基于OpenCL的雷达信号自适应恒虚警率检测优化方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于并行计算应用于雷达信号处理技术领域,涉及一种基于OpenCL的雷达信号自适应恒虚警率检测优化方法。
背景技术
随着雷达检测系统的越来越复杂,其精度提高的同时系统实时性却存在一定的下降。相对于传统的恒虚警检测技术,自适应恒虚警率检测在雷达信号处理中有着良好的检测性能。由于该技术有着较高的算法复杂度,所以一般采用DSP和FPGA等定制化设备,但存在开发周期长、调试难度大、耗费资源等问题。近年来,GPU进行通用计算的潜力引起了研究者的注意。由于GPU具有极强的浮点运算能力,通过将GPU引入异构计算系统,可以大幅提高计算系统性能。开放运算语言(OpenCL)是面向异构系统的并行编程标准和编程环境,它的出现为异构计算提供了一种通用和开放的解决方案。
发明内容
本发明的目的是提供一种基于OpenCL的雷达信号自适应恒虚警率检测优化方法,解决了现有雷达系统中存在大量冗余计算、内存浪费和硬件资源利用率不高的问题。
本发明所采用的技术方案是,基于OpenCL的雷达信号自适应恒虚警率检测优化方法,具体按照以下步骤实施:
步骤1、构建雷达回波信号,得到雷达回波仿真信号数据R;
步骤2、对步骤1得到的雷达回波仿真信号数据R预处理、填充序列,得到处理后的雷达回波信号数据M2;
步骤3、将步骤2得到的雷达回波信号数据M2传输到设备端,进行平方率检波,得到二维矩阵S2;
步骤4、使用步骤3得到的二维矩阵S2作为输入,进行优化后的自适应恒虚警率检测,得到目标信号检测数据T;
步骤5、将步骤4得到的目标信号检测数据T拷贝到CPU端并输出,完成变化指数恒虚警率检测处理流程。
本发明的特点还在于:
步骤1具体为:
步骤1.1、线性调频参数配置;设置采样频率为fs,雷达发射脉冲重复周期为PRT,则单个脉冲周期的采样点数为fs*PRT,再通过设置脉冲数量为n,则总的采样点数fs*PRT*n,模拟目标个数为targetNumber,并且给每个目标分配不同的目标功率;
步骤1.2、信号选择;选择线性调频信号,具体表达式为:
其中,
其中μ=B/T称为线性调频信号的调频斜率,B是调频带宽,T为脉冲宽度;
对复包络信号形式u(t)进行傅里叶变换(FFT)得到线性调频信号频谱的表达式,用U(f)表示:
步骤1.3、简化线性调频信号频谱计算方式;
按照菲涅尔积分的性质,当脉冲压缩比值(B*T)远大于1时,式(3)中线性调频信号频谱的表达式可以简化为:
根据线性调频信号频谱计算方式分别模拟产生多个目标的回波数据,且模拟产生系统噪声信号,最终得到雷达回波仿真信号数据R。
步骤2的具体过程是:
步骤2.1、将雷达回波仿真信号数据R依次进行脉冲压缩、动目标检测和动目标显示的预处理,得到数据M1;
步骤2.2、采用边界方式对步骤2.1得到的数据M1进行填充,得到填充后的雷达回波信号数据M2。
步骤2.1的具体过程是:
步骤2.1.1、对输入雷达回波仿真信号数据R进行一维傅里叶变换处理,得到频域数据S1,同时对匹配滤波器系数进行傅里叶变换处理,得到频域滤波系数C1;
步骤2.1.2、对频域数据S1和频域滤波系数C1进行复数点乘,然后进行傅里叶逆变换得到频域脉冲压缩的结果R1;
步骤2.1.3、采用动目标显示(MTI)处理对R1进行双延迟线对消滤波得到二维回波数据M,输出信号y(t)表示为:
y(t)=x(t)-2x(t-1)+x(t-2) (5);
其中x(t)为经过脉冲压缩后的结果R1;
步骤2.1.4、通过步骤2.1.3后,会减少两个脉冲,采用补零的方式填充到原来的脉冲数,然后采用傅里叶变换处理来实现动目标检测MTD滤波,对于动目标显示MTI处理后的二维回波数据M,在每个距离单元上进行傅里叶变换处理运算,得到一个相干处理时间内若干个脉冲相干积累后的结果M1。
步骤2.2具体为:在原距离维度数据上做填充,在每个脉冲距离维度的最左边和最右边分别填充M1中大小为参考单元nr和保护单元np数量和的数据,其中左右参考单元分别是当前脉冲距离维度数据的前nr和后nr个距离单元,左右保护单元分别是当前脉冲距离维度数据两侧第nr+1到nr+np+1个距离单元,得到填充后的雷达回波信号数据M2。
步骤3的具体过程是:
步骤3.1、将步骤2得到的雷达回波信号数据M2传输到GPU设备端中;
利用创建内存对象(clCreateBuffer)接口函数,在OpenCL中采用了异构系统架构(HSA),统一CPU和GPU的内存空间地址,采用zero copy的写法,实现从CPU主机端到GPU设备端的数据传递;
步骤3.2、进行平方率检波;
步骤3.2.1、设置工作组大小p,根据步骤2中得到的雷达回波信号数据M2,计算本地数组个数q,q=L/p,其中,L为雷达回波信号数据M2中距离维数据长度;
步骤3.2.2、将雷达回波信号数据M2从GPU全局内存加载到本地内存中;具体为,将全局内存中的雷达回波信号数据M2依次分配到q个本地数组中,然后对预加载的数据执行平方率检波内核计算,再将结果写回到全局内存中,得到平方率检波后的二维矩阵S2;
由于雷达回波信号数据M2数据格式为实部虚部交替存储,即连续两个数据分别是信号的实部和虚部,在每个工作组内,实部和虚部分别进行一次平方和操作,作为每个待检测单元的功率值。
步骤4的具体过程是:
步骤4.1、对步骤3得到的二维矩阵S2数据预处理,计算整个长度为L的参考单元样本均值
步骤4.2、根据步骤4.1预处理得到的总数据组SUM,设计内核函数分别处理变化因子和MR统计量,选择门限计算方法,计算得到待检测单元的杂波背景功率估计值w;
步骤4.3、将步骤4.2得到的待检测单元的杂波背景功率估计值w与待检测单元的实际值进行比较,若w大于待检测单元的实际值,则待检测单元为目标信号,输出目标信号检测数据T为1;否则,则待检测单元为噪声或者杂波,输出目标信号检测数据T为0。
步骤4.1具体为:
步骤4.1.1、根据积分图像算法,长度为L的距离维度数据的任何一段数据和表示为:
sum(a)=ii(x)-ii(y) (6)
式中ii(x)是在位置x处的积分图像值,a表示位置x到位置y的距离,ii(x)的计算方式为:
其中,x'是当前像素点的位置,i(x')是输入图像相关位置的像素点;
步骤4.1.2、利用并行前缀和(Scan)算法计算参考单元样本均值
a、设置第二工作组大小,计算本地内存数组个数,并将全局内存的二维矩阵S2数据分块划分到本地内存数组中;
b、向上扫描过程,相邻元素匹配实现的并行规约,规约次数为log
c、向下扫描过程,步骤b的逆过程,从根部向下遍历树,使用来自过程b的部分和在数组上构建扫描,从在距离维度数据L最后插入零开始,在每一步中,当前层的每个节点都将自己的值传递给它的左孩子,并将其值与左孩子的前一个值之和传递给右孩子,得到参考单元样本均值
步骤4.2具体为:
步骤4.2.1、计算统计量VI,VI统计量用来计算左右参考单元是否均匀,计算方法如下:
其中,
根据步骤4.1得到的参考单元样本均值
步骤4.2.2、计算统计量MR,MR统计量用来计算左右参考单元均值是否相同,具体为:
其中,A表示左参考单元数组,B表示右参考单元数组,
步骤4.2.3、根据背景功率检测目标;
1)、计算门限因子;
A表示左参考单元数组,B表示右参考单元数组,∑A、∑B以及∑AB分别表示左参考单元、右参考单元以及二者合并的参考单元采样值的和,VI
2)、杂波背景的判断为:
/>
K
3)、依据左右参考单元是否均匀以及二者均值是否相同,选择门限计算方法,计算得到待检测单元的杂波背景功率估计值w。
步骤4.2.3中,选择门限计算方法具体为:当左右参考单元都判断为均匀且均值相同时,采用单元平均(CA-CFAR)来估计背景功率并计算检测门限;对左右参考单元分别判断为均匀,但是二者均值不相同时,采用单元平均选大(GO-CFAR)作为背景功率的估计;当一侧参考单元判断为均匀,另一侧不均匀时,选择参考单元长度为N/2的CA-CFAR方法,N为参考单元长度;当两侧参考单元都不均匀时,选择单元平均选小(SO-CFAR)作为背景功率的估计。
本发明的有益效果是:
本发明的基于OpenCL的雷达信号自适应恒虚警率检测优化方法,通过结合OpenCL异构编程模型实现了基于GPU的自适应恒虚警率检测并行计算,能够有效减少处理数据的时间,提高系统的性能,可以满足现有雷达系统对软件实时性的要求,有效地促进了软件化雷达系统的发展和后续国产GPU生态的发展。
附图说明
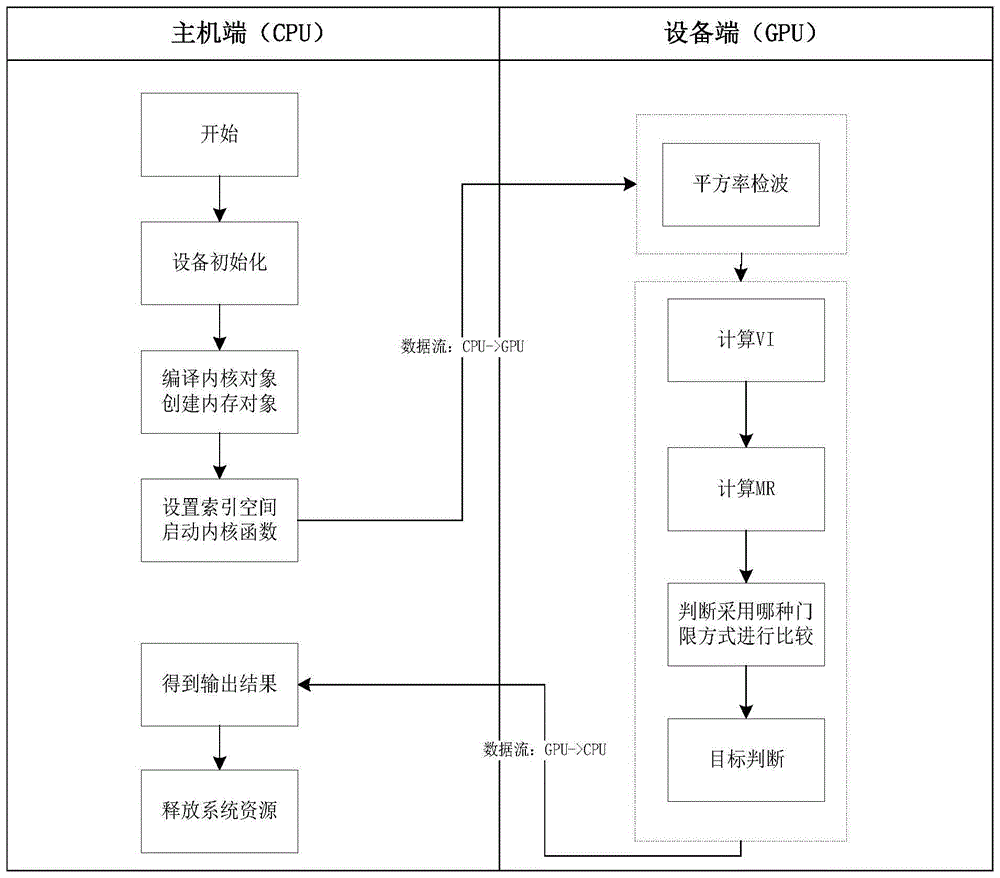
图1是本发明基于OpenCL的雷达信号自适应恒虚警率检测优化方法的流程图;
图2是本发明方法中的变化指数恒虚警率检测算法流程图;
图3是本发明方法采用的数据预处理中的填充方式图;
图4是本发明方法采用的适用于GPU的积分图像算法的流程图;
图5是本发明方法对脉冲多普勒雷达回波信号进行处理的误差统计图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明的基于OpenCL的雷达信号自适应恒虚警率检测方法,流程如图1所示,按照以下步骤实施:
步骤1,构建雷达回波信号,得到雷达回波仿真信号数据R,具体过程是:
1.1、线性调频参数配置;
设置采样频率为fs,雷达发射脉冲重复周期为PRT,则单个脉冲周期的采样点数为fs*PRT,再通过设置脉冲数量为n,则总的采样点数fs*PRT*n,模拟目标个数为targetNumber,并且给每个目标分配不同的目标功率。
1.2、信号选择;
选择线性调频信号,具体表达式为:
其中,
其中μ=B/T称为线性调频信号的调频斜率,B是调频带宽,T为脉冲宽度,t是时间变量;
对复包络信号形式u(t)进行傅里叶变换(FFT)得到线性调频信号频谱的表达式,用U(f)表示:
1.3、简化线性调频信号频谱计算方式;
按照菲涅尔积分的性质,当脉冲压缩比值(B*T)远大于1时,式(3)中线性调频信号频谱的表达式可以简化为:
根据线性调频信号频谱计算方式分别模拟产生多个目标的回波数据,且模拟产生系统噪声信号,最终得到雷达回波仿真信号数据R。
步骤2,对步骤1得到雷达回波仿真信号数据R进行预处理和填充序列,得到处理后的雷达回波信号数据M2,具体过程是:
步骤2.1、将雷达回波仿真信号数据R依次进行脉冲压缩、动目标检测和动目标显示的预处理,得到数据M1;
步骤2.1.1、对输入雷达回波仿真信号数据R进行一维FFT处理,得到频域数据S1,同时对匹配滤波器系数进行FFT处理,得到频域滤波系数C1;
步骤2.1.2、对频域数据S1和频域滤波系数C1进行复数点乘,然后进行傅里叶逆变换得到频域脉冲压缩的结果R1;
步骤2.1.3、动目标显示(MTI)处理是根据杂波和动目标回波在频率上的差异,通过对R1进行双延迟线对消滤波得到二维回波数据M,输出信号y(t)表示为:
y(t)=x(t)-2x(t-1)+x(t-2) (5);
其中x(t)为经过脉冲压缩后的结果R1。
步骤2.1.4、通过步骤2.1.3后,会减少两个脉冲,采用补零的方式填充到原来的脉冲数,然后采用FFT来实现动目标检测MTD滤波,对于动目标显示MTI处理后的二维回波数据M,在每个距离单元上进行FFT运算,得到一个相干处理时间(CPI)内若干个脉冲相干积累后的结果M1;
步骤2.2、为了减少GPU数据中不必要的if和else分支操作,采用边界方式对步骤2.1得到的数据M1进行填充;
具体为:在原距离维度数据上做填充,在每个脉冲距离维度的最左边和最右边分别填充M1中大小为参考单元nr和保护单元np数量和的数据,其中左右参考单元分别是当前脉冲距离维度数据的前nr和后nr个距离单元,左右保护单元分别是当前脉冲距离维度数据两侧第nr+1到nr+np+1个距离单元,如图3所示。不论是镜像复制还是按序复制都会对这两类数据结果产生影响较小,得到填充后的雷达回波信号数据M2。
步骤3,使用步骤2构建的雷达回波信号数据M2传输到GPU设备端中,进行平方率检波,得到二维矩阵S2,具体过程是:
步骤3.1、将步骤2中填充后的雷达回波信号数据M2传输到GPU设备端中;
步骤3.1.1、利用创建内存对象(clCreateBuffer)接口函数实现从CPU主机端到GPU设备端的数据传递,其中参数配置为内存对象将设置主机指针指定的内存区域(CL_MEM_COPY_HOST_PTR),主机设备会在GPU设备上分配一个缓冲区,一般是GPU中的RAM,然后会立即将数据复制到GPU设备端,不需要额外的内存分配,但会在每个设备上都会分配该缓存,可以通过下述步骤解决;
步骤3.1.2、在OpenCL中采用了异构系统架构(HSA),统一CPU和GPU的内存空间地址,采用zero copy的写法,不需要将先将数据从CPU内存中传输到GPU中,通常依靠基于直接存储器访问(DMA)的复制和内存管理单元(MMU)的内存映射,便于CPU与GPU传递指针,减少了CPU与GPU之间数据传输的次数,能够有效的减少处理数据的时间,提升了系统性能。
步骤3.2、进行平方率检波;
步骤3.2.1、设置工作组大小p,对于平方率检波内核函数来说,AMD系列GPU支持的最大工作组大小为256。根据步骤2中得到的雷达回波信号数据M2,选择该数据中距离维度数据长度L除以工作组大小p来确定本地数组个数q;
步骤3.2.2、为了减少全局内存的访问次数,需要将步骤3.2.1中得到的M2从GPU全局内存加载到本地内存中;
根据步骤3.2.1设置的工作组大小p,将全局内存中的数据M2依次分配到q个本地数组中,然后对预加载的数据执行平方率检波内核计算,然后将结果写回到全局内存中,得到平方率检波后的二维矩阵S2;
由于M2信号数据格式为实部虚部交替存储,即连续两个数据分别是信号的实部和虚部,在每个工作组内,实部和虚部分别进行一次平方和操作,作为每个待检测单元的功率值。
步骤4,如图2所示进行自适应恒虚警率检测,即使用步骤3得到的二维矩阵S2作为输入,设计内核函数分别处理变化因子和MR统计量,判断当前信号是否是目标信号,具体过程是:
步骤4.1、对步骤3得到的二维矩阵S2数据预处理,整个长度为L的参考单元样本均值
具体为:
步骤4.1.1、根据积分图像算法,长度为L的距离维度数据的任何一段数据和可以表示为:
sum(a)=ii(x)-ii(y) (6)
式中ii(x)是在位置x处的积分图像值,a表示位置x到位置y的距离,ii(x)的计算方式为:
其中,x'是当前像素点的位置,i(x')是输入图像相关位置的像素点;
步骤4.1.2、利用并行前缀和(Scan)算法计算参考单元样本均值
a、设置第二工作组大小,计算本地内存数组个数,并将全局内存的二维矩阵S2数据分块划分到本地内存数组中;
b、向上扫描(Up Sweep)过程,如图4所示,相邻元素匹配实现的并行规约,规约次数为log
c、向下扫描(Down Sweep)过程,步骤b的逆过程,如图4所示,我们从根部向下遍历树,使用来自过程b的部分和在数组上构建扫描。我们从在距离维度数据L最后插入零开始,在每一步中,当前层的每个节点都将自己的值传递给它的左孩子,并将其值与左孩子的前一个值之和传递给右孩子,得到参考单元样本均值
步骤4.2、根据步骤4.1预处理得到的总数据组SUM,设计内核函数并行计算VI和MR统计量,选择门限计算方法,计算得到待检测单元的杂波背景功率估计值w;
具体为:
步骤4.2.1、计算统计量VI,VI统计量用来计算左右参考单元是否均匀,主要用来判断参考单元中的采样数据是否来自于均匀环境,计算方法如下:
其中,
根据步骤4.1得到的参考单元样本均值
步骤4.2.2、计算统计量MR,MR统计量用来计算左右参考单元均值是否相同。具体为:
其中,A表示左参考单元数组,B表示右参考单元数组,
步骤4.2.3、根据背景功率检测目标;
1)、计算门限因子;
下表1中,A表示左参考单元数组,B表示右参考单元数组,∑A、∑B以及∑AB分别表示左参考单元、右参考单元以及二者合并的参考单元采样值的和,如图2所示,VI
2)、杂波背景的判断为:
K
3)、依据左右参考单元是否均匀以及二者均值是否相同,根据下表1选择门限计算方法,计算得到待检测单元的杂波背景功率估计值w。
表1检测门限计算方案
表1中,当左右参考单元都判断为均匀且均值相同时,采用单元平均(CA-CFAR)来估计背景功率并计算检测门限。对左右参考单元分别判断为均匀,但是二者均值不相同时,采用单元平均选大(GO-CFAR)作为背景功率的估计。当一侧参考单元判断为均匀,另一侧不均匀时,选择参考单元长度为N/2的CA-CFAR方法,N为参考单元长度。当两侧参考单元都不均匀时,选择单元平均选小(SO-CFAR)作为背景功率的估计。
步骤4.3、判定待检测单元是否为目标;
将步骤4.2得到的待检测单元的杂波背景功率估计值w与待检测单元的实际值进行比较,若w大于待检测单元的实际值,则待检测单元为目标信号,输出目标信号检测数据T为1;否则,则待检测单元为噪声或者杂波,输出目标信号检测数据T为0。
步骤5,将步骤4得到的目标信号检测数据T从GPU端拷贝到CPU主机端并输出,完成变化指数恒虚警率检测处理流程。
通过从缓冲区对象读入主机内存接口函数(clEnqueueReadBuffer)函数,将步骤4得到的目标信号检测数据T从GPU端拷贝到CPU端并输出,完成变化因子恒虚警率检测的处理过程。
本发明的基于OpenCL的雷达信号自适应恒虚警率检测优化方法,优点为:
(1)相对于传统的基于经典恒虚警处理方案,提出了基于OpenCL的自适应恒虚警率检测处理方案。采用CPU+GPU异构模型,CPU端处理逻辑,GPU端处理数据,能够充分发挥系统的性能。
(2)分别从硬件特征、存储和算法本身角度对自适应恒虚警率检测方法进行优化。硬件方面,由于GPU不擅于处理分支操作,通过对源数据预处理从而减少分支逻辑操作;在内存方面,通过将数据从全局内存分配到更靠近线程的局部内存中,减少了线程访问全局数据的时间;在算法本身方面,分别优化了变化指数和MR统计量的计算方法,解决了每个线程都需要做一次求和的冗余操作,改善了系统性能。
实施例
为验证本方法的有效性,通过以下仿真实验进行进一步阐述。
1、仿真条件
硬件条件:仿真测试的CPU为Intel(R)Core(TM)i5-6200U,4核,运行频率为2.4GHz;GPU为AMD Radeon R7 M370,采用GCN1架构,运行频率为875MHz。
模拟信号参数:发射信号带宽为2.0×10
2、仿真内容
仿真1:
在上述仿真条件下,针对该数据矩阵进行距离维CFAR检测时,分别采用一维和二维寻址方式,选用变化指数恒虚警率检测技术,测试稳定后取三次实验结果,表2给出了CFAR在CPU和GPU上运行时间对比。
表2CPU与GPU运行时间以及加速比
/>
仿真2:
在上述仿真条件下,用本发明对脉冲多普勒雷达信号进行GPU加速,得到的整体加速比以及GPU内核利用率如表3所示。
表3优化前后的执行时间对比
仿真3:
在上述仿真条件下,用本发明和matlab软件对脉冲多普勒雷达信号回波信号进行处理,统计两者的误差,结果如图5所示。
3、仿真分析
从表2可以看出采用一维和二维寻址方式分别耗费的平均时间为130.148ms、31.479ms。并行化后的恒虚警率检测算法在GPU上相对于CPU有着良好的性能,且采用二维寻址方式相对于一维更能体现GPU的性能。
由表3可以看出,优化后系统的执行时间较优化前缩小到原来的1/9,由于减少了计算时大量的阻塞状态,内核利用率也得到了较大提升。实验证明,本方法加速效果明显。
由图5可以看出,用本发明和matlab软件处理后的数据基本一致。在处理待检测功率估计值时将CPU与GPU的数据做误差分析,其绝对误差小于3×10