
- 基于DPSO-ANFIS的弃渣坝变形预测方法
- 基于DPSO-ANFIS的弃渣坝变形预测方法