一种基于深度学习的低压台区线损估计方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及低压配电技术领域,特别涉及一种基于深度学习的低压台区线损估计方法。
背景技术
随着工业与经济的不断发展,各国开始重视并着手开展节能减排相关战略。我国政府十分重视节能减排工作,把其作为经济提高、发展方式转变的重要指标。“线损跳高,效益跳水”,国网公司总部先后于2016年和2018年两次出台了关于加强线损管理的文件,同安全生产一样,线损管理对电网企业的管理也具有十分重要的意义。
线损是反映电力企业的经营和管理水平重要技术经济指标,其大小与电力企业的经济效益息息相关。节能降损是长期国策。线损率是电力系统的一项重要技术经济指标,它同时也是衡量电力企业经营水平和管理水平的一项综合性技术经济指标。努力降低电网的电能损耗,对于管理线损尽力减到最少,将技术线损控制在合理的范围内是各级供电企业的一项必不可少的工作。由于统计线损中包含了管理线损电量,不能反映电力网的真实损耗情况,因此先计算出电网的理论线损率,再与统计线损率进行比较,如果两者相差太大,说明管理线损电量很大,需要采取一些管理和组织措施进行降损。理论线损计算不仅可以加强线损管理,为制定合理的线损考核指标提供依据,还可以在技术经济方面对各种降损措施的技术方案进行比较,考察各降损措施的实际效果。通过线损的理论计算,可以清晰的了解电网中损耗的构成情况,例如理论线损电量的占比,不明线损电量的占比,各电压等级下电网损耗的占比,线路、变压器等各元件损耗的占比等等,掌握电网中线损构成利于线损的分压、分区、分线、分台区的“四分”管理。同时,通过线损的理论计算还可以发现线损管理工作中的薄弱环节,并进行针对性改进。由此可见,线损理论计算可以指导和促进线损管理工作。
发明内容
本发明的目的在于:在不依赖复杂的理论计算方式的前提下,仅利用丰富的历史运行数据就对观测信息不及时、不完善的低压台区的理论线损进行准确估计,提高计算速度和计算准确性;同时,对采集的历史数据进行特征提取与降维,形成一种基于深度学习的低压台区线损估计方法。技术方案如下:
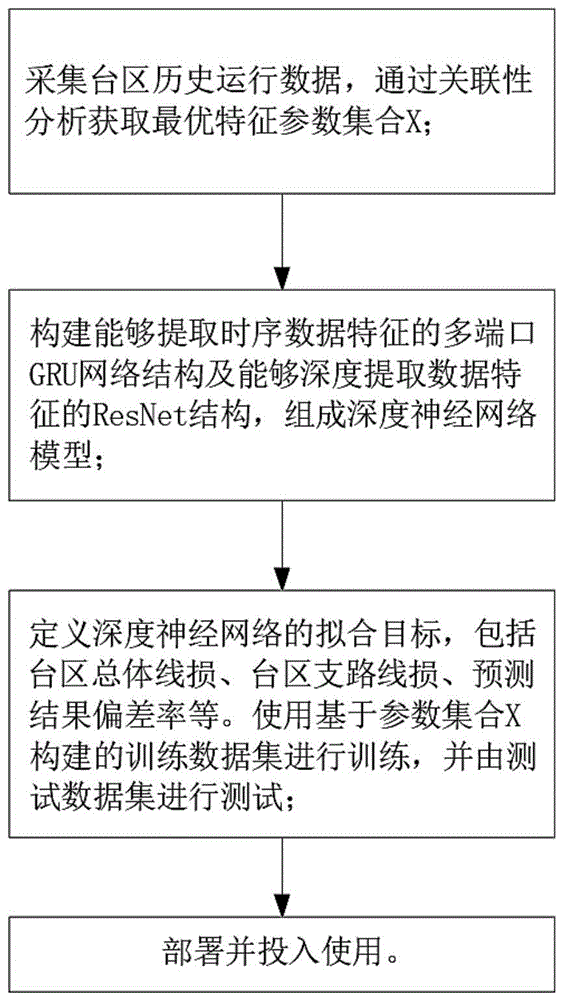
一种基于深度学习的低压台区线损估计方法,包括以下步骤:
S1:采集台区历史运行数据,包括各节点数据D、支路数据B和关于总线损有功功率的台区历史线损数据L
S2:对所述历史运行数据进行多维度关联性分析:对各节点数据D与台区历史线损数据L
S3:对各节点数据D与台区历史线损数据L
S4:构建用于提取台区数据中如电压曲线、功率曲线等具有时序结构数据的特征多端口GRU网络结构,及用于缓解数据特征提取过程中发生梯度消失和梯度爆炸问题的ResNet结构,组成深度神经网络模型;
S5:定义深度神经网络的拟合对象包括:台区整体的线损有功功率、台区各支路的线损有功功率和台区整体的线损有功功率的预测偏差;使用基于最优特征参数集合X构建的训练数据集进行训练;
S6:部署并投入使用。
进一步的,所述各节点数据D中,D={D
所述台区历史线损数据L
所述支路数据B中,B={B
所述台区历史线损数据L
更进一步的,所述对各节点数据D与台区历史线损数据L
其中,D
更进一步的,所述对各支路数据B与台区历史线损数据L
计算第t个时刻/时间段,第i种支路据与对应的史线损数据L
式中,α和β分别为在所有时刻/时间段t中,及所有支路数据种类i中,时刻/时间段t下第i种支路据与对应的史线损数据L
更进一步的,所述对各支路数据B的同期数据之间的相似度计算具体为:
式中,t
更进一步的,所述台区整体的线损有功功率的预测偏差的目标函数如下:
其中,M代表抽取的样本数目;t
更进一步的,所述深度神经网络模型中,四种时序电气特征量:节点同期电压时序数据、节点同期有功功率时序数据、节点近期电压时序数据和节点近期有功功率时序数据分别经2层GRU进行特征提取;两种非时序电气特征量:支路即时电压数据和支路即时电流数据分别经2层DNN进行特征提取;之后经汇集层将这六种电气特征量的特征数据汇集,由两个残差块进行深度特征提取,最后经输出层分别输出目标量:台区整体的线损有功功率、台区各支路的线损有功功率,以及台区整体的线损有功功率的预测偏差。
本发明的有益效果是:本发明通过对台区历史数据进行多维度关联性分析,分解出不同类型、不同时间尺度下最能够反应系统线损状态的电气特征参数;在此基础上,构建了一种基于GRU和ResNet结构的线损估计深度神经网络,能够利用历史时序数据和即时数据同时对台区整体线损、各支路线损以及预测结果偏差(误差率)进行评估;不仅能够对观测信息不及时、不完善的低压台区的理论线损进行准确估计,提高计算速度和计算准确性;同时还对采集的历史数据进行特征提取,实现数据降维,降低计算成本。
附图说明
图1为本发明基于深度学习的低压台区线损估计方法的示意图。
图2本发明方法的深度神经网络结构示意图。
图3为各节点历史电压幅值关于系统总线损有功功率之间的互信息值的统计图。
图4为各节点历史电压相位角关于系统总线损有功功率之间的互信息值的统计图。
图5为各节点历史有功功率关于系统总线损有功功率之间的互信息值的统计图。
图6为各节点历史无功功率关于系统总线损有功功率之间的互信息值的统计图。
图7为各支路参数关于支路有功功率损耗的灰色关联度统计图。
图8为支路1数据在不同时间长度下的同期数据之间的相似度大小的示意图。
图9为全部支路的数据在不同时间长度下的同期数据之间的相似度大小的平均值的示意图。
图10为训练过程中网络的预测偏差的统计图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
在本发明的一个实施例中,如图1所示,本发明提出一种基于深度学习的低压台区线损估计方法,包括以下步骤:
S1:采集台区历史运行数据,对该数据集进行多维度关联性分析,获取最优特征参数集合X。
在本实施例中,所述节点数据D中,D={D
在本实施例中,所述台区历史线损数据L
在本实施例中,所述支路数据B中,B={B
在本实施例中,所述台区历史线损数据L
在本实施例中,对台区历史运行数据的多维度关联性分析,包括对各节点数据D与台区历史线损数据L
在本实施例中,对各节点数据D与台区历史线损L
其中D
在本实施例中,对各支路数据B与台区历史线损数据L
其中,ρ为比例系数,一般取为0.5;B
在本实施例中,对各支路数据B的同期数据之间的相似度计算,由下式进行表示:
其中,t
在本实施例中,对台区历史运行数据的多维度关联性分析,根据各节点数据关于台区历史线损之间的互信息值由大到小,筛选各项数据的互信息值均排列最靠前的256个节点(记作集合ND)作为节点数据提取节点,在保证数据的特征表达能力的前提下,实现数据降维,减少内存消耗,提高计算速度。根据各支路数据关于台区历史线损数据之间的灰色关联度由大到小,确定以电压幅值、电流作为数据提取参数类型,提高输入数据的特征表达能力,避免冗余参数的干扰;根据各支路数据的同期数据之间的相似度大小,选择以待预测时间点的7日内的前4小时数据作为时序数据序列,为神经网络对台区线损有功功率的预测提供最为充分的历史数据,提高预测精度。最终得到的输入数据格式如表1所示。
表1输入数据格式
S2:构建能够提取台区数据中如电压曲线、功率曲线等具有时序结构数据的特征的多端口GRU网络结构,及能够缓解数据特征提取过程中发生梯度消失和梯度爆炸问题的ResNet结构,组成深度神经网络模型。
在本实施例中,针对多时间尺度的数据,构建的基于GRU与ResNet的多端口深度神经网络,其结构如图2所示。4种时序电气特征量分别经2层GRU进行特征提取,2种非时序电气特征量分别经2层DNN进行特征提取,之后,经汇集层将这6种电气特征量的特征数据汇集,由2个残差块进行深度特征提取,最后经输出层分别输出目标量。
S3:定义深度神经网络的拟合目标,包括台区总体线损、台区支路线损、预测结果偏差率等。使用基于参数集合X构建的训练数据集进行训练,并由测试数据集进行测试;
在本实施例中,深度神经网络的拟合对象(即输出对象)同时包括台区整体的线损有功功率(P_all),台区各支路的线损有功功率(P_each)以及台区整体的线损有功功率的预测偏差(Error)。其中,台区整体的线损有功功率的预测偏差(Error)的目标函数如下:
其中,M代表抽取的样本数目;t
S4:部署并投入使用。
为进一步验证本发明基于深度学习的低压台区理论线损估计方法的有效性,进行仿真实验。具体的,选择一563节点系统作为仿真计算原型,其中,数据总数为7800个断面。
本实验基于Python及Tensorflow 2.0框架进行,并采用Numba计算库对Numpy进行加速,所使用的计算机配置Inter Core i5-9300H CPU@2.40GHz及1张NVIDIA GTX 1660TiGPU。
实验中,首先对全部563个节点的互信息值进行计算,分别计算各节点参数与该系统总有功功率损耗之间的互信息值。计算所得的结果如图3至图6所示,根绝图中各节点各项参数关于系统总有功功率损耗之间的互信息值的大小,可以筛选出四项数值均位居前列的256个节点作为输入数据采集节点,实现数据降维。图7显示了各项支路参数关于各支路的有功功率损耗的灰色关联度值,可以看出,支路首末端电压幅值之差与支路电流关于支路有功功率损耗的灰色关联度值较高,因此选取该两项参数作为支路数据输入信息。
图8至图9分别显示了支路1和所有支路的支路参数在不同时间长度下的同期数据之间的相似度大小(横纵坐标分别为相对于当前时刻的天数(起始值为1天)和相对于当前时刻的小时数(起始值为4小时)的偏移值),可以看出,选择7日内的4小时近期数据,具有最小相似度误差。
图10显示了最终的训练结果,可以看出,仅需使用100个min-batch-size(取为128)的数据即可使神经网络的估计误差降至2%的范围内,具有较高的预测精度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。