基于双层孪生网络和可持续学习的人脸伪造检测方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及属于人工智能安全领域,尤其涉及一种基于双层孪生网络和可持续学习的人脸伪造检测方法。
背景技术
人脸深度伪造是一种生成式深度学习算法,它能创建或者修改人脸的面部特征,这些修改过的伪造视频或者图像很难用人眼去辨别真假,因此,如何有效的检测人脸伪造是亟需解决的问题。
目前,大部分人脸伪造检测方法均基于深度学习,这些方法通常是利用人工神经网络,提取人脸图像特征并识别出篡改的痕迹,从而检测出人脸图像是否是伪造。然而,现有的基于深度学习的很多人脸伪造检测方法的神经网络模型一般只有单一网络架构,这样的网络架构模型训练提取特征时通常更倾向于提取单一维度的特征,而忽视了从多维度的角度提取特征,导致检测的准确性不高。因此,若将网络模型解耦成两个子网络,并且将多维度的特征进行交互融合,可以提高模型整体提取特征的能力,提高模型检测的准确性。
基于深度学习的检测方法虽然能够取得较好的检测效果,但是大部分方法着眼于提高准确度,却忽视了检测方法的泛化性。因此,当待检测的伪造技术与训练时的伪造技术不同时,检测的准确率会大大降低,这主要是因为检测模型的泛化性不足。
虽然现有不少新的提高检测泛化性方法已经被提出,但检测模型的泛化性仍有很大的提升空间。持续学习是指模型在多个不同任务工程中持续的学习,在最大限度不遗忘掉已学过知识的前提下,提高在新知识上的性能。因此,若基于持续学习来优化模型,便可以较好的弥补模型在泛化性方面的缺陷,在检测未知人脸伪造技术上也能有较好的准确率。另一方面,基于持续学习的很多方法对于数据进行不断迭代的有监督学习,从而获得的特征表示容易产生过拟合。这是因为有监督学习更倾向于拟合在已知任务上旧的特征,从而在持续学习过程中,当学习到新的未知任务时,会更加倾向于遗忘之前学过的旧任务。总的来说,只利用有监督学习进行训练的模型,面对新的未知任务的时候,容易发生灾难性遗忘,准确度会大幅降低。
在现实生活中,因为人脸伪造方式多种多样,不同人脸伪造方式对图像造成的影响也不同,现有的人脸伪造检测一般只判断该人脸图像是否是伪造的,很少去判断该人脸伪造图像具体的伪造位置。
综上所述,可得出,现有人脸伪造检测技术主要的缺陷与不足为:
1)现有的人脸伪造检测网络模型,大多是单一网络模型架构,这样的模型架构提取特征时倾向于提取单一维度的特征,容易忽视多维度的特征,导致检测准确率不够高;
2) 现有的人脸伪造检测方法的泛化性能不足,面对未知的伪造技术时,进行预测的准确率不高。此外,现有的基于持续学习的方法因为大多只采用有监督学习,有一定程度上的灾难性遗忘和过拟合问题;
3)现有的人脸伪造检测方法的一般只判断人脸图像是否是伪造的,而不去检测具体的伪造位置。
发明内容
发明目的:本发明的目的是提供一种能提高准确性、泛化性能和检测出人脸伪造具体
位置的基于双层孪生网络和可持续学习的人脸伪造检测方法。
技术方案:本发明的人脸伪造检测方法,包括如下步骤:
S1,对获取数量庞大的人脸伪造图像进行预处理操作,并且根据不同的伪造技术,将图像数据集划分为不同的任务数据集,并整合所有的任务数据集形成一个完整的人脸伪造图像数据集;
S2,以人脸伪造图像数据集为训练集,基于持续学习策略,训练预先构建好的双层孪生网络,得到基于双层孪生网络和可持续学习的人脸伪造检测模型;
S3,采用人脸伪造检测模型对待检测的人脸图像进行检测,预测图像中每一个像素点的伪造概率;若伪造概率大于阈值,判断该像素点是伪造的,最终得出待测图像对应的预测伪造结果图像和伪造位置。
进一步,步骤S1中,所述人脸伪造图像数据集的实现步骤如下:
S11,选择人脸伪造检测任务的公共数据集FaceForensics++和人脸公开数据集CelebA;
其中,公共数据集包含大量人脸伪造视频,利用DeepFakes、Face2Face、FaceSwap和NeuralTextures四种人脸伪造技术,采用帧采样的方式,根据公共数据集中的视频得到人脸伪造图像;
人脸公开数据集包含大量真实人脸图像,利用DeepFakes,Face2Face,FaceSwap和NeuralTextures四种人脸伪造技术,对人脸公开数据集中的人脸图像进行伪造,每张图像随机采用一种伪造方式;
S12,对于获取到的所有人脸伪造图像,统一调整为相同尺寸,并按照伪造技术不同划分为t个任务数据集
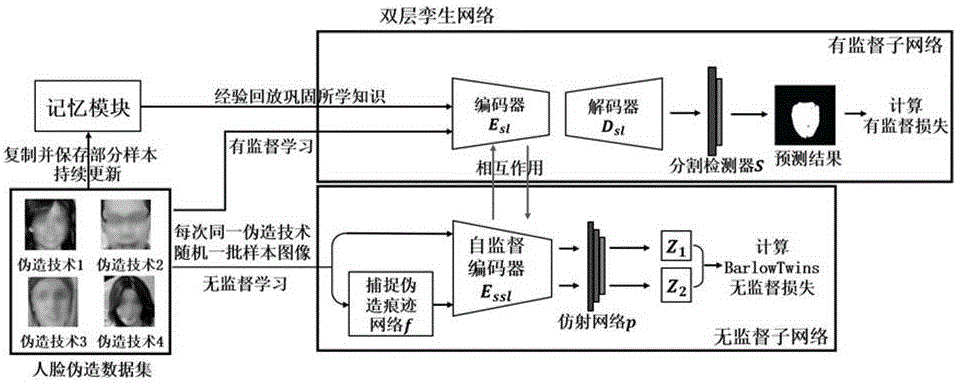
进一步,步骤S2中,所述双层孪生网络主要包括三个部分:用于快速学习的有监督子网络、用于慢速学习的无监督子网络和记忆模块;
其中,无监督子网络通过无监督学习的方式充分学习人脸伪造的篡改痕迹特征,并将学习到的每一层特征通过特征融合的方式融合到有监督子网络来指导其学习,并利用当前的有监督子网络检测结果来计算自监督损失,同时更新无监督子网络的权重参数;
有监督子网络在有监督学习下利用三种损失来共同进行训练,三种损失包括:无监督子网络的无监督检测结果来计算损失;利用有监督子网络在无监督指导下的有监督学习检测结果来计算损失;计算在无监督子网络指导下的当前模型对于记忆样本的检测结果与记录的记忆样本的旧的检测结果之间的KL散度;
记忆模块通过不断经验回放来巩固人脸伪造检测模型学习到的知识,每次随机提取的样本都会有一部分被复制到记忆模块当中,当人脸伪造检测模型在学习新的伪造技术时,会不断从记忆模块中采样样本数据,对人脸伪造检测模型进行训练。
进一步,所述无监督子网络包括捕捉伪造痕迹网络
所述有监督子网络包括有监督编码器
进一步,步骤S2中,以人脸伪造图像数据集为训练集,基于持续学习策略,训练预先构建好的双层孪生网络的实现包括以下步骤:
S21,从训练集中,随机任取第t个伪造技术组成的数据集
S22,对于第
路线1是直接输入自监督编码器
路线2是输入到捕捉伪造痕迹网络
此时,通过无监督方式计算特征
其中,
式中,
其中,
S23,对于第t个伪造技术组成的数据集
其中,y表示标注的真实伪造位置;
随后,对记忆模块中的样本数据进行采样,得到样本数据
表示记忆模块中采样的样本数据的数量,/>
通过有监督网络的预测结果
其中,/>
最终,人脸伪造检测模型的有监督损失
利用有监督损失
进一步,步骤S2中,基于持续学习策略,不断重复选取任务数据集
本发明与现有技术相比,其显著效果如下:
1、本发明设计的双层孪生网络模型由两个子网络组成,两个子网络分别对应无监督学习下提取特征和有监督学习下提取特征,两者交互作用,特征融合,模型能够获取到多维度的特征,合理的增强了模型的人脸伪造图像提取特征能力,有效的提高了人脸伪造检测的准确性;
2、本发明利用持续学习策略来对双层孪生网络模型进行训练,有效的弥补现有方法在检测泛化性能不足方面的缺陷;同时,在持续学习中加入了无监督学习来提取特征,缓解了现有的基于持续学习的方法只采用有监督学习的方式导致的灾难性遗忘和过拟合问题,从而进一步提高了模型人脸伪造检测的泛化性能;
3、本发明采用了针对于分割检测专用的损失函数以及U-Net网络结构,判断该图像是否伪造的同时还能够分割图像检测出人脸伪造的具体位置。
附图说明
图1为本发明的人脸伪造检测模型训练过程中的整体结构图;
图2为本发明的双层孪生网络中无监督子网络的示意图;
图3为本发明的双层孪生网络中有监督子网络的示意图;
图4为本发明的双层孪生网络中两个子网络之间交互的示意图。
具体实施方式
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
本发明提出的基于双层孪生网络和可持续学习的人脸伪造检测方法,通过结合有监督学习和无监督学习的方式有效地提高模型检测的准确性。同时,通过持续学习策略大幅地提高检测模型对于未知伪造方式的泛化能力,无监督的加入也缓解了持续学习中的灾难性遗忘和过拟合问题。此外,本发明还能准确检测出伪造的具体位置。
如图1所示,本实施例提供了一种基于双层孪生网络和可持续学习的人脸伪造检测方法,具体细节包括如下步骤:
步骤1,构建训练用数据集
对获取数量庞大的人脸伪造图像进行预处理操作,并且根据不同的伪造技术,将图像数据集划分为不同的任务数据集,并整合所有的任务数据集形成一个完整的人脸伪造图像数据集,以便于后续持续学习。
本实例选择了两个数据集作为实验数据集,分别是人脸伪造最常用的数据集FaceForensics++与人脸公开CelebA数据集,FaceForensics++数据集有大量人脸伪造视频,利用了四种人脸伪造技术,即DeepFakes,Face2Face,FaceSwap和NeuralTextures,对于视频利用opencv-python工具库包进行帧采样,具体为每秒采样10帧;CelebA数据集,该数据集包含大量真实人脸图像,利用DeepFakes,Face2Face,FaceSwap和NeuralTextures四种人脸伪造技术对这些人脸图像进行伪造,每张图像随机采用一种伪造方式,保证这四种伪造方式应用图像数量大致相同,通过这两种方式获取到数量庞大的人脸伪造图像,接着对人脸伪造图像进行预处理操作,将这些图像的尺寸都缩放到158*158大小;将调整后的图像按照伪造技术不同从而划分为t个的任务数据集
优选的,本实施例中t为4,共划分为4个不同任务,每个子任务数据集含有3万张人脸伪造图像,整体数据集共有12万张人脸伪造图像用于训练与测试。
步骤2,以步骤1中的人脸伪造图像数据集为驱动,基于持续学习策略训练预先构建好的双层孪生网络。双层孪生网络主要包括三个部分:适用于快速学习的有监督子网络、适用于慢速学习的无监督子网络和记忆模块。
其中,无监督子网络通过无监督学习的方式充分学习人脸伪造的篡改痕迹特征,并将学习到的每一层特征通过特征融合的方式融合到有监督子网络来指导其学习,并利用当前的有监督子网络检测结果来计算自监督损失,从而更新无监督子网络的权重参数。
有监督子网络在有监督学习下利用三种损失来共同进行训练,包括A1)无监督子网络的无监督检测结果来计算损失;A2)利用有监督子网络在无监督指导下的有监督学习检测结果来计算损失;A3)计算在无监督子网络指导下的当前模型对于记忆样本的检测结果与之前记录的记忆样本的旧的检测结果之间的KL散度,三方面损失合并,实现同时约束模型的特征提取,无监督子网络与有监督子网络的互补作用。
此外,记忆模块通过不断经验回放来巩固人脸伪造检测模型学习到的知识,每次随机提取的样本都会有一部分被复制到记忆模块当中,当人脸伪造检测模型在学习新的伪造技术时,会不断从记忆模块中采样样本数据,对人脸伪造检测模型进行训练,从而巩固之前已学习到的旧知识。通过不断地迭代来优化整个模型的权重参数,最终获得最优的权重参数并能够提取到恰当的多种人脸伪造技术之间的共性特征,从而实现人脸伪造检测上的高泛化性。
用步骤1中的人脸伪造图像数据集来训练预先构建好的双层孪生网络,包括以下步骤:
步骤21,从训练图像数据集中,随机任取第t个伪造技术组成的数据集
优选的,本实施例中任取的每批样本图像数量为32,而这其中复制进记忆模块的样本图像数量为12。
步骤22,如图2所示,开始构建双层孪生网络中的无监督子网络,该无监督子网络由捕捉伪造痕迹网络
对于第
路线1是直接输入自监督编码器
另一条路线2是通过捕捉伪造痕迹网络
此时,同样的一批样本经过两个不同路线得到了一对特征
其中,
式(1)中,
步骤23,如图3所示,开始构建双层孪生网络中的有监督子网络,该有监督子网络由有监督编码器
如图4所示,有监督子网络中的有监督编码器
对于任取到的第t个伪造技术组成的数据集
式中,y表示标注的真实伪造位置;
接着在记忆模块中的样本数据进行采样,得到样本数据
式中,
利用从记忆模块中采样再通过有监督网络的预测结果
式中,
优选的,本实施例中,超参数
最终,双层孪生网络的有监督损失
利用有监督损失
基于持续学习策略,不断重复选取任务数据集
步骤3,用步骤2中训练好的基于双层孪生网络和可持续学习的人脸伪造检测模型,对想要检测的人脸图像进行检测,得出图像中每一个像素点的伪造预测概率,若概率大于阈值,即判断该像素点是伪造的,最终可以得出待测图像对应的预测伪造结果图像,图1中预测结果图的伪造白色像素点位置即为模型预测出的伪造位置。
优选的,本实施例中,阈值设置为0.5,即若一个像素点的预测概率大于0.5,即判断该像素点是伪造的。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。