一种基于机器学习技术的电子凭证流转系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及电数字数据处理领域,具体涉及一种基于机器学习技术的电子凭证流转系统。
背景技术
随着技术的发展,很多业务的办理从线下转到了线上,而线上业务又往往需要电子凭证作为身份或者资格的证明,随着业务的多样化,如何确定在什么系统中应用什么电子凭证成了一项耗费时间的过程,因此,需要一种电子凭证的流转系统来帮助使用者提高电子凭证的使用便捷性。
背景技术的前述论述仅意图便于理解本发明。此论述并不认可或承认提及的材料中的任一种公共常识的一部分。
现在已经开发出了很多电子凭证系统,经过我们大量的检索与参考,发现现有的电子凭证系统有如公开号为CN107277000B所公开的系统,这些系统一般包括:发布电子凭证签发申请;对接收端进行认证,生成电子凭证,将电子凭证与签发信息发布到电子凭证安全基础模块;从电子凭证安全基础模块获取电子凭证、电子凭证签发结果;发布电子凭证认证申请到电子凭证安全基础模块;利用电子凭证安全基础模块对接收端进行认证,将认证确认信息发布到电子凭证安全基础模块,等待接收端确认;接收端对认证确认信息进行确认;从电子凭证安全基础模块获取电子凭证认证结果。但该系统只是对单一电子凭证的管理及应用,无法解决多电子凭证时使用麻烦的问题。
发明内容
本发明的目的在于,针对所存在的不足,提出了一种基于机器学习技术的电子凭证流转系统。
本发明采用如下技术方案:
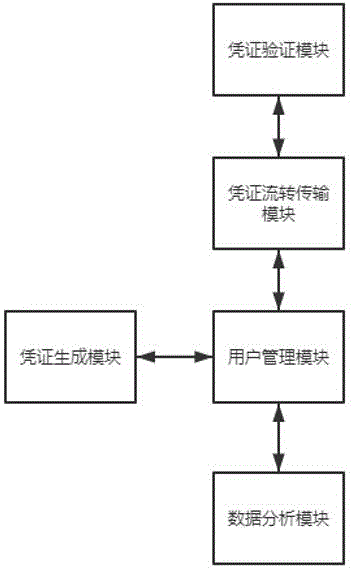
一种基于机器学习技术的电子凭证流转系统,包括凭证生成模块、凭证流转传输模块、凭证验证模块、用户管理模块和数据分析模块;
所述凭证生成模块用于生成初始凭证信息,所述凭证流转传输模块将凭证信息按照预设路径进行数据传输,所述凭证验证模块用于对传输后的凭证进行验证,所述用户管理模块用于用户管理电子凭证,所述数据分析模块基于机器学习技术预测凭证的流转路径;
所述数据分析模块接收通过所述用户管理模块发送的需求信息并对需求信息进行分析,得到需求凭证和流转路径,所述需求凭证反馈给所述用户管理模块,所述流转路径发送给所述凭证流转传输模块;
所述数据分析模块包括文本解构单元、训练单元、执行单元和配对信息记录单元,所述文本解构单元用于对需求信息进行解析,所述训练单元基于已知配对信息的解析内容对预测模型进行训练,所述执行单元用于执行预测模型,所述配对信息记录单元用于记录每个配对信息序号对应的需求凭证、流转路径和目标系统;
所述文本解构单元向所述预测模型发送解析后得到的解构词wd的文本累计值V(wd),所述预测模型设有m个输入数据和n个输出数据,所述预测模型根据下式计算出每个输出数据:
;
其中,
所述预测模型将最大的输出数据的序号作为预测的配对信息序号;
进一步的,所述训练单元使用预测模型预测的配对信息与已知需求信息的配对信息不一致时,对应的训练数据样本作为错误样本,所述训练单元计算出错误样本的偏离数据:
所述训练单元对同一批训练数据样本重复进行预测——得到偏离数据——调整处理系数过程,直至不再出现错误样本,然后将最终的处理系数发送给所述执行单元;
进一步的,所述训练单元将偏离数据处理成n*n的矩阵Q:
;
所述训练单元根据下式对处理系数进行一次优化:
;
其中,K为由处理系数构成的m*n的矩阵,
所述训练单元将矩阵
进一步的,所述文本解构单元对需求信息进行解析的过程包括如下步骤:
S21、所述文本解构单元从需求信息的文本中按照顺序获取一个关键词;
S22、所述文本解构单元选择与所述关键词关联度最大的一个解构词;
S23、根据下式对解构词的文本累计值进行累计计算:
;
其中,As为关键词与解构词的关联度,V(wd)为解构词的文本累计值;
S24、重复步骤S21至步骤S23,直至需求信息文本中的关键词被提取完毕;
S25、输出所有解构词的文本累计值;
进一步的,所述文本解构单元包括解构词寄存器、文本累计值寄存器和数据调用处理器,所述解构词寄存器用于保存关键词信息、解构词信息以及关键词与解构词的关联度信息,所述文本累计值用于保存每个解构词的文本累计值数据,所述数据调用处理器用于获取关联度信息和文本累计值信息并向计算处理器发送计算任务。
本发明所取得的有益效果是:
本系统通过设置数据分析模块,对用户提交的需求信息进行智能分析,快速得到需要的凭证以及应用的目标系统,并提供流转路径,将用户拥有的对应凭证发送至目标系统处理业务,这大大降低了用户需要自己去获取业务相关内容的时间,提高了用户使用电子凭证时的便捷性。同时,本系统通过对模型进行训练,提高了输出的需求凭证以及目标系统的准确性。
为使能更进一步了解本发明的特征及技术内容,请参阅以下有关本发明的详细说明与附图,然而所提供的附图仅用于提供参考与说明,并非用来对本发明加以限制。
附图说明
图1为本发明整体结构框架示意图;
图2为本发明数据分析模块构成示意图;
图3为本发明文本解构单元构成示意图;
图4为本发明训练单元构成示意图;
图5为本发明执行单元构成示意图。
具体实施方式
以下是通过特定的具体实施例来说明本发明的实施方式,本领域技术人员可由本说明书所公开的内容了解本发明的优点与效果。本发明可通过其他不同的具体实施例加以施行或应用,本说明书中的各项细节也可基于不同观点与应用,在不悖离本发明的精神下进行各种修饰与变更。另外,本发明的附图仅为简单示意说明,并非依实际尺寸的描绘,事先声明。以下的实施方式将进一步详细说明本发明的相关技术内容,但所公开的内容并非用以限制本发明的保护范围。
实施例一:本实施例提供了一种基于机器学习技术的电子凭证流转系统,结合图1,包括凭证生成模块、凭证流转传输模块、凭证验证模块、用户管理模块和数据分析模块;
所述凭证生成模块用于生成初始凭证信息,所述凭证流转传输模块将凭证信息按照预设路径进行数据传输,所述凭证验证模块用于对传输后的凭证进行验证,所述用户管理模块用于用户管理电子凭证,所述数据分析模块基于机器学习技术预测凭证的流转路径;
所述数据分析模块接收通过所述用户管理模块发送的需求信息并对需求信息进行分析,得到需求凭证和流转路径,所述需求凭证反馈给所述用户管理模块,所述流转路径发送给所述凭证流转传输模块;
所述数据分析模块包括文本解构单元、训练单元、执行单元和配对信息记录单元,所述文本解构单元用于对需求信息进行解析,所述训练单元基于已知配对信息的解析内容对预测模型进行训练,所述执行单元用于执行预测模型,所述配对信息记录单元用于记录每个配对信息序号对应的需求凭证、流转路径和目标系统;
所述文本解构单元向所述预测模型发送解析后得到的解构词wd的文本累计值V(wd),所述预测模型设有m个输入数据和n个输出数据,所述预测模型根据下式计算出每个输出数据:
;
其中,
所述预测模型将最大的输出数据的序号作为预测的配对信息序号;
所述训练单元使用预测模型预测的配对信息与已知需求信息的配对信息不一致时,对应的训练数据样本作为错误样本,所述训练单元计算出错误样本的偏离数据:
所述训练单元对同一批训练数据样本重复进行预测——得到偏离数据——调整处理系数过程,直至不再出现错误样本,然后将最终的处理系数发送给所述执行单元;
所述训练单元将偏离数据处理成n*n的矩阵Q:
;
所述训练单元根据下式对处理系数进行一次优化:
;
其中,K为由处理系数构成的m*n的矩阵,
所述训练单元将矩阵
所述文本解构单元对需求信息进行解析的过程包括如下步骤:
S21、所述文本解构单元从需求信息的文本中按照顺序获取一个关键词;
S22、所述文本解构单元选择与所述关键词关联度最大的一个解构词;
S23、根据下式对解构词的文本累计值进行累计计算:
;
其中,As为关键词与解构词的关联度,V(wd)为解构词的文本累计值;
S24、重复步骤S21至步骤S23,直至需求信息文本中的关键词被提取完毕;
S25、输出所有解构词的文本累计值;
所述文本解构单元包括解构词寄存器、文本累计值寄存器和数据调用处理器,所述解构词寄存器用于保存关键词信息、解构词信息以及关键词与解构词的关联度信息,所述文本累计值用于保存每个解构词的文本累计值数据,所述数据调用处理器用于获取关联度信息和文本累计值信息并向计算处理器发送计算任务。
实施例二:本实施例包含了实施例一中的全部内容,提供了一种基于机器学习技术的电子凭证流转系统,包括凭证生成模块、凭证流转传输模块、凭证验证模块、用户管理模块和数据分析模块,
所述凭证生成模块用于生成初始凭证信息,所述凭证流转传输模块将凭证信息按照预设路径进行数据传输,所述凭证验证模块用于对传输后的凭证进行验证,所述用户管理模块用于用户管理电子凭证,所述数据分析模块基于机器学习技术预测凭证的流转路径;
所述系统的电子凭证流转处理过程包括如下步骤:
S1、用户登录所述用户管理模块,提交信息给所述凭证生成模块,所述凭证生成模块生成初始电子凭证,并将凭证信息保存在所述用户管理模块中;
S2、用户通过所述用户管理模块向所述数据分析模块发送需求信息,所述数据分析模块对需求信息进行分析,得到需求凭证和流转路径,所述需求凭证反馈给所述用户管理模块,所述流转路径发送给所述凭证流转传输模块;
S3、用户根据所述需求凭证将对应的凭证信息发送给所述凭证流转传输模块;
S4、所述凭证流转传输模块根据所述流转路径将凭证信息传输至目标系统;
S5、所述目标系统通过所述凭证验证模块对凭证信息进行验证,验证通过后,所述凭证验证模块对凭证进行迭代处理,并由目标系统将迭代后的凭证信息发送给所述用户管理模块;
S6、所述用户管理模块将新的凭证信息替换原有的凭证信息进行保存;
所述凭证信息包括凭证内容和校验内容,所述凭证内容在迭代过程中保持不变,所述校验内容在迭代过程中产生变化;
结合图2,所述数据分析模块包括文本解构单元、训练单元和执行单元,所述文本解构单元用于对需求信息进行解析,所述训练单元基于已知目标系统的解析内容对预测模型进行训练,所述执行单元用于执行预测模型;
所述文本解构单元对需求信息进行解析的过程包括如下步骤:
S21、所述文本解构单元从需求信息的文本中按照顺序获取一个关键词;
S22、所述文本解构单元选择与所述关键词关联度最大的一个解构词;
S23、根据下式对解构词的文本累计值进行累计计算:
;
其中,wd表示解构词,As为关键词与解构词的关联度,V(wd)为文本累计值;
S24、重复步骤S21至步骤S23,直至需求信息文本中的关键词被提取完毕;
S25、输出所有解构词的文本累计值;
在步骤S25中,对于已知目标系统的需求信息,文本累计值被输出至训练单元,对于未知目标系统的需求信息,文本累计值被输出至执行单元;
所述预测模型设有m个输入数据和n个输出数据,其中,m为解构词的数量,n为目标系统与凭证的配对信息数量,每个输入数据与输出数据之间设有一个处理系数,用
;
其中,
其中,处理系数满足:
;
所述预测模型将最大的输出数据的序号作为预测的配对信息序号;
当预测的配对信息与已知需求信息的配对信息不一致时,对应的训练数据样本作为错误样本,所述训练单元计算出错误样本的偏离数据:
所述训练单元对一批训练数据样本进行预测后,根据错误样本对处理系数
所述处理系数用m*n的矩阵K表示:
;
所述训练单元将偏离数据处理成n*n的矩阵Q:
;
矩阵Q中的元素表示具有相同的预测配对信息序号和已知配对信息序号的偏离数据的累加值加1;
所述训练单元将矩阵K与矩阵Q相乘,得到m*n的矩阵
所述训练单元将矩阵
在矩阵K与矩阵
所述训练单元对同一批训练数据样本重复进行预测——得到偏离数据——调整处理系数过程,直至不再出现错误样本,然后将最终的处理系数发送给所述执行单元;
所述执行单元接收到一个需求信息的文本累计值后,使用预测模型进行处理,将最大的输出数据的序号作为预测的配对信息序号作为输出结果;
结合图2,所述数据分析模块包含配对信息记录单元,所述配对信息记录单元中记录了每个配对信息序号对应的需求凭证、流转路径和目标系统,所述数据分析模块根据所述执行单元的输出结构检索到对应的需求凭证和流转路径;
所述数据分析模块包含计算处理器,所述计算处理器用于执行所述文本解构单元、训练单元和执行单元发送的计算任务;
结合图3,所述文本解构单元包括解构词寄存器、文本累计值寄存器和数据调用处理器,所述解构词寄存器用于保存关键词信息、解构词信息以及关键词与解构词的关联度信息,所述文本累计值用于保存每个解构词的文本累计值数据,所述数据调用处理器用于获取关联度信息和文本累计值信息并向计算处理器发送计算任务;
结合图4,所述训练单元包括第一数据寄存器、第一预测逻辑控制器和优化控制器,所述数据寄存器用于保存训练单元产生的数据,所述预测逻辑控制器用于控制预测流程并向所述计算处理器发送与预测有关的计算任务,所述优化控制器用于控制优化流程并向所述计算处理器发送调整处理系数时的计算任务;
结合图5,所述执行单元包括第二数据寄存器和第二预测逻辑控制器,所述第二数据寄存器用于保存执行单元产生的数据,所述第二预测逻辑控制器用于控制预测流程并向所述计算处理器发送与预测有关的计算任务;
所述第一预测逻辑控制器和所述第二预测逻辑控制器是相同但独立的元件。
以上所公开的内容仅为本发明的优选可行实施例,并非因此局限本发明的保护范围,所以凡是运用本发明说明书及附图内容所做的等效技术变化,均包含于本发明的保护范围内,此外,随着技术发展其中的元素可以更新的。
- 一种在线电子凭证签署及流转方法
- 一种电子抵用凭证发放系统
- 基于电子地图及电子凭证流转按需获取信息的设备及方法
- 基于电子地图及电子凭证流转按需获取信息的设备及方法